集成学习(ensemble learning)本身不是一个单独的机器学习算法,它是通过构建并结合多个机器学习器来完成学习任务。也就是我们常说的“博采众长”。集成学习可以用于分类问题集成,回归问题集成,特征选取集成,异常点检测集成等等。是近年来非常火爆的机器学习方法。
1.集成学习概述
如图是集成学习的一个概括图。对于训练集数据,我们通过训练若干个个体学习器,通过一定的结合策略,就可以最终形成一个强学习器,以达到博采众长的目的。
集成学习有两个主要的问题需要解决,第一是如何得到若干个个体学习器,第二是如何选择一种结合策略,将这些个体学习器集合成一个强学习器。

2. 集成学习的种类
集成学习的第一个问题就是如何得到若干个个体学习器?
这个个体学习器可以是同一个种类的 ,比如都是决策树个体学习器。也可以不全是一个种类的,比如同时使用支持向量机个体学习器,逻辑回归个体学习器和朴素贝叶斯个体学习器来学习,最终结合程一个强分类器。 但是现在一般应用比较广泛的是同种类(同质)的分类器的集成。
同质个体学习器按照个体学习器之间是否存在依赖关系可以分为两类:bagging系列算法 和 boosting系列算法。
下面就分别对这两类算法做一个概括总结。
(1) bagging
bagging算法中,个体学习器之间不存在强依赖关系,一系列个体学习器可以并行生成。
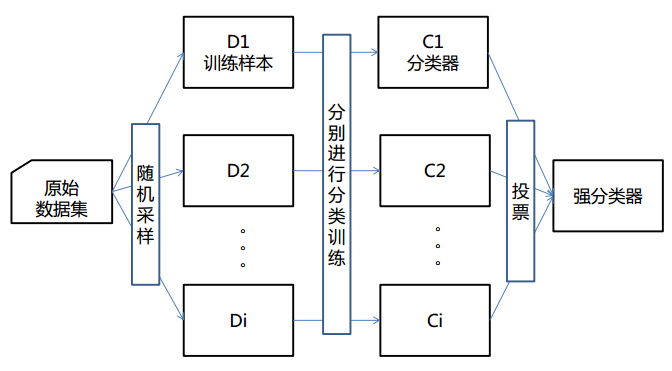
从上图可以看出,bagging的个体弱学习器的训练集是通过随机采样得到的。通过T次的随机采样,我们就可以得到T个采样集,对于这T个采样集,我们可以分别独立的训练出T个弱学习器,再对这T个弱学习器通过集合策略来得到最终的强学习器。
这里的随机采样一般采用的是自助采样法(Bootstrap sampling),是有放回的采样。 对于一个样本,它在某一次含m个样本的训练集的随机采样中,每次被采集到的概率是1/m。不被采集到的概率为(1−1/m)。如果m次采样都没有被采集中的概率是((1−1/m)^m)。当m→∞时,((1−1/m)^m)→1/e≃0.368。也就是说,在bagging的每轮随机采样中,训练集中大约有36.8%的数据没有被采样集采集中。对于这部分大约36.8%的没有被采样到的数据,我们常常称之为袋外数据(Out Of Bag, 简称OOB)。这些数据没有参与训练集模型的拟合,因此可以用来检测模型的泛化能力。
随机森林是bagging的一个特化进阶版,所谓的特化是因为随机森林的弱学习器都是决策树。所谓的进阶是随机森林在bagging的样本随机采样基础上,又加上了特征的随机选择,其基本思想没有脱离bagging的范畴。
(2) boosting
boosting算法中,个体学习器之间存在强依赖关系,一系列个体学习器基本都需要串行生成。
boosting算法主要目标为将弱学习器“提升”为强学习器,大部分Boosting算法都是根据前一个学习器的训练效果对样本点的权重进行调整(提高前一轮中学习误差率高的训练样本点的权重,使得误差率高的点在后一轮的弱学习器中得到更多的重视),再根据新的样本权重训练下一个学习器,如此迭代M次,最后将一系列弱学习器组合成一个强学习器。
Boosting系列算法里最著名算法主要有AdaBoost算法和提升树(boosting tree)系列算法。提升树系列算法里面应用最广泛的是梯度提升树(Gradient Boosting Tree)。
(3) bagging和boosting的区别
1. 个体分类器之间的依赖关系上
- Bagging: 每个弱分类器是独立的,可以并行生成。
- Boosting: 每个弱分类器有强依赖关系,只能串行生成,因为后一个模型参数需要前一轮模型的结果。
2.样本选择上
- Bagging: 每个弱分类器的训练集是在原始集中有放回的选取的,从原始集中选出的各轮训练集之间是独立的。
- Boosting: 每个弱分类器的训练集都是不变的,都为原始集,只是训练中每个样例在分类器中的权重发生变化,而权值是根据上一轮的分类结果进行调整的。
3.样本权重上
- Bagging: 使用均匀取样,每个样本权重是相等的。
- Boosting: 每个样本权重不相等,在每一轮训练中会根据错误率不断调整样例权值,错误率越大的权重越大。
4.集成结果上
- Bagging: 平均或少数服从多数原则,每个弱分类器的权重一般是相等的。
- Boosting: 加权平均,每个弱分类器有相应的权重,对于分类误差小的分类器有更大的权重。
5.优化目标上
- Bagging: 降低方差,提高模型整体的稳定性。
- Boosting: 降低偏差,提高模型整体的精确度。
6.单个评估器效力比较弱的时候
- Bagging: 集成不是很有帮助。
- Boosting: 集成可能一定程度上能提高精度。
7.单个评估器存在过拟合的时候
- Bagging: 一定程度上解决过拟合。
- Boosting: 可能会加剧过拟合。
3. 集成学习的结合策略
假设我们的预测类别是{c1,c2,...cK},对于任意一个预测样本x,我们的T个弱学习器的预测结果分别是(h1(x),h2(x)...hT(x))。
(1)平均法
对于数值类的回归预测问题,通常使用的结合策略是平均法,也就是说,对于若干个弱学习器的输出进行平均得到最终的预测输出。
最简单的平均是算术平均,则最终预测是:
如果每个个体学习器有一个权重w,则最终预测是:
(2)投票法
对于分类问题的预测,我们通常使用的是投票法。
最简单的投票法是相对多数投票法,也就是我们常说的少数服从多数,也就是T个弱学习器的对样本x的预测结果中,数量最多的类别ci为最终的分类类别。如果不止一个类别获得最高票,则随机选择一个做最终类别。
稍微复杂的投票法是绝对多数投票法,也就是我们常说的要票过半数。在相对多数投票法的基础上,不光要求获得最高票,还要求票过半数。否则会拒绝预测。
更加复杂的是加权投票法,和加权平均法一样,每个弱学习器的分类票数要乘以一个权重,最终将各个类别的加权票数求和,最大的值对应的类别为最终类别。
(3) 学习法
集成学习的结合策略中平均或者投票的方法相对比较简单,但是可能学习误差较大。于是就有了学习法这种方法,对于学习法,代表方法是stacking,当使用stacking的结合策略时, 我们不是对弱学习器的结果做简单的逻辑处理,而是再加上一层学习器,也就是说,我们将训练集弱学习器的学习结果作为输入,将训练集的输出作为输出,重新训练一个学习器来得到最终结果。
在这种情况下,我们将弱学习器称为初级学习器,将用于结合的学习器称为次级学习器。对于测试集,我们首先用初级学习器预测一次,得到次级学习器的输入样本,再用次级学习器预测一次,得到最终的预测结果。