第四章 数据计算
Laxcus所有数据计算工作都是通过网络实施。相较于集中计算,在网络间进行的数据计算更适合处理那些数据量大、复杂的、耗时长的计算任务。能够实施网络计算的前提是数据可以被分割,就是把一组大的数据分成若干组小的数据。分割数据的办法有很多种,目前最常用的是按照数值范围和散列规则进行分割。需要强调的是,在被分割后的数据里,不应该存在内容重叠的现象。
在这一章里,我们通过介绍一个分布计算算法,来说明Laxcus集群的分布计算是如何实现的。
4.1 Diffuse/Converge算法
Diffuse/Converge是我们设计的一套分布计算模型,与Laxcus大数据管理系统紧密结合,负责组织实施大规模数据计算工作。Diffuse/Converge算法依据我们对数据处理的理解产生,在我们的数据处理概念中,传统的集中计算模型,数据处理可以分解为两个阶段:产生、计算,如果把它扩大到网络环境,可以进一步解释为:分散、聚合。它们的区别在于:前者是直接产生数据,然后对数据进行计算,输出计算结果;后者是通过网络收集数据,经过组织整理后,再分配给多台计算机去执行计算,最后输出计算结果。实际上,分布计算与集中计算相比,只是多出数据组织整理环节,其它部分基本是一样的,但是在数据处理能力上,Diffuse/Converge算法可以驱动和计算的数据量远远超越集中计算所能提供的规模,足以满足当前各种大数据计算业务需要。
在Laxcus里,Diffuse/Converge算法只提供计算规则和API,实际数据计算业务仍然需要用户编码实现。
以下结合图4.1,阐述Diffuse/Converge算法的处理流程。
如图所示,Call节点是Diffuse/Converge算法的起点,实际也是计算结果的输出点,它负责进行协调和分配数据资源,而不会产生数据和计算数据。每个分布任务都从Diffuse开始,它被指向Data节点。在这个阶段,Call节点会同时发出多个Diffuse请求,分别作用到多个Data节点上。每个Data站点根据Diffuse请求中的参数,执行产生数据的工作,数据来源可以是磁盘,也可以按照某种规则生成。这些数据产生后,被抽象处理成元数据,返回给Call站点,成为后续计算的依据。
Converge是分布计算第二阶段,它的作用点是Work节点。同Diffuse阶段一样,Call节点也会向多个Work节点发出多个Converge请求,每个Work节点根据Converge请求中的参数,执行数据计算工作。与Diffuse不同的是,Converge是一个迭代的过程,在一次数据计算中,允许有任意多次的Converge发生,直到最后一次Converge计算生成计算结果。在此之前,Converge产生的都是元数据。
通过以上说明可以看到,Diffuse只执行一次,Converge会执行多次。这正是本处要特别说明的:Diffuse/Converge算法的本质是阶段间串行、阶段内并行的工作方式,每个阶段完成后才能进入下一个阶段,当前阶段的数据输出是下一阶段的数据输入。阶段内的并行处理由线程执行,线程之间是无联系的独立计算。
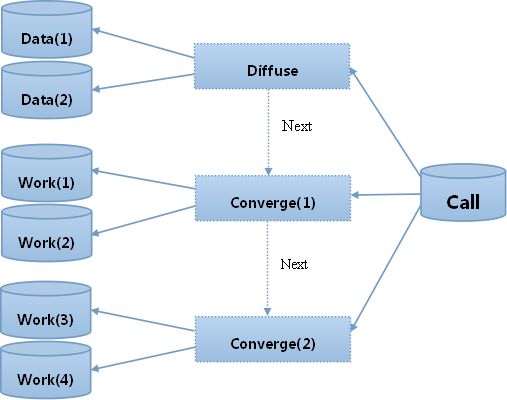
图4.1 Diffuse/Converge 处理流程
4.2 数据计算过程中的数据平均分配问题
在Diffuse/Converge分布计算过程中,每个Data/Work节点产生和计算的数据量常常是不一致的。这个现象如果放在这样的环境下就很容易看出来:1.集群的硬件配置完全一致;2.集群里只有一个计算任务。当这样的条件成立且数据量分配不均时,将导致Work节点在计算数据时,发生计算时间长短不一的现象,大批先期完成的子计算任务被迫等待最后一个计算结果,徒然增加了总计算时间,出现木桶短板效应。这样的数据处理显然不符合我们追求的最大计算量、同时最小计算时间的要求,如果能够使每个节点的数据量趋于相同,大家在相同或者接近的时间内返回计算结果,那么短板效应就会消失,就可以获得最大的计算效费比。显然这样的分布计算才是最合理和有效率的。
平均分配数据量的工作由Call站点来负责。如上所述,在数据计算过程中,Data/Work站点会向Call节点返回元数据,我们在设计这些元数据时,已经考虑到平均分配数据量问题,并因此设置了一些参数。显式的如被分割的数据尺寸,隐式的参数由用户来定义和解释。通过这些参数,Call站点在计算时,可以给每个Work站点分配相同或者基本一致的数据量。这样,在理想的环境下,每个Work节点能够在相同或者接近的时间内返回计算结果,保证数据计算获得一个最佳的计算时间。