0. 前言
slice 是一种基于数组实现的轻量级数据结构,在slice.go中定义如下:
type slice struct {
array unsafe.Pointer
len int
cap int
}
从定义中可以看到,slice是一种结构体类型,里面有3个元素。array是数组指针,它指向底层分配的数组;len是切片的元素个数;cap是切片的容量。
1. 常见操作
首先来看看Slice的常见操作。
1.1 创建切片
(1) 使用内置的make()函数
// 只指定长度,则默认容量和长度相等,make([]T, len)
s1 := make([]int, 5)
fmt.Printf("type=%T, len=%d, cap=%d
", s1, len(s1), cap(s1)) // []int, len=5, cap=5
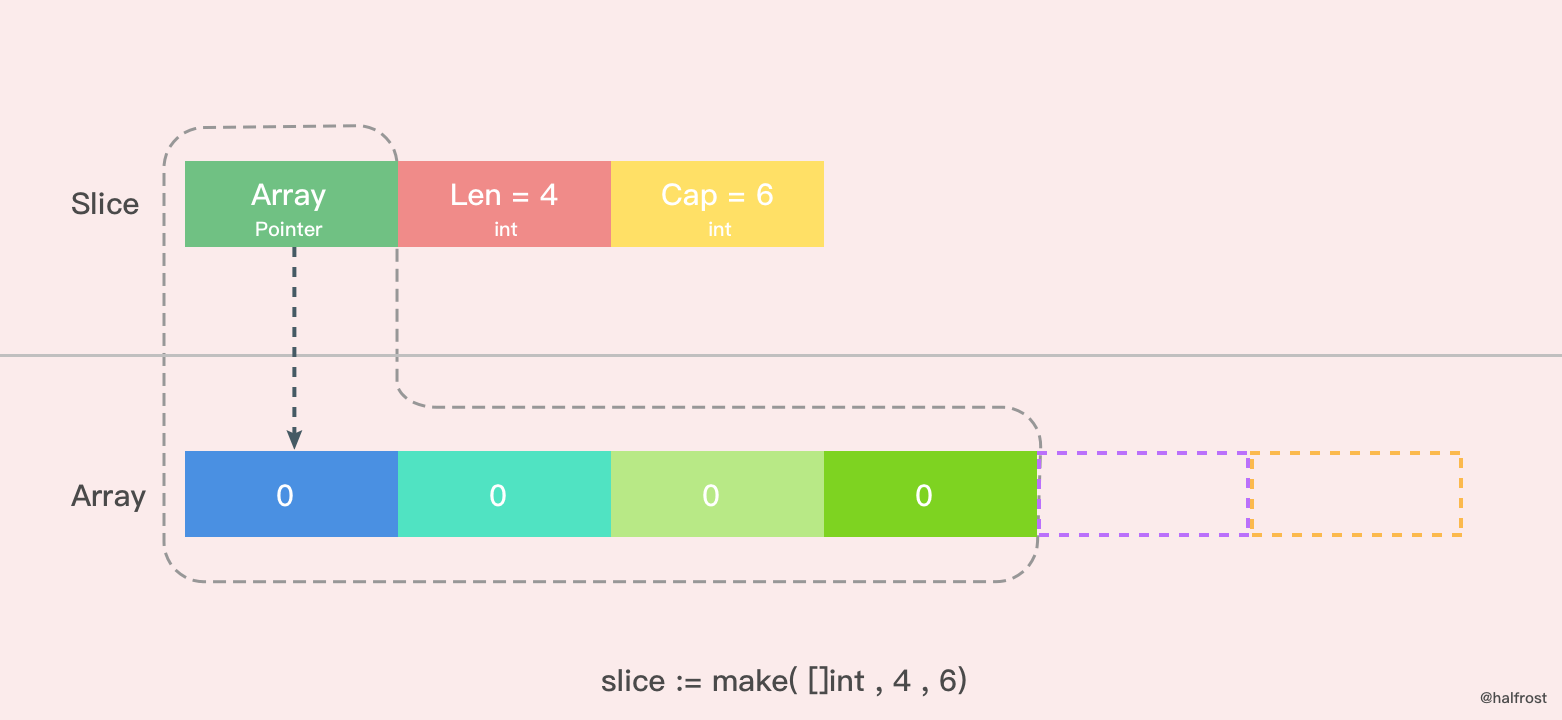
// 指定长度和容量,确保len<=cap,make([]T, len, cap)
s2 := make([]int, 4, 6)
fmt.Printf("type=%T, len=%d, cap=%d
", s2, len(s2), cap(s2)) // []int, len=4, cap=6
示意图如下:
(2) 使用切片字面量
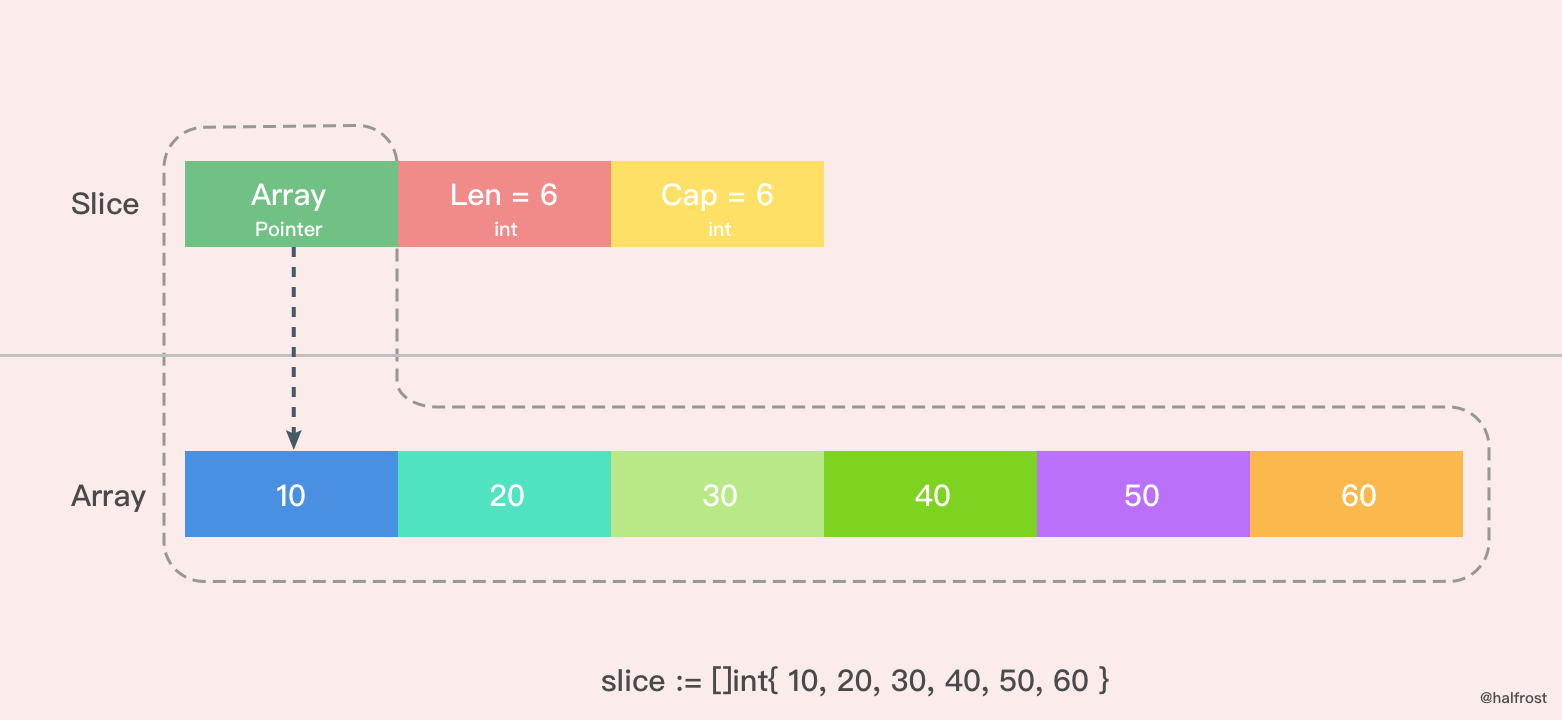
//其长度和容量都是6
s1 := []int{10, 20, 30, 40, 50, 60}
//使用索引声明切片
//下面创建了一个长度为100的切片
s2 := []int{99: 0}
初学时,一定要分清切片和数组的区别。需要注意的是 [] 里面不要写数组的容量或...,因为如果写了个数以后就是数组了,而不是切片了。
示意图如下:
1.2 增加元素
内置的append()用于向slice追加元素。append函数对于理解slice底层是如何工作的非常重要,这里涉及到slice的扩容机制等内容。
s := []int{10, 20, 30, 40, 50, 60}
s = append(s, 33)
1.3 复制切片
使用内置的copy()函数。
s1 := []int{10, 20, 30, 40, 50, 60}
s2 := make([]int, 3)
copy(s2, s1) // s2: 10,20,30
1.4 删除元素
Go语言中没有删除切片元素的内置函数,但是自己实现也是非常简单。比如:
func deleteElement(slice []int, index int) []int {
s1 := slice[:index]
s1 = append(s1, slice[index+1:]...)
return s1
}
2. 切片扩容
2.1 直观认识
首先,通过下面这样一个简单小程序直观的感受一下slice究竟是如何动态变化的?
s := make([]int, 1)
for i := 1; i <= 10; i++ {
fmt.Printf("%v
", s)
fmt.Printf("len=%d, cap=%d
", len(s), cap(s))
s = append(s, i)
}
输出结果如下:
[0]
len=1, cap=1 // 初始化为 make([]int, 1),即len=cap=1
[0 1]
len=2, cap=2 // 向切片中追加第1个数后,出现第1次扩容,此时cap: 1->2
[0 1 2]
len=3, cap=4 // 向切片中追加第2个数,发现容量又不够了,于是第2次扩容,cap: 2->4
[0 1 2 3]
len=4, cap=4 // 向切片中追加第3个数,此时切片中元素为4个,容量正好够,因此不需要扩容
[0 1 2 3 4]
len=5, cap=8 // 向切片中追加第4个数,此时切片中元素为5个,容量又不够了,于是第3次扩容,cap: 4->8
...
从输出结果可以看到,一旦出现切片中的元素个数len大于当前切片的容量cap时,就会出现扩容,并且,新的容量大小变成原来的2倍。
2.2 源码解析
有了这样直观的认识,再从源码的角度探究其内部是如何实现的。
// slice.go
// growslice handles slice growth during append.
// It is passed the slice element type, the old slice, and the desired new minimum capacity,
// and it returns a new slice with at least that capacity, with the old data
// copied into it.
// growslice函数处理向切片追加元素时扩容的问题。
// 调用该函数时,需传入3个参数,分别是切片的元素类型et,旧的切片old以及新申请的容量cap
func growslice(et *_type, old slice, cap int) slice {
...
// 如果新要扩容的容量比原来的容量还要小,这代表要缩容了,那么可以直接报panic了
if cap < old.cap {
panic(errorString("growslice: cap out of range"))
}
if et.size == 0 {
// append should not create a slice with nil pointer but non-zero len.
// We assume that append doesn't need to preserve old.array in this case.
return slice{unsafe.Pointer(&zerobase), old.len, cap}
}
// 这里是关键代码,即“扩容策略”
newcap := old.cap
doublecap := newcap + newcap
// 如果新申请容量(cap)大于2倍的旧容量(old.cap),最终容量(newcap)就是新申请的容量(cap)
if cap > doublecap {
newcap = cap
} else {
// 如果新申请容量(cap) ≤ 2倍的旧容量(old.cap),则又分为两种情况
// case 1: 如果旧切片的长度小于1024,则最终容量(newcap)就是旧容量(old.cap)的两倍
if old.len < 1024 {
newcap = doublecap
} else {
// case 2: 如果旧切片的长度大于等于1024,
// 则最终容量(newcap)从旧容量(old.cap)开始循环增加原来的 1/4,直到最终容量(newcap)大于等于新申请的容量(cap)
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// 如果最终容量(newcap)计算值溢出,则最终容量(newcap)就是新申请容量(cap)
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
// 前面计算出了元素的个数,现在计算根据每个元素的大小,计算需要分配的内存容量
var overflow bool
var lenmem, newlenmem, capmem uintptr
// Specialize for common values of et.size.
// For 1 we don't need any division/multiplication.
// For sys.PtrSize, compiler will optimize division/multiplication into a shift by a constant.
// For powers of 2, use a variable shift.
switch {
case et.size == 1:
lenmem = uintptr(old.len)
newlenmem = uintptr(cap)
capmem = roundupsize(uintptr(newcap))
overflow = uintptr(newcap) > maxAlloc
newcap = int(capmem)
case et.size == sys.PtrSize:
lenmem = uintptr(old.len) * sys.PtrSize
newlenmem = uintptr(cap) * sys.PtrSize
capmem = roundupsize(uintptr(newcap) * sys.PtrSize)
overflow = uintptr(newcap) > maxAlloc/sys.PtrSize
newcap = int(capmem / sys.PtrSize)
case isPowerOfTwo(et.size):
var shift uintptr
if sys.PtrSize == 8 {
// Mask shift for better code generation.
shift = uintptr(sys.Ctz64(uint64(et.size))) & 63
} else {
shift = uintptr(sys.Ctz32(uint32(et.size))) & 31
}
lenmem = uintptr(old.len) << shift
newlenmem = uintptr(cap) << shift
capmem = roundupsize(uintptr(newcap) << shift)
overflow = uintptr(newcap) > (maxAlloc >> shift)
newcap = int(capmem >> shift)
default:
lenmem = uintptr(old.len) * et.size
newlenmem = uintptr(cap) * et.size
capmem, overflow = math.MulUintptr(et.size, uintptr(newcap))
capmem = roundupsize(capmem)
newcap = int(capmem / et.size)
}
if overflow || capmem > maxAlloc {
panic(errorString("growslice: cap out of range"))
}
// 内存分配
var p unsafe.Pointer
if et.ptrdata == 0 { // 看不懂~
p = mallocgc(capmem, nil, false)
// The append() that calls growslice is going to overwrite from old.len to cap (which will be the new length).
// Only clear the part that will not be overwritten.
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
} else {
// Note: can't use rawmem (which avoids zeroing of memory), because then GC can scan uninitialized memory.
p = mallocgc(capmem, et, true)
if lenmem > 0 && writeBarrier.enabled {
// Only shade the pointers in old.array since we know the destination slice p
// only contains nil pointers because it has been cleared during alloc.
bulkBarrierPreWriteSrcOnly(uintptr(p), uintptr(old.array), lenmem)
}
}
memmove(p, old.array, lenmem)
return slice{p, old.len, newcap}
}
以上就是slice扩容的实现,我们主要关注两点:
- 扩容的策略,即增长因子是多少(2倍?还是多少?)
- 扩容后的切片是在原先的地址上追加写入的吗?还是开辟了新的内存空间?
换句话说,我们关注在数量上是如何变化的,在内存空间上又是如何变化的。
关注点1:扩容策略
扩容策略部分的代码还是浅显易懂的,上面的注释已经说的比较清楚了,这里再总结一遍。
-
如果新申请容量(cap) > 2倍的旧容量(old.cap),最终容量(newcap)就是新申请的容量(cap)
-
如果新申请容量(cap) ≤ 2倍的旧容量(old.cap),则又分为两种情况:
-
- case 1:如果旧切片的长度小于1024,则最终容量(newcap)就是旧容量(old.cap)的两倍
- case 2:如果旧切片长度大于等于1024,则最终容量(newcap)从旧容量(old.cap)开始循环增加原来的 1/4,即
newcap=old.cap, for {newcap += newcap/4},直到最终容量(newcap)大于等于新申请的容量(cap),即newcap >= cap。 - 并且在case 2中,要注意累加可能出现的溢出情况,如果最终容量(newcap)计算值溢出,则最终容量(newcap)就是新申请容量(cap)
简单来说,如果切片的元素个数小于1024个,扩容的时候就2倍的增加;一旦元素超过1024个,扩容就按1.25倍的增加。
验证如下:
// case 1
slice := []int{1020:-1}
newSlice := append(slice, 10)
fmt.Printf("Pointer = %p, len = %d, cap = %d
", &slice, len(slice), cap(slice))
fmt.Printf("Pointer = %p, len = %d, cap = %d
", &newSlice, len(newSlice), cap(newSlice))
// 输出
Pointer = 0xc00004e420, len = 1021, cap = 1021
Pointer = 0xc00004e440, len = 1022, cap = 2048
// case 2
slice := []int{1023:-1}
newSlice := append(slice, 10)
fmt.Printf("Pointer = %p, len = %d, cap = %d
", &slice, len(slice), cap(slice))
fmt.Printf("Pointer = %p, len = %d, cap = %d
", &newSlice, len(newSlice), cap(newSlice))
// 输出
Pointer = 0xc000004480, len = 1024, cap = 1024
Pointer = 0xc0000044a0, len = 1025, cap = 1280
从这两个例子中可以看到:
- 当原切片中的元素个数小于1024个时,扩容时会变成原来的2倍(1021 × 2 = 2042 ==> 优化成 2048)
- 当原切片中的元素个数大于等于1024个时,扩容时会变成原来的1.25倍(1024 × 1.25 = 1280)。
关注点2:内存策略
// TODO( 源码理解有困难,分析暂时略)
总的来说,内存策略方面,我们关注的是,在扩容之后,新分配的空间是在原切片的地址之后呢?还是重新申请一块新的地址?
我们举几个例子加以说明,这里有一些坑需要注意。
// case 1
array := [4]int{10, 20, 30, 40}
slice := array[0:2]
newSlice := append(slice, 50)
fmt.Printf("slice = %v, Pointer = %p, len = %d, cap = %d
", slice, &slice, len(slice), cap(slice))
fmt.Printf("newSlice = %v, Pointer = %p, len = %d, cap = %d
", newSlice, &newSlice, len(newSlice), cap(newSlice))
newSlice[1] += 10 // 语句1
fmt.Printf("slice = %v, Pointer = %p, len = %d, cap = %d
", slice, &slice, len(slice), cap(slice))
fmt.Printf("newSlice = %v, Pointer = %p, len = %d, cap = %d
", newSlice, &newSlice, len(newSlice), cap(newSlice))
fmt.Printf("array = %v
", array)
输出:
slice = [10 20], Pointer = 0xc00004e420, len = 2, cap = 4
newSlice = [10 20 50], Pointer = 0xc00004e440, len = 3, cap = 4
slice = [10 30], Pointer = 0xc00004e420, len = 2, cap = 4 // 虽然语句1是对newSlice进行操作,但是slice中的值也被修改了
newSlice = [10 30 50], Pointer = 0xc00004e440, len = 3, cap = 4
array = [10 30 50 40] // 原数组下标为1处的值也被修改了,并且对newSlice的append操作也影响了原数组
这个过程表示如下:

在这种情况下,假设追加的元素个数为n,若当前len+n <= 当前cap,那么不会为新形成的切片分配全新的内存空间,而是把追加的元素直接写入到同一个引用的数组中,从而造成了“牵一发而动全身”的影响。这种情况是非常危险的,因为还有其他切片的底层也引用了这个数组,那么它的值就在未知的情况下被修改了。
还是上面的代码,如果一次性向slice中加入多个元素,使得 当前len+n > 当前cap,那么就会为newSlice开辟新的内存空间,先把slice中的值复制到新的空间上,再执行追加写入操作。此时,slice和newSlice底层引用的不再是同一个数组,使得对newSlice的修改不会影响slice和数组array。验证如下:
// case 2
array := [4]int{10, 20, 30, 40}
slice := array[0:2]
newSlice := append(slice, []int{50, 60, 70}...) // 语句1
fmt.Printf("slice = %v, Pointer = %p, len = %d, cap = %d
", slice, &slice, len(slice), cap(slice))
fmt.Printf("newSlice = %v, Pointer = %p, len = %d, cap = %d
", newSlice, &newSlice, len(newSlice), cap(newSlice))
newSlice[1] += 10 // 语句2
fmt.Printf("slice = %v, Pointer = %p, len = %d, cap = %d
", slice, &slice, len(slice), cap(slice))
fmt.Printf("newSlice = %v, Pointer = %p, len = %d, cap = %d
", newSlice, &newSlice, len(newSlice), cap(newSlice))
fmt.Printf("array = %v
", array)
输出:
slice = [10 20], Pointer = 0xc00004e500, len = 2, cap = 4
newSlice = [10 20 50 60 70], Pointer = 0xc00004e520, len = 5, cap = 8 // 由于语句1追加3个元素,超过了cap,于是要扩容
slice = [10 20], Pointer = 0xc00004e500, len = 2, cap = 4 // 语句2 不影响slice
newSlice = [10 30 50 60 70], Pointer = 0xc00004e520, len = 5, cap = 8
array = [10 20 30 40] // 语句2 也不影响原数组
3. 复制切片
slice.go源码中的拷贝方法有两个,一个是slicecopy(),另一个是slicestringcopy() ,两者的逻辑是一样的,这里对前者进行分析。代码如下。
// 将元素从源切片fm复制到目标切片to,每个元素的大小是width
func slicecopy(to, fm slice, width uintptr) int {
// 如果源切片或者目标切片有一个长度为0,那么就不需要拷贝,直接 return
if fm.len == 0 || to.len == 0 {
return 0
}
// n 记录下源切片或者目标切片较短的那一个的长度
n := fm.len
if to.len < n {
n = to.len
}
// 如果入参 width = 0,也不需要拷贝了,返回较短的切片的长度
if width == 0 {
return n
}
// 如果开启了竞争检测
if raceenabled {
callerpc := getcallerpc()
pc := funcPC(slicecopy)
racewriterangepc(to.array, uintptr(n*int(width)), callerpc, pc)
racereadrangepc(fm.array, uintptr(n*int(width)), callerpc, pc)
}
// 如果开启了 The memory sanitizer (msan)
if msanenabled {
msanwrite(to.array, uintptr(n*int(width)))
msanread(fm.array, uintptr(n*int(width)))
}
// 待拷贝的内存大小
size := uintptr(n) * width
if size == 1 { // common case worth about 2x to do here
// TODO: is this still worth it with new memmove impl?
// 如果要复制的元素仅有一个字节,则直接改变指针即可
*(*byte)(to.array) = *(*byte)(fm.array) // known to be a byte pointer
} else {
// 否则,就把size个bytes从fm.array地址开始,拷贝到to.array地址之后
memmove(to.array, fm.array, size)
}
return n
}
在这个方法中,slicecopy 方法会把源切片值(即 fm Slice )中的元素复制到目标切片(即 to Slice )中,并返回被复制的元素个数,copy 的两个类型必须一致。slicecopy 方法最终的复制结果取决于较短的那个切片。
下面是一个简单的例子。
s1 := []int{1,3,3,4}
array := [...]int{10, 30, 30, 40, 50, 88, 200, 100}
s2 := array[:5]
n := copy(s1, s2)
fmt.Printf("n=%d, s1=%v
", n, s1)
s3 := make([]int, 10)
n = copy(s3, s2)
fmt.Printf("n=%d, s3=%v
", n, s3)
输出如下:
n=4, s1=[10 30 30 40] // 目标切片较短
n=5, s3=[10 30 30 40 50 0 0 0 0 0] // 源切片较短
一个需要注意的问题
说到拷贝,切片中有一个需要注意的问题。先看下面的例子。
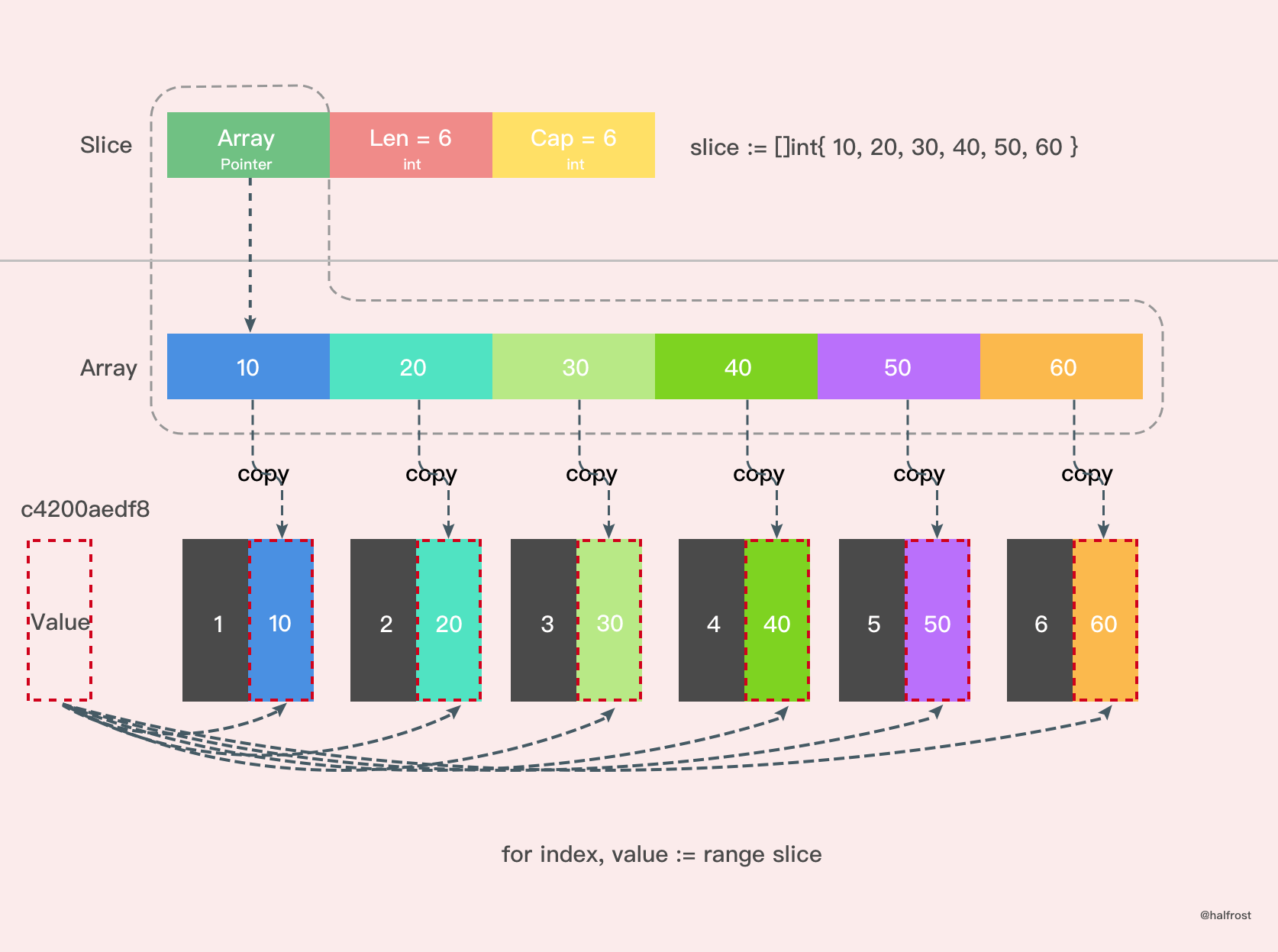
s := []int{1,2,3,4}
for i, v := range s {
fmt.Printf("value=%d, value-addr=%x, slice-addr=%x
", v, &v, &s[i])
}
输出如下:
value=1, value-addr=c000058080, slice-addr=c000056140
value=2, value-addr=c000058080, slice-addr=c000056148
value=3, value-addr=c000058080, slice-addr=c000056150
value=4, value-addr=c000058080, slice-addr=c000056158
从上面的结果可以看到,如果用 range 的方式去遍历一个切片,拿到的 value 其实是切片元素的「拷贝」,而不是「元素本身」,所以每次打印 value 的地址都不变。因此,想要遍历改变切片中的值,需要通过索引的方式,&s[i]才是元素真正的地址。
4. 空切片 vs nil 切片
在使用Go语言的切片时,还需要特别注意empty slice和nil slice的区别,两者看上去很像,但却是完全不同的东西。首先,来看下面这段程序。
// empty slice
s1 := []int{}
s2 := make([]int, 0)
fmt.Printf("s1==nil:%v, len=%d, cap=%d
",s1==nil, len(s1), cap(s1))
fmt.Printf("s2==nil:%v, len=%d, cap=%d
",s2==nil, len(s2), cap(s2))
// nil slice
var s3 []int
fmt.Printf("s3==nil:%v, len=%d, cap=%d
",s3==nil, len(s3), cap(s3))
在继续阅读之前不妨先想一下输出结果会是什么?
ok,下面就是输出结果。
s1==nil:false, len=0, cap=0
s2==nil:false, len=0, cap=0
s3==nil:true, len=0, cap=0
可以看到,不管是nil 切片还是空切片,他们的len和cap都是0,唯独有区别的是,空切片不等于nil,而nil 切片等于nil。前面我们已经知道了切片的数据结构包含3个部分,分别是指向底层数组的指针,len和cap,那么显然,nil 切片和空切片的区别就在于内部指针的不同。来看下面两张图,进一步理解。
4.1 空切片
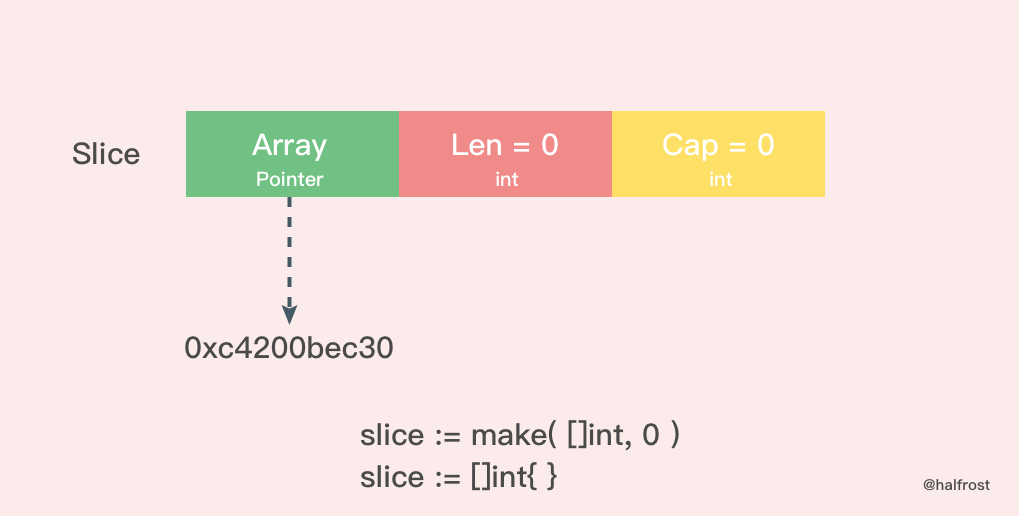
空切片一般会用来表示一个空的集合,比如数据库查询,一条结果也没有查到,那么就可以返回一个空切片。空切片指向的地址不是nil,指向的是一个内存地址,但是它没有分配任何内存空间,即底层元素包含0个元素。
4.2 nil 切片
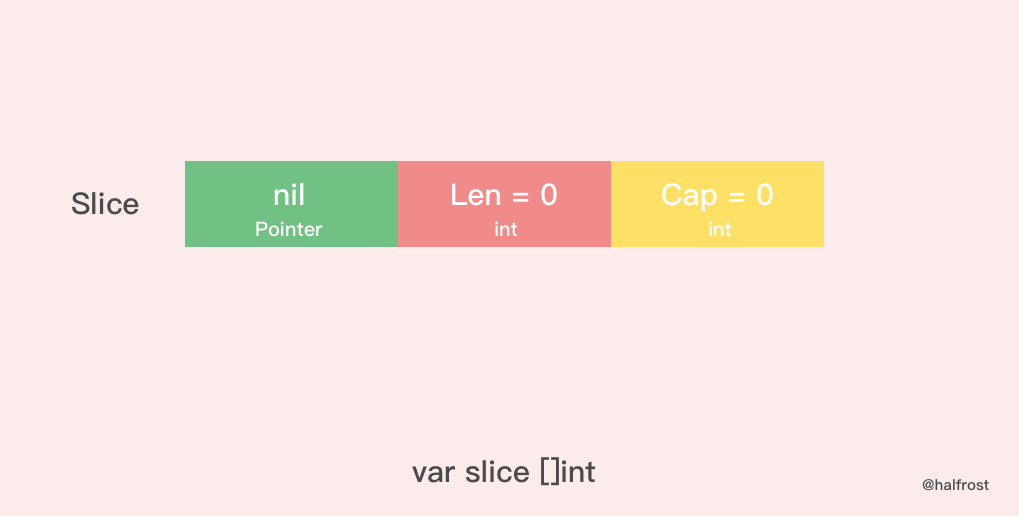
nil 切片的指针就是nil,并不指向某个内存地址。nil 切片被用在很多标准库和内置函数中,描述一个不存在的切片的时候,就需要用到 nil 切片。比如函数在发生异常的时候,返回的切片就是 nil 切片。
5. 总结
- slice 的数据结构?底层实现?slice和数组的区别。
- slice 的基本操作?创建、append、copy等
- 向切片中append元素时的扩容策略?两个关注点,容量大小的计算策略和内存分配策略。
- empty slice 和 nil slice 的区别?
- 关于切片拷贝, range 遍历切片时有一个点需要注意,即
for i, v := range s {...},还有印象吗?
(本文完)
参考: