1.机器学习概论
1.python基础的准备
本课程拟采用Python做为机器算法应用的实现语言,所以请确保:
1)安装好Python开发环境, PyCharm 或 Anaconda等都可以,按个人习惯喜好。
2)基本库的安装,如numpy、pandas、scipy、matplotlib
3)具备一定的Python编程技能,如果不熟悉,可选择一个教程进行学习,Python简单好上手,资源也很丰富。
菜鸟教程 Python 3 教程 http://www.runoob.com/python3/python3-tutorial.html
廖雪峰的官方网站 Python3 https://www.liaoxuefeng.com/wiki/1016959663602400
2.本周视频学习内容:https://www.bilibili.com/video/BV1Tb411H7uC?p=1
1)P4 Python基础
2)P1 机器学习概论
机器学习是一门多领域交叉学科,涉及较多的数学知识,我们不做太多理论上的要求,如果有听不懂的地方,不要放弃,看一遍就有个印象。通过观看视频,大家对课程有个总体的认识。
建议大家边看边做笔记,记录要点及所在时间点,以便有必要的时候回看。学习笔记也是作业的一部分。
3.作业要求:
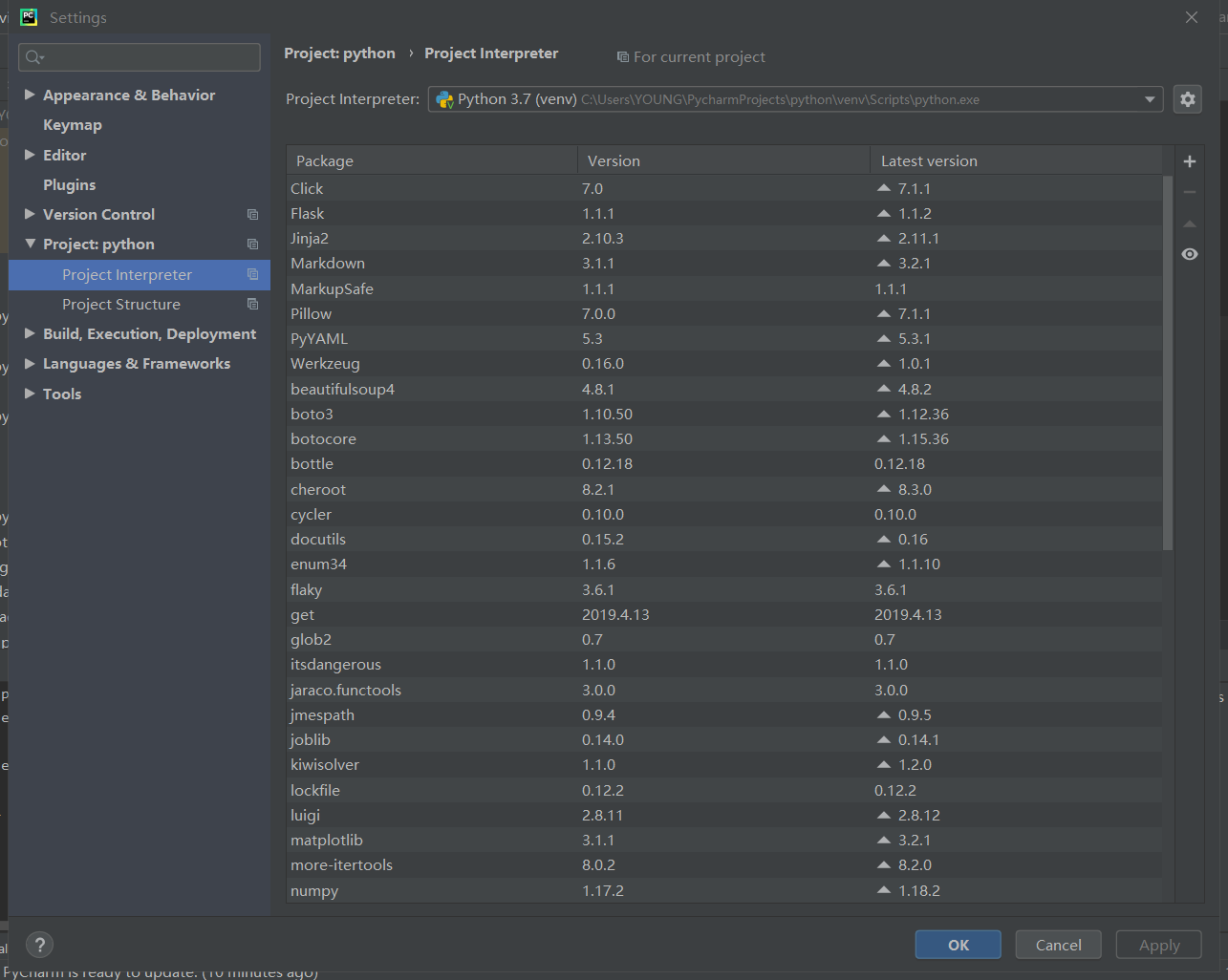
1)贴上Python环境及pip list截图,了解一下大家的准备情况。暂不具备开发条件的请说明原因及打算。


2)贴上视频学习笔记,要求真实,不要抄袭,可以手写拍照。
①切片可以下标索引,也可以T/F来索引

②数据清洗去重

③机器学习方法

3)什么是机器学习,有哪些分类?结合案例,写出你的理解。
机器学习(Machine Learning)是研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演译。
目前机器学习主流分为:监督学习,无监督学习,强化学习。监督学习:监督学习可分为“回归”和“分类”问题。在回归问题中,我们会预测一个连续值。也就是说我们试图将输入变量和输出用一个连续函数对应起来;而在分类问题中,我们会预测一个离散值,我们试图将输入变量与离散的类别对应起来。每个数据点都会获得标注,如类别标签或与数值相关的标签。一个类别标签的例子:将图片分类为「苹果」或「橘子」;数值标签的例子如:预测一套二手房的售价。监督学习的目的是通过学习许多有标签的样本,然后对新的数据做出预测。例如,准确识别新照片上的水果(分类)或者预测二手房的售价(回归)。无监督学习:在无监督学习中,我们基本上不知道结果会是什么样子,但我们可以通过聚类的方式从数据中提取一个特殊的结构。在无监督学习中给定的数据是和监督学习中给定的数据是不一样的。数据点没有相关的标签。相反,无监督学习算法的目标是以某种方式组织数据,然后找出数据中存在的内在结构。这包括将数据进行聚类,或者找到更简单的方式处理复杂数据,使复杂数据看起来更简单。强化学习:Alphago用的就是强化学习,强化学习是一种学习模型,它并不会直接给你解决方案——你要通过试错去找到解决方案。强化学习不需要标签,你选择的行动(move)越好,得到的反馈越多,所以你能通过执行这些行动看是输是赢来学习下围棋,不需要有人告诉你什么是好的行动什么是坏的行动。给我影响最深的就是参加混沌大学的线下课,是AI的重量级人物Michael I. Jordan讲的,其中有一段视频是一个模拟的人,利用强化学习的算法,从站不起来到最后能够正常跑步的过程,而且真正实现的代码连100行都不到,一页ppt而已。总结:目前用到最多是监督学习和无监督学习,尤其是监督学习,因为应用场景多能给公司创造直接价值,如果找工作可以多关注。但是强化学习是未来,因为能学习到的能力没有数据限制。...