作业来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2696
1.列表,元组,字典,集合分别如何增删改查及遍历。
(1)列表
list = ['aaa','bbb','ccc'] list.append('ddd') print(list) #末尾插入元素 list = ['aaa','bbb','ccc'] list.insert(2,'ddd') print(list) #元素插入指定位置 list = ['aaa','bbb','ccc'] list.remove('ccc') print(list) #按名称删除元素 list = ['aaa','bbb','ccc'] list.pop(1) print(list) #按位置删除元素 list = ['aaa','bbb','ccc'] list[1] = 'ddd' print(list) #按位置修改元素 list = ['aaa','bbb','ccc'] print(list[1]) #查找元素 list = ['aaa','bbb','ccc'] for bianli in list: print("序号:{} {}".format(list.index(bianli),bianli)) #遍历
显示结果:
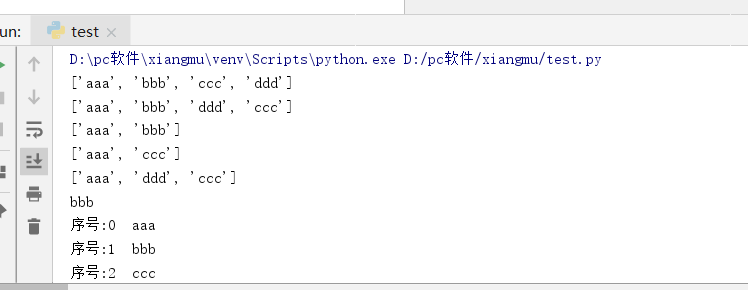
(2)元组
ob = ('aaa','bbb')
ob2 = ('ccc','ddd')
ob3 = ob + ob2
print(ob3)
#添加元素
ob3 = ('aaa','bbb','ccc','ddd')
print("第一个:{} 第二个:{}".format(ob3[0],ob3[1]))
#查找指定元素
ob = ('aaa','bbb')
print("已删除元组ob")
del ob
#元组删除
ob3 = ('你','是','真','滴','皮')
for bl in ob3:
print(bl)
#遍历元组
显示结果:

(3)字典
dict = {'aaa':100,'bbb':90,'ccc':80}
dict['ddd'] = 70
print(dict)
#添加元素
dict = {'aaa':100,'bbb':90,'ccc':80}
del dict['aaa']
print(dict)
#删除元素1
dict = {'aaa':100,'bbb':90,'ccc':80}
dict.pop('aaa')
print(dict)
#删除元素2
dict = {'aaa':100,'bbb':90,'ccc':80}
dict['aaa'] = 99
print(dict)
#修改元素
dict = {'aaa':100,'bbb':90,'ccc':80}
print("查找的人:{}".format(dict['aaa']))
#查找元素
dict = {'aaa':100,'bbb':90,'ccc':80}
for bl in dict:
print("{}:{}".format(bl,dict[bl]))
#遍历字典
显示结果:

(4)集合
s = set(['aaa','bbb','ccc'])
s.add('123456')
print(s)
#添加元素
s = set(['aaa','bbb','ccc'])
s.remove('aaa')
print(s)
#删除元素
s = set(['aaa','bbb','ccc'])
s = list(s)
s[0] = 'ddd'
s = set(s)
print(s)
#修改元素
s = set(['aaa','bbb','ccc'])
s.clear()
print(s)
s = set(['aaa','bbb','ccc'])
for bl in s:
print(bl)
#遍历
显示结果:
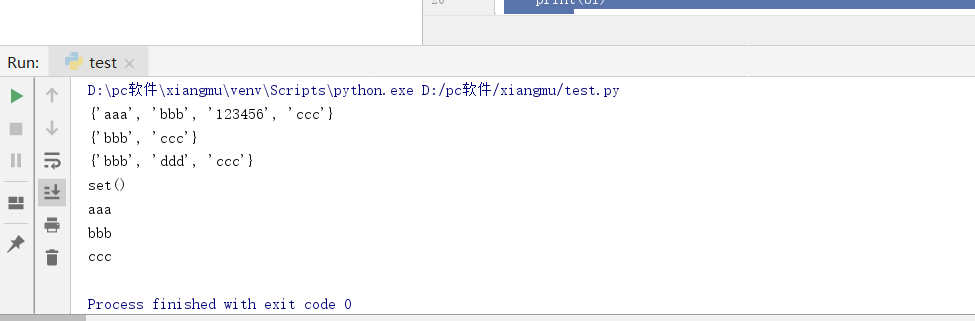
2.总结列表,元组,字典,集合的联系与区别。参考以下几个方面:
下列以列表,元组,字典,集合为默认顺序:
- 括号 ------ (1)列表:[ ] (2)元组:( ) (3)字典:{ } (4) 集合:( )
- 有序无序------(1)有序 (2)有序 (3)无序 (4)无序
- 可变不可变-----(1)可变 (2)可变 (3)不可变,元组中的元素不可修改、不可删除(4)可变
- 重复不可重复-----(1)可以重复(2)可以重复(3)可以重复(4)不可以重复
- 存储与查找方式------(1)① 找出某个值第一个匹配项的索引位置,如:list.index(‘a’)② 使用下标索引,如:list[1] (2)使用下标索引,如:tuple[1](3)通过使用相应的键来查找,如:dict[‘a’] (4)通过判断元素是否在集合内,如:1 in dict
3.词频统计
f = open(r'D:pc软件xiangmuzz.txt',encoding='utf8')
#打开文件
stop={'a','the','and','i','you','in','but','not','with','by','its','for','of','an','to','my','myself','we','our','ours','ourelves','about','no','nor'}
def gettext():
sep = "~`*()!<>?,./;':[]{}-=_+"
text = f.read().lower()
for s in sep:
text=text.replace(s,'')
return text
#读取文件
textList = gettext().split()
print(textList)
#分解提取单词
textSet = set(textList)
stop = set(stop)
textSet = textSet - stop
print(textSet)
#排除语法词
textDict = {}
for word in textSet:
textDict[word] = textList.count(word)
print(textDict)
print(textDict.items())
word = list(textDict.items())
#单词计数
word.sort(key=lambda x:x[1],reverse=True)
print(word)
#排序
for q in range(20):
print(word[q])
#次数为前20的单词
import pandas as pd
pd.DataFrame(data=word).to_csv("text.csv",encoding='utf-8')
显示结果:

词云可视化:
