作业要求来自于https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2773
1. 下载一长篇中文小说
2. 从文件读取待分析文本
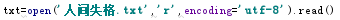
3. 安装并使用jieba进行中文分词
4. 更新词库,加入所分析对象的专业词汇

5. 生成词频统计
6. 排序
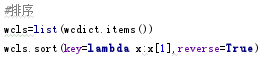
7. 排除语法型词汇,代词、冠词、连词

8. 输出词频最大TOP20,把结果存放到文件里

9. 生成词云
版本一:

版本2:
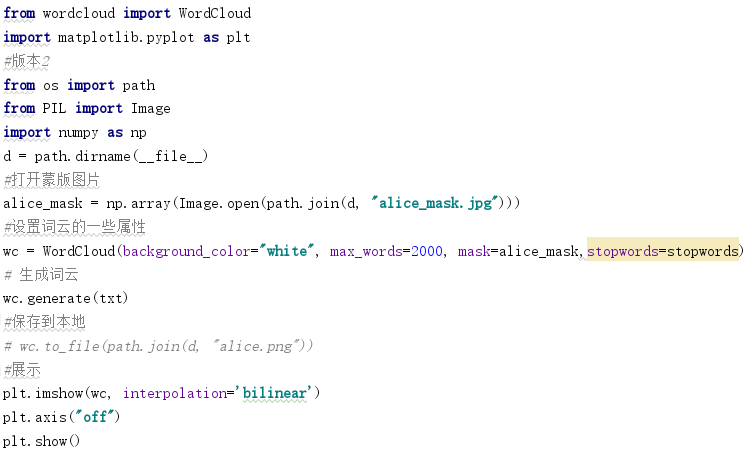
具体代码如下:


import jieba txt=open('人间失格.txt','r',encoding='utf-8').read() #加载停用词表 stopwords = [line.strip() for line in open('stops_chinese1.txt',encoding='utf-8').readlines()] #分词 wordsls=jieba.lcut(txt) wcdict={} for word in wordsls: #不在停用词表中 if word not in stopwords: #不统计字数为一的词 if len(word)==1: continue else: wcdict[word]=wcdict.get(word,0)+1 #更新词库 jieba.add_word('海诺莫钦') jieba.add_word('卡尔莫钦') #排序 wcls=list(wcdict.items()) wcls.sort(key=lambda x:x[1],reverse=True) #输出词频最大TOP20 for i in range(20): print(wcls[i]) #排序好的单词列表word保存成csv文件 import pandas as pd pd.DataFrame(data=wcls).to_csv('人间失格.csv',encoding='utf-8') #词云 from wordcloud import WordCloud import matplotlib.pyplot as plt #版本1 wl_split=' '.join(wcdist)#空格分隔字符串 mywc = WordCloud().generate(wl_split)#生产词云 plt.imshow(mywc)#显示词云 plt.axis("off") plt.show() #版本2 from os import path from PIL import Image import numpy as np #去掉文件名,返回目录 d = path.dirname(__file__) #打开蒙版图片 alice_mask = np.array(Image.open(path.join(d, "alice_mask.jpg"))) #设置词云的一些属性 wc = WordCloud(background_color="white", max_words=2000, mask=alice_mask,stopwords=stopwords) # 生成词云 wc.generate(txt) #保存到本地 wc.to_file(path.join(d, "alice.png")) #展示 plt.imshow(wc, interpolation='bilinear') plt.axis("off") plt.show()
词云结果图:
排序

版本一

版本二
