over() 是一个常用的函数,不管在oralce 还是大数据hive-sql 都支持。最近在看SQL的时候,才发现,自己以前的理解与over()实际使用有一定的偏差。
使用
over(order by xxx) 按照xxx排序进行累计,order by是个默认的开窗函数
over(partition by xxx)按照xxx分区
over(partition by xxx order by xx)按照xxx分区,并以xx排序
一般大家想到的是这几种,其实还有一种
over()
下面将以sum()与 over()结合,举几个例子方便理解。
首先创建一张简单的表(CLIENT):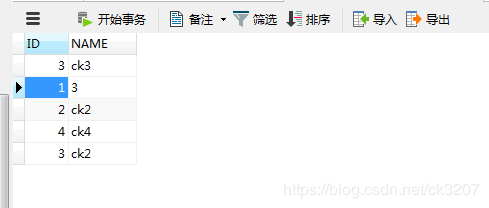
情况一
over(order by xxx)
按照ID排序
SELECT NAME, SUM("ID") OVER(ORDER BY "ID" ) FROM CLIENT;
得到结果:
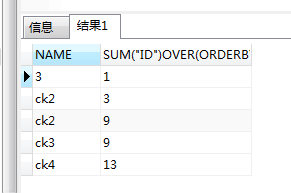
实现逻辑:按照ID升序排序,第N行数据为:第N行相等排序值唯一时,累加第一行至第N-1行值,并加上第N行的数据作为第N行的最终值;第N行相等排序值不唯一时,累加第一行至第N-1行值,并加上第N行的数据*n(n为与第N行相同值的个数)数据作为第N行的最终值;
情况二
over(partition by xxx)
按照xxx分区
SELECT NAME, SUM("ID") OVER(PARTITION BY NAME ) FROM CLIENT;
得到结果:
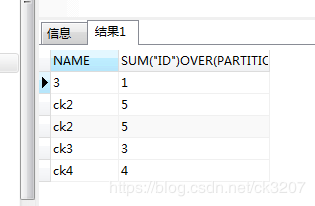
实现逻辑:某个分区的值:按照 NAME 分区,将与NAME相同分区下的值求和;
情况三
over(partition by xxx order by xx)
按照xxx分区,并以xx排序
SELECT NAME, SUM("ID") OVER(PARTITION BY NAME ORDER BY "ID" ) FROM CLIENT;
得到结果:

实现逻辑:如果理解了前两种实现逻辑,那么这种情况其实很容易理解,就是前两种的结合体。先按照情况二按照NAME分区,然后按照情况一处理分区内的数据即可;
情况四
over()
over中为空
SELECT name, SUM("ID") over() FROM CLIENT;
得到结果:
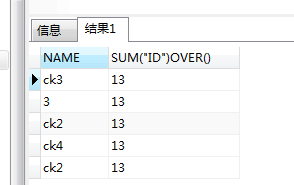
实现逻辑:此时,其实就是对所有ID进行求和而已, 你可认为over()函数不存在一样处理得到值,不同的是,此时会有多条数据,而如果没有over的sum 仅有一条数据,这也正是over函数的一大特点;
窗口函数进阶
讲一讲over窗口函数的其他灵活的用法。即,统计当前行的前N行及后N行数据。
先来看一下数据的组成:
SELECT name, "ID" FROM CLIENT order by "ID";
结果为:
3 1 ck2 2 ck2 3 ck3 3 ck4 4
ROWS BETWEEN CURRENT ROW AND CURRENT ROW
SELECT name, SUM("ID") over(ORDER BY "ID" ROWS BETWEEN CURRENT ROW AND CURRENT ROW) FROM CLIENT;
3 1
ck2 2
ck2 3
ck3 3
ck4 4
此案例下,其实与SELECT name, "ID" FROM CLIENT order by "ID";结果一致。因为数据统计行范围为BETWEEN CURRENT ROW AND CURRENT ROW,即当前行。
ROWS BETWEEN 1 PRECEDING AND CURRENT ROW
SELECT name, SUM("ID") over(ORDER BY "ID" ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) FROM CLIENT;
3 1
ck2 3
ck2 5
ck3 6
ck4 7
此案例下,数据会统计当前行及当前行的前一行数据。PRECEDING为在…之前。
ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING
SELECT name, SUM("ID") over(ORDER BY "ID" ROWS BETWEEN CURRENT ROW AND 1 following) FROM CLIENT;
3 3
ck2 5
ck2 6
ck3 7
ck4 4
此案例下,数据会统计当前行及当前行的后一行数据。FOLLOWING为在…之后。
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
SELECT name, SUM("ID") over(ORDER BY "ID" ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) FROM CLIENT;
3 3
ck2 6
ck2 8
ck3 10
ck4 7
此案例下,数据会统计当前行、当前行的前一行数据及当前行的后一行数据。
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
SELECT name, SUM("ID") over(ORDER BY "ID" ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) FROM CLIENT;
3 1
ck2 3
ck2 6
ck3 9
ck4 13
此案例下,数据会统计当前行之前的所有数据及当前行的数据。注意此SQL执行结果与SQLSELECT name, SUM("ID") over(ORDER BY "ID" ) FROM CLIENT;某些情况下结果是一致的。但当"ID"有重复值时,案例SQL数据到哪行算到哪行,而SQLSELECT name, SUM("ID") over(ORDER BY "ID" ) FROM CLIENT;会统计当前行前的所有数据及与当前行值一样的所有数据。
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
SELECT name, SUM("ID") over(ORDER BY "ID" ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING ) FROM CLIENT;
3 13
ck2 13
ck2 13
ck3 13
ck4 13
此案例下,会统计表中所有数据。与SQLSELECT name, SUM("ID") over() FROM CLIENT;结果无异,只是结果的排序略有不同。
说了这么多使用方法,可我还是不知道怎么用啊?假设有这么一种情况,数据库中有每月公司经营的盈亏额。老板想让你计算下每个月基于上一月是盈利还是亏损?盈利/亏损值是多少?那么此时用上一个over函数,分分钟搞定。
select month, sum(balance) over(order by month rows between 1 preceding and current row) from month_profit_table ; // 假设balance盈利为正,亏损为负