1、集合分四类:set,map,list,queue
位于java.util包下.
集合类和数组的区别,数组可以保存基本类型的值或者是对象的引用,而集合里只能保存对象的引用.
集合类主要由两个接口派生而出:Collection和Map
collection集合里面一共10个可用的类.
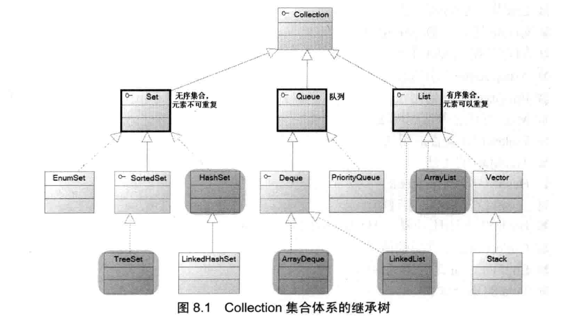
其中,
set里面4个: EnumSet, TreeSet, HashSet, LinkedHashSet
Queue里面2个: ArrayDeque, PriorityQueue,
List里面3个: ArrayList, Vector, Stack
同时实现Queue和List的一个: LinkedList
常用的有5个.
Map中实现类一共9个,常用的是HashMap, TreeMap

collection中方法,也就是Set, Queue, List共同的方法.
所有的collection的实现类都从写了toString()方法,该方法可一次性输出集合中所有元素.
包括:
求并集(添加元素或集合):
求补集(删除某元素或集合):
求交集:
是否包含某元素或集合:
是否为空:
遍历集合:
books.forEach(obj -> System.out.println("迭代集合元素:"+obj));
或者如下:
Iterator<String> it = books.iterator(); //这种形式遍历可以用it.remove()来删除元素,其他的方式都不可以,会引发异常. while(it.hasNext()){ System.out.println(it.next()); }
或者如下:
for(String book : books){ System.out.println(book); }
清空集合:
元素个数:
转成数组:
2、用java8增强的Iterator遍历集合元素
Iterator接口里定义了4个方法:
boolean hasNext(): 如果被迭代的集合元素还没有被遍历完,则返回true
Object next(): 返回集合里的下一个元素
void remove(): 删除集合里上一次next方法返回的元素
void forEachRemaining(Consumer action),这是java8为Iterator新增的默认方法,可使用Lambda表达式来遍历集合元素.
Iterator<String> it = books.iterator();
it.forEachRemaining(obj -> System.out.println("迭代集合元素:"+obj));
8.2.5 使用Java8 新增的predicate操作集合
打印长度小于10的元素:
books.removeIf(ele -> ((String)ele).length() <10);
System.out.println(books);
返回符合条件的元素的个数:
public static void main(String[] args){ System.out.println(callAll(books,ele -> ((String)ele).contains("疯狂"))); } public static int callAll(Collection<String> books, Predicate<Object> p){ int total = 0; for(Object obj :books){ if(p.test(obj)){ total ++; } } return total; }
8.2.6 Java8新增的Stream操作集合
java8新增了Stream,IntStream,LongStream等,其中Stream是一个通用的流接口.还为每个流式Api提供了对应的Builder,例如Stream.Builder,开发者可以通过这些Builder来创建对应的流.
独立使用Stream的步骤如下:
1.使用Stream或XxxStream的builder()类方法创建改Stream对应的Builder.
2.重复调用Builder的add()方法向该流中添加多个元素.
3.调用Builder的build()方法获取对应的Stream.
4.调用Stream的聚集方法.
第4步可以根据需求来调用不同的方法,Stream提供了大量的聚集方法供用户调用,对应大部分聚集方法而言,每个Stream只能执行一次.
public static void main(String[] args) { IntStream is = IntStream.builder() .add(20) .add(13) .add(-2) .add(18) .build(); // System.out.println("最大值:"+ is.max().getAsInt()); // System.out.println("最小值:"+ is.min().getAsInt()); // System.out.println("总和:"+ is.sum()); // System.out.println("总数:"+ is.count()); // System.out.println("平均值:"+ is.average()); // System.out.println("平方均大于20:"+ is.allMatch(ele -> ele*ele > 20)); // System.out.println("某个元素平方大于20:"+ is.anyMatch(ele -> ele*ele > 20)); //将is映射成一个新的Stream,新Stream的每个元素是原Stream元素的2倍+1 IntStream newIs = is.map(ele -> ele * 2 +1); // //使用方法引用的方式来遍历集合元素 newIs.forEach(System.out::println); }
因为collection有Stream接口,所以,用Stream方法来重写上面的"返回符合条件的元素的个数"
public static void main(String[] args) { Collection<String> books = new HashSet<>(); books.add("123241232"); books.add("wdw12ddw"); books.add("es23d"); System.out.println(books.stream() .filter(ele -> ((String) ele).contains("123")).count()); }
8.3 Set集合
HashSet的特点:
1.不能保证元素的排列顺序
2.不是同步的,如果多线程访问,必须通过代码来保证其同步
3.集合元素之可以是null
比较的规则是,equals()方法和HashCode()方法返回的值都相等,那么set认为是同一个对象.
所以,当把一个对象放到HashSet中时,如果需要重写该对象对应类的equals()方法,那么也要重写其hashCode()方法.
因此,当程序把可变对象添加到HashSet中之后,尽量不要去修改该集合元素中参与计算hashCode(),equals()的实例变量,否则会导致HashSet无法正确操作这些集合元素.
8.3.2 LinkedHashSet类
LinkedHashSet集合也是根据元素的hashCode值来决定元素的存储位置,但它同时使用链表维护元素的次序,这样使得元素看起来是以插入的顺序保存的,也就是说,当遍历LinkedHash集合里的元素时,LinkedHashSet将会元素的添加顺序来访问集合里的元素.
LinkedHashSet需要维护元素的插入顺序,因此新呢过略低于HashSet的性能,但在迭代访问Set里的全部元素时将有很好的性能,因为天以链表来维护内部顺序.
LinkedHashSet<String> books = new LinkedHashSet<>();
8.3.3 TreeSet 类
TreeSet是SortedSet接口的实现类,正如SortedSet名字所暗示的,TreeSet可以确保集合元素处于排序状态.与HashSet集合相比,TreeSet还提供了如下几个额外的方法.
访问前一个,后一个,第一个,最后一个元素的方法,并提供了三个从TreeSet中截取子TreeSet的方法,以及一个Comparator()来返回该TreeSet的定制的排序方法.默认使用自然排序,即从小的到大的顺序.
public static void main(String[] args) { // TODO Auto-generated method stub TreeSet nums = new TreeSet<>(); nums.add(5); nums.add(2); nums.add(6); nums.add(-4); System.out.println(nums); }
如果试图把一个对象添加到TreeSet时,则改对象的类必须实现Comparable接口,否则程序将会抛出ClassCastException异常.不过java一些常用类已经实现了Comparable接口,并提供了比较大小的标准.
另外一点:大部分类在实现compareTo(Object obj)方法时,都需要将被比较对象obj强制类型转换成相同的类型,因为只有相同类的两个实例才会比较大小.所以向TreeSet中添加的应该是同一个类(或者有继承关系)的对象.
为了让程序更加健壮,推荐不要修改放入HashSet和TreeSet集合中元素的关键实例变量.
2.定制排序
两种方法,一个是要比较的类,需要实现Comparator接口,一个是创建TreeSet时使用Lambda表达式.
8.3.4EnumSet类
EnumSet是一个专为枚举类设计的集合类,EnumSet中的所有元素都必须是指定枚举类型的枚举值,该枚举类型在创建EnumSet时显示或隐式地指定.EnumSet的集合元素也是有序的,EnumSet以枚举值在Enum类内的定义顺序来决定集合元素的顺序.
EnumSet在内部以位向量的形式存储,这种存储形式非常紧凑,高效,因此EnumSet对象占用内存很小,而且运行效率也很好,尤其是进行批量操作(如调用containsAll()和retainAll()方法时),如果其参数也是Enumset机会,则该批量操作的执行速度非常快.
EnumSet机会不允许加入null元素.

8.3.5 各Set实现类的性能分析
EnumSet性能最好,但只能保存同一个枚举类
HashSet很快,通常用它.
LinkedSet保持了存入顺序,一般操作比HashSet慢,但遍历时比HashSet快.
TreeSet,只有当需要一个保持排序的Set时,才应该使用TreeSet.
另外,这四个类都是现场不安全的,如果多线程调用,需要用synchronizedSortedSet方法包装起来.
SortedSet<String> s = Collections.synchronizedSortedSet(new TreeSet<>());
8.4 List集合

List判断两个对象相等只要通过equals()方法比较返回true即可.
public static void main(String[] args) { List<Object> books = new ArrayList<>(); // 向books集合中添加4个元素 books.add(new String("轻量级Java EE企业应用实战")); books.add(new String("疯狂Java讲义")); books.add(new String("疯狂Android讲义")); books.add(new String("疯狂iOS讲义")); // 使用目标类型为Comparator的Lambda表达式对List集合排序 books.sort((o1, o2)->((String)o1).length() - ((String)o2).length()); System.out.println(books); // 使用目标类型为UnaryOperator的Lambda表达式来替换集合中所有元素 // 该Lambda表达式控制使用每个字符串的长度作为新的集合元素 books.replaceAll(ele->((String)ele).length()); System.out.println(books); // 输出[7, 8, 11, 16] }

public static void main(String[] args) { String[] books = { "疯狂Java讲义", "疯狂iOS讲义", "轻量级Java EE企业应用实战" }; List<String> bookList = new ArrayList<String>(); for (int i = 0; i < books.length ; i++ ) { bookList.add(books[i]); } ListIterator<String> lit = bookList.listIterator(); while (lit.hasNext()) { System.out.println(lit.next()); lit.add("-------分隔符-------"); } System.out.println("=======下面开始反向迭代======="); while(lit.hasPrevious()) { System.out.println(lit.previous()); } }

public static void main(String[] args) { List<String> fixedList = Arrays.asList("疯狂Java讲义", "轻量级Java EE企业应用实战"); // 获取fixedList的实现类,将输出Arrays$ArrayList System.out.println(fixedList.getClass()); // 使用方法引用遍历集合元素 fixedList.forEach(System.out::println); // 试图增加、删除元素都会引发UnsupportedOperationException异常 fixedList.add("疯狂Android讲义"); fixedList.remove("疯狂Java讲义"); }
8.5 Queue集合
用来模拟队列,先进先出

8.5.1 PriorityQueue实现类
PriorityQueue保存队列元素的顺序并不是安计入队列的顺序,而是安队列元素的大小进行重新排序,因此当调用peek()方法或者poll()方法取出队列中的
元素时,并不是取出最先进入队列的元素,而是取出队列中最小的元素.