scrapy-图片-文件爬取
实验网址:https://sc.chinaz.com/tupian/rentiyishu.html
最终结果:获取详情页的图片,和详情页面的附件
使用框架:Scrapy>ImagesPipeline>FilesPipeline
使用工具:Chrome浏览器
一、网页分析
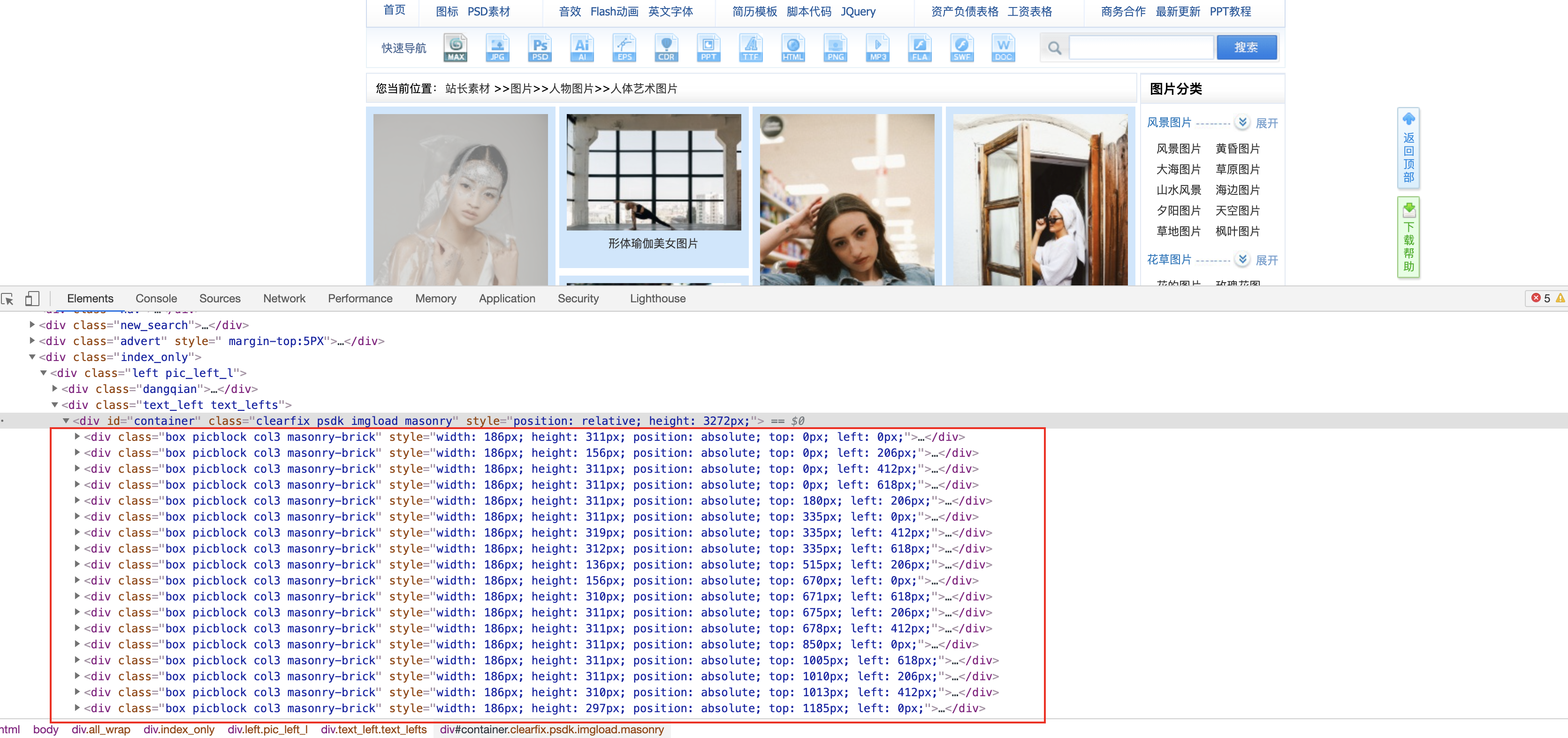
1.1首先要拿到当前页面的所有图片的div列表,此处略过框架新建项目的步骤
class ImageSpider(scrapy.Spider):
name = 'image'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://sc.chinaz.com/tupian/rentiyishu.html']
def parse(self, response):
# 拿到每个图片的div
div_list = response.xpath('//*[@id="container"]/div')
# 获取当前的总共页数
page_total = response.xpath("//div[@class='fenye']/a[last()-1]/b/text()").extract_first()
1.2 遍历div列表
此处的img_href获取的属性是src2,因为改网页使用的是图片懒加载
for div in div_list:
# 获取图片的超链接进行
img_href = 'https:' + div.xpath('./div/a/img//@src2').extract_first()
# 获取图片名称
img_name = div.xpath('./div/a/img//@alt').extract_first()
# 获取详情页面的url
content_url = 'https:' + div.xpath('./div/a/@href').extract_first()
# https://scpic1.chinaz.net/Files/pic/pic9/202101/apic30501_s.jpg
# 根据一定的规则将前面获取到超链接进行替换获取到真正的图片地址,当然也可以在详情页面直接获取,可以不用替换
new_href = str.replace(img_href, 'Files', 'files').replace('_s', '')
1.3 items配置
此处需要定义三个item
import scrapy
class ImagedownloadItem(scrapy.Item):
# define the fields for your item here like:
# 图片的超链接
url = scrapy.Field()
# 图片和压缩包的名称
img_name = scrapy.Field()
# 图片超清的压缩包
img_hd = scrapy.Field()
1.4 创建item对象
注意导包
# 创建item对象
item = ImagedownloadItem()
# 图片url传给item
item['url'] = new_href
# 图片名称传给item
item['img_name'] = img_name
# 再次手动请求把详情页面给content_url方法,并且传入item对象
yield scrapy.Request(content_url, callback=self.fileParse, meta={'item': item})
1.5 新建详情页文件下载函数
def fileParse(self, response):
# 拿到item对象
item = response.meta['item']
# print(response)
# 拿到第一个压缩包的下载地址
filepath = response.xpath("//div[@class='downbody']//div[3][@class='dian']/a[1]/@href").extract_first()
# 讲地址传入给item
item['img_hd'] = filepath
yield item
1.6 分页操作
# 分页操作获取pagenum的页码进行拼接
page_url = f'https://sc.chinaz.com/tupian/rentiyishu_{self.page_num}.html'
# 判断当前页码和全局的页面条数是否相等,不相等则进行分页解析下载
if self.page_num != page_total:
# 每次请求之后当前页面数+1
self.page_num += 1
# 递归调用当前的方法进行解析
yield scrapy.Request(page_url,callback=self.parse)
二、自定义PipeLine
2.1 自定义ImagesPipeline
# 自定义图片下载类
class ImgPipeLine(ImagesPipeline):
num = 0
# 重写父类方法
def get_media_requests(self, item, info):
# 下载请求图片,并将item对象和图片名称等信息传给下一个调用函数file_path
self.num += 1
yield scrapy.Request(item['url'], meta={'item': item, 'url': item['url'], 'img_name': item['img_name']})
# 重写方法,返回新的文件路径
def file_path(self, request, response=None, info=None, *, item=None):
# 获取图片名称拼接
img_name = request.meta['img_name'] + '.jpg'
print(f'�33[35m下载', img_name, '图片完成')
return img_name
# 返回给下一个即将被执行的管道类
def item_completed(self, results, item, info):
return item
def __del__(self):
print(f'图片数量是{self.num}')
2.2 自定义FilesPipeline
# 新建文件类
class RarPipeLine(FilesPipeline):
num1 = 0
num2 = 0
# 重写父类方法
def get_media_requests(self, item, info):
self.num1 += 1
print(f'�33[32m下载超清压缩包{item["img_name"]}完成')
yield scrapy.Request(item['img_hd'])
# 定义文件名
def file_path(self, request, response=None, info=None, *, item=None):
self.num2 += 1
# print(f"下载{item['img_name'].rar}完成")
file_name = item['img_name'] + '.rar'
# print(f'当前文件名{file_name}')
return file_name
# 返回给下一个即将被执行的管道类
def item_completed(self, results, item, info):
return item
def __del__(self):
print(f'num1一共{self.num1}')
print(f'num2一共{self.num2}')
三、配置文件
3.1 settings
BOT_NAME = 'imageDownload'
SPIDER_MODULES = ['imageDownload.spiders']
NEWSPIDER_MODULE = 'imageDownload.spiders'
# 日志只显示错误日志
LOG_LEVEL = 'ERROR'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# q请求头
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36'
# Obey robots.txt rules
# robots协议
ROBOTSTXT_OBEY = False
# 图片存储路径
IMAGES_STORE = './images'
# 文件存储路径
FILES_STORE = './download'
# item管道
ITEM_PIPELINES = {
# 图片管道
'imageDownload.pipelines.ImgPipeLine': 300,
# 文件管道
'imageDownload.pipelines.RarPipeLine': 301,
}
四、完整代码
4.1 imgae.py
import scrapy
from imageDownload.items import ImagedownloadItem
class ImageSpider(scrapy.Spider):
name = 'image'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://sc.chinaz.com/tupian/rentiyishu.html']
# 分页计数器
page_num = 2
def parse(self, response):
# 拿到每个图片的div
div_list = response.xpath('//*[@id="container"]/div')
# 获取当前的总共页数
page_total = response.xpath("//div[@class='fenye']/a[last()-1]/b/text()").extract_first()
for div in div_list:
# 获取图片的超链接进行
img_href = 'https:' + div.xpath('./div/a/img//@src2').extract_first()
# 获取图片名称
img_name = div.xpath('./div/a/img//@alt').extract_first()
# 获取详情页面的url
content_url = 'https:' + div.xpath('./div/a/@href').extract_first()
# https://scpic1.chinaz.net/Files/pic/pic9/202101/apic30501_s.jpg
# 根据一定的规则将前面获取到超链接进行替换获取到真正的图片地址,当然也可以在详情页面直接获取,可以不用替换
new_href = str.replace(img_href, 'Files', 'files').replace('_s', '')
# 图片高清压缩包
# 创建item对象
item = ImagedownloadItem()
# 图片url传给item
item['url'] = new_href
# 图片名称传给item
item['img_name'] = img_name
# 再次手动请求把详情页面给content_url方法,并且传入item对象
yield scrapy.Request(content_url, callback=self.fileParse, meta={'item': item})
# 分页操作获取pagenum的页码进行拼接
page_url = f'https://sc.chinaz.com/tupian/rentiyishu_{self.page_num}.html'
# 判断当前页码和全局的页面条数是否相等,不相等则进行分页解析下载
if self.page_num != page_total:
# 每次请求之后当前页面数+1
self.page_num += 1
# 递归调用当前的方法进行解析
yield scrapy.Request(page_url,callback=self.parse)
# 获取图片下载地址
def fileParse(self, response):
# 拿到item对象
item = response.meta['item']
# print(response)
# 拿到第一个压缩包的下载地址
filepath = response.xpath("//div[@class='downbody']//div[3][@class='dian']/a[1]/@href").extract_first()
# 讲地址传入给item
item['img_hd'] = filepath
yield item
4.2 items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ImagedownloadItem(scrapy.Item):
# define the fields for your item here like:
# 图片的超链接
url = scrapy.Field()
# 图片和压缩包的名称
img_name = scrapy.Field()
# 图片超清的压缩包
img_hd = scrapy.Field()
4.3 PipeLine.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
from scrapy.pipelines.images import ImagesPipeline
from scrapy.pipelines.files import FilesPipeline
import scrapy
import time
from urllib.parse import urlparse
# class ImagedownloadPipeline:
# def process_item(self, item, spider):
# return item
# 自定义图片下载类
class ImgPipeLine(ImagesPipeline):
num = 0
# 重写父类方法
def get_media_requests(self, item, info):
# 下载请求图片,并将item对象和图片名称等信息传给下一个调用函数file_path
self.num += 1
yield scrapy.Request(item['url'], meta={'item': item, 'url': item['url'], 'img_name': item['img_name']})
# 重写方法,返回新的文件路径
def file_path(self, request, response=None, info=None, *, item=None):
# 获取图片名称拼接
img_name = request.meta['img_name'] + '.jpg'
print(f'�33[35m下载', img_name, '图片完成')
return img_name
# 返回给下一个即将被执行的管道类
def item_completed(self, results, item, info):
return item
def __del__(self):
print(f'图片数量是{self.num}')
# 新建文件类
class RarPipeLine(FilesPipeline):
num1 = 0
num2 = 0
# 重写父类方法
def get_media_requests(self, item, info):
self.num1 += 1
print(f'�33[32m下载超清压缩包{item["img_name"]}完成')
yield scrapy.Request(item['img_hd'])
# 定义文件名
def file_path(self, request, response=None, info=None, *, item=None):
self.num2 += 1
# print(f"下载{item['img_name'].rar}完成")
file_name = item['img_name'] + '.rar'
# print(f'当前文件名{file_name}')
return file_name
# 返回给下一个即将被执行的管道类
def item_completed(self, results, item, info):
return item
def __del__(self):
print(f'num1一共{self.num1}')
print(f'num2一共{self.num2}')