第0讲 开山篇
读前介绍:本文中如下文本格式是超链接,可以点击跳转
>>超链接<<
我的学习目标:基础要坚如磐石 代码要十份规范 笔记要认真详实
一、java内容介绍
java编程可以分成三个方向
①java se(j2se) 桌面开发
②java ee (j2ee)web开发
③java me (j2me) 手机开发
java SE是基础中的基础
二、java SE课程介绍
java SE 包括以下几个部分
□ java 面向对象编程【核心中的核心,重点中的重点】
□java 图形界面
□java数据库编程 【通过满汉楼系统进行讲解】
□java 文件io流
□java 网络编程 【会拿山寨版的QQ来讲】
□java多线程 【通过坦克大战进行讲解,仔细了解该项目特点】
三、如何学习课程
1、高效而愉快的学习【高效:老师带你,你随着老师走下来】
2、先建立一个整体框架,然后细节
3、用到什么再学什么
4、先know how,再know Why
5、软件编程是一个“做中学”的课程,不是会了再做,而是做了才会
6、适当的囫囵吞枣,不要在某个点抓着不放
7、学习软件编程是在琢磨别人怎么做,而不是我认为应该怎么做的过程
四、java EE课程介绍
①、java EE基础(1)
java面向对象编程、数据库编程(sql server,oracle)————》》java se 【十分十分重要】
②、java EE基础(2)
html、css、JavaScript————》》div+css
③、java ee中级部分
servlet、Jsp————》》mvc模式
④、java ee高级部分
Struts、Ejb、Hibernate、Spring、Ajax(ext,dw2)————》》ssh框架
五、最终目标
最后当我们学完整个体系之后,脑袋里应该形成下图所示的层次模块
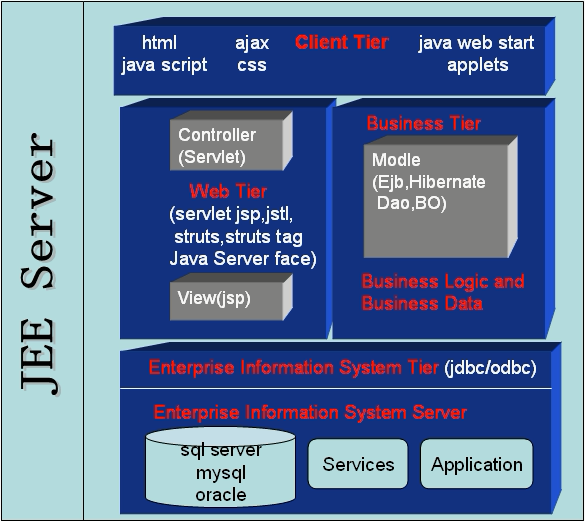
这个体系包括Client(就是用户看到的内容)、Web(服务器端)、Business(业务)、DB(数据库)四部分构成。希望努力学习。
第1讲 内容介绍,项目演示和原理剖析
一、课程介绍
□ java 面向对象编程【核心中的核心,重点中的重点】
□java 图形界面 【图形界面不是java的强项,在图形化界面上Delphi和C++Builder不错,java在后台是强项 】
□java数据库编程 【通过满汉楼系统进行讲解,如果一个项目不和数据库连接起来基本没多大意义】
□java 文件io流 【java如何进行文件操作】
□java 网络编程 【会拿山寨版的QQ来讲,传输的内容如视频,语音,文字和图片等】
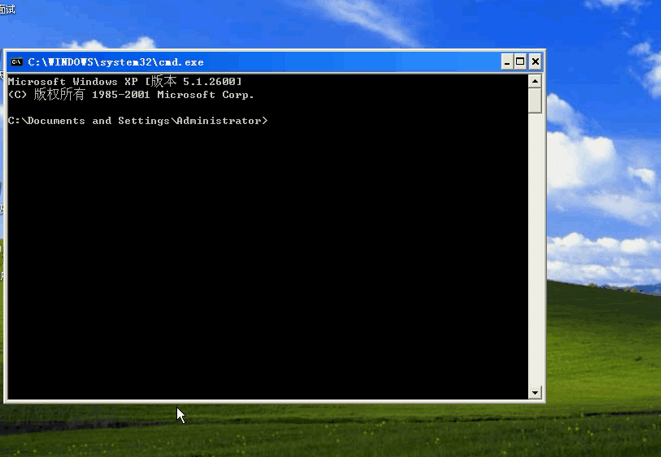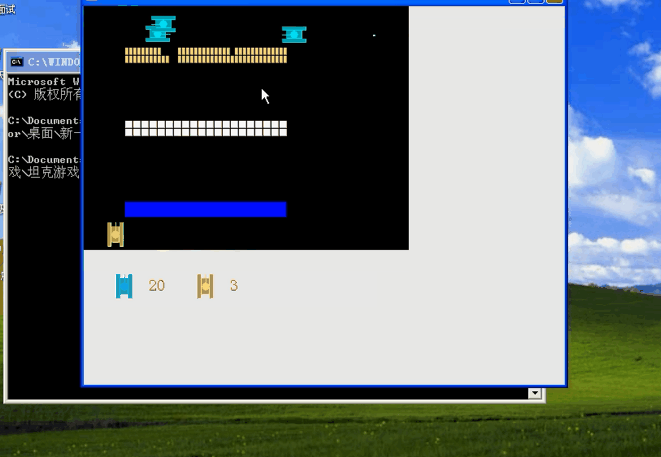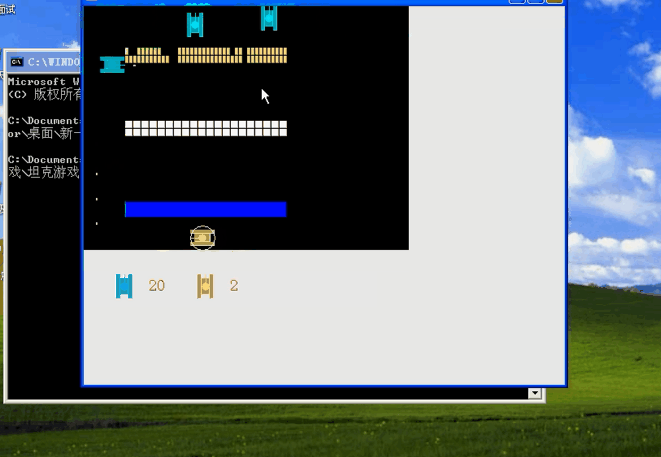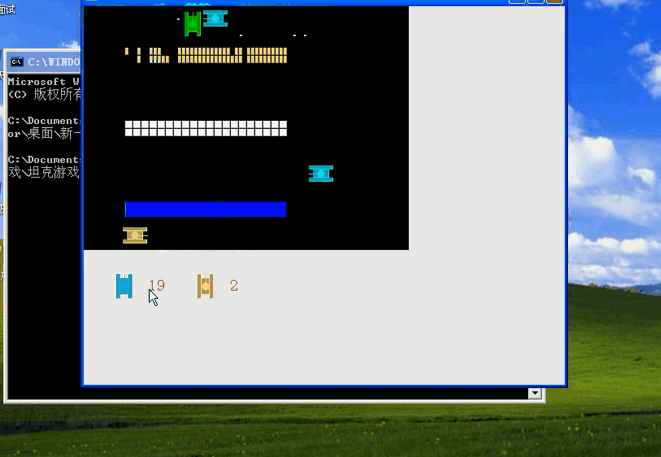
山寨版QQ项目效果演示
□java多线程 【通过坦克大战进行讲解,仔细了解韩老师的该项目特点】
坦克大战项目效果演示【对面向对象和多线程进行学习】
二、java介绍
1、java是什么?
java是一种语言。中国人和中国人之间的交流是依靠汉语,而计算机和人之间依靠的是计算机语言,而java就是众多编程语言中的一个。
编程语言排行榜网址:>>https://www.tiobe.com/tiobe-index/ <<
2019年2月编程语言排行榜(数据来源TIOBE)
| Feb 2019 | Feb 2018 | Change | Programming Language | Ratings | Change |
|---|---|---|---|---|---|
| 1 | 1 | Java | 15.876% | +0.89% | |
| 2 | 2 | C | 12.424% | +0.57% | |
| 3 | 4 |  |
Python | 7.574% | +2.41% |
| 4 | 3 |  |
C++ | 7.444% | +1.72% |
| 5 | 6 | |
Visual Basic .NET | 7.095% | +3.02% |
| 6 | 8 | |
JavaScript | 2.848% | -0.32% |
| 7 | 5 | |
C# | 2.846% | -1.61% |
| 8 | 7 | |
PHP | 2.271% | -1.15% |
| 9 | 11 | |
SQL | 1.900% | -0.46% |
| 10 | 20 |  |
Objective-C | 1.447% | +0.32% |
| 11 | 15 | |
Assembly language | 1.377% | -0.46% |
| 12 | 19 | |
MATLAB | 1.196% | -0.03% |
| 13 | 17 | |
Perl | 1.102% | -0.66% |
| 14 | 9 |  |
Delphi/Object Pascal | 1.066% | -1.52% |
| 15 | 13 | |
R | 1.043% | -1.04% |
| 16 | 10 | |
Ruby | 1.037% | -1.50% |
| 17 | 12 | |
Visual Basic | 0.991% | -1.19% |
| 18 | 18 | Go | 0.960% | -0.46% | |
| 19 | 49 | |
Groovy | 0.936% | +0.75% |
| 20 | 16 | |
Swift | 0.918% | -0.88% |
2、java的产生
首先认识一下java创始人:James Gosling

在1990年,sun公司启动了一个项目计划,叫绿色计划,想写一种语言去控制电视机的机顶盒,当时没有对该语言起名,当时该语言市场不大,于是把这种语言用来控制家用电器,如空调,冰箱洗衣机等进行一定的编程。后来在1992年对该语言起名为oak,因为sun公司在美国硅谷,那里橡树比较多。后来又对语言名称进行更改为silk,但是该名称在美国属于专业术语,由于美国许多程序员喜欢喝咖啡,于是起名为java。在1994年gosling参加了硅谷大会,演示java功能,他当时用java写了一个浏览器,名称是>>HotJava Browser<<,他用他的浏览器输入一个网址一回车出现了一个动态的网页,震惊世界。于是SUN公司搭建了一个FTP服务器把java公开免费下载,java市场得以推广。1995年SUN公司正式把该语言命名为java。
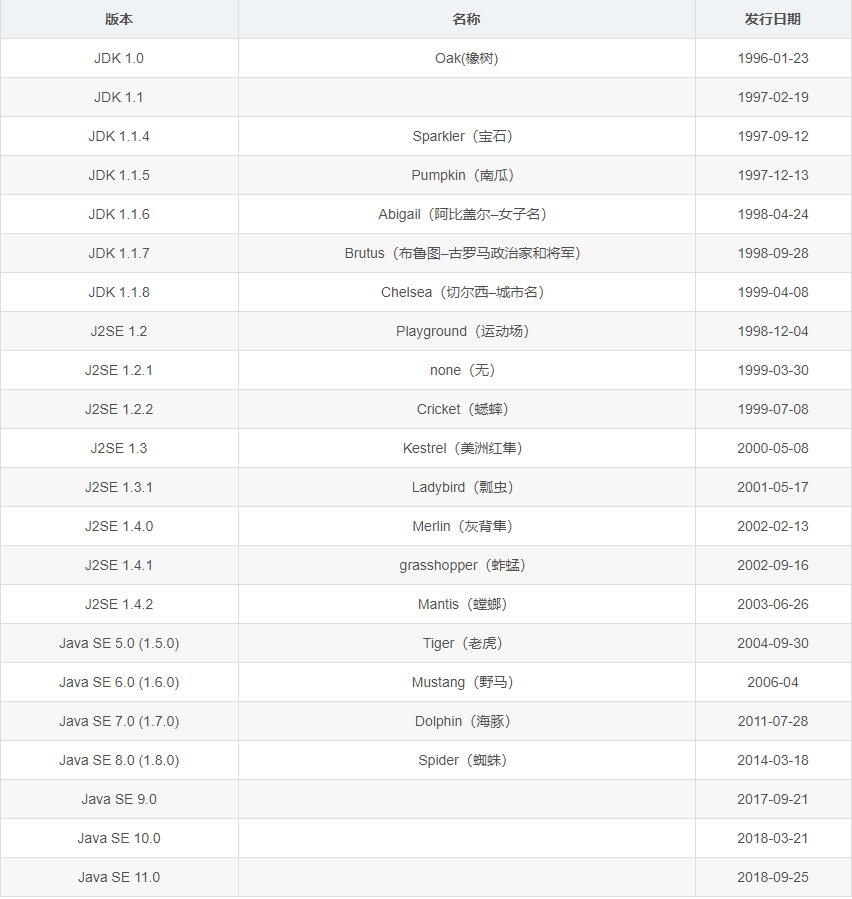
java版本目前(截止到2019年2月21日)更新到11.0版本
历史版本更新情况如下
三、java开发工具的介绍
①、Java开发工具
△记事本
△jcreateor 【已退出历史舞台】
△jbuilder 【也已退出历史舞台】
△netbean
△eclipse【推荐】
各种开发工具的图标如下:

②、如何选择开发工具
学习的开始阶段先选择使用记事本,培养写代码的格式和感觉,当对Java具有一定的了解后在转换成高级开发工具Eclipse。
③、为这么这么选择
①、更深刻的理解Java技术,培养代码感。
②、有利于公司面试。面试的时候公司会要求被面试者用纸和笔把程序写下来。
四、Java语言的特点
□Java语言是简单的
Java语言相对于其他语言来说比较简单。
□Java语言是面向对象的
面向对象的意思目前不好说,只需要记住,在以后的学习中在慢慢体会。
□Java语言是跨平台(操作系统)的【即一次编译,到处运行】
这里首先说明一下,Java语言是跨平台的,但是他的跨平台行依赖于JVM,JVM是不跨平台的【后续了解】。
常见的平台有以下类型

□Java是高性能的
五、第一个java程序(HelloWorld)[通过该案例讲解在java程序运行原理]
1、了解Java的开发运行环境【即JDK[全程Java Development Kit]】。
什么是JDK? 所谓JDK就是Java开发运行环境,包括Java开发工具和Java运行时环境【JRE 全称Java Runtime Environment】,而JRE又包括Java虚拟机【JVM 全称Java Virtual Machine】和Java自带的标准类库【存在于Java安装目录下的lib文件夹中】。在不同平台【即操作系统】有不同的JVM。我们需要根据自己的平台下载与自己平台相匹配的JDK进行安装。
什么是JVM?JVM是Java Virtual Machine(Java>>虚拟机<<)的缩写,JVM是一种用于计算设备的规范,它是在已安装JDK的平台上虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。>>JVM虚拟机拓展阅读
什么是JRE?JRE是Java Runtime Environment(Java运行环境)的缩写,是用于Java程序的运行环境,包括JVM和核心类库。不做开发的平台可以只单独安装JRE来运行Java程序。
总结:我们想要运行一个已有的Java程序,那么只需安装 JRE 即可。 我们想要开发一个全新的Java程序,那么必须安装 JDK ,其内部包含 JRE 。
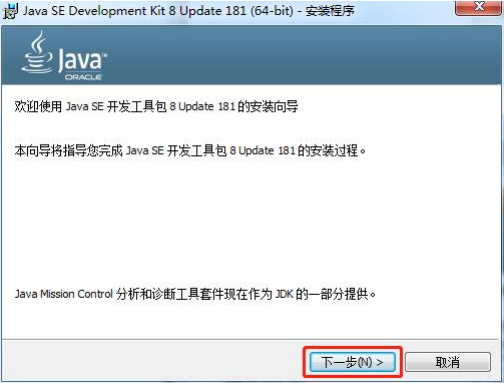
2、安装JDK
1、下载JDK
JDK的下载网址为:>>点击跳转至JDK下载页<<
该页面【跳转后的官网页面】提供JDK不同版本的下载,本人下载的是JDK8.0的.exe安装程序,在下方的安装中以JDK8.0的安装作为安装流程的讲解【本人平台WIndows版本,64位系统】。
2、安装JDK
第一步、双击下载后的安装程序,在出现的窗口中点击"下一步"。
第二步、安装路径
此处的安装路径务必记住!!!!默认路径为黄色方框的路径,可以不更改,直接点击下一步,如需更改安装路径可点击红色方框的更改按钮,此处我安装时选择了更改安装路径。务必注意!

点击更改按钮后会出现下方的对话框,下方为我修改后的安装路径,此路径记下,作为配置环境变量的参数。
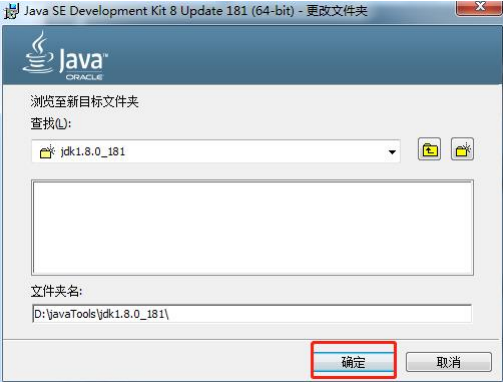
高能提示:安装路径中,建议不要包含中文和空格。jre可以不用安装了,原因是JDK中已经包含了jRE。
后续操作都是点“确定”或者“下一步”,傻瓜操作不再赘述。
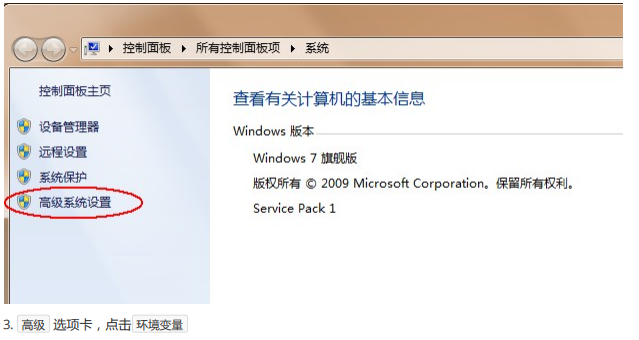
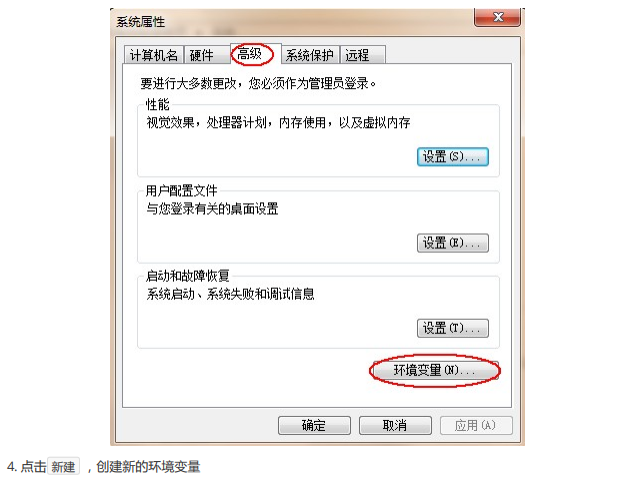
3、配置环境变量
1、为什么要配置环境变量
开发Java程序,需要使用JDK中提供的工具,工具在JDK 1.8安装目录的 bin 目录下。在DOS命令行下使用这些工具,就要先进入到JDK的bin目录下,这个过程就会非常的麻烦。不进入JDK的 bin 目录,这些工具就不能使用,会报错。为了开发方便,我们想在任意的目录下都可以使用JDK的开发工具,则必须要配置环境变量,配置环境变量的意义 在于告诉操作系统,我们使用的JDK开发工具在哪个目录下。
2、如何配置环境变量
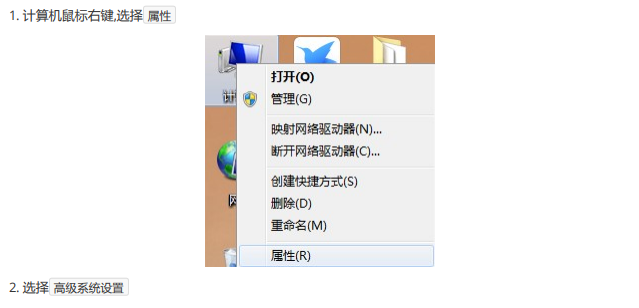
①、Windows7/8版本
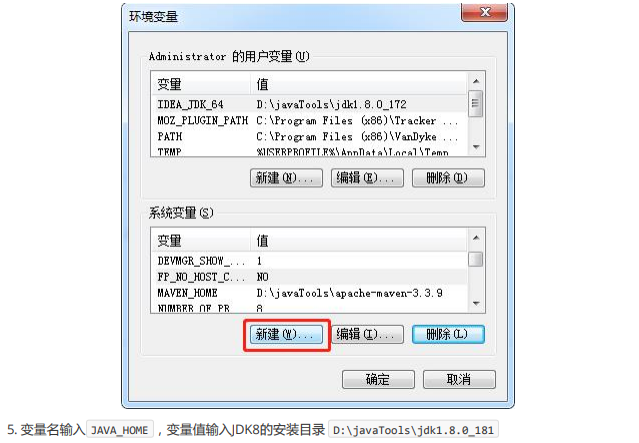
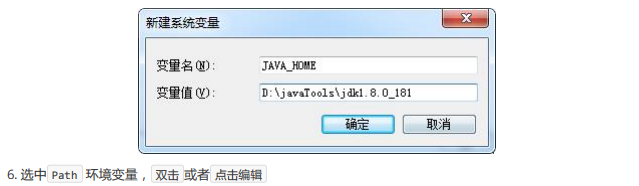
此处的安装目录务必是你自己的安装目录
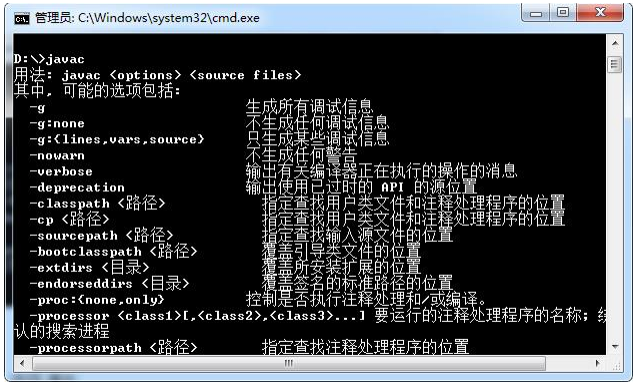
如果运行javac之后出现以上一大段内容,恭喜你Java的安装和配置已经成功!
②、Windows 10版本
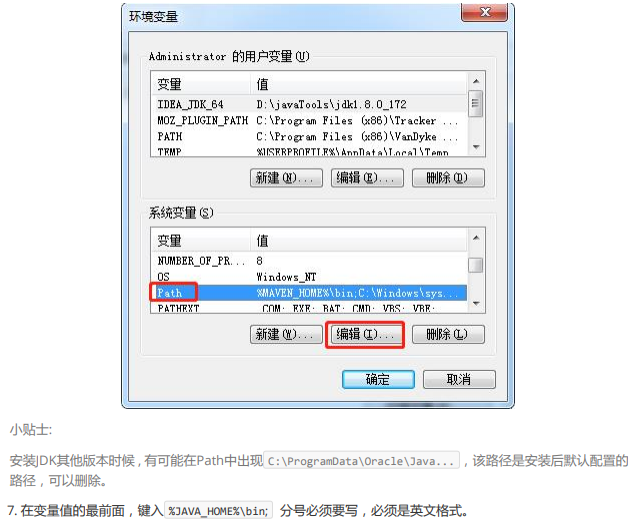
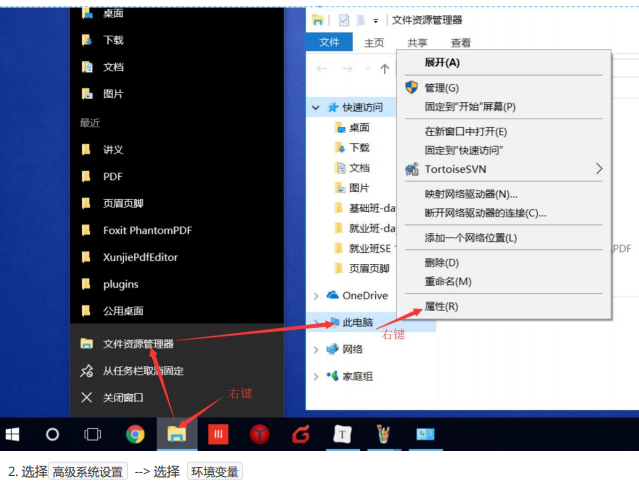
1. 文件资源管理器 --> 此电脑鼠标右键 --> 选择 属性【或者在电脑桌面上的“此电脑”【注意:桌面上的此电脑图标左下角务必不能有箭头】右键选择属性再或者在键盘上同时按下“Windows按键”+E,在出现的对话框左侧找到“此电脑”然后在上面右键选择属性。】
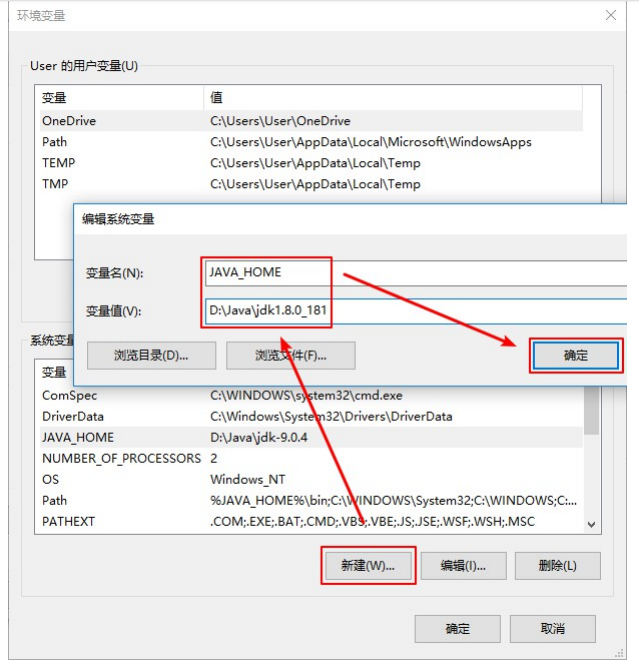
 此处的安装目录务必是你自己的安装目录。
此处的安装目录务必是你自己的安装目录。

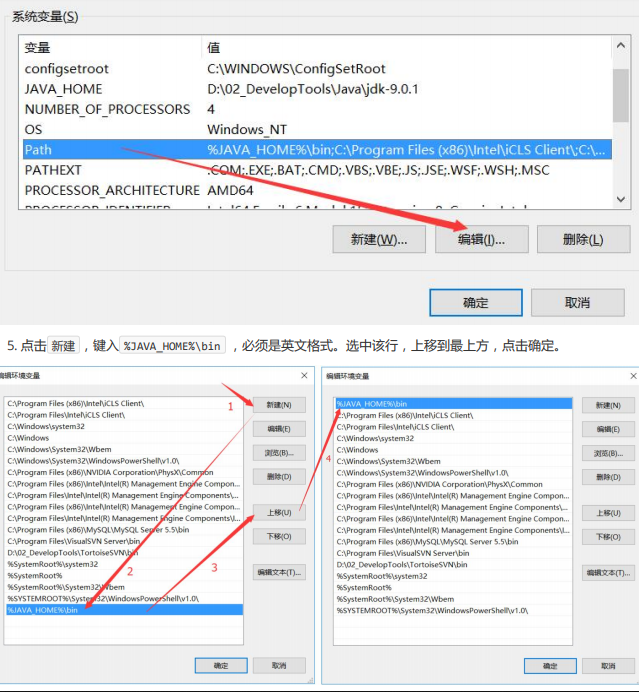

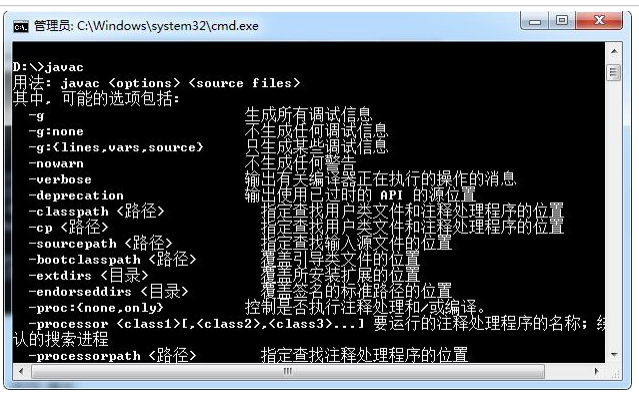
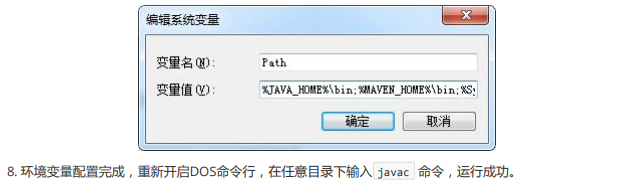
如果运行javac之后出现以上一大段内容,恭喜你Java的安装和配置已经成功!
4、JDK再解释
JDK中包含JRE和Java的工具,Java的编译器javac.exe和Java的解释器java.exe,在java的类库中有3600多个类,但是我们常用的类有150个,我们只需把这150个类掌握就可以成为java大神。另外配置环境变量的目的是为了告诉系统我们的JDK安装在了那里,当我们在CMD控制台进行调用开发工具和运行工具的时候系统可以及时找到并相应。
CMD控制台在哪里?我们可以同时按下“windows”+“R”,然后在出现的窗口中输入cmd,然后点击回车。就进入了cmd控制台了。

5、开始编写程序HolleWorld.java
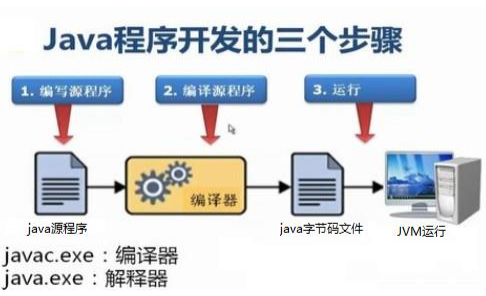
开发环境已经搭建完毕,可以开发我们第一个Java程序了。 Java程序开发三步骤:编写、编译、运行。
现在我们用记事本写我们第一个java程序————HolleWorld.java
我们在自己的硬盘(D、E、F等那个盘都行)根目录下新建一个文件夹,起名为exercise,作为自己以后java的练习文件夹,并在该文件夹中新建一个记事本文件。然后把.txt的拓展名修改为.java。

然后用记事本打开,编写如下内容。
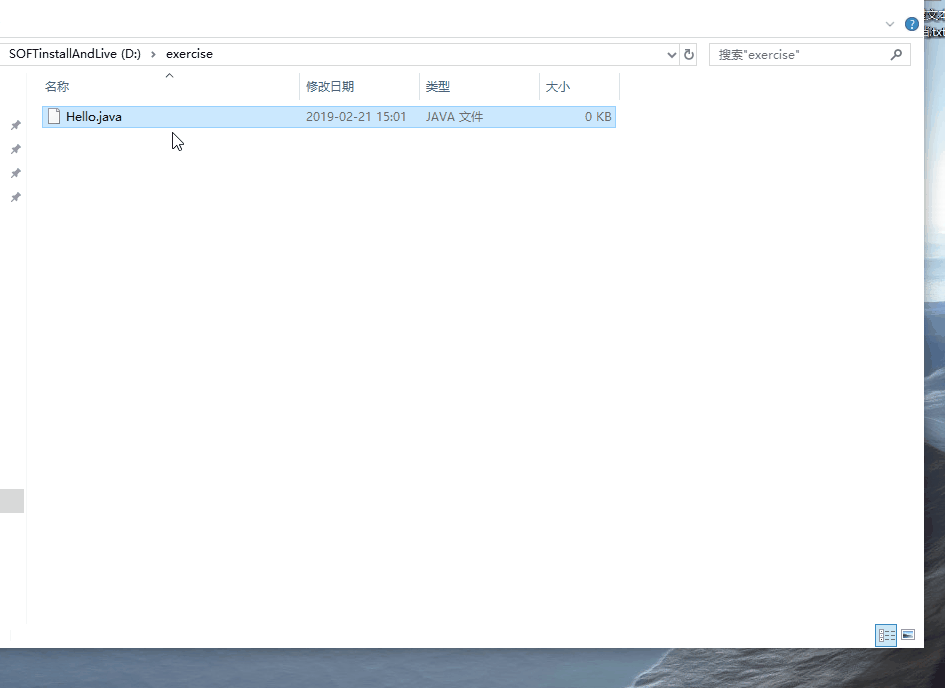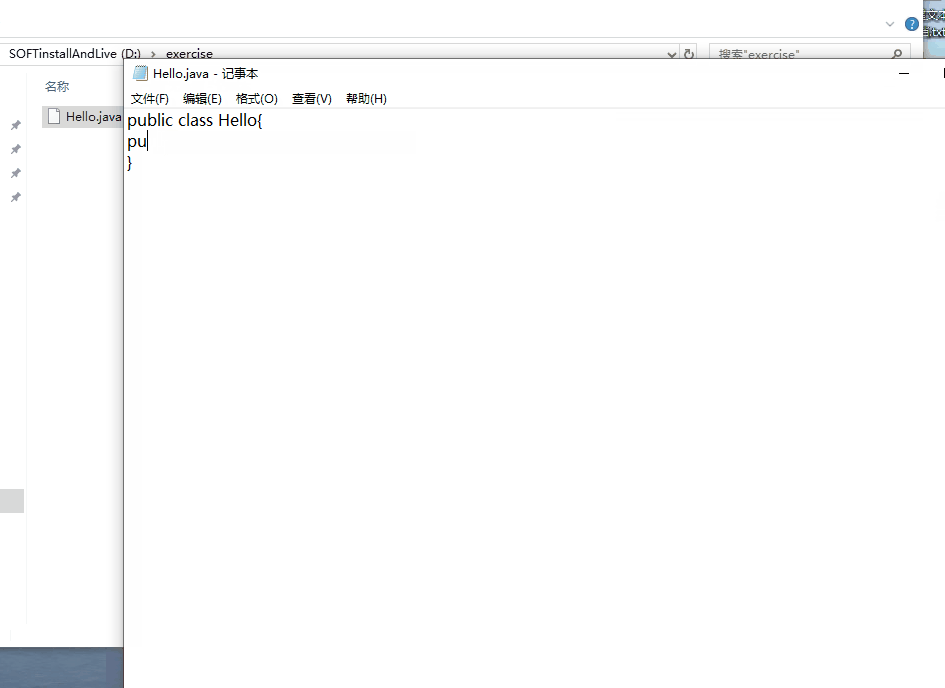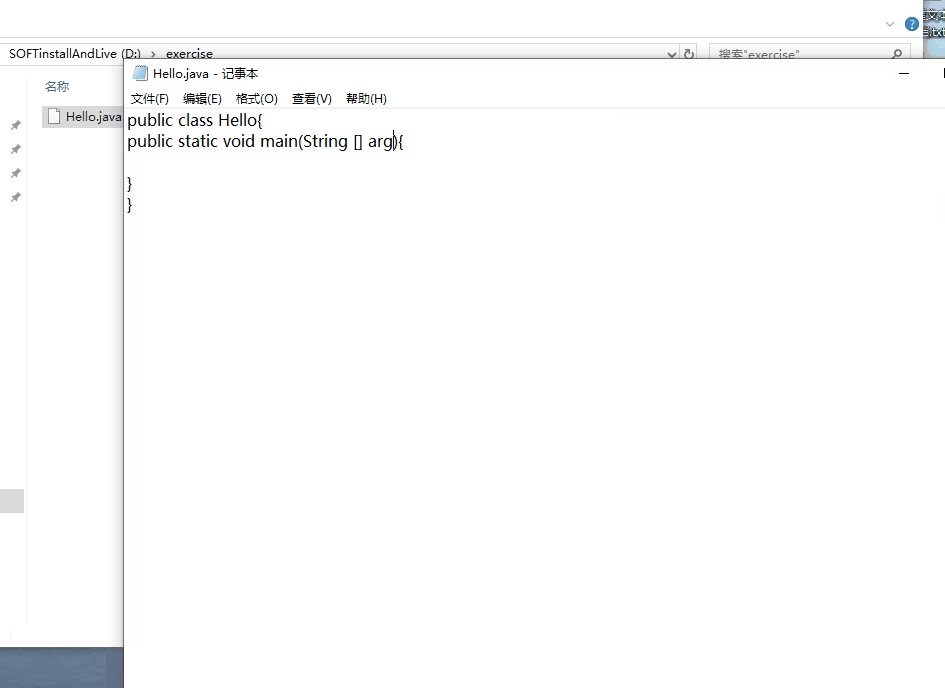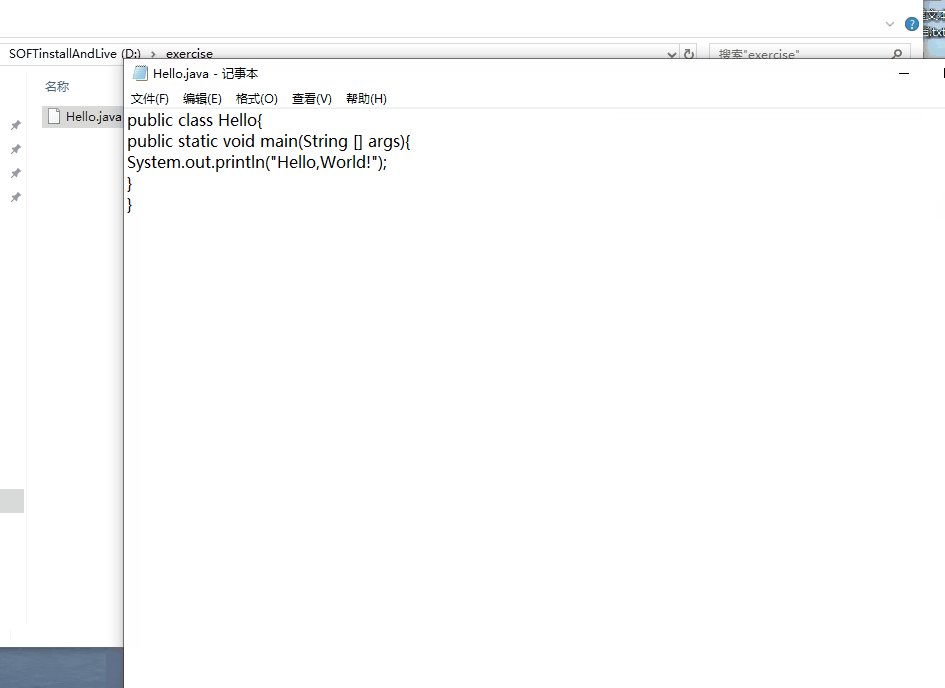
public class Hello { public static void main(String[] args) { System.out.println("Hello World!"); } }
按照如下图所示方法【在Hello.java所在的路径下输入cmd然后回车】进入cmd控制台,此时的路径就是Hello.java文件所在的路径,然后按照如图所示的过程输入命令就可以运行该java程序,输出Hello,World!【小技巧:在控制台输入当前路径下的文件名时,当输入文件名的前几个字母可以使用Tab键进行补全。】
拓展了解:关于java中类的命名和文件的命名规范请查看>>java类的命名规则与规范<<【在第4讲中是重点】
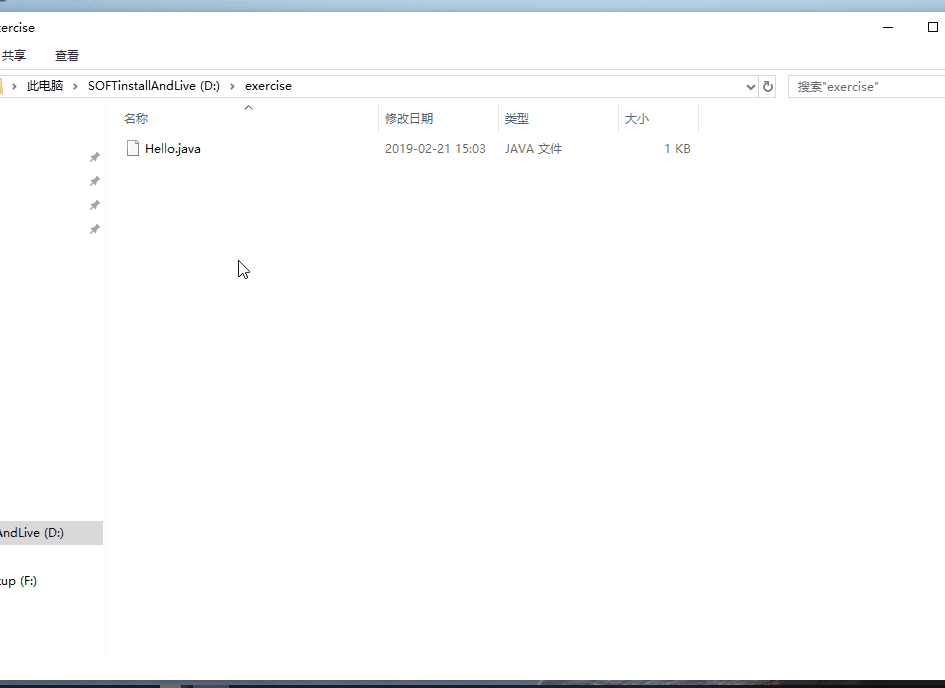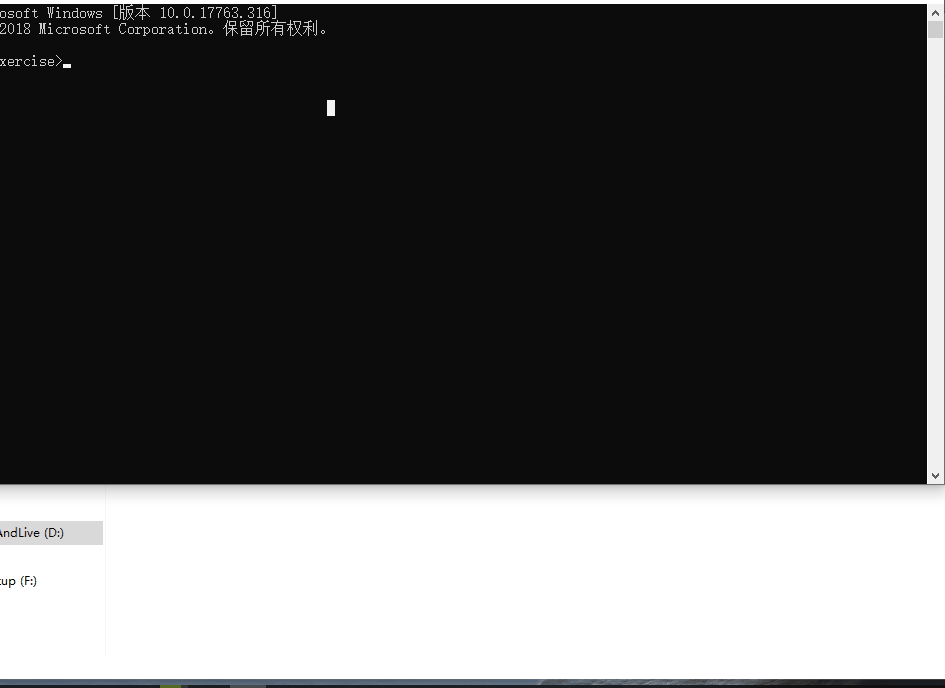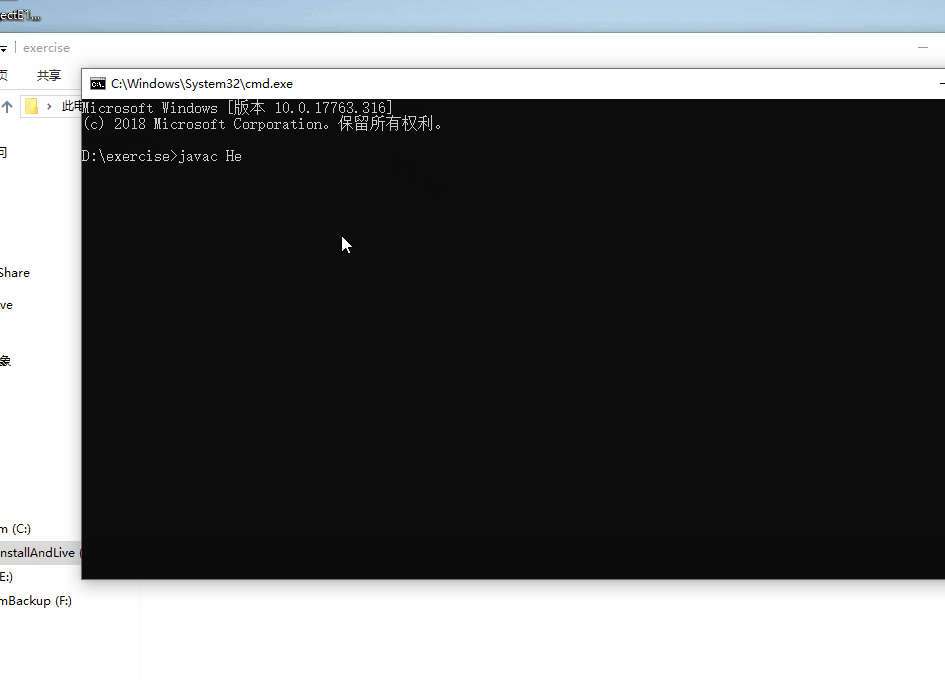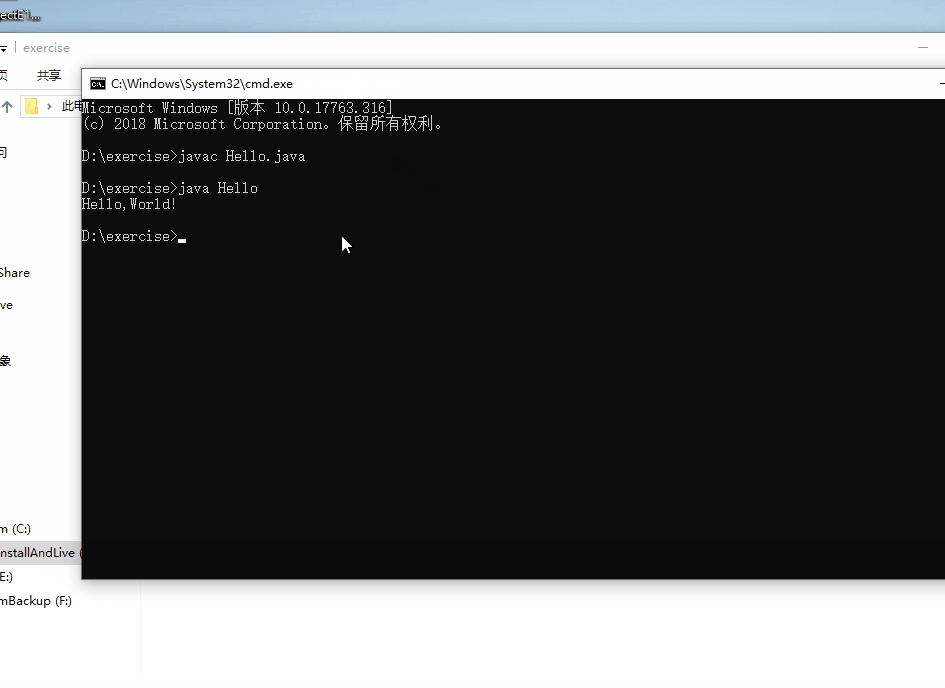
至此,第一个java程序编写完成。从此你就不是小白了!欢迎进入java世界。
6、java的基本语法(1)
我们编写程序时一般不是只写代码的,还要在代码中添加注释,增强代码的可读性,容易理解。所以上方的代码添加注释后就是下面这个样式
public class Hello {
public static void main(String[] args) { //作者:Alvin //功能:打印输出Hello World! //时间:2019年2月21日 System.out.println("Hello World!"); } }
上方代码中,双斜杠//后面的文字都是注释内容,java中添加注释的方法共有三种,分别是
①、//行注释,我是注释内容
②、/*
块注释,我是注释内容
*/
③、/**
*文档注释,我是注释内容
*/
一般注释写在功能代码的上方,注释是给人看的,不是给机器看的,机器在编译的时候直接跳过注释。
在使用javac命令进行编译Hello.java文件时,javac.exe会把Hello.java文件编译成Hello.class文件【即字节码文件】,然后通过java命令利用java.exe解释器执行java文件加载到虚拟机运行。
java程序在运行的时候总是从main方法开始,也就是说main方法是程序执行的入口。
说明:java程序如果运行一定是从main方法开始,main方法不一定要放在public修饰的公共类中,也就是说包含main()的类如果运行不一定要是public修饰的类。
【拓展阅读】
《深入jvm第二版》中有这样一句话:java虚拟机实例通过调用某个类的main()来运行一个Java程序,而这个main()必须是public static void 并接收一个字符串数组作为参数,任何拥有这样一个main()的类都可以作为java程序的起点。并没有说拥有main()方法的类一定要是public类。
在java文件中,如果拥有public类,则该文件的文件名务必和该类完全相同。
java程序在编写的时候,java文件的文件名(如Hello.java)一定要和文件中public修饰的类类名一致,即图中的两个名称一致。
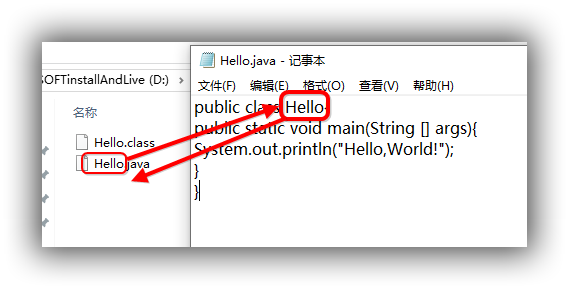
否则java编译时会出错,无法通过。
对于目前程序中出现的单词解释如下
public :表示这个类是公共的,一个java文件中只能有一个public类
class :表示这是一个类
Hello :类名(公共类的类名必须和文件名一致)
main :一个主函数,相当于是程序的入口
第2讲 变量、数据类型
一、问题引入
①、首先看一个程序
/* * 作者:Alvin * 功能:计算两个数的和 * 时间:2019年2月21日15:58:06 * *********************************************** * public :表示这个类是公共的,一个java文件中只能有一个public类 * class :表示这是一个类 * Hello :类名(公共类的类名必须和文件名一致) * main :一个主函数,相当于是程序的入口 */ public class AddCalculate { //一个主函数,相当于程序的入口 public static void main(String[] args) { //定义一个变量,变量名为a,它的值为10 int a=10; //定义一个变量,变量名为b,它的值为20 int b=20; //定义了一个变量,变量名为result,它的值是a+b的和 int result=a+b; //输出结果 System.out.println("结果是:"+result); } }
上方代码执行后输出的内容如下图

②、然后我们了解一个概念————内存。

每个计算机中都有内寸,而计算机中的程序都必须被加载到内存中才能会被执行。所以我们如果要让计算机帮助我们处理问题就必须把问题抽象成数学模型然后加载到内存中通过CPU的计算帮助我们解决。
在本讲开头的程序中,程序中的如下语句
//定义一个变量,变量名为a,它的值为10 int a=10; //定义一个变量,变量名为b,它的值为20 int b=20; //定义了一个变量,变量名为result,它的值是a+b的和
int a=10 的作用就是请求系统从内存中获得一定大小的内存空间,并且给这个内存空间起名为a,并把10这个数字存入到内存中。同理int b=20 的作用也是这样。
语句
//定义了一个变量,变量名为result,它的值是a+b的和 int result=a+b;
的作用也是请求系统从内存中分配一个内存空间并起名为result,同时把a这块内存空间的值和b这块内存空间的值求和得到的数的大小存入到result而a,b这两块内存中的值保持不变。
所以,类似于上面这样的语句就是请求内存并给该内存起一个别名且存储数据到请求到的内存中。
我们再看个程序
/* * 作者:Alvin * 功能:对同一块名称为a的内存存储不同的数值 * 时间:2019年2月21日16:40:55 * *********************************************** * public :表示这个类是公共的,一个java文件中只能有一个public类 * class :表示这是一个类 * Hello :类名(公共类的类名必须和文件名一致) * main :一个主函数,相当于是程序的入口 */ public class AddCalculate { //一个主函数,相当于程序的入口 public static void main(String[] args) { //定义一个变量,变量名为a,它的值为10 int a=10; //打印a内存中存储的数值 System.out.println(a); //把20存入到名字为a的内存中 a=20; //打印a内存中存储的数值 System.out.println(a); } }
上方代码的执行结果为
10
20
说明内存分配给a的这块空间是可以存储不同数值的,但如果a重新存储了其他数值则原来的数值会被覆盖掉。我们可以直接用字母a打印出其所表示的内存中的数值,说明a可以认为是一个数量,并且在前后两次数值存储后当我们的输出的都是a的情况下数值改变了,说明a是一个变化的数量,我们称为变量
总结:上方在向系统申请内存的过程【即int a语句】称为定义变量,在向获得的内存中存储数据的过程【即语句a=10】称为:赋值
二、提出问题
1、为什么有变量?
我们应该首先知道程序是用来解决生活实际问题的,所以说程序是在现实生活中抽象出来的数学物理模型的基础上进行编写的。而现实生活又是一个动态的世界,不是一副静态的画,所以抽象的数学物理模型在表达动态的量的时候也是用变量表示的,程序员再把模型转换成程序的时候也就必须使用变量去呈现表达,通过变化的量来表达固定的数学物理模型。
当然、在数学物理模型中还存在一些固定不变的量,像圆周率3.1415926,像普朗克常量等,这些量称为常量。
并且变量是任何编程语言的基本组成单位。变量是用来帮助系统在内存中分配多大的和什么结构的内存。
2、所有变量都是一样的么?
不是,java基本数据类型有四大变量类型

3、为什么要分数据类型?
程序在请求系统分配内存空间的时候,为了避免造成内存浪费,保证有限的内存空间合理使用,又为了存储在内存中的数据安全,不允许一个变量名去取用其他内存空间的数据,还有其他因素,所以制定了不同的数据类型让系统分配规定大小和类型的内存空间。
假如用来存储一个人的年龄,使用int类型[现在不用明白为什么,后面会讲解]的变量就可以,而用来存储一个人的身份证号码使用int类型的变量就不可以了,因为18位身份证号码数据长度大大超过了int所能存储的数据长度。
所以规定数据类型是为了在系统分配内存时能够对不同数据类型分配请求分配不同大小的内存空间。
4、 不同数据类型在内存中分配的大小是多少?
计算机基础知识拓展【不懂也没关系】 我们知道,通常 电路开关在开、合时电灯亮、灭,则电路开关可以用0、1进行表示,而 电路开关在开、合下电灯灭、亮,则电路开关可以用1、0,我们称这种电路为非电路【电路情形开关合灯泡并联】。 类似的还有当电路两开关为串联是开关全部合上时电灯亮的电路称为与电路,还有当电路两开关为并联时开关有一个合上时电灯亮的电路称为或电路等 内存中是这些成千上万个电路相CU互结合而成。内存上有很多逻辑电路的电平输入点,每一个点的一个0或1表示一位。计算机CPU处理来自于内存中的数据。
数据在计算机中存储是以补码【后续会详细说明】的方式在内存中存储的。
计算机计算加减乘除其实都是按照加法来进行运算的。 人为规定:在计算机中 1 Byte=8bit【即8位】 1KB=1024Byte 1MB=1024KB 1GB=1024MB 1TB=1024GB 1PB=1024TB 1EB=1024PB
在问题2中,我们知道,java的基本数据类型有四种,分别是
整型、浮点型、布尔型、字符型
下面详细介绍各个类型的精度(存储大小范围)和详细分类
①、整型
整型变量包括四种整型类型,关于数据长度和大小范围详见>>内容扩展模块①
| 类型名 | 占用内存大小 | 保存数据大小范围 | 最大保存整数的长度 |
| byte | 1B | -128~127 | 3 |
| short | 2B | -12768~12767 | 5 |
| int | 4B | -2147483648~2147483647 | 10 |
| long | 8B | -9223372036854775808~9223372036854775807 | 19 |
一个整数在未加说明的情况下系统会默认为int类型。
②、浮点型
关于浮点数在内存中的存储以及精确位数详见>>内容扩充模块③<<
| 类型名 | 占用内存大小 | 保存数据大小范围 | 最大能精确保存的长度 |
| float | 4B | -3.40E+38 ~ +3.40E+38 | 绝对保证6位,有效数字7位 |
| double | 8B | -1.79E+308 ~ +1.79E+308 | 绝对保证15位,有效数字16位 |
一个浮点数在未加说明的情况下,系统默认为double类型。典型案例:float f=2.3;编译时会报错,因为2.3是double类型不能赋值给float【原因后面会讲】,此时需要在小数后面加一个大写或者小写的F,即float f=2.3f;
③、布尔型
boolean型变量只有true和false两种值。具体boolean类型的变量占用几个字节,没有给出精确的定义【详细介绍查看>>内容扩充模块④<<】。
④、字符型
char类型只能表示一个字符,占用1个字节。单个字符必须使用英文的单引号引起来且引号之内只能有一个字符【一个汉字或一个字母】,如 char str='a';另外字符型变量可以同整型数值进行运算。如果表示一个字符串,如"avaljbljlajklsd",则要使用String类型,String是个类,String是引用数据类型,后续做讲解。注意字符串必须使用英文双引号进行包围。
原因详见>>内容扩充模块⑤<<
⑤、空型
最后还有一个空类型null,所有字母必须小写。
5、关键字和标识符
关键字: Java预先定义好的,具有特殊含义的单词(如上方的public 、static 、void 、main、return、int 、float、等)详见>>内容扩展模块⑩<<
标识符: 由程序员自己定义的单词
类名,变量名,方法名
标识符的命名规则和规范
规则:
a.必须由数字,字母,_,$组成
b.数字不能开头
c.不能和关键字重名
规范:
a.见名知义
b.驼峰式命名法
类名:所有单词的首字母大写(大驼峰)
变量名,方法名:第二个单词开始首字母大写(小驼峰)
关键字都是小写的
称为大神,第二步: 严格遵循规则和规范
以下哪些标识符是合法的:
HelloWorld Hello_World Hello_
_Hello Hello World 1HelloWorld
6、定义变量规则与规范
格式:
数据类型 变量名 = 值; 这里值 必须对应数据类型
变量定义中需要注意的两点
首先要遵守标识符的命名规则与规范
a.在同一个大括号中,不能定义两个名字一样的变量(哪怕类型不一样也不行!!!)
b.变量定义后可以不赋值,但是该变量是不能使用
c.变量可以先定义后赋值,而且可以赋值多次,以最后一次赋值为准
d.一些奇葩的定义和赋值方式
int a,b; ab都没有赋值
int a = 10,b; a赋值了 b没有赋值
int a,b = 10; a没有赋值,b赋值了
int a = 10,b = 20;ab都赋值了
能够定义8种基本数据集类型的变量
整型变量
byte/short/int/long 变量名 = 值;
在发开中如果没有特殊说明,建议使用int
如果我们使用的是long,需要在值后面加上L
浮点型变量
float/double 变量名 = 值;
在发开中如果没有特殊说明,建议使用double
如果我们使用的是float,需要在值后面加上F
字符型变量
char c = 'a';
布尔型变量
boolean b = true/false;
字符串型变量
String name = "jack";
7、如何使用上方的数据类型?
仔细阅读并编写下方代码并上机运行,体会变量的定义和使用。
public class Test { public static void main(String[] args) { // TODO Auto-generated method stub //定义一个整型变量age并赋值为10 int age=10; //定义一个byte短整型变量page并赋值为10 byte page=10; //定义一个short整型变量num并赋值为8 short num=8; //定义一个字符型变量并赋值'a' char ch='a'; //定一个字符型变量并赋值'b' char cha='b'; //定义一个boolean变量并赋值为true boolean bo=true; //定义一个单精度浮点型变量 float fl=2f; //输出上方的结果 System.out.println(age); System.out.println(page); System.out.println(num); System.out.println(ch); System.out.println(bo); System.out.println(fl); //输出字符类型和int类型的计算结果 System.out.println(cha+age); } }
输出结果如下
10 10 8 a true 2.0 108
8、数据类型的转换
为什么会有数据转换?因为java规定,不同类型的数据之间不能进行数据运算。所以需要进行数据类型转换才能进行算术运算。数据类型的转换包括自动转换和强制转换。
①、自动转换
java在进行运算的时候在一些情况下会进行自动转换,其自动转换遵循以下规则
1、byte、short、char变量在进行运算的时候自动转为int类型
2、boolean类型不参与任何类型的转换
3、float变量在运算的时候会自动转换成double变量
变量自动转换的方向
char、byte、short(只要这三个变量参与运算就直接被系统转换为int)————》int————》long————》float————》double
②、强制转换
强制转换的作用对象是变量,强制转换的方向是从高精度转换成低精度,转换后可能会丢失数据精度。一般在开发中尽量少用。
强制类型转换的方法
在需要进行强制类型转换的变量前加小括号并在小括号内输入需要转换成的目的数据类型。
如float a=10.99;
int b=(int)a;
上方的代码意义是将浮点型变量强制转换成整型变量然后把值赋给b变量,转换后的变量会丢失掉小数点后面的部分。
③、变量和常量的运算__编译器的常量优化
int a = 3.14; //报错的,3.14是宽类型 a是窄类型
float f = 3.14; //报错的
a.编译器会对常量进行优化
byte b = 10;//编译器常量优化,只要该常量没有超过byte的范围,编译器自动优化
short s = 10;//编译器常量优化,只要该常量没有超过short的范围,编译器会自动优化
b.编译器会对常量计算进行优化
byte b = 10 + 20;//编译器也会对常量计算后的结果优化,只要结果没超过byte范围
byte b1 = 10;
byte b2 = 20;
byte b = 10 + 20; //常量计算可以优化
byte b = b1 + 20; //含有变量b1不能优化
byte b = 10 +b2; //含有变量b2不能优化
byte b = b1 + b2; //更不能优化
拓展:在java中当我们定义一个变量后如果没有赋值则会被系统赋予初始值,初始值结果如下
byte short int long的初始值为0
char的初始值为' '空格
float和double是0.0
boolean的初始值是false
引用类型是null
9、案例展示
1、交换两个变量中保存的整数的位置【思路一:此思路会浪费内存】
public class Alvin{ public static void main(String [] args) { //定义两个变量 int a=10; int b=20; int c=0; //开始交换两个数的位置 c=a; a=b; b=c; System.out.println("a="+a+";b="+b); } }
2、交换两个变量中保存的整数的位置【思路2:此思路有局限,可能溢出数据】
public class Alvin{ public static void main(String [] args) { //定义两个变量 int a=10; int b=20; //交换两个变量的位置 a+=b; b=a-b; a=a-b; System.out.println("a="+a+";b="+b); } }
3、交换两个变量中保存的整数的位置【思路3:最好的方法】
public class Alvin{ public static void main(String [] args) { //定义两个变量 int a=10; int b=20; //交换两个变量的位置 a=a^b; b=a^b; a=a^b; System.out.println("a="+a+";b="+b); } }
第3讲 运算符和流程控制
一、运算符
1、算术运算符
| 运算符符号 | 名称 | 功能 | 分类 | 举例 |
| + | 加 | 将两个操作数相加 | 双目运算符 | int a=3+4;//结果把7赋值给a |
| — | 减 | 将两个操作数相减 | 双目运算符 | int a=10-3;//结果把7赋值给a |
| * | 乘 | 将两个操作数相乘 | 双目运算符 | int a=3*4;//结果把12赋值给a |
| / | 除 | 将两个操作数相除 | 双目运算符 | int a=29/4;//结果把7赋值给a |
| % | 模 | 对第一个操作数以第二个操作数的倍数取余 | 双目运算符 | int a=16%9;//结果把7赋值给a |
| ++ | 自加 | 将一个变量的值加1 | 单目运算符 | int i=0; i++;【或++i】最后把i的值赋值为1 |
| —— | 自减 | 将一个变量的值减1 | 单目运算符 | int i=2; i--;【或--i】最后把i的值赋值为1 |
关于自加和自减的详细讲解详见>>内容扩充模块⑦<<
算术运算符中的*、/运算中,只要操作数中有一个浮点型变量则系统直接把另一个操作数转换成浮点型变量,计算结果为浮点型。
注意事项:
①、在利用算术运算符计算中注意自动转换。
②、在*、/、%运算中,两个操作数如果有一个为浮点型变量或常量则结果也为浮点型。
③、运算结果不可以超过左侧变量的存储范围。
应用举例:写一个java程序判断两个数能否被整除,能则返回"可以被整除"否则返回"不能被整除"。
下方代码部分代码目前无需深究,后续会有讲解。
/* * 作者:Alvin * 功能:判断两个数能否被整除 * 时间:2019年2月22日08:53:05 * */ public class Test { public static void main(String[] args) { // TODO Auto-generated method stub //定义被除数变量 int firstDivisor=10; //定义除数变量 int secondDivisor=3; //对余数结果进行判断,余数为零则可以被整除,余数不为零则执行else语句中的字段 //下方的if...else..目前无需纠结 if(firstDivisor%secondDivisor == 0) { System.out.println("可以被整除"); } else { System.out.println("不能被整除"); } } }
2、复合赋值运算符
| 运算符符号 | 名称 | 功能 | 种类 | 举例 |
| += | 加等于 | 对两个操作数求和并赋值给左侧变量 | 双目运算符 | a+=3;等价于a=a+3; |
| -= | 减等于 | 对两个操作数求差并赋值给左侧变量 | 双目运算符 | a-=3;等价于a=a-3; |
| *= | 乘等于 | 对两个操作数求积并赋值给左侧变量 | 双目运算符 | a*=3;等价于a=a*3; |
| /= | 除等于 | 对两个操作数求商并赋值给左侧变量 | 双目运算符 | a/=3;等价于a=a/3; |
| %= | 模等于 | 对两个操作数求余并赋值给左侧变量 | 双目运算符 | a%=3;等价于a=a%3; |
3、关系运算符
关系运算符中其计算结果是boolean型,结果只有true或false。
| 运算符符号 | 名称 | 功能 | 种类 | 举例 | 举例中运算返回结果 |
| > | 大于 | 判断左侧的值是否大于右侧的值 | 双目运算符 | 10>20 | false |
| < | 小于 | 判断左侧的值是否小于右侧的值 | 双目运算符 | 10<20 | true |
| >= | 大于等于 | 判断左侧的值是否大于或等于右侧的值 | 双目运算符 | 10>=20 | false |
| == | 等于 | 判断左侧的值是否等于右侧的值 | 双目运算符 | 10==20 | false |
| <= | 小于等于 | 判断左侧的值是否小于或等于右侧的值 | 双目运算符 | 10<=20 | true |
| != | 不等于 | 判断左侧的值是否不等于于右侧的值 | 双目运算符 | 10!=20 | true |
4、逻辑运算符
| 运算符符号 | 名称 | 功能 | 种类 | 举例 | 举例中运算结果 |
| && | 逻辑与【又称短路与】 | 根据运算符两侧的boolean值判断真假 | 双目运算符 | 5>4 && 1<0 | false |
| || | 逻辑或【又称短路或】 | 根据运算符两侧的boolean值判断真假 | 双目运算符 | 5>4 && 1<0 | true |
| ! | 非 | 对原来的boolean值取反 | 单目运算符 | !(5>4 && 1<0) | false |
| ^ | 异或 | 根据运算符两侧的boolean值判断真假 | 双目运算符 | 5>4 ^ 1<0 | true |
逻辑运算符的真假情况如下
①、所有的逻辑运算符,只能运算布尔类型的数据
②、&& 短路与 规则:全真为真 一假则假
③、|| 短路或 规则:全假为假 一真则真
④、^异或 规则:相同为假 不同为真
⑤、! 非,取反 注意:只能操作一个布尔值 规则:真变假 假变真
5、三目运算符
三目运算符的结构
布尔表达式?值1:值2;
流程是:如果布尔表达式的判断为true则返回值1,否则返回值2.
案例
// 使用三目运算符求两个数的较大者 int a=10,b=20; System.out.println(a>b?a:b);
输出结果
20
6、补充
运算符是有优先级的,他们的优先级顺序如下图所示

总结:从上方的表可以看出:小括号、方括号、成员访问符(.) > 单目运算符 > 算术运算符 > 移位运算符 > 逻辑运算符 > 逻辑运算符(==和!=) >&>|>&&>||>三目运算符>复合赋值运算符
二、流程控制
顾名思义,流程控制就是对程序执行的流程进行控制,也就是控制程序语句什么时候,什么情况下执行那一条语句。根据分类的不同,流程控制可以分为顺序控制、分支控制和循环控制
1、顺序控制
顺序控制就是程序按照从上而下,从左而右的顺序顺序执行。
如下程序
/* * 作者:Alvin * 功能:流程控制之顺序控制 * 时间:2019年2月22日13:42:42 * */ public class Test { public static void main(String[] args) { // TODO Auto-generated method stub System.out.println("我是第1句"); System.out.println("我是第2句"); System.out.println("我是第3句"); System.out.println("我是第4句"); System.out.println("我是第5句"); System.out.println("我是第6句"); } }
程序执行后的结果输出如下
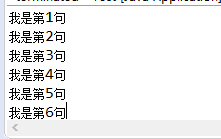
结果说明,在正常情况下,程序会按照代码的书写顺序执行。
但是事实上,我们在生活中总需要进行选择,有了选择就有了在某种情况下我们需要做什么事,程序也是如此。
2、分支控制
分支控制就是在某种情况下指定程序执行那些代码块。
分支控制中有以下几个分类:
1、单分支
单分支语句就像生活中一件事我们做或不做。
语句格式:
if(关系表达式或boolean类型变量或非0值) { 需要执行的代码块; }
案例:
/* * 作者:Alvin * 功能:单分支语句案例 * 时间:2019年2月22日13:51:57 * */ public class Test { public static void main(String[] args) { // TODO Auto-generated method stub //定义两个变量 int a=2; //此处的判断条件为boolean表达式 //第一个单分支语句 if(a==2); { //当满足a==2时,把a的值更改为3 a=3; //输出a的值 System.out.println("a的值为:"+a); } //第二个单分支语句 if(a!=2); { //当满足a!=2时,把a的值更改为2 a=2; //输出a的值 System.out.println("a的值为:"+a); }
if(a==1);
{
//当满足a==1时,把a的值更改为2
a=2;
//输出a的值
System.out.println("a的值为:"+a);
}
} }
上方代码输出结果如下

说明当if()中小括号中的boolean表达式(或者其他值)为真(或者不为0)时,if语句后面的大括号中的代码块会被执行,当小括号中的boolean为假false时,if后面的大括号中的代码块不会被执行
2、双分支
双分支就是对一件事进行判断,假如成立时干什么,假如不成立时又干什么。
语句格式如下
if(boolean表达式); { //如果boolean表达式成立则执行该括号里面的代码块 代码块; } else { //如果boolean表达式中不成立,即为false,则执行下方代码块 代码块; }
案例:
/* * 作者:Alvin * 功能:双分支语句案例 * 时间:2019年2月22日14:09:16 * */ public class Test { public static void main(String[] args) { // TODO Auto-generated method stub /* *要求: 抛硬币,用0表示背面,用1表示正面,如果抛出的硬币为正面则学猫叫,否则学狗叫 * */ //定义一个变量result表示抛硬币得到的结果,我们假设硬币的结果为1 int result=1; if(result==0) { //如果结果为背面学狗叫 System.out.println("汪汪!"); }else { //如果结果为正面学猫叫 System.out.println("喵喵!"); } } }
运行结果
喵喵!
修改result=0后输出的结果
汪汪!
希望自己调试体会。
注意:if语句中的else会根据就近原则向上匹配最近的if。
3、多分支
多分支语句是用来应对多种情况下的语句选择。
多分支语句有两种,分别为
1、if型
if(boolean表达式)
{
代码块;
}
else if(boolean表达式)
{
代码块;
}
else if(boolean表达式)
{
代码块;
}
...........//此处省略n个else if
else{
代码块;
}
2 、switch....case .....case....default
switch(变量值)
{
case 常量1:语句;break;
case 常量2:语句;break;
case 常量3:语句;break;
case 常量4:语句;break;
case 常量5:语句;break;
................//此处省略n个case语句
default:语句;break;
}
先执行表达式,获取值
表达式的值和case后面的值依次做匹配
哪一个case后面的值与表达式的值相等,那么就执行其后面的代码块
执行完毕代码块后,由于有一个break,那么整个switch结束
如果所有的值都没有匹配上,那么无条件执行default后面的代码块
关于switch....case.....default语句需要注意的几点。
①、可以使用的数据类型主要有byte、short、int、char、enum、String(JDK7中新增的)等。内容扩充文章<<
②、default语句写在switch代码块中的判断位置不影响最后的执行结果。if语句如果包含else则else必不能提前写。java语言中的else遵循向上就近匹配原则,即else会匹配其上方最近的的一个if或else..if结构。
③、case后面只能是常量,且case后面的常量不能有相同的常量。
④、在switch的每个分支判定语句中,break作为每条分支语句执行成功后switch结构的终结,如果省略会发生case穿透,则程序对下方case不再判断,而是直接执行,知道遇见一个break或者switch语句执行完毕为止。
⑤、switch和if....else语句中的default和else可作为所有条件都无法匹配后的保守处理结果,可在开发过程中降低程序的bug带来的影响。
代码演示【主要代码】
int a=10,b=20; System.out.println(a>b?a:b); switch(a) { default:System.out.println("default");break; case 10:System.out.println("10"); case 5:System.out.println("5"); case 6:System.out.println("6");break; case 7:System.out.println("7");break; case 20:System.out.println("20");break; }
输出结果
20 10 5 6
从上方可以看出,default的位置与结果无关,缺少break的语句会发生case穿透【即忽视下方case判定的存在】直接执行case后面的代码块。
3、循环控制
循环控制流程包括三种
1、for
首先看一下for循环的结构
for(①初始化语句;②循环条件;④自增(减)循环计数器){ ③循环体 }
执行流程:
首先执行①--> ②③④ --> ②③④ --> ...........-->②结束
看一个案例
//在控制台输出7次Hollow World //使用for循环 for(int i = 0;i < 7; i++){ System.out.println("Hello World!"); }
执行结果
Hello World!
Hello World!
Hello World!
Hello World!
Hello World!
Hello World!
Hello World!
使用for循环的建议
①、for循环中,循环计数器的初始值建议从0或者1开始
②、for循环中定义的变量不可以超越for循环大括号所包围的范围。
2、while
格式:
①初始化语句 while(②循环条件){ ③循环体; ④自增(减)循环计数器
}
执行流程:
首先执行①--->②③④-->②③④---> ...--->②
案例
//在控制台输出7次Hollow World //使用while循环 int i = 0; while(i < 7){ System.out.println("Hello World!"); i++; }
输出结果
Hello World!
Hello World!
Hello World!
Hello World!
Hello World!
Hello World!
Hello World!
拓展:while循环在不确定循环次数的程序中比较常用,代码样式更简洁
如下案例
/* * 作者:Alvin * 功能:猜数字--while循环实现 * 时间:2019年2月22日20:27:04 * */ import java.io.BufferedReader; import java.io.InputStreamReader; public class Test2 { public static void main(String[] args){ // TODO Auto-generated method stub //创建对象,接收从键盘输入的数据 InputStreamReader isr=new InputStreamReader(System.in); BufferedReader bf=new BufferedReader(isr); //循环设置为永真条件,用于在猜错的时候进行再次生成随机数,循环猜数 while(true){ //打印提示,提示用户输入 System.out.println("输入你要猜的数【0-9】:"); //try.....catch用于捕捉输入流的异常 try { //对输入的数和系统随机生成的数进行判断是否相等,如果相等则执行下方代码块 if(Integer.parseInt(bf.readLine()) == (int)(Math.random()*10)) { System.out.println("你好棒!猜对了!是你最懂我的心!"); break; } //如果系统产生的随机值和自己的数值不一致,则输出提示继续猜。 else System.out.println("不好意思接着猜!"); } catch (Exception e) { System.out.println("可能输入有误!"); } } } }
执行结果演示
输入你要猜的数【0-9】: 5 不好意思接着猜! 输入你要猜的数【0-9】: 4 不好意思接着猜! 输入你要猜的数【0-9】: 6 你好棒!猜对了!是你最懂我的心!
上方程序也可以用for循环进行改写如下
/* * 作者:Alvin * 功能:猜数字--for循环实现 * 时间:2019年2月22日20:31:33 * */ import java.io.BufferedReader; import java.io.InputStreamReader; public class Test2 { public static void main(String[] args){ // TODO Auto-generated method stub //创建对象,接收从键盘输入的数据 InputStreamReader isr=new InputStreamReader(System.in); BufferedReader bf=new BufferedReader(isr); //循环设置为永真条件,用于在猜错的时候进行再次生成随机数,循环猜数 for(;true;){ //打印提示,提示用户输入 System.out.println("输入你要猜的数【0-9】:"); //try.....catch用于捕捉输入流的异常 try { //对输入的数和系统随机生成的数进行判断是否相等,如果相等则执行下方代码块 if(Integer.parseInt(bf.readLine()) == (int)(Math.random()*10)) { System.out.println("你好棒!猜对了!是你最懂我的心!"); break; } //如果系统产生的随机值和自己的数值不一致,则输出提示继续猜。 else System.out.println("不好意思接着猜!"); } catch (Exception e) { System.out.println("可能输入有误!"); } } } }
3、do....while
格式:
①初始化语句 do{ ③循环体 ④步进语句 }while(②循环条件);
执行流程:
首先执行①③④-->②③④-->②③④-->.....--->②结束
特点:do..while循环是先执行一次,再去判断
至少会执行一次
案例:把上方的猜数字再用do....while改写一下,代码如下
/* * 作者:Alvin * 功能:猜数字--do.....while循环实现 * 时间:2019年2月22日20:36:54 * */ import java.io.BufferedReader; import java.io.InputStreamReader; public class Test2 { public static void main(String[] args){ // TODO Auto-generated method stub //创建对象,接收从键盘输入的数据 InputStreamReader isr=new InputStreamReader(System.in); BufferedReader bf=new BufferedReader(isr); //循环设置为永真条件,用于在猜错的时候进行再次生成随机数,循环猜数 do{ //打印提示,提示用户输入 System.out.println("输入你要猜的数【0-9】:"); //try.....catch用于捕捉输入流的异常 try { //对输入的数和系统随机生成的数进行判断是否相等,如果相等则执行下方代码块 if(Integer.parseInt(bf.readLine()) == (int)(Math.random()*10)) { System.out.println("你好棒!猜对了!是你最懂我的心!"); break; } //如果系统产生的随机值和自己的数值不一致,则输出提示继续猜。 else System.out.println("不好意思接着猜!"); } catch (Exception e) { System.out.println("可能输入有误!"); } }while(true); } }
没用的知识点扩充:
死循环: 永不停止的循环
Java中最简单的死循环:
while(true);
for(;;);
java中循环上只有while和for循环可以省略掉花括号。
4、跳转控制语句
转移控制语句是当程序运行遇到下列关键字时需要进行跳转。常见类型如下
1、break;在循环代码块中用于立即结束其所在层的循环,继续执行下方代码。
2、continue;在循环代码中立即结束剩余循环代码块直接跳转到下一次循环。
3、return;当程序遇到return时会立即结束包含该语句的整个方法,继续执行该方法后的下方代码,在每个方法内部,return后面不能再写无效代码
4、System.exit;当程序遇到该语句时,直接跳转到改程序的结束位置,程序结束。
TIp:
1.break的介绍举例
break语句的作用:立刻马上rightnow结束整个循环
public static void main(String[] args) { // TODO Auto-generated method stub // 打印1-10 for (int i = 1; i < 11; i++) { // 判断 if (i == 3) { break; // 打断 } System.out.println(i);// 1 2 } System.out.println("循环结束了.."); }
执行结果
1 2 循环结束了..
2.continue的介绍
continue语句的作用:立刻马上结束本次循环,继续下一次循环
public static void main(String[] args) {
// TODO Auto-generated method stub
// 打印1-10
for (int i = 1; i < 11; i++) {
// 判断
if (i == 3) {
continue; // 跳过本次
}
System.out.println(i);// 1 2 4 5 6 7 8 9 10
}
System.out.println("循环结束了..");
}
输出结果
1 2 4 5 6 7 8 9 10 循环结束了..
必须明确的事情是:break和continue只对循环有效,对if判断语句无效。
5、补充
1、拓展视野
上方的循环语句已经讲解完毕,需要补充的是在编程过程中经常使用的嵌套循环结构,也就是在循环结构中又包含了若干个循环结构。像下方这样的为两层for循环
//.嵌套循环:
// 一个循环的循环体是另外一个循环
// 格式:
for(初始化语句;循环条件;步进语句){
for(初始化语句;循环条件;步进语句){
循环体;
}
}
在开发中,嵌套几层循环【不一定是for循环】根据实际情况而定。
2、Java入门程序联系
1、打印10次Hello【源码如下】
public static void main(String[] args) { // TODO Auto-generated method stub for(int i=0;i<10;i++) { System.out.println("Hello"); } }
2、打印100个1【源码如下】
public static void main(String[] args) { // TODO Auto-generated method stub for(int i=0;i<100;i++) { System.out.println(1); } }
3、打印从1~100【源码如下】
public static void main(String[] args) { // TODO Auto-generated method stub for(int i=1;i<=100;i++) { System.out.println(i); } }
4、打印1~100之中的偶数【源码如下】
public static void main(String[] args) { // TODO Auto-generated method stub for(int i=1;i<=100;i++) { if(i%2==0) System.out.println(i); } }
5、打印从1~100之中的素数【源码如下】
public static void main(String[] args) { // TODO Auto-generated method stub //外层循环生成需要判定的数 for(int i=1;i<=100;i++) { //从2开始到给定的数进行逐求余 int j=2; while(j<=i) { //当余数为0时终止比较 if(i%j==0) break; j++; } //假如最后结果是j与i的值相同,则说明只能被其本身整除,则该数是素数 if(i==j) System.out.println(i); } }
6、打印50个斐波那契数列【源码如下】
public static void main(String[] args) { // TODO Auto-generated method stub //打印50个斐波那契数列 long sum=0; long fron=0; long back=1; for(int k=1;k<50;k++) { //第一次打印把第一个1打印出来 if(k==1) System.out.println(1); //sum的值定义为相邻的前面两个数一前一后的和 sum=fron+back; System.out.println(sum); //打印后两个值向后移动一位 fron=back; back=sum; } }
7、打印一个6行10列的矩形【源码如下】
public static void main(String[] args) { // TODO Auto-generated method stub //外层循环控制行数 for(int line=1;line<=6;line++) { //内层循环控制列数 for(int row=1;row<=10;row++) { //打印不换行 System.out.print("*"); } //一行打印完毕后换行 System.out.println(); } }
8、打印一个7层的直角三角形【源码如下】
public static void main(String[] args) { // TODO Auto-generated method stub //外层循环控制行数 for(int line=1;line<=6;line++) { //内层循环控制列数,此时注意行数与每行中星星个数的关系 for(int row=1;row<=line;row++) { //打印不换行 System.out.print("*"); } //一行打印完毕后换行 System.out.println(); } }
9、打印一个7层的等边三角形【源码如下】
public static void main(String[] args) { // TODO Auto-generated method stub //外层循环控制行数 for(int line=1;line<=7;line++) { //因为每行要打印两种元素空格和星星,所以需要两个for循环完成行内元素打印 //本循环打印空格 for(int space=1;space<=7-line;space++) { //打印空格不换行,数量关系与直角三角形做对比 System.out.print(" "); } //此时注意行数与每行中星星个数的关系 for(int row=1;row<=2*line-1;row++) { //打印星星不换行 System.out.print("*"); } //一行打印完毕后换行 System.out.println(); } }
10、打印一个实心菱形【源码如下】
System.out.println("======菱形【在打印等腰三角形上的改变】===========");
public static void main(String[] args) { // TODO Auto-generated method stub //总打印行数 int rowsDia = 15; //用于改变菱形上下打印的过度变量 int midRow=0; for(int row=1;row<=rowsDia;row++){ //改变菱形上下打印的方向判断 if(row<=((rowsDia+1)/2)) //当row<=(rowsDia+1)/2时,打印上半部分的赋值方法 midRow=row; else //当row>(rows+1)/2时,打印下半部分的赋值方式 midRow=rowsDia-row+1; //打印空格[后面有个-3是为了使菱形左右移动的] for(int space=0;space<((rowsDia+1)/2)-midRow;space++) System.out.print(" "); //打印星星 for(int star=1;star<=2*midRow-1;star++) System.out.print("*"); System.out.println(); } }
11、打印一个空心菱形【源码如下】
System.out.println("======空心菱形【在打印菱形上的改变】===========");
//总打印行数
int rowsDiaEmpty = 15;
//用于改变菱形上下打印的过度变量
int midRowEmpty=0;
for(int row=1;row<=rowsDiaEmpty;row++){
//改变菱形上下打印的方向判断
if(row<=((rowsDiaEmpty+1)/2))
//当row<=(rowsDiaEmpty+1)/2时,打印上半部分的赋值方法
midRowEmpty=row;
else
//当row>(rows+1)/2时,打印下半部分的赋值方式
midRowEmpty=rowsDiaEmpty-row+1;
//打印空格[后面有个-3是为了使菱形左右移动的]
for(int space=0;space<((rowsDiaEmpty+1)/2)-midRowEmpty;space++)
System.out.print(" ");
//打印星星
System.out.print("*");
for(int star=1;star<=2*midRowEmpty-2;star++)
if(star== 2*midRowEmpty-2)
System.out.print("*");
else
System.out.print(" ");
System.out.println();
}
12、打印一个水仙花数【源码如下】
13、打印九九乘法表【源码如下】
for(int i=1;i<=9;i++) { for(int j=1;j<=i;j++) { System.out.print(j+"x"+i+"="+(i*j)+" "); } System.out.println(); }
拓展:java语句在控制台的格式化输出
double d = 12.345;
String s = "TestString!";
int i = 1234;
//"%"表示进行格式化输出,"%"之后的内容为格式的定义。
System.out.printf("%f
",d);//"f"表示格式化输出浮点数。 后面的
表示换行
System.out.printf("%6.2f
",d);//"6.2"中的6表示输出的长度,2表示小数点后的位数,符合四舍五入,默认右对齐。
System.out.printf("%+9.2f
",d);//"+"表示输出的数带正负号。
System.out.printf("%-9.4f
",d);//"-"表示输出的数左对齐(默认为右对齐)。
System.out.printf("%+-9.3f
",d);//"+-"表示输出的数带正负号且左对齐。
System.out.printf("%d
",i);//"d"表示输出十进制整数。
System.out.printf("%o
",i);//"o"表示输出八进制整数。
System.out.printf("%x
",i);//"d"表示输出十六进制整数。
System.out.printf("%#x
",i);//"d"表示输出带有十六进制标志的整数。
System.out.printf("%s
",s);//"d"表示输出字符串。
System.out.printf("输出一个浮点数:%f,一个整数:%d,一个字符串:%s
",d,i,s);//可以输出多个变量,注意顺序。
System.out.printf("字符串:%2$s,%1$d的十六进制数:%1$#x
",i,s);//"X$"表示第几个变量。
上方代码执行结果:以0x开始的数据表示16进制,计算机中每位的权为16,即(16进制)10 = (10进制)1×16备注:这里的0是数字0,不是字母O!
12.345000 12.35 +12.35 12.3450 +12.345 1234 2322 4d2 0x4d2 TestString! 输出一个浮点数:12.345000,一个整数:1234,一个字符串:TestString! 字符串:TestString!,1234的十六进制数:0x4d2
第4讲 类、对象、成员方法
从本讲我们开始讲解Java面向对象编程之类与对象。在类中涉及的东西特别多,如封装、继承、多态、实现、成员变量、成员属性、成员函数、成员方法、构造方法、默认方法等。在内存中程序在运行的过程划分为代码区、静态区、栈区等。
本讲内容:
1、java面向对象编程(1)--类与对象
2、java面向对象编程(1)--构造方法
学习目标:
1.初步掌握java中的类和对象
2、什么是成员变量和成员方法
3、掌握构造方法的使用
一、问题引入
张老太养了两只猫,一只名字叫小白,今年3岁,白色。还有一直名字叫小花,今年10岁,花色。请编写一个程序,当用户输入小猫的名字时就显示该猫的名字、年龄、颜色。如果用户输入的小猫名错误,则显示张老太没有 这只猫。
我们发现,如果用我们现有的知识是可以解决这个问题的。代码如下
import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; /* * 作者:Alvin * 功能:张老太养猫案例 * 时间:2019年2月23日09:25:39 * * */ public class Test { public static void main(String[] args) { // TODO Auto-generated method stub //接收从键盘输入的内容 BufferedReader bf=new BufferedReader(new InputStreamReader(System.in)); //定义字符串型变量name,用于存放从键盘接收的用户输入的信息 String name=null; //try....catch异常处理 try { //提示输入 System.out.println("请输入你要查询的猫的名字:"); //从键盘接收一行 name=bf.readLine(); } catch (IOException e) { // TODO Auto-generated catch block //如果输入不合法字段将显示该信息提示用户 System.out.println("对不起,您的输入有误,请重新输入!"); } //定义张老太的白猫 String cat_white="小白"; int age_white=3; String color_white="白"; //定义张老太的花猫 String cat_hua="小花"; int age_hua=10; String color_hua="花"; //不可以使用==号进行判断,因为==比较的是地址是否相同 if(cat_white.equals(name)) { System.out.println("名字是"+cat_white+"年龄是"+age_white+"颜色是"+color_white); } else if(cat_hua.equals(name)) { System.out.println("名字是"+cat_hua+"年龄是"+age_hua+"颜色是"+color_hua); }else { System.out.println("张老太没有这只猫!"); } } }
运行结果
请输入你要查询的猫的名字: 小白 名字是小白年龄是3颜色是白色
二、解决方案
但是我们发现,上面我们需要为两只猫分别添加名字、年龄、颜色属性,如果张老太有1万只猫,我们岂不是要重复定义属性代码1万次。这两只猫都有这三个共同的属性,只是这三个属性的值不同而已,上面的代码书写过于分散,那为了使代码看起来更简洁统一并且提高代码的复用率,我们想到可不可以把猫的共同属性抽象出来,把共同属性放在一块然后给他起个名字叫猫?这样我们就可以在定义变量的时候直接定义一个猫,然后给这个猫起个名字,加个年龄,配上花色就好了。这就像在自然界一样每个动物当他们出生的时候就已经具有其他同类的物种所具有的共同属性,但是他们的属性值不同而已,如一只熊猫降生时我们就把称之为熊猫,然后给他起个名字叫亮亮,它还有体重,身高等和其他熊猫共有的属性,但属性的值不同。
按照我们刚才的思路,我们现在把猫这个类给抽象出来,本题我们只需抽象出包含名字、年龄和颜色属性的猫类。
代码如下
/* * 作者:Alvin * 功能:定义一个猫类 * 时间:2019年2月23日09:53:57 * * */ public class Test { public static void main(String[] args) { // TODO Auto-generated method stub } } //定义一个猫类 class Cat { //猫的年龄 int age; //猫的名字 String name; //猫的颜色 String color; }
如果我们用上面的思路来写代码的话代码如下
import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; /* * 作者:Alvin * 功能:定义一个猫类并实现查询猫操作 * 时间:2019年2月23日10:35:02 * * */ public class Test { public static void main(String[] args) { // TODO Auto-generated method stub //第一只猫,此时的Cat类就相当于数据类型,像定义int一样进行定义 Cat cat1=new Cat(); cat1.name="小白"; cat1.age=3; cat1.color="白色"; //第二只猫 Cat cat2=new Cat(); cat2.name="小花"; cat2.age=10; cat2.color="花色"; //接收从键盘输入的内容 BufferedReader bf=new BufferedReader(new InputStreamReader(System.in)); String name=null; //try....catch异常处理 try { //提示输入 System.out.println("请输入你要查询的猫的名字:"); //从键盘接收一行 name=bf.readLine(); } catch (IOException e) { // TODO Auto-generated catch block //如果输入不合法字段将显示该信息提示用户 System.out.println("对不起,您的输入有误,请重新输入!"); } //不可以使用==号进行判断,因为==比较的是地址是否相同 if(cat1.name.equals(name)) { System.out.println("名字是"+cat1.name+"年龄是"+cat1.age+"颜色是"+cat1.color); } else if(cat2.name.equals(name)) { System.out.println("名字是"+cat2.name+"年龄是"+cat2.age+"颜色是"+cat2.color); }else { System.out.println("张老太没有这只猫!"); } } } // 定义一个猫类 class Cat { // 猫的年龄 int age; // 猫的名字 String name; // 猫的颜色 String color; }
运行结果
请输入你要查询的猫的名字: 小白 名字是小白年龄是3颜色是白色
我们看到,这种方法也解决了问题。但是这种方法只需我们定义两个Cat类型的对象,更符合认识事物的思维。
上方案例说明,我们的方法是可行的。代码中Cat cat1=new Cat()这句话我们称为用Cat类创建一个对象cat1并对cat1进行实例化简称实例化一个对象。我们上面的代码就是面向对象的编程,简单且不恰当的说就是对象进行操作的编程。
编程语言的发展朝向着接近人的思维方式演变。首先由汇编语言【面向机器】,在汇编语言中,用助记符(Mnemonics)代替机器指令的操作码,用地址符号(Symbol)或标号(Label)代替指令或操作数的地址,编程十份繁琐。后来程序发展到面向过程的语言,如C语言,面向过程的语言也称为结构化程序设计语言,是高级语言的一种。在面向过程程序设计中,问题被看作一系列需要完成的任务,函数则用于完成这些任务,解决问题的焦点集中于函数。机器语言程序之所以极其复杂和晦涩难懂,一是用二进制数表示机器指令的操作码和存放操作数的存储单元地址。二是每一条机器指令只能执行简单运算。面向过程语言要达到简化程序设计过程的目的,需要做到:一是使语句的格式尽量接近自然语言的格式:二是能够用一条语句描述完成自然表达式运算过程的步骤。因此,语句的格式和描述运算过程步骤的方法与自然表达式接近是面向过程语言的一大特色。面向对象语言(Object-Oriented Language)是一类以对象作为基本程序结构单位的程序设计语言,指用于描述的设计是以对象为核心,而对象是程序运行时刻的基本成分。语言中提供了类、继承等成分,有识认性、多态性、类别性和继承性四个主要特点。
上方案例中的类距离一个完整的类还很遥远,上面的类是一个简单的类。
三、案例总结
根据上方案例,我们总结一下,类和对象的关系和区别。
①、类是抽象的,概念的,代表一类事物,比如人类,猫类
②、对象是具体的,实际的,代表一个具体事物
③、类是对象的模板,通过类可以声明一个具体的对象实例。
四、类-如何定义
一个全面的类定义比较复杂,如下是一个比较完整的类的结构
/*下方是一个完整的类。目前没有学习到的地方可以提前了解一下,以后学习可以有印象。特别提醒一个java中可以有好多类但只能有一个公共类。 * 1、package:该关键字后面是该类在src目录下所在的路径,该关键字在一个java文件中只能出现一次并且位于java文件的有效代码的第一句 * 2、包名:包名是当前编辑的java文件在src目录下的路径,windows文件路径分级是采用右斜线的,如路径C:Program FilesJava,而在开发工具中是以英文符号 . 进行区分文件夹上下级,符号的左侧是上级文件夹,右侧是下级文件夹 * 3、访问权限修饰符:该修饰符是用来说明该类可以被哪些类调用,当前我们学习的只有public修饰符,它也是权限最大的修饰符,允许任何类调用该类 * 4、class:class是定义类的关键字,该关键字的字母都不可以小写,java是强类型语言【即严格区分变量类型和字母大小写】,后面紧跟类名 * 5、类名:类名是标识符,命名规则遵循大驼峰命名法,遵守>>>>标识符的命名规则与规范<<<<。 * 6、extends:是定义类的关键字,该关键字的字母都不可以小写,java是强类型语言【即严格区分变量类型和字母大小写】,后面紧跟父类名[在java中有些类是可以被继承的,就像儿子和父亲的关系,儿子可以继承父亲遗传的属性,如脸型,鼻型和谢顶等] * 7、父类名:父类名就是该类需要继承的父类的名字,extends后面紧跟父类名,但是当且仅当只能跟一个父类名 * 8、implements:是定义类的关键字,该关键字的字母都不可以小写,java是强类型语言【即严格区分变量类型和字母大小写】,后面紧跟需要实现的接口 * 9、接口名:接口名是需要实现的接口,什么是接口?用现实生活中的USB接口为例,接口只提供一个接入的端口途径,具体USB接口要实现什么功能根据插入的设备来决定,如我们插入一个U盘就可以存储,插入一个摄像头就可以摄像,所以也说明接口的具体实现取决于使用接口的设备。程序中的接口与此大致相同,接口的实现和继承类不同,一个类可以同时实现多个接口,也就是在implements后面可以跟多个接口名,用英文逗号分开 * 10、成员变量:成员变量如:int a;中a就是成员变量,类中的成员变量可以是简单类型,也可以是引用类型。 * 11、成员方法:后续讲解 * 12、构造方法:后续解释 * */ package 包名; 访问权限修饰符 class 类名 extends 父类名 implements 接口名 { 构造方法; 成员变量; 成员方法; }
我们会逐步讲解学习,不断丰富类,直到面向对象编程讲解完毕我们就能够认识一个完整的类。
刚才我们定义了一个猫类,猫类的格式如下
class 类名 { 成员变量; }
上方是我们当前认识类的一个层次。
出处出现了两个新词,成员变量和引用类型那什么是成员变量呢?
成员变量是类的基本组成部分,一般是基本数据类型,也可以是引用类型,比如我们定义的猫类的int age;就是成员变量.
引用类型简单的说就是指向了另一个类,在C++中的解释是指向了一个地址。引用类型举例如下
/* * 作者:Alvin * 功能:引用类型讲解 * 时间:2019年2月23日11:37:17 * */ public class Test { public static void main(String[] args) { // TODO Auto-generated method stub //这里的Master就是一个引用类型 Master mast; } } // 定义一个主人类 class Master { int age; String name; }
复习:一个Java源文件中最多只能有一个public类,当有一个public类时,源文件名必
须与之一致,否则无法编译,如果源文件中没有一个public类,则文件名与类中没有一致性要求。
至于main()不是必须要放在public类中才能运行程序。
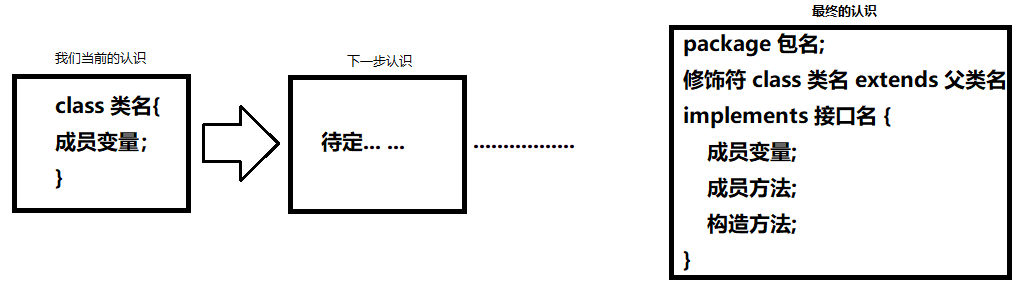
我们对于类的认识阶段如下图所示
五、创建一个对象
1、对象的创建
创建对象有两种方法一种是先声明在实例化【相当于对变量进行赋值】对象,另一种是一步到位。
①、先声明再实例化
结构
类名 对象名; 对象名=new 类名();
例如
//这里的Master是一个类 Master mast; mast=new Master();
②、声明的同时实例化对象
结构
类名 对象名=new 类名();
例如
//这里的Master是一个类 Master mast=new Master();
2、对象访问(使用)成员变量
一般情况下结构【目前认知内是可以的随着学习的深入,此种方式会有局限性】
对象名.成员变量名
例如
//通过该语句可以访问主人的名字 mast.name
3、拓展[了解]:内存与对象
1.Java关键字new是一个运算符。
2.创建一个Java对象需要三部:声明引用变量、实例化、初始化对象实例。
3.实例化:就是“创建一个Java对象”-----分配内存并返回指向该内存的引用。
4.初始化:就是调用构造方法,对类的实例数据赋初值。
5.Java对象内存布局:包括对象头和实例数据。如下图:
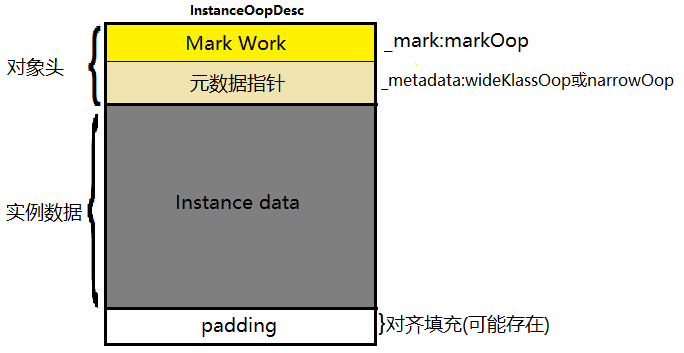
对象头:它主要包括对象自身的运行行元数据,比如哈希码、GC分代年龄、锁状态标志等;同时还包含一个类型指针,指向类元数据,表明该对象所属的类型。
实例数据:它是对象真正存储的有效信息,包括程序代码中定义的各种类型的字段(包括从父类继承下来的和本身拥有的字段)。
在hotSpot虚拟机中,对象在内存中的布局可以分成对象头、实例数据、对齐填充三部分。对齐填充:它不是必要存在的,仅仅起着占位符的作用。
6.Object obj = new Object();
那“Object obj”这部分的语义将会反映到Java栈的本地变量表中,作为一个reference类型数据出现。而“new Object()”这部分的语义将会反映到Java堆中,形成一块存储了Object类型所有实例数据值(Instance Data,对象中各个实例字段的数据)的结构化内存,根据具体类型以及虚拟机实现的对象内存布局(Object Memory Layout)的不同,这块内存的长度是不固定的。另外,在Java堆中还必须包含能查找到此对象类型数据(如对象类型、父类、实现的接口、方法等)的地址信息,这些类型数据则存储在方法区中。
4、对象对象赋值
/* * 作者:Alvin * 功能:实现对象与对象的赋值 * 时间:2019年2月23日13:42:47 * */ public class Test { public static void main(String []args) { //定义第一个猫 Cat cat1=new Cat(); cat1.age=10; cat1.name="小白"; //定义第二个猫 Cat cat2; cat2=cat1; System.out.println(cat2.age+cat2.name); //通过cat2修改猫的名字 cat2.name="小花"; System.out.println(cat1.name); System.out.println(cat2.name); } } class Cat{ String name; int age; }
输出结果
10小白
小花
小花
通过以上案例,我们可以这么不准确的理解:对象中保存的其实是指向实例数据的引用[即指针]。
六、类的成员方法
1、成员方法的定义
像我们人不但具有身高、体重、肤色等属性,还具有一些行为,如说话,会跑会跳等,这就对应了我们类中的成员方法。
下面我们先定义一个人类,包含肤色、体重和身高。
class Person{ String color; int weight; float height; }
既然人有行动,所以我们为人类添加一个说话的方法,在添加之前,我们先看一下方法的格式
/*首先明确方法的位置只能是类的内部,其他方法的外部,任何一个方法的内部都不能定义其他方法,但一个方法内可以调用另一个方法 * 1、访问权限控制符:说明该方法的允许被访问的范围,当前我们所知的是public * 2、返回值类型:当方法执行完毕后返回的结果,如果不需要返回结果则填写void说明 * 3、方法名:方法名是标识符,遵守标识符的>>>>命名规则和规范<<<< * 4、参数列表:参数列表是被调用时需要传来的被处理的数值,如果不需要传来值则可以为空,但是小括号不可以省略 * 5、方法体:方法体中包含方法的成员变量和成员方法,是处理问题的流程 * 6、return语句:return语句是返回经过该方法处理后的与返回值类型相同的值并结束当前方法,如果方法不需要返回值【即返回值类型为void】则return可以省略或写为return; * 7、补充:在return语句的下方不可以再编写任何无效代码,编译器会报错。 * */ 访问权限控制符 返回值类型 方法名(参数列表) { 方法体; return 返回值; }
根据以上的结构,我们现在给上面的Person类添加说话的方法,并说出:我是一个好人。
代码如下
//定义一个人类 class Person{ //定义人的属性 String color; int weight; float height; //定义speak方法,由于无返回值,所以使用void填充到返回值类型那里 public void speak() { System.out.println("我是一个好人"); } }
上面就创建了一个方法speak,方法只有被调用才能被执行,现在我们来在main方法中调用执行speak方法
public static void main(String[] args){ //创建人的对象 Person per=new Person(); //调用说话的方法 per.speak(); }
上面就完成了方法的调用
然不仅仅可以说话,还可以计算,我们再定一个用于计算的方法
/* * 作者:Alvin * 功能:为人类添加说话和计算方法 * 时间:2019年2月24日11:11:21 * */ public class Test2 { public static void main(String[] args) { // 创建人的对象 Person per = new Person(); // 调用说话的方法 per.speak(); //调用人的计算方法 per.cal(10, 90); } } // 定义一个人类 class Person { // 定义人的属性 String color; int weight; float height; // 定义speak方法,由于无返回值,所以使用void填充到返回值类型那里 public void speak() { System.out.println("我是一个好人"); } // 定一个cal方法,使用无返回值得类型,增加这个人的计算功能,需要两个参数 public void cal(int a, int b) { System.out.println(a + b); } }
我们看到,这个计算方法cal和说话方法speak不同,cal需要传递一个参数,而speak方法不需要传递参数,共同特点是即使不传递参数小括号也不会省略。有传递参数时传递的参数必须和方法中参数列表中的参数类型和顺序相同。
我们现在修改一下计算方法,让计算的结果不让它人类定义的那个对象自己说出来,让他计算出来后把答案传给另一个变量,然后系统通过变量把结果说出来。
/* * 作者:Alvin * 功能:为人类修改有返回值的计算方法 * 时间:2019年2月24日11:19:23 * */ public class Test2 { public static void main(String[] args) { // 创建人的对象 Person per = new Person(); // 调用说话的方法 //per.speak(); //调用人的计算方法并把结果传给result变量,接收结果的变量应和方法返回值类型一致 int result=per.calc(10, 90); //把得到的结果通过系统输出 System.out.println(result); } } // 定义一个人类 class Person { // 定义人的属性 String color; int weight; float height; // 定义speak方法,由于无返回值,所以使用void填充到返回值类型那里 // public void speak() { // System.out.println("我是一个好人"); // } // 定一个cal方法,使用有返回值类型,增加这个人的计算功能,需要两个参数 public int calc(int a, int b) { return a + b; } }
上面的方法就是有返回值得方法,通过return返回结果。
2、方法的重载
通过上面没有返回值的计算方法cal我们知道,我们知道我们现在的人类已经可以计算两个数的加法了,但是我们发现如果我们输入两个不同时为int类型的数值传给该方法则编译器会报错,所以,我们如何能同时让它可以计算其他类型的数值只和呢?如计算2.1+3等类型的和。
我们只需要通过对上面的方法进行修改就可以完成了,代码如下
/* * 作者:Alvin * 功能:方法的重载 * 时间:2019年2月24日11:38:18 * */ public class Test2 { public static void main(String[] args) { // 创建人的对象 Person per = new Person(); //调用人的计算方法 per.cal(10, 90); //计算两个浮点数之和 per.cal(2.1, 3.9); // 定一个cal方法,可以计算一个整数,一个浮点数之和 per.cal(2, 3.9); // 定一个cal方法,可以计算一个浮点数,一个整数之和 per.cal(2.1, 3); } } // 定义一个人类 class Person { // 定义人的属性 String color; int weight; float height; // 说明1、定一个cal方法,可以计算两个整数之和 public void cal(int a, int b) { System.out.println(a + b); } //说明2、 定一个cal方法,可以计算两个浮点数之和,使用double是因为java中浮点数的默认数据类型为double public void cal(double a, double b) { System.out.println(a + b); } //说明3、 定一个cal方法,可以计算一个整数,一个浮点数之和 public void cal(int a, double b) { System.out.println(a + b); } //说明4、 定一个cal方法,可以计算一个浮点数,一个整数之和 public void cal(double a, int b) { System.out.println(a + b); } }
计算结果
100 6.0 5.9 5.1
通过以上编码,我们实现了要求的功能。通过观察总结如下
1、类中的实现计算的各个方法名完全相同
2、不同方法的参数列表全部不同
像以上定义方法的形式我们称为方法的重载。
方法的重载(overload)的定义:在同一个类中,方法名一样,参数列表不一样,这些方法称为方法的重载,作用是在同一类中同一方法的不同实现方式,具体调用那个方法取决于接收的参数。
参数列表不一样,有三种情况:
a.参数个数不一样
如:
//此方法用来返回两个数的最小值,如果输入一个数就返回该参数本身 public int test(int a) { return a; } public int test(int a, int b) { if (a > b) return b; else return a; }
b.参数类型不一样
讲解见说明1和说明2
c.参数顺序不一样
见说明3和说明4
高能提示:方法的重载中只与上面两个方面有关,如果返回值类型不同不能构成重载。
3、为什么要进行方法重载
方法重载对编程人员来说是十份方便的,我们知道java是强类型语言,对数据类型有严格的限制,如果不予许重载,那么如果要解决上方计算两个数的和就需要程序员定义四个不同名字的方法,而通过重载只需要定义一个方法cal就可以了,大大减少了程序员编码的负担。使用相同的方法名,当进行调用时JVM会自动选择调用哪一个方法,不需要人为干预。
4、方法调用的流程
如图,了解就行,看下面两幅图
图一

图二
5、方法的声明
必须明确一点方法的声明和方法的定义最大的区别是没有函数体!!!对,你没有看错,没有函数体,样式如下
访问修饰符 数据类型 函数名(参数列表);
如
public int test(int a);/*方法的声明,注意大括号也没有*/
大家或许顾虑,一个方法没有方法体为什么要声明呢?方法的声明是为了在以后的抽象类和接口中使用的。目前先不涉及该内容,后续会有讲解。再次提醒注意没有大括号!!小括号后面直接跟英文分号;
到此为止,我们目前更加完善了对类的认识。

第五讲 构造方法
一、类的构造方法介绍
什么是构造方法?下面我们提出一个需求:我们在用前面创建的人类创建一个对象后,需要再给已经创建的对象的属性赋值。如果现在要求,在创建人类的对象之后就直接指定该对象的年龄和姓名,该怎么做?此时使用构造方法就可以解决。这句话就可以表达构造方法的作用。你可以在定义类的时候定义一个构造方法。
构造方法是类的一种特殊方法,它的主要作用是完成对使用该类创建的对象的初始化。它具有以下特点
①、方法名和类名相同
②、没有返回值类型,就是在方法的返回值类型处空下来
③、在创建一个类的新对象时,系统会自动的调用该类的构造方法完成对新对象的初始化
案例如下
class Test2 { public static void main(String[] args) { Person per=new Person(30,"xiaoming"); System.out.println("名字:"+per.name+"体重:"+per.weight); } } //定义一个人类 class Person{ //定义人的属性 String name; int weight; float height; public Person(int weight,String name) { this.weight=weight; this.name=name; } //定义speak方法,由于无返回值,所以使用void填充到返回值类型那里 public void speak() { System.out.println("我是一个好人"); } }
执行结果
名字:xiaoming体重:30
从这里我们了解到其实在new运算符后面跟着的就是构造方法。当我们创建人类对象并通过new实例化这个对象,通过构造方法传过去的参数可以完成对对象属性在初始化时的属性赋值。
从现在开始我们开始使用开发工具进行编码。我们使用的开发工工具是eclipse【大家目前大家都在转用idea,我感觉开发工具适合自己最好。】,开发工具可以在eclipse的官网下载,免费使用【idea是收费的】。
至于开发工具的使用方法大家可以自行百度,搜索步骤,第一步搜索下载你想使用的开发工具,第二步搜索如何安装该开发工具【如果是付费的还需要搜索如何破解,有钱的可以忽略,直接买,】,第三部搜索如何在该开发工具中创建项目,并创建运行项目。
下面我们对下面的图片仔细观察第7行代码
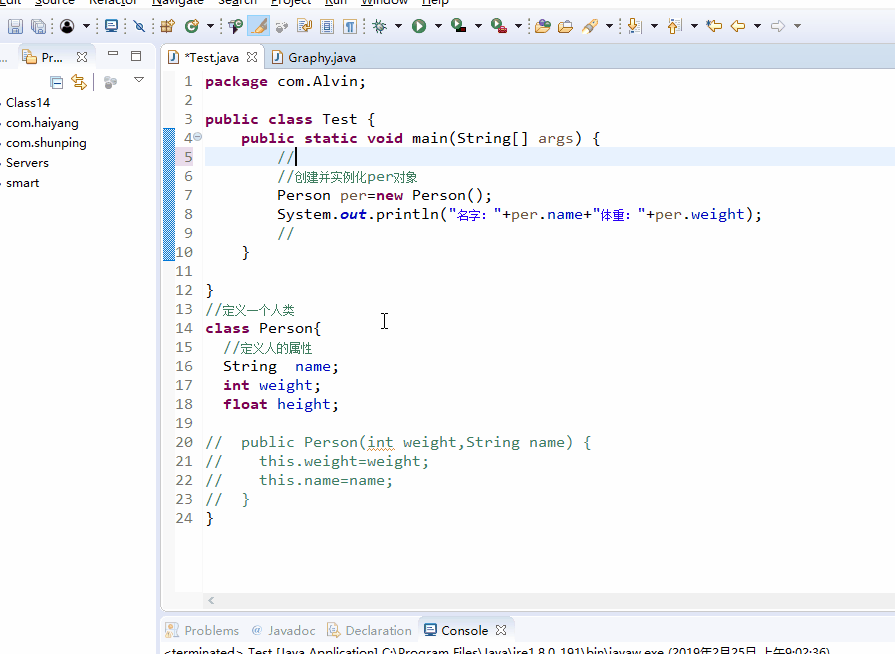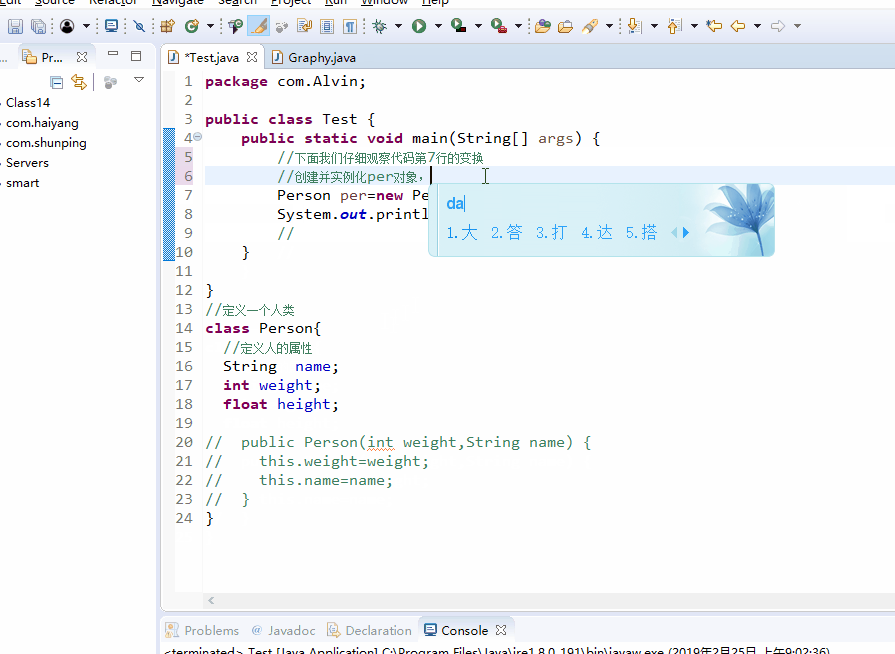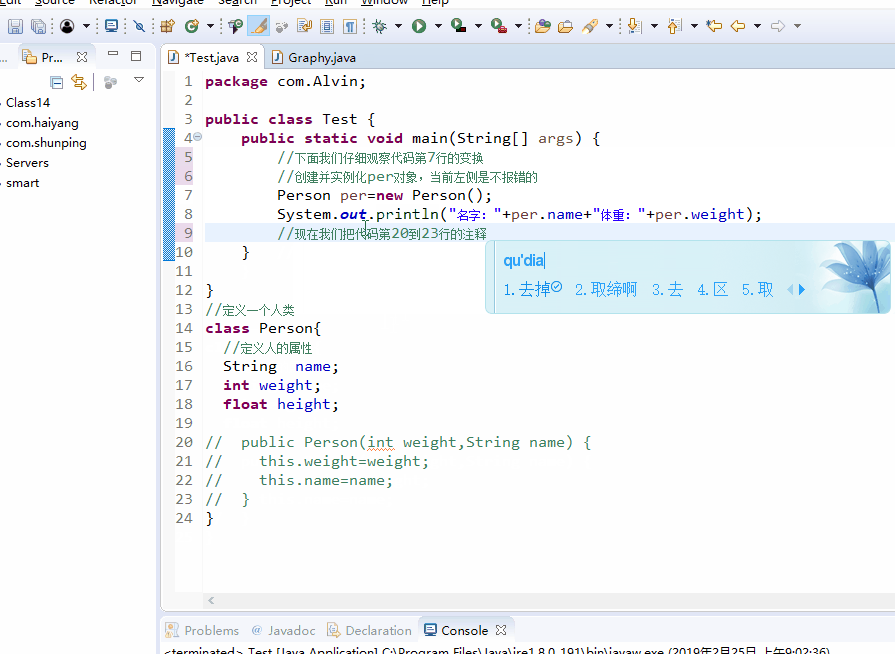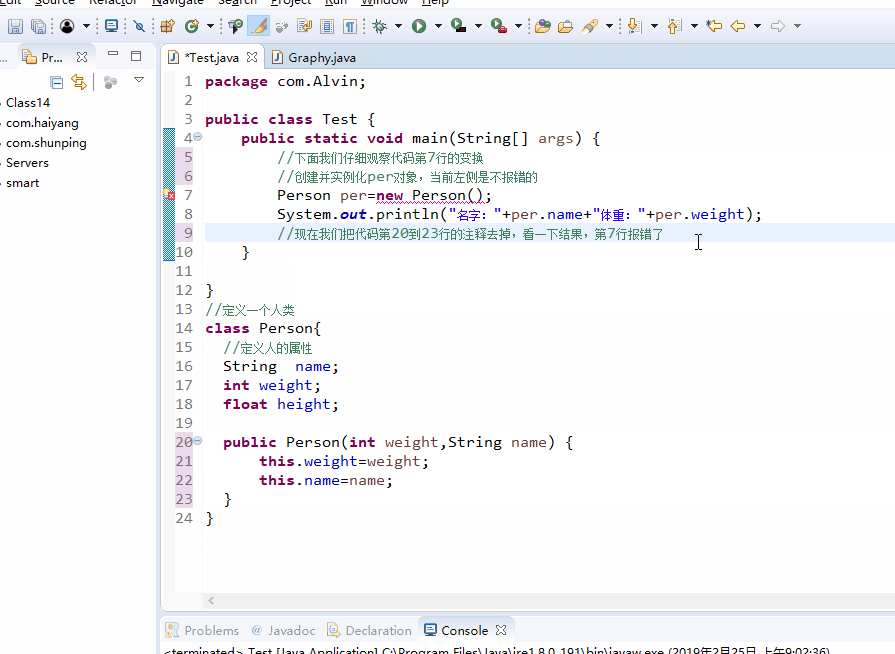
上面这种情况是为什么呢?为什么当我们没有对Person类写构造方法的时候调用该类的构造方法是对的,当我们定一个构造方法反而报错了呢?
原因是当该Person类没有创建构造方法时,系统会自动生成一个构造方法,当我们自己写了一个构造方法后系统就不再为该类创建构造方法,如果想恢复默认的构造方法只需要删除我们定义的方法,或者写一个空的构造方法。
构造方法与其他方法的不同点除了是在new运算中初始化成员变量的属性,其他的特点和普通的方法大致相同,构造方法也可以被重载。
最后小结:
①、方法名和类名相同
②、构造方法没有返回值
③、主要作用是完成对新对象属性的初始化,严重鄙视在构造方法中执行一些方法操作,如连接数据库等
④、在一个类中可以有多个构造方法,即构造方法可以被重载
⑤、每个类都有一个默认的构造方法
来现在我们再来看一下我们目前对类的了解范围
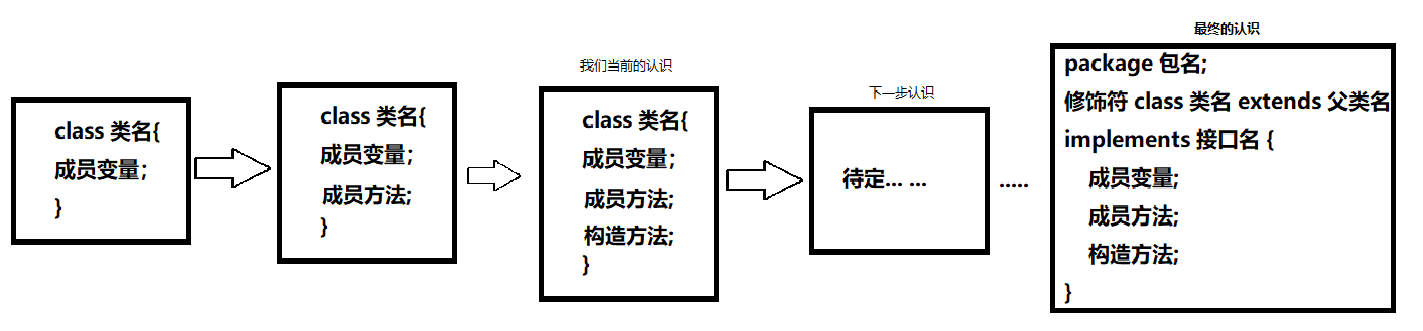
恭喜、又对类有了更深一层的认识。
第六讲 this、类变量
一、this代词
在本节。我们将了解什么是this代词。其实在上面的程序中我们已经见过this这个代词。
就在这张图中的第21和22行
那么这个this究竟是干什么的呢?其实这个this是用来为创建的对象而设计的关系代词,也就是说当我们用上面的Person类去创建两个该类的对象时,jvm就为这两个对象分别创建了this代词,所以每个对象都有一个this。这个代词就相当于我们每个人都说“我的”这个代词时所有的指向都是自己一样。创建了哪个对象,哪个对象就拥有他所拥有的this。下面我们看一个例子
/* * 作者:Alvin * 功能:讲解this代词 * 时间:2019年2月25日12:59:48 * */ public class Test { public static void main(String[] args) { Dog dog1=new Dog("小黄",34); Dog dog2=new Dog("小白",23); dog1.showInfo(); dog2.showInfo(); } } class Dog{ String name; int age; public Dog(String name,int age) { this.age=age; this.name=name; } public void showInfo(){ System.out.println("这条狗的名字是:"+this.name+";这条狗的年龄是:"+this.age); } }
输出结果为
这条狗的名字是:小黄;这条狗的年龄是:34 这条狗的名字是:小白;这条狗的年龄是:23
通过以上案例我们看到,在输出语句的this.age和this.name虽然相同,但是这是两个不同的狗(对象)做出的信息展示。
然后我们在定义一个人,让这个人养一只狗
/* * 作者:Alvin * 功能:讲解this代词 * 时间:2019年2月25日12:59:48 * */ public class Test { public static void main(String[] args) { //创建一个人的对象 Person per=new Person("小明", 23); //访问方法中基本数据类型成员变量的值 per.showInfo(); //通过对象访问引用数据类型中的值 per.dog.showInfo(); } } //定义人类 class Person{ //定义人属性 String name; int age; //引用数据类型的属性定义 Dog dog=new Dog("大黄",32); //定义人类的构造方法 public Person(String name,int age){ //通过this代词进行赋值 this.name=name; this.age=age; } public void showInfo() { System.out.println("名字是:"+this.name+"年龄是:"+this.age); } } //定义狗类 class Dog{ String name; int age; //狗的构造方法 public Dog(String name,int age) { //通过this代词进行赋值 this.age=age; this.name=name; } //用于展示狗的信息 public void showInfo(){ System.out.println("这条狗的名字是:"+this.name+";这条狗的年龄是:"+this.age); } }
通过以上代码我们发现,在类中访问引用数据类型的值和访问一般基本类型成员变量的过程相似,大致相同。
![]() this代词使用时注意,this不能再该类定义的外部使用,只能在该类定义的方法中使用。
this代词使用时注意,this不能再该类定义的外部使用,只能在该类定义的方法中使用。
this代词的应用场景
this关键字主要有三个应用:
(1)this调用本类中的属性,也就是类中的成员变量;
(2)this调用本类中的其他方法;
(3)this调用本类中的其他构造方法,调用时要放在构造方法的首行。
应用一:引用成员变量
Public Class Student { String name; //定义一个成员变量name private void SetName(String name) { //定义一个参数(局部变量)name this.name=name; //将局部变量的值传递给成员变量 } }
this这个关键字其代表的就是对象中的成员变量或者方法。也就是说,如果在某个变量前面加上一个this关键字,其指的就是这个对象的成员变量或者方法,而不是指成员方法的形式参数或者局部变量。
为此在上面这个代码中,this.name代表的就是对象中的成员变量,又叫做对象的属性,而后面的name则是方法的形式参数,代码this.name=name就是将形式参数的值传递给成员变量。
应用二:调用类的构造方法
public class Student { //定义一个类,类的名字为student。 public Student() { //定义一个方法,名字与类相同故为构造方法 this(“Hello!”); } public Student(String name) { //定义一个带形式参数的构造方法 } }
在一个Java类中,其方法可以分为成员方法和构造方法两种。构造方法是一个与类同名的方法,在Java类中必须存在一个构造方法。如果在代码中没有显示的体现构造方法的话,那么编译器在编译的时候会自动添加一个没有形式参数的构造方法。这个构造方法跟普通的成员方法还是有很多不同的地方。如构造方法一律是没有返回值的,而且也不用void关键字来说明这个构造方法没有返回值。而普通的方法可以有返回值、也可以没有返回值,程序员可以根据自己的需要来定义。不过如果普通的方法没有返回值的话,那么一定要在方法定义的时候采用void关键字来进行说明。其次构造方法的名字有严格的要求,即必须与类的名字相同。也就是说,Java编译器发现有个方法与类的名字相同才把其当作构造方法来对待。而对于普通方法的话,则要求不能够与类的名字相同,而且多个成员方法不能够采用相同的名字。在一个类中可以存在多个构造方法,这些构造方法都采用相同的名字,只是形式参数不同。Java语言就凭形式参数不同来判断调用那个构造方法。
应用三:返回对象的值
this关键字除了可以引用变量或者成员方法之外,还有一个重大的作用就是返回类的引用。
如在代码中,可以使用return this,来返回某个类的引用。此时这个this关键字就代表类的名称。如代码在上面student类中,那么代码代表的含义就是return student。可见,这个this关键字除了可以引用变量或者成员方法之外,还可以作为类的返回值,这才是this关键字最引人注意的地方。
public Class Student { String name; //定义一个成员变量name private void SetName(String name) { //定义一个参数(局部变量)name this.name=name; //将局部变量的值传递给成员变量 } Return this }
原文:https://blog.csdn.net/yanwenwennihao/article/details/79375611
二、类变量、类方法
1、类变量
本节我们将了解什么是类变量和类方法,从名词上理解就是这些变量和方法是属于类的。既然是属于类的,而类就是一个模板,那么由该类创建的所有对象都可以使用和访问。
我们先引入一个例子加深理解
问题:一群孩子玩堆雪人,不时会有孩子加入,请问当一个孩子加入后如何计算出现在共有多少人在玩?
分析:我们知道,一个孩子就是一个对象,当一个孩子加入后如果有一个量可以允许该对象访问然后让该变量加一多好?
根据以上分析,在java中就提供了该中类型的变量——类变量!
代码如下
/* * 作者:Alvin * 功能:静态变量讲解以及访问案例-堆雪人 * 时间:2019年2月25日13:51:01 * */ public class Test { public static void main(String[] args) { Child ch1=new Child("小明", 15); ch1.showInfo(); Child ch2=new Child("小黄", 14); ch2.showInfo(); Child ch3=new Child("小化", 13); ch3.showInfo(); Child ch4=new Child("小量", 10); ch4.showInfo(); } } //定义小孩类 class Child{ String name; int age; //用static修饰的变量就是静态变量,该变量就允许所有的Child类创建的对象共享访问 static int total=0; //Child的构造方法 public Child(String name,int age) { //通过this代词进行赋值 this.age=age; this.name=name; } //用于展示人数的信息 public void showInfo(){ this.total+=1; System.out.println("现在的人数是:"+this.total); } }
输出结果
现在人数是:1 现在人数是:2 现在人数是:3 现在人数是:4
我们发现,static修饰的变量不会随着每次对象的创建而重新赋值为0,该变量实现了对该类创建的所有对象的共享。
对该静态变量还有一种访问方式,就是通过类名进行访问。上方代码做如下修改
/* * 作者:Alvin * 功能:静态变量讲解及类名访问案例-堆雪人 * 时间:2019年2月25日13:58:23 * */ public class Test { public static void main(String[] args) { Child ch1=new Child("小明", 15); Child.total+=1; System.out.println("现在人数是:"+Child.total); Child ch2=new Child("小黄", 14); Child.total+=1; System.out.println("现在人数是:"+Child.total); Child ch3=new Child("小化", 13); Child.total+=1; System.out.println("现在人数是:"+Child.total); Child ch4=new Child("小量", 10); Child.total+=1; System.out.println("现在人数是:"+Child.total); } } //定义小孩类 class Child{ String name; int age; //用static修饰的变量就是静态变量,该变量就允许所有的Child类创建的对象共享访问 static int total=0; //Child的构造方法 public Child(String name,int age) { //通过this代词进行赋值 this.age=age; this.name=name; } }
输出结果
现在人数是:1 现在人数是:2 现在人数是:3 现在人数是:4
也就是说静态变量【或类变量】可以通过类名直接访问。
总结:
1、类变量是该类的所有对象共享的变量,任何一个该类的对象去访问它时取到的都是相同的值,同样任何一个该类的对象去修改它时修改的也是同一个变量。该变量被分配在内存中的静态区。
类变量的格式
访问权限控制符 static 数据类型 变量名;
2、访问类变量的形式有两种
类名.类变量名 或者对象名.类变量
一个类的静态变量可以被该类的任何一个对象访问。也是唯一一个可以通过类名.静态变量,但是普通变量是不能这么干的。
观察下列程序,说出执行后的结果

执行结果为:


3 4
对上方代码的解释
必须明白的
1、由static修饰的静态代码块[上图的5-8行]在代码执行时直接被加载到内存中的静态区,且仅执行一次自加操作。十份重要的一点,静态区块的代码只会被执行一次,无论创建多少个对象都只是执行一次。
2、构造方法中的自加操作会在对象初始化的时候执行一次自加操作,i变量是静态变量,所以在对象中的该类构造方法执行的自加操作就会在静态变量上加1,也就是说每创建一个对象就会执行一次构造方法,执行一次自加操作。
上方的代码执行的顺序是【行号,只写主要步骤】
4——》7——》16——》9——》11——》17——》19——》11——》20
上方的static代码块只执行了一次。即使你不创建Demo3_2对象程序也会直接令动态变量i存储在内存中。
当你去实例化一个对象的时候,就不会再执行static这块代码块了,其他代码就该怎么走就怎么走。
拓展文章:>>静态变量如何在内存中的存放位置<<
2、类方法【又称静态方法】
什么是类方法,为什么有类方法?类方法是属于所有对象实例的,其形式如下:
访问修饰符 static 数据返回类型 方法名(){};
注意:类方法中不能访问非静态变量(类变量)。
使用:类名.类方法名 或者 对象名.类方法名
下面我们看一个小案例。(统计学费总和),源码如下
先定义一个学生类
//定义学生类 class Stu{ int age; String name; int fee; static int totalFee; public Stu(int age,String name,int fee) { this.age=age; this.name=name; totalFee+=fee; } //返回总学费 public int getTotalFee() { return totalFee; }
然后在main方法中创建对象并实例化
//定义一个Stu对象 Stu stu1=new Stu(29,"当归",368); Stu stu2=new Stu(29,"王明",78); System.out.println("总费用:"+stu2.getTotalFee()); System.out.println("总费用:"+stu1.getTotalFee());
输出结果如下
总费用:446
总费用:446
虽然我们看到上面的方法解决了问题,但是我们发现,对于getTotalFee方法对每一个创建的对象都会拥有一个该方法,并且该方法会占用内存,造成资源的浪费。
所以,如果有一个方法能够被所有Stu创建的类共享就好多了,这样既节约了资源又达到了目的。这时类方法就能够达到我们所期望的目的。该方法改造后的结果如下。
//返回总学费 public static int getTotalFee() { return totalFee; }
上面的方法就会被所有共同的类创建的对象所共享。当我们在调用的时候就不会在内存中再分配内存。
注意一点:java中规则---【自己定的规则】类变量原则上用类方法去访问
java中规定,类方法中只可以访问静态变量不可以访问成员变量。但成员方法中既可以访问类变量也可以访问成员变量。
总结:
一、类变量和实例变量最大的区别如下
1、加上static称为类变量或静态变量,否则称为实例变量
2、类变量是与类相关的,公共的属性
3、实例变量属于每个对象个体的属性
4、类变量可以通过类名.类变量名直接访问【前提是成员访问权限控制符允许访问】
二、类方法的小结
1、类方法属于与类相关的,公共的方法
2、实例方法属于每个对象个体的方法
3、类方法可以通过 类名.类方法名 直接访问
三、关于静态代码块的最后说明
1、静态代码块只会在创建对象的时候执行一次。
2、无论创建多少个该类的对象,该代码块只会执行一次
3、静态代码块的优先级在该类中最高,优于主方法和构造方法
拓展阅读:>>类静态成员变量的存储位置及JVM的内存划分 <<、>>JVM几种常量池的区分<<
第七讲 类的三大特征
初步理解类的封装、继承、多态。这三大特征是公认的java面向对象的三大特征。
在前面我们定义的类都是抽象出来的共有属性,形成一个数学物理模型,也称为模板,这种研究问题的模板我们成为抽象。如只要是人他都有肤色、血型、身高、体重等属性,那么我们把这些人的共有属性抽象出来形成一个模型就是我们所需要的人类Person。
1、封装
所谓封装就是我们把抽象出来的属性和方法都通过类包裹在一起,数据通过类的包裹在内部被保护起来。通过访问权限控制符只允许其他部分访问被授权访问的操作。举例来说就像电视机,我们手里的遥控器提供的按钮就是对外授权的操作,至于我们按下遥控按钮后的操作我们无法碰触,这些操作都被电视机给包裹起来,我们唯一能感知的就是显示器带来的反馈。
类是通过访问权限控制符对内部的成员变量和方法进行保护的。
那么什么是访问权限控制符?我们前面接触到的访问权限控制符只有public,其实访问权限控制符还有三种,如下表
| 访问级别 | 访问控制修饰符 | 同类 | 同包 | 子类 | 不同包 |
| 公开 | public | √ | √ | √ | √ |
| 受保护 | protected | √ | √ | √ | |
| 默认 | 没有修饰符 | √ | √ | ||
| 私有 | private | √ |
说明:java提供四种访问控制修饰符号控制方法和变量的访问权限
1、公开级别:用public修饰,对外公开
2、受保护级别:用protected修饰,对子类和同一个包中的类公开
3、默认级别:没有修饰符号,向同一个包的类公开
4、私有级别:private修饰,只有类本身可以访问,不对外公开
首先明确包的概念:
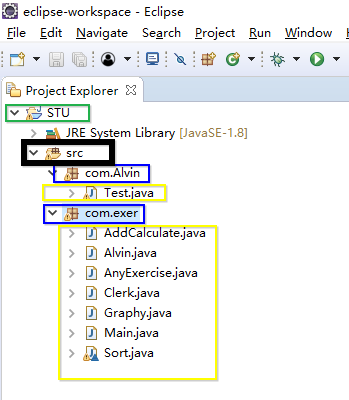
引入:上图中绿色方框内的是项目(project)名称,黑色方框内的是java源码存放的目录,src是source的缩写,src目录下的蓝色方框是包(package),橘黄色区域内的是我们的java源文件存放的位置。
从上面可以看出包的作用是用来划分java源文件划分区域的,例如支付宝开发中,不同的模块会有不同的包名进行存储java源文件,不同包名会有不同的模块开发,但是这些模块中可能涉及到共同的类名,通过包可以把相同的类名放置在不同的包中不至于混淆,而在同一个包中不可以拥有相同的类名。其实包的本质就是文件夹,通过英文句号.来区分上下级。
介绍:
1、包的作用如下
①、区分相同名字的类
②、当类很多时,可以很好的管理类
③、控制访问范围
2、package关键字
每一个java源文件都在文件头部加入了package关键字,标明该文件在该项目中所在的包路径。格式如下
package 包名;
如 :
package com.tecen.pay;
注意:该行代码必须放在每个java文件的第一句,且每个java文件中只能有一行该代码。
3、包的命名规范
包在命名的时候字母务必全部小写。
4、常用包
在我们以后的开发中会经常用到以下包【无需记忆,需要的时候通过ctrl+shift+O快捷键就可以导入】
java.lang.*; java.util.*; java.net.*; java.awt.*;
下面我们演示一个动态图,用来展示包的导入。
5、包的导入
导入格式
import 包名;
引入包的目的是要使用该包内的方法。
如下导包案例
import java.awt.*;
好了,下面通过一个例子来感受一下部分访问控制修饰符的作用。
我们来创建一个职员类Clerk,要求不能随便查看职员的工资年龄和隐私。这个时候在设计类的时候我们就需要通过访问控制修饰符进行处理了。源码如下
//职员 class Clerk { //职员的工资和年龄属性通过private进行修饰 public String name; private int age; private float salary; public Clerk(String name, int age, float salary){ this.name=name; this.age=age; this.salary=salary; } }
在上方的private修饰的属性,按照上面的表格的说明,被修饰的属性只能在该类,即Clerk类中被访问,在其他类中不能被访问。
如果我们强行在其他类中进行访问,则代码如下
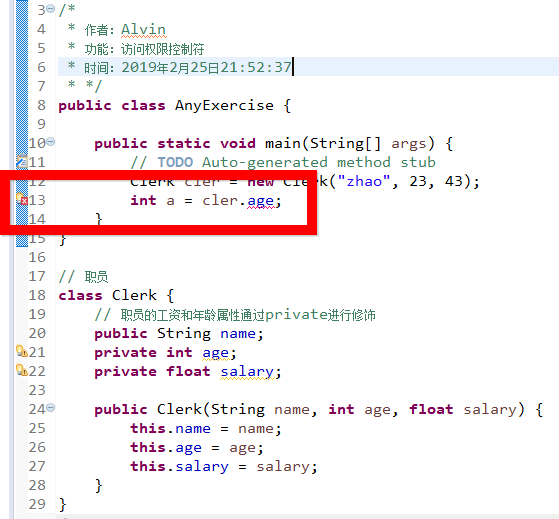
我们看到,虽然我们在其他类中用对象强行访问,但是编译器会报错的。
那么既然类中的成员变量通过private访问控制修饰符不再对该类以外开放访问权限,对数据进行了保护,我们如何进行访问该变量呢?
我们可以通过在该类内部定义一个可以跨类访问的方法进行访问(如protected),如
/* * 作者:Alvin * 功能:访问权限控制符-protected * 时间:2019年2月26日09:24:20 * */ public class AnyExercise { public static void main(String[] args) { // TODO Auto-generated method stub Clerk cler = new Clerk("zhao", 23, 43); //通过Clerk中的protected修饰的方法进行访问。 System.out.println(cler.getAge()); System.out.println(cler.getSalary()); } } // 职员 class Clerk { // 职员的工资和年龄属性通过private进行修饰 public String name; private int age; private float salary; public Clerk(String name, int age, float salary) { this.name = name; this.age = age; this.salary = salary; } //访问被private访问控制修饰符修饰的成员变量的 protected int getAge() { return age; } //访问被private访问控制修饰符修饰的成员变量的 protected float getSalary() { return salary; } }
执行结果如下
23 43.0
可以看出,我们通过访问protected修饰的方法是可以访问到类中的静态变量的,实现了类变量的跨类访问.既然protected可以跨类访问,那么他可以跨包访问么?我们来测试一下
首先在包com.jihaiyang包【关于包的定义可以自行百度】中定义一个public类,然后定义两个protected修饰的方法。结构如下图
在类Clerk中输入如下代码
//职员 public class Clerk { // 职员的工资和年龄属性通过private进行修饰 public String name; private int age; private float salary; public Clerk(String name, int age, float salary) { this.name = name; this.age = age; this.salary = salary; } //访问被private访问控制修饰符修饰的成员变量的 protected int getAge() { return age; } //访问被private访问控制修饰符修饰的成员变量的 protected float getSalary() { return salary; } }
在Test类中输入如下代码
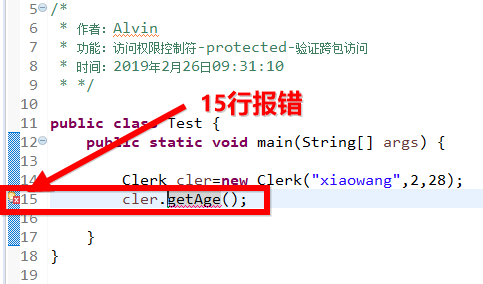
/* * 作者:Alvin * 功能:访问权限控制符-protected-验证跨包访问 * 时间:2019年2月26日09:31:10 * */ public class Test { public static void main(String[] args) { Clerk cler=new Clerk("xiaowang",2,28); cler.getAge(); } }
我们看到,被protected修饰的方法getAge和getSalary是不能够跨包访问的,即使我们强制编写访问该方法,编译器是报错的
上方都验证了private和protected修饰后的访问范围。默认修饰符下是允许同包中访问的,如都在com.Alvin下进行访问,而在子类【在继承中讲解】中是不允许被访问的,protected允许子类进行访问,public允许同一个工程内所有范围的访问,不同工程之间是不允许被访问的,除非哪个项目打包后被这个项目引用。
在回顾一下刚开始将的访问控制修饰符


我们前面也见到过static,那么当多个访问控制修饰符同时出现时的书写规范是什么?
oracle.com教材中描述,如果两个或两个以上的(不同的)字段修饰符出现在字段声明,它们出现的顺序需与FieldModifier一致,这只是习惯,但不是必需的。
FieldModifier顺序>>"public protected private static final transient volatile"<<
如果以后我们想在JSP页面中通过标签来操作Java类,那么我们所写的Java类就必须遵守JavaBean规范。JavaBean类的组成包括其属性和方法。
一个完整规范类————JavaBean的规范
1、JavaBean类必须是一个公共类。
2、JavaBean类中必须包含两个类,一个是无参的构造方法,一个是全参的构造方法。
3、JavaBean类中所有的成员变量必须为私有,必须被private修饰。
4、JavaBean类中必须为私有成员变量提供set和get方法
参考讲解>>javaBean规范<<、>>【了解】什么是javabean及其在JSP中的用法<<
2、继承
继承是什么?为什么要继承,我们先看一段代码
//小学生类 class pupil{ //定义成员属性 private int age; private String name; private float fee; public int getAge() { return age; } public void setAge(int age) { this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public float getFee() { return fee; } public void setFee(float fee) { this.fee = fee; } //缴费 public void pay(float fee) { this.fee=fee; } } //中学生类 class MiddleStu{ //定义成员属性 private int age; private String name; private float fee; public int getAge() { return age; } public void setAge(int age) { this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public float getFee() { return fee; } public void setFee(float fee) { this.fee = fee; } //缴费 public void pay(float fee) { this.fee=0.8f*fee; } } //大学生类 class ColStu{ //定义成员属性 private int age; private String name; private float fee; public int getAge() { return age; } public void setAge(int age) { this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public float getFee() { return fee; } public void setFee(float fee) { this.fee = fee; } //缴费 public void pay(float fee) { this.fee=0.5f*fee; }
我们看一下,上面的代码在定义小学生,中学生和大学生类的过程中,大部分的代码都是相同的,所以这样写代码看起来太过于冗余,没有提高代码的复用率,影响板式。那么有没有什么方法可以这样:先在一个类中把所有类共用的属性或方法给封装起来,当其他的类在定义的时候可以直接从中继承这个类,达到即编写美观又提高代码的复用率呢?答案很显然是有,看如下代码
修改后的代码如下
//我们先定义一个学生类,把是学生都共有的属性都写上 class Stu{ //定义成员属性 public int age; public String name; public float fee; } //小学生类通过extends关键字继承学生类 class pupil extends Stu{ //缴费 public void pay(float fee) { this.fee=fee; } } //中学生类 class MiddleStu extends Stu{ //缴费 public void pay(float fee) { this.fee=0.8f*fee; } } //大学生类 class ColStu extends Stu{ //缴费 public void pay(float fee) { this.fee=0.5f*fee; } }
通过对比我们发现,除了第一个定义的学生类Stu,其他类都符合如下的定义格式
访问控制修饰符 class 类名 extends 父类名{ 成员变量和方法; }
上面的格式就是类的继承的定义格式。
我们知道在现实世界中,我们会从父辈继承父辈已有的特性,而编程中的继承思想正好对应了现实生活中的继承,使编程更符合人类思维。当多个类具有多种相同属性时可以从这些类中抽象出来一个父类,把相同的属性封装在父类中,其他的类【即子类】通过继承父类来直接拥有父类的一些特征【不一定是全部特征,因为父类中如果成员变量被某些变量、方法修饰则该变量、方法是不可以被继承的】,这种做法即提高了代码利用率,有使代码简洁易懂。
那么父类中的那些方法和属性可以被子类继承呢?
此处不再用代码演示【因为静态的东西无法直观的展示,录制动态图又太大了,无法上传。】,直接记住结论
结论:父类的public、protected、默认【就是不写修饰符】修饰的属性和方法可以被子类继承,而父类中private修饰的属性和方法不可以被子类继承。所以编程中如果你不想子类继承父类中的某个方法或属性就可以用private修饰符进行修饰。
有些人可能会把访问修饰控制符的访问权限和类在继承父类中的继承范围给混淆。访问控制修饰符是用来对修饰后的成员变量和成员方法在不同范围的类和包中的访问进行限制的,而子类能否继承自父类的哪些属性只存在于子类和父类之间的关系,结论表明只要被private修饰的成员属性和方法都不可以被继承,只要不被private修饰的成员方法和成员变量都可以被继承。
继承的注意事项:
1、子类只能继承一个父类【就像儿子只能有一个爸爸】,java中可以通过接口来变相弥补这个弊端,另外Java中允许A类继承B类,然后B类又是继承自C类...这种类型的多层继承。
2、java中所有类都是Object的子类【不信可以查JDK 的API文档】
3、java中有3000多个类,我们只需掌握150个类就行了
4、编程过程中不知道怎么办了怎么办————问Google大神!似乎现在只能百度了
5、多查jdk帮助文档
6、开发过程中有些类必须使用jdk提供的已经写好的类
当前我们对类的认识程度如下图
方法的覆盖【也称方法的重写】前面我们介绍了方法的重载,了解到同一类中可以通过方法的重载实现同一方法的不同实现。下面我们介绍方法的覆盖。
首先必须明确的是方法的覆盖是存在与父类和子类之间的,这不同于方法的重载。我们先看一个如下案例。要求
定义一个父类Animal,定义动物类的成员属性和成员方法,在定义Animal的子类Cat、Dog,然后让Dog和Cat拥有发出各自声音的方法。
源码如下
/* * 作者:Alvin * 功能:方法的覆盖 * 时间:2019年2月27日11:13:58 * */ public class Test { public static void main(String[] args) {
//本别创建三个实例并调用三个实例中的方法 Dog dog=new Dog(); dog.say(); Cat cat=new Cat(); cat.say(); Animal ani=new Animal(); ani.say(); } } // 定义父类Animal class Animal { int age; String name; // 定义方法叫,因为是动物类,不同的动物会发出不同的叫声,所以此处的叫声输出我是动物,我不知道怎么叫 public void say() { System.out.println("我是动物,我不知道怎么叫、、、、、、、"); } } // 猫类 class Cat extends Animal{ public void say() { //猫类,发出喵喵叫 System.out.println("我是猫,喵............"); } } //狗类 class Dog extends Animal{ public void say() { //狗类,发出汪汪叫...... System.out.println("我是狗,汪汪.........."); } }
运行结果
我是狗,汪汪..........
我是猫,喵............
我是动物,我不知道怎么叫、、、、、、、
通过以上案例我们发现,方法的覆盖会发生在子类中,覆盖的是父类中的方法, 并且必须是在子类中编写与父类中一模一样的同名方法,包括访问控制修饰符,返回值,方法名和方法参数。覆盖的目的就是子类想要继承父类的某个方法但是该方法的作用又和父类的方法有些不同就需要方法的覆盖。例如生活中小明的父亲和小明都具有工作的能力,但是小明的父亲是医生,而小明是教师,所以在实现工作方法行为的时候小明的方法就需要覆盖父类的医生工作去做自己的教师工作。
方法覆盖的注意事项:方法覆盖总的来讲有以下两点。【总结】
①、子类的方法的返回类型,参数,方法名称,要和父类方法的返回类型,参数,方法名称完全一样,否则编译出错。
②、子类方法不能缩小父类方法的访问权限。
上发的第二条中,说明访问控制符是可以不一样的,但是子类中的访问控制符要么与父类的访问控制符要么权限一样,要么比父类的访问控制符的权限大,但一定不能比父类的访问控制符权限小。
super代词的产生为了解决子类与父类中的成员变量名重名的问题。在继承中如果父类拥有默认构造,则子类的任何一个构造中都会在该构造的第一句中添加super();语句用来表示引用父类的构造,同理补充this代词也有构造传递。通过super.方法名直接调用父类中的某方法中的方法体可以调用父类中的该方法。
3、多态
多态这个词从字面上理解就是一个类【指一个引用或类型】的多种状态。如我们前面讲到的交学费问题,有小学生类、中学生类和大学生类,而这些类都继承自Stu类,所以Stu的子类就是Stu类的不同状态,故而继承可以实现一个类的多种状态,故而说继承是实现多态的一种条件。在后面我们还要讲解一个知识点,接口(interface),接口也可以通过不同的接入而实现不同的功能,就像计算机的USB接口可以插入U盘实现数据存储、插入摄像头实现图形传输等,也是通过一个USB实现了不同的工作状态。同样的例子还用前面讲到的Animal类与子类Dog类和Cat类等。另外还有抽象类(abstract)【后续讲解】所以说多态实现途径有继承、接口和抽象类。那么我们如何实现多态呢?
1、多态的继承实现
下面把以前举例使用的一个代码拿过来,该代码是Animal类和子类Dog、子类Cat的,源码如下
/* * 作者:Alvin * 功能:继承的演示 * 时间:2019年2月28日14:32:38 * */ public class Test { public static void main(String[] args) { //本别创建三个实例并调用三个实例中的方法 Dog dog=new Dog(); dog.say(); Cat cat=new Cat(); cat.say(); Animal ani=new Animal(); ani.say(); } } // 定义父类Animal class Animal { int age; String name; // 定义方法叫,因为是动物类,不同的动物会发出不同的叫声,所以此处的叫声输出我是动物,我不知道怎么叫 public void say() { System.out.println("我是动物,我不知道怎么叫、、、、、、、"); } } // 猫类 class Cat extends Animal{ public void say() { //猫类,发出喵喵叫 System.out.println("我是猫,喵............"); } } //狗类 class Dog extends Animal{ public void say() { //狗类,发出汪汪叫...... System.out.println("我是狗,汪汪.........."); } }
运行结果如下
我是狗,汪汪.......... 我是猫,喵............ 我是动物,我不知道怎么叫、、、、、、、
现在我们稍微修改一下上方代代码-----修改之后代码如下
/* * 作者:Alvin * 功能:多态实现的演示————继承 * 时间:2019年2月28日14:38:15 * */ public class Test { public static void main(String[] args) { //本别创建三个实例并调用三个实例中的方法 /* Dog dog=new Dog(); dog.say(); Cat cat=new Cat(); cat.say(); Animal ani=new Animal(); ani.say(); */ //本次修改的代码如下
//使用父类定义对象,使用子类引用
Animal ani=new Animal();
ani.say();
Animal aniCat=new Cat();
aniCat.say();
Animal aniDog=new Dog();
aniDog.say();
} } // 定义父类Animal class Animal { int age; String name; // 定义方法叫,因为是动物类,不同的动物会发出不同的叫声,所以此处的叫声输出我是动物,我不知道怎么叫 public void say() { System.out.println("我是动物,我不知道怎么叫、、、、、、、"); } } // 猫类 class Cat extends Animal{ public void say() { //猫类,发出喵喵叫 System.out.println("我是猫,喵............"); } } //狗类 class Dog extends Animal{ public void say() { //狗类,发出汪汪叫...... System.out.println("我是狗,汪汪.........."); } }
执行结果
我是动物,我不知道怎么叫、、、、、、、 我是猫,喵............ 我是狗,汪汪..........
我们注意到我们在定义的是Animal类型的对象,然而我们在new的时候却是分别使用了它的子类Cat类和Dog类,最后输出的结果也分别输出了各自new出来的对象的方法给出的结果。这说明JVM虚拟机会自动判断我们我们所定义的父类和子类之间的关系,当我们定义一个父类对象的时候,如果我们new的是子类,那么系统就会自动把子类的对象的引用赋值给左侧的父类对象,此时左侧父类对象的类型仍然是父类的类型,没有发生转变。我们来验证一下。如下代码所示
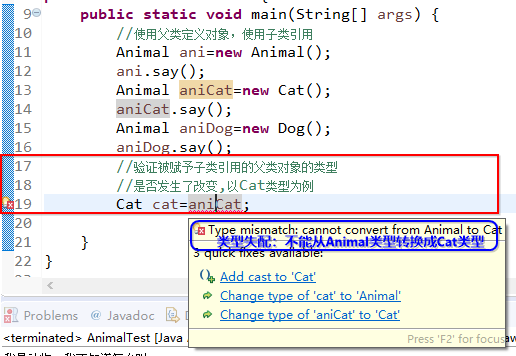
我们注意到,当我们试图把已经保存有Cat类型引用的变量aniCat的值赋值给新创建的Cat类型的变量cat时,编译器提示如图所示的错误,所以说虽然可以用父类保存子类的引用但系统没有对父类的类型进行转换,父类类型仍然是父类的类型。我们再用代码验证一下这段蓝紫色底纹的文字。
上方特性体现了继承在多态中的应用。
划重点还有我们必须遵守的一点,继承中多态的实现依赖于方法的覆盖【也称重写】。即如果我们的Animal类中没有say方法,而子类中有say方法,那么我们就不能用上述的方法去调用子类中的say方法。而如果我们子类中没有say方法而父类中有say方法,那么我们如果这样调用就直接调用父类中的say方法。
如图【子类没有say方法的调用结果】

如图【父类没有say方法的调用结果】

最后展示一个通过多态实现的小案例————狗吃骨头猫吃鱼,来体会一下多态。
要求:定义一个主人,当主人调用feed方法时如果传给的是狗和骨头就出狗爱吃骨头,如果传给的是猫和鱼,就输出猫爱吃鱼。
源码如下
/* * 作者:Alvin * 功能:实现主人喂食案例 * 时间:2019年2月28日16:16:15 * */ public class FeedPet { public static void main(String[] args) { // TODO Auto-generated method stub Master master=new Master(); master.feed(new Dog(), new Bone()); master.feed(new Cat(), new Fish()); } } //创建主人类 class Master{ public void feed(Animal animal,Food food) { animal.showInfo(); food.showInfo(); } } //创建食物类 class Food{ public void showInfo() { } } //创建鱼类 class Fish extends Food{ public void showInfo() { System.out.println("鱼"); } } //创建骨头类 class Bone extends Food{ public void showInfo() { System.out.println("骨头"); } } //创建动物类 class Animal{ public void showInfo(){ } } //创建狗类 class Dog extends Animal{ public void showInfo() { System.out.println("我是狗,我喜欢吃骨头"); } } //创建猫类 class Cat extends Animal{ public void showInfo() { System.out.println("我是猫,我喜欢吃鱼"); } }
输出结果
我是狗,我喜欢吃骨头 骨头 我是猫,我喜欢吃鱼 鱼
拓展:>>Java子类与父类之间的类型转换<<
1.向上转换
父类的引用变量指向子类变量时,子类对象向父类对象向上转换。从子类向父类的转换不需要什么限制,只需直接将子类实例赋值给父类变量即可,这也是Java中多态的实现机制。
2.向下转换
在父类变量调用子类特有的、不是从父类继承来的方法和变量时,需要父类变量向子类转换。
为什么要向下转换?
在继承关系中,有一些方法是不适合由父类定义并由子类继承并重写的,有些方法是子类特有的,不应该通过继承得到,且子类可能也会有自己特有的成员变量,那么在使用多态机制的时候,若我们要通过父类类型变量使用到这些子类特有的方法或属性的话,就需要将父类类型变量转换成对应的子类型变量。一个典型例子便是标准库中的数据类型包装类:Integer类,Double类,Long类等,它们都继承自Number类,且它们都有一个方法叫做compareTo用于比较两个同样的类型。然而这个方法是这些子类通过实现Comparable接口来实现的,在Number类中并没有该方法的实现,因此若要通过Number类型变量来使用compareTo方法,就要先将Number类转换成子类的对象。
注意
父类变量向子类转换必须通过显式强制类型转换,采取和向上转换相同的直接赋值方式是不行的;并且,当把一个父类型变量实例转换为子类型变量时,必须确保该父类变量是子类的一个实例,从继承链的角度来理解这些原因:子类一定是父类的一个实例,然而父类却不一定是子类的实例。在进行父类向子类的转换时,一个好的习惯是通过instanceof运算符来判断父类变量是否是该子类的一个实例,否则在运行时会抛出运行异常ClassCastException,表示类转换异常。
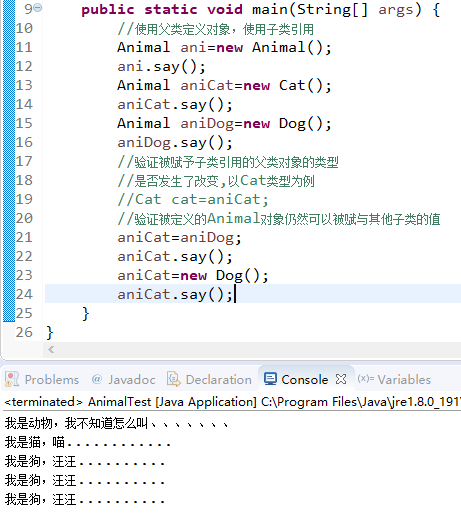
我们通过源码来只管感受一下,还是上面案例,我把main方法的内容修改一下
public static void main(String[] args) { //使用父类定义对象,使用子类引用 Animal ani=new Animal(); ani.say(); Animal aniCat=new Cat(); aniCat.say(); //下方的aniCat是在13行得来 //此时的aniCat父类对象是子类Cat的一个实例 //不可以转换 Cat cat=(Cat)aniCat; cat.say(); //下方的ani是在11行得到 //此时的ani父类对象不是子类Cat的一个实例 //不可以转换 Cat cat1=(Cat)ani; cat1.say(); }
执行结果如下
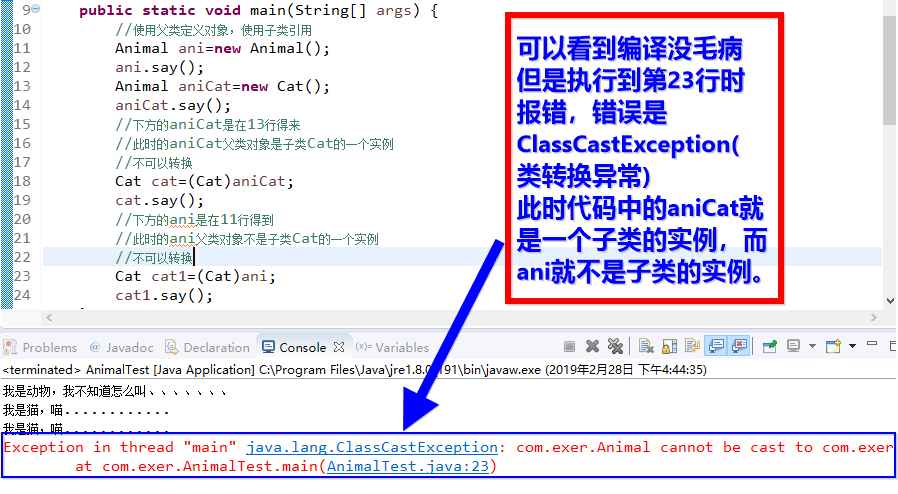
多态中可以实现向上的自动转换,但是在处理向下的转化中,可能会出现类型转换异常,所以在进行转换前建议通过instanceof运算符判断以下类型,继承中没有爷爷类一说,只有父类。
2、多态的抽象类实现
1、首先我们要解决的问题是什么是抽象类?
我们先看一个案例,在前面我们定义的Animal类中的say()方法实际上在子类中一直没有用到父类中的say()方法,子类所使用的say()方法都是经过自己重写的say方法。也就是说父类中的方法体完全没有必要写,当不同的子类去继承父类的时候,子类总是会重写该方法去实现自己所要达到的功能。
// 定义父类Animal class Animal { int age; String name; // 定义方法叫,因为是动物类,不同的动物会发出不同的叫声,所以此处的叫声输出我是动物,我不知道怎么叫 public void say() { System.out.println("我是动物,我不知道怎么叫、、、、、、、"); } }
上方所表达的就是父类方法在子类方法中实现的不确定性。那这么说的话我们如何更好地去书写代码呢?这就需要抽象方法来解决了。
首先看一下定义:被abstract(单词意思抽象)修饰的方法称为抽象方法,被abstract修饰的类称为抽象类。定义就这么简单,举个案例了解一下。就像刚才的Animal类中的say()方法我们就可以书写为
abstract public void say();
抽象类的编写举例如下
abstract public class Animal{ String name; abstract public void say(); }
2、关于抽象类和抽象方法的规则如下
1、抽象类不可以被实例化
2、抽象类仍然可以被继承
3、抽象类的子类必须实现抽象类中的所有抽象方法【就是把抽象类中的抽象方法给重写成完整的功能】
4、抽象类中可以没有抽象方法【也就是说抽象类中可以有其他完整的方法】
5、含有抽象方法的类一定要命名为抽象类
6、抽象方法一定不能在定义的时候在抽象类中实现,也不能写大括号【大括号被认为是函数主体的存在】
3、什么时候使用它?
前面我们已经讲了抽象类是用来解决父类方法在子类方法中实现的不确定性的,所以当我们父类中的一个方法在大部分子类中都会被重写的话就可以把该类声明为抽象类,类中的该方法声明为抽象方法,至于用不用在实际开发过程中很少用,但是公司面试问的挺多。
下面我们通过案例来理解一下抽闲类的多态实现【从原有案例修改得到源码】
/*
* 作者:Alvin
* 功能:抽象类的多态实现案例
* 时间:2019年2月28日18:02:42
* */
public class AnimalTest {
public static void main(String[] args) {
//此处如果直接定义抽象类对象并用Animal实例会报错
//Animal ani=new Animal();
//定义父类变量为子类的实例
Animal aniCat=new Cat();
aniCat.say();
//定义父类变量为子类的实例
Animal aniDog=new Dog();
aniDog.say();
}
}
// 定义抽象类Animal
abstract class Animal {
int age;
String name;
//因为该方法被所有子类
abstract public void say();
}
// 猫类
class Cat extends Animal{
//实现抽象类中的say方法
public void say() {
//猫类,发出喵喵叫
System.out.println("我是猫,喵............");
}
}
//狗类
class Dog extends Animal{
//实现抽象类中的say方法
public void say() {
//狗类,发出汪汪叫......
System.out.println("我是狗,汪汪..........");
}
}
执行结果
我是猫,喵............
我是狗,汪汪..........
3、多态的接口实现
以前只简单说了接口,那么什么是接口?
还是一样的举例,以USB为例,不同的厂商在生产USB插头的时候他们生产的USB插头的标准都是一样的,否则就不能插入适配,但是插入USB的设备实现是不一样的,有的是存储设备,有的是照相设备等,而接口只是提供了一个可以发生交换的通道。
程序中的接口也是这样,java中接口就是封装在一起的没有内容的方法,当某个类想用的时候在根据具体情况把它写出来实现。
实现接口的格式如下
class 类名 implements 接口名1,接口名2,....{ 方法; 变量; }
我们发现在关键字implements后面可以跟多个接口名,这说明一个类可以同时实现多个接口。
然后再看一下接口的定义格式
interface 接口名{ 方法名(); }
通过以上讲解我们可以这么类比
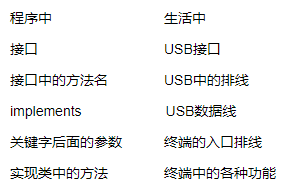
方法名对应排线是因为在接口中有好多方法,但是具体使用哪一个根据具体情况而定,而在USB的排线中会根据不同功能而是用不同的线进行传输。
可以这么说,接口时更加抽象的抽象类,因为抽象类中的方法可以有方法体,而接口中的每一个方法都不能被实现接口体现了高内聚低耦合的程序设计思想。
下面我们定义一个接口
interface Usb{
//定义一个变量
int a=1;
//声明两个方法 public void start(); public void stop(); }
上面我们就定义了一个Usb接口,并声明了两个方法,用来在USB启用和停止的时候被调用的方法。接下来我们接着来实现接口。我们定义一个相机类用来实现接口
//定义一个相机类 class Camera implements Usb{ //相继开始使用USB接口 public void start() { System.out.println("我是相机,开始工作了!"); } //相继停止使用USB接口 public void stop() { System.out.println("我是相机,停止工作了!"); } }
接着我们定义计算机类,用计算机去创建方法调用USB
//定义一个计算机类 class Computer{ //计算机的USB被唤醒加载 public void useUsb(Usb usb) { usb.start(); usb.stop(); } }
最后我们在测试类中定义计算机对象并把相机加载到USB接口上
public static void main(String[] args) { Computer computer=new Computer(); computer.useUsb(new Camera()); }
这样就完成了对USB接口的多态实现。执行结果如下
我是相机,开始工作了! 我是相机,停止工作了!
现在我们再添加一个设备,U盘,然后再传给计算机的USB接口,代码如下
//定义一个U盘类 class uDisk implements Usb{ //U盘开始使用USB接口 public void start() { System.out.println("我是U盘,开始工作了!"); } //U盘相继停止使用USB接口 public void stop() { System.out.println("我是U盘,停止工作了!"); } }
测试类中的main方法添加
Computer computer=new Computer(); computer.useUsb(new Camera()); computer.useUsb(new uDisk());
执行结果
我是相机,开始工作了! 我是相机,停止工作了! 我是U盘,开始工作了! 我是U盘,停止工作了!
接口使用时的注意事项【规则】
1、接口不能被实例化
接口不能被实例化是因为接口一般作为方法的集合体,没有方法体。
2、接口中的所有方法必须满足以下要求
接口中的方法要么为抽象方法[public abstract] void method();在接口中,public abstract可以省略。要么为默认方法 public default void method(){};再或者为静态方法public static void method(){};
3、一个类可以实现多个接口
一个类可以实现多个接口并且实现所有接口的所有抽象方法。当遇到实现的多个接口的抽象方法重名问题那么只需要重写一个抽象方法就可以,但是如果出现两个接口的默认方法重名,那么必须在实现类重写一个被重名的方法。Java允许单继承多实现,当一个类出现接口中的默认方法和父类中的正常方法完全一致时,由于父类的优先级比接口高,所以只会调用父类中的方法,接口中的默认方法会被覆盖。
4、接口中可以有变量,但是变量不能用private和protected修饰
关于这一点还要声明
a.接口中的变量本质上就是static的,不管你加不加static修饰,该变量只能用public,static或者final进行修饰
b.在java开发中,我们经常把经常用的变量,定义在接口中,作为全局变量进行使用,interface的所有成员变量都被声明为最终静态的,也就是常量。修改是可以通过继承的方式重写的
访问形式:接口名.变量名
5、一个接口不能继承其他的类,但是可以继承自其他的接口
实现接口 与 继承类 对比
java的继承是单继承,也就是一个类最多只能继承一个父类,这种单继承机制保证了类的纯洁性,但不可否认对子类的扩展有一定影响,所以我们认为:(1)实现接口可以看做是对继承的一种补充。还有一点,继承是层级式的,不太灵活。就像我么的家谱,如果在任何一个类中它的方法属性发生更改,那么该类所有的子类都会发生改变,在某些情况下这种结果可能是灾难性的。
而接口就没有那么麻烦,加入一个接口发生改变为了避免该接口造成的影响可以采取在实现该接口的类上移除发生改变的接口就行。
所以有(2)实现接口可以在不打破继承关系的情况下实现功能的扩展。我们在通过接口实现多态时是通过使用接口类型的变量作为传递的媒介,使凡是继承了该接口的类都能够通过该接口类型的变量访问到实现类中的方法,其本质也是通过方法的重写来实现的。
对多态理解的在深入
继承是多态得以实现的基础,从字面上理解,多态就是一种类型的多种状态,将一个方法调用同这个方法的主体联系起来【即将这个类实例和这个实例的方法联系起来】。这种联系的调用分为前期绑定和后期绑定两种情况。
①、前期绑定
前期绑定是在程序运行之前进行的绑定,由编译器和链接程序进行实现,又叫做静态绑定。比如static方法和final方法,注意这里也包括private方法,因为他们是隐式final的。
②、后期绑定
在运行时根据对象的类型进行绑定。由方法调用机制进行实现,因此又叫动态绑定和运行时绑定。除了前期绑定只外所有的方法都属于后期绑定。
多态就是在后期绑定这种机制上实现的。多态给我们带来的好处是消除了类之间的耦合关系,使程序更容易拓展,是编写更加灵活。
接口的最后总结:
1、接口不能被实例化
2、接口中的所有方法不能够有方法体,花括号也不能出现{}
3、一个类可以实现多个接口
4、接口中的方法可以有参数列表和返回类型,但不能有任何方法体
4、接口中可以有变量,但是变量不能用private和protected修饰
关于这一点还要声明
a.接口中的变量本质上就是static的,不管你加不加static修饰,该变量只能用public,static或者final进行修饰,即接口中的方法可以被声明为 public 或不声明,但结果都会按照 public 类型处理,接口中可以包含字段,但是会被隐式的声明为 static 和 final,也就是说接口中的字段只是被存储在该接口的静态存储区域内,而不属于该接口
b.在java开发中,我们经常把经常用的变量,定义在接口中,作为全局变量进行使用
访问形式:接口名.变量名
5、一个接口不能继承其他的类,但是可以继承自其他的接口,即扩展一个接口来生成新的接口应使用关键字 extends ,实现一个接口使用 implements
6、多态调用方法时的特点:多态继承关系中,编译阶段验证父类方法,运行阶段运行子类,所以多态只能调用字子父类中共有的方法——即实现基于重写。
所以说多态实现的前提是重写!!!!
到现在为止我们对类的认识才更加完善
第八讲 final修饰符
一、final概念
final中文意思:最后的,最终的
final可以修饰变量或者方法
在某些情况下,程序员可能有以下需求:
①当不希望父类的某些方法被子类覆盖时可以用final关键字修饰【区别于private,private修饰的不能被继承,而final的可以被继承但是不能被重写】
②当不希望类的某个变量的值被修改,可以用final修该,可以用final修饰【区别于static,static修饰的变量是可以被该类所有的实例共享的,可以访问和修改,而final修饰的量是被所有实例允许访问但是不允许修改】
③、当不希望类被继承时可以在类的修饰符中添加final进行修饰
final就是为了满足以上三个要求的。
对第一条举例
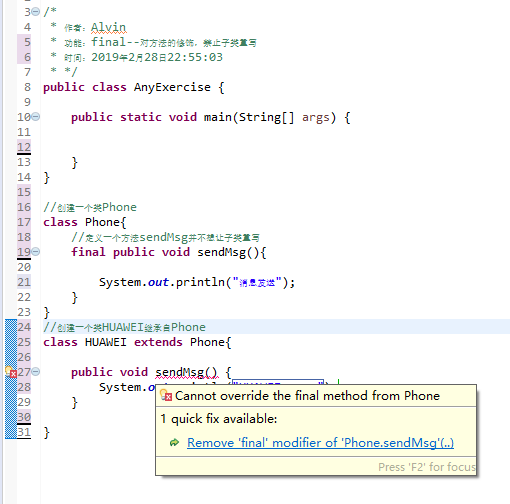
从上图可以看到,爱27行的错误提示显示不能重写从Phone继承的final方法
再如第二条
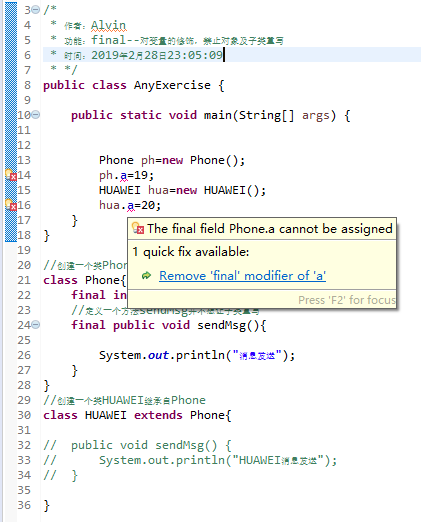
在第14和16行提示了相同错误
还有第三条
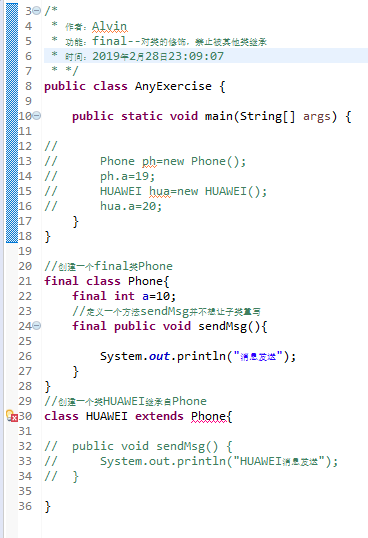
在第30行对试图继承Phone类的HUAWEI类报错。
二、final的注意事项
①、final修饰的变量又叫常量,一般用 xx_xx_xx来命名
②、final修饰的变量在定义时必须赋值,否则以后就不能赋值了
三、final什么时候用
①、因为安全考虑,某个类的方法不允许被修改
②、一个类不允许被继承
③、某些变量值是固定不变的,如π=3.1415926
FBI WARNING
至此,Java的面向对象编程的基本知识已经结束。
第九讲 数组
一、一维数组
一、简单类型的数组
1、案例————求学生年龄的平均数
当我们去求n个学生的平均年龄时,因为每个学生的年龄都是整数,所以可以让这n个学生站成一排,因为我们统计的是学生的年龄平均数,所以和学生的其他特征无关,于是我们对所有学生的年龄起名为年龄,从第一个学生开始我们依次给他们起名为年龄1、年龄2、年龄3....年龄n记录,然后在把年龄值依次相加最后除以上面的处理思想就类似于java中使用数组进行解决。那么什么是数组?数组是可以存放相同数据类型的数据结构。我们注意到前面我们需要统计的都是年龄值,这些年龄值就是我们需要存储的元素。由于不同的人有不同的年龄值所以有不同的名称,但是他们都是年龄,所以通过总称“年龄”来代表他们所有人的年龄,通过“年龄+序号”来表示第几个学生的年龄。在数组中也是用这种方法区分总体和个体的。
2、数组的定义格式
数组的定义格式如下
数据类型 数组名[]=new 数据类型[数组长度];
或
数据类型[] 数组名=new 数据类型[数组长度];
或
数据类型[] 数组名;
数组名=new 数据类型[数组长度];
或
数据类型[] 数组名={元素1,元素2,元素3,元素......};此种定义方法用于数组元素在程序编写的时候可以已知的赋值。
如我们要统计90个学生的平均年龄【年龄是整数】就需要下方这样定义
int age=new int[90];
上方的int就是“数据类型”,age就是“数组名”,90就是“数组长度”。
3、数组中元素的访问
我们通过上方定义了一个长度为90的数组,那么数组中的元素是如何访问呢?java规定,数组中元素的访问遵守下方的格式。
数组名[下标];
这里的下标不同于我们生活中的从1开始,这里的下标是从0开始的到数组长度减1结束。比如我们要取出第5个人的年龄只需要通过age[4]就可以取到。那么为什么数组的下标要从零开始呢?【以下纯属个人理解】系统把数组是分配在一段连续的内存中的。它的结构可以用下面的图片简单示意一下
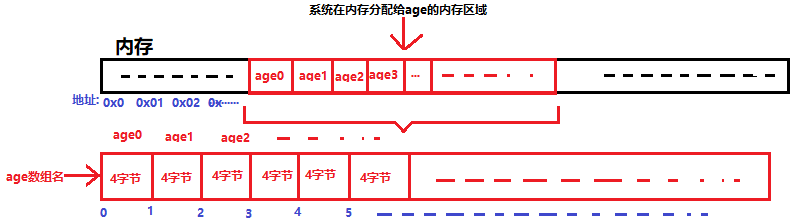
我们知道我们人是在地球上的,我们在地球上都有一个唯一的家庭地址,相同的事实是我们运行的程序数据都存储在内存中,并且这些数据也有地址,我们家庭的地址使用文字进行描述,而内存中的数据地址通过十六进制的数字依次从内存的一端从小到大向后排列,所以当我们像内存中申请一个90个长度的int型变量时系统就会在内存中划出这样一片连续的区域并把开头的那个元素的地址返回给数组名。由于我们的数据都是有大小的,所以在每个元素之间都会有该类型大小的空间供存放数据。当我们在使用数组的某个元素的时候我们不可能通过地址进行访问,所以通过数组名加下标的形式进行访问,而下标就是地址的另一种呈现形式,它表示从第一个元素头部开始你访问的数据向后移动多少个该数组类型所占空间大小。如当我们访问第一个人的年龄时因为age指向的就是第一个人的年龄头部,所以向后偏移的量【即偏移量(offset)】为0,所以使用age[0]访问到了第一个人的年龄数据。
补充:在数组中最常用的一属性是.length属性,可以获取数组的长度
如前面我们定义的一个长度为90的数组,我们可以通过数组名.length获得该数组的长度。操作如下
int arrayLength=age.length;
通过上述语句就把age数组的长度得到并赋值给一个新变量arrayLength进行保存。
4、使用数组时的注意事项。
①、数组是定长的。所谓定长就是数组一旦定义长度就不可以改变,如我们上面声明了一个长度为90的数组,当我们想在该数组中添加元素时是不被允许的。数组大小不能从控制台输入。
②、数组是用来保存同一种类型的元素的。在上方定义的数组类型是int型,从图中我们看到,在每个空缺的空间大小都是int个字节,此时如果我们把一个long类型的数字存进去是不可能的。因为long类型是8个字节。
③、数组的访问不可以超过数组的长度,否则会报错。就像我们刚才声明的一个长度为90的数组,如果我们在访问的时候使用age[90]就会报空指针异常,因为数组的下标是按照偏移量来的,如果使用age[90]那么就是在访问第91个元素,但是该元素不存在,所以会报错。
④、数组在定义的时候必须指定长度。因为数组是定长的,所以定义的时候必须提供长度。
⑤、数组名是指向首个元素的首地址【头部】
5、数组的遍历
数组的访问是通过角标进行的访问,对数组的遍历就可以通过吧角标换成变量然后在循环中进行
代码如下
二、对象数组
前面以int类型代表基本数据类型介绍了数组,那么可不可以有对象数组呢?
1、案例
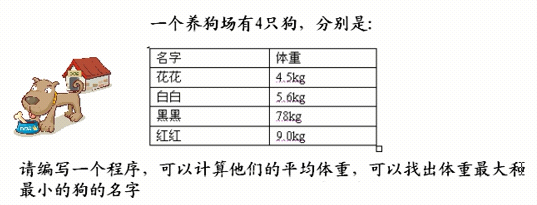
编写一个程序,要求求出平均体重,并找出体重最大的和最小的输出他们的名字。
很显然,如果使用原来的数组无法保存上面的所有信息。这个时候我们就需要定义引用类型来解决。
源码如下
通过以上方法我们解决了以上问题。上面解决问题的方式就是使用对象数组。
2、对象数组的定义格式
对象数组的定义格式和基本数据类型的一样。
3、对象数组的元素访问
对象数组的元素访问和基本数据类型的元素访问也一样,只不过基本数据类型的数组访问到的是存储在内存中的数据,而对象数组访问到的是数组中的对象,如果想访问到该对象的属性还需要通过成员运算符“.”进行访问。
4、使用对象数组时的注意事项
1、所有基本数据类型的要求
2、在定义对象数组时必须为数组中的每个对象进行new操作否则内存中没有为该对象分配空间,数组中的对象无法使用,如果编译会报空指针异常。
5、对象数组的遍历
对象数组的遍历和基本类型数组的遍历一样。
第十讲 排序
所谓排序就是将一群数据,依指定的顺序进行排列的过程。 也是程序员的基本功。
排序的分类,从大的方面有
①、内部排序
指将需要处理的所有数据加载到内存存储器中进行排序。包括(交换式排序、选择是排序、插入式排序)
②、外部排序
当数据量巨大的时候无法全部加载到内存中,需要借助外部存储进行排序,包括(合并排序,和直接合并排序)
排序(Sorting)是一种数据处理中很重要的运算,同时也是很常用的运算,一般数据处理工作的25%得时间都在进行排序。
所谓排序就是将一组记录按照某个域的值进行按照要求进行序列化(如从大到小或者从小到大)操作。
此处讲解传参和传指的区别。
一、内部排序
1、交换式排序法
交换式排序法属于内部排序法,是运用数据值比较后依照判断规则对数据进行位置交换,以达到排序的目的。
交换式排序法分为两种(假设排序要求是将整数数字从小到大排列):
①、冒泡排序法(Bubble Sort)
冒泡排序的思想
从第一个元素开始,依次将相邻的两个元素进行比较,如果满足前一个数大于后一个数的条件则将这两个数交换位置。交换后继续进行比较循环进行。由于每次排序都会把最大的那个数通过比较移到最后端,所以每完成一次从头到尾的比较就将比较的范围缩减1.

源码如下
class BubbleSort{ public static void main(String[] args) { // TODO Auto-generated method stub int arr[]= {1,6,0,-1,9,-10,9,-90,39,20,95,48,39,-39,30}; int temp=0; //排序,最终按照从小到大的顺序进行排序 //外层循环,他决定走几趟 //经过以上几个变量的比较,每一轮排序都会把本轮的最大值给排列到最后。多以在内部遍历的时候遍历的长度为arr.length-1-i; for(int i=0;i<arr.length;i++) { for(int j=0;j<arr.length-1-i;j++) { if(arr[j]>arr[j+1]) { //不增加变量的情况下交换两个变量的值。 // arr[j]+=arr[j+1]; // arr[j+1]=arr[j]-arr[j+1]; // arr[j]=arr[j]-arr[j+1]; // 添加一个temp变量交换两个变量的值。 temp=arr[j]; arr[j]=arr[j+1]; arr[j+1]=temp; } } } for(int j=0;j<arr.length;j++) { System.out.println(arr[j]); } } }
②、快速排序法(Quick sort)
该方法是对冒泡排序的一种改进。
思路:通过一趟将要排序的数据分割成两部分,其中一部分的所有数据比另一部分的所有数据都要小,然后将产生的两部分在各自分成上面要求的形式,以此类推,最后得到的数据就是排序完成的数据。
快速排序思想:快速排序使用的是分治思想。
特点:采用分治思想,对数据进行划分同时进行排序。
快速排序的优缺点:
优点:效率最高时间最快。
缺点:由于采用的递归思想,所以需要等最后一个数出栈其他的数才能够接着出栈,故十份消耗内存
源码如下
class QuickSort{ public void sort(int left,int right,int[] array) { int l=left; int r=right; int pivot = array[(left+right)/2]; int temp=0; while(l<r) { while(array[l]<pivot) l++; while(array[r]>pivot) r--; if(l>=r) break; temp=array[l]; array[l]=array[r]; array[r]=temp; if(array[l]==pivot) --r; if(array[r]==pivot) ++l; } if(l==r) { l++; r--; } if(left<r) sort(left,r,array); if(right>l) sort(l,right,array); } }
2、选择式排序法
选择式排序也属于内部排序法,是从欲排序的数据中按指定的规则选出某一元素,经过和其他元素重整,再依要求交换位置后达到排序目的。
选择式排序又可分为两种
①、选择排序法(Selection Sort)【比冒泡排序法快一点】
选择排序的思想是从每趟中选出一个较小值,然后记住这个最小值的下标,本趟完成所有对比后会选择出本次选出的最小值,然后跟每趟开头的那个元素交换位置。最开始的时候将第一个元素开成最小的元素。
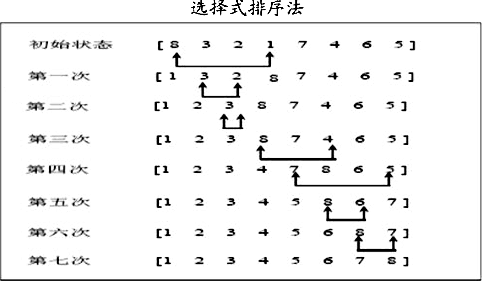
源码如下
class SelectSort { public static void main(String[] args) {// 要求将给定的数序列按照从小到大的顺序进行排列 // TODO Auto-generated method stub int arr[] = { 1, 6, 0, -1, 9, -10, 9, -90, 39, 20, 95, 48, 39, -39, 30 }; int temp;// 定义临时变量用于当条件满足时用于交换数据 int minIndex;// 用于记录本趟中的最小数值的下标 for (int i = 0; i < arr.length - 1; i++) {// 排序时决定走几趟 minIndex = i; for (int j = i + 1; j < arr.length; j++)// 在该趟中选择出最小的数值给该趟中的第一个交换位置。 { if (arr[minIndex] > arr[j]) { minIndex = j; } } temp = arr[i]; arr[i] = arr[minIndex]; arr[minIndex] = temp; } // 输出排序后的数组信息。 for (int k = 0; k < arr.length; k++) { System.out.println(arr[k]); } } }
②、堆排序法(Heap Sort)
将排序码k1,k2,k3.......kn表示成一棵完全二叉树,然后从第n/2个排序码开始筛选,使由该结点作为根结点组成的子二叉树符合堆的定义,然后从第n/2-1个排序码重复刚才操作,直到第一个排序码停止。这时候该二叉树符合堆的定义,初始堆已经建立。
接着,可以按照如下方法进行堆排序:将堆中的第一个结点(二叉树根结点)和最后一个结点的数据进行交换(k1与kn),再将k1-kn-1重新建堆,然后k1和kn-1交换,再将k1-kn-2重新建堆,然后k1和kn-2交换,如此重复下去,每次重新建堆的元素个数不断减1,直到重新建堆的元素个数仅剩一个为止。这时堆排序已经完成,则排序码k1,k2,k3,k.....kn已排成一个有序序列。
若排序是从小到大排序,则可以建立大根堆实现堆排序,若排序是从大到小,则可以用小根堆实现排序。
堆排序图示
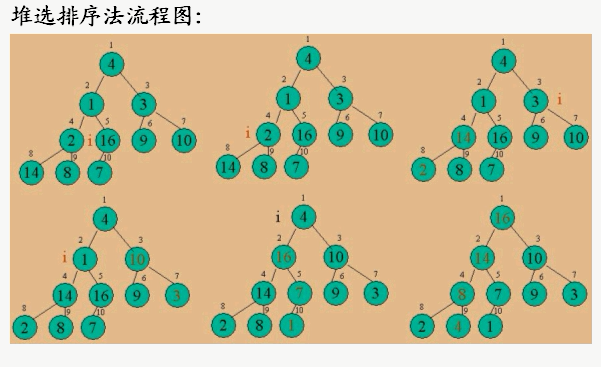
3、插入式排序法
插入式排序发也属于内部排序法,是对于欲排序的元素以插入的方式找寻该元素的适当位置,来达到所给元素的序列化。
插入排序法又可分为三种
①、插入排序法(Insertion sort)【优于选择排序法】
思想;首选把欲排序的数据分成有序集和无序集,然后每次从无序集中取出一个元素和有序集中的元素依次比价,如果在有序集中从某个位置开始的值比待插入值小,有序集的后一个元素比待插入值大,则把该元素插入到有序集的这两个值之间的位置。
代码如下:
class InsertSort{ public static void main(String[] args) { // TODO Auto-generated method stub //插入排序,本例题要求把所有的数据按照从小到大进行排列 int arr[]= {1,6,0,-1,9,-10,9,-90,39,20,95,48,39,-39,30}; for(int i=0;i<arr.length-1;i++) { //把将要参与比较的数备份下来。因为后面需要移位 int insertValue=arr[i]; //insertVal准备和前一个数比较 int index=i-1; while(index>-1 && insertValue<arr[index] ) { //将把arr[index]向后移动 arr[index+1]=arr[index]; index--; } //把数插入到指定位置。 arr[index+1]=insertValue; } for(int k=0;k<arr.length;k++) { System.out.println(arr[k]); } } }
②、谢尔排序(shell sort)
谢尔排序(又称希尔排序shell sort)又称为“最小增量排序”。该方法的基本思想是:先将整个待排元素序列分割成若干个子序列(由相隔某个“增量”的元素组成的)分别进行直接插入排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序。
因为直接插入排序在元素基本有序的情况下(接近最好情况),效率很高,因此希尔排序在时间效率上比前两种方法有较大提高。速度上快速排序是最快的。
③、二叉树排序法(Binary-tree Sort)
二分插入(Binary Insert Sort)的基本思想是:在有序表中采用二分查找的方法查找待排元素的插入位置。
其处理过程:先将第一个元素作为有序序列,进行n-1次插入,用二分查找的方法查找待排元素的插入位置,将待排元素插入。
二、外部排序
合并排序
合并排序是外部排序最常用的排序方法。若数据量太大无法一次完成加载内存,可使用外部辅助内存来处理排序数据,主要应用在文件排序。
排序方法:
将欲排序的数据分别存在数个文件大小可加载内存的文件中,再针对各个文件分别使用“内部排序法”将文件中的数据排序号写回文件。再对所有已排序好的文件两两合并,直到所有文件合并成一个文件后则数据排序完成。
假设有四个文件A、B、C、D,其内部数据均已排序完成,则文件合并排序方式如下。
(1)将已排序好的A、B合并成E,C、D合并成F,E、F的内部数据分别均已排好序。
(2)将已排好的E、F合并成G,G的内部数据已排好序
(3)四个文件A、B、C、D数据排序完成
第十一讲 查询、多维数组
一、查询
在java中,我们常用的查找有两种
①顺序查找
速度最慢的一种查找,效率也低。【举例实现】
②二分查找
只适应于有序数列。要求是先排序再查找,即使执行两个操作,在大的数据中执行查找操作,二分查找也要比顺序查找快。【举例实现】
二、多维数组
多维数组中最重要的是二维数组,其他的维度的数组基本上用不到,三维数组在3DmMarks中可以用到。
①、二维数组的定义
语法:类型 数组名[][] = new 类型[大小][大小];
比如:int a[][]=new int[2][3]
②、分析
二维数组在内存中的存在形式。二维数组在内存中仍然是以一维数组的形式存在的。如上面定义的数组的存储顺序是
a[0][0]a[0][1]a[0][2]a[1][0]a[1][1]a[1][2].....
③、案例,请用二维数组输出如下图形
0 0 0 0 0 0
0 0 1 0 0 0
0 2 0 3 0 0
0 0 0 0 0 0
④、案例,要求对
0 0 0 0 0 0
0 0 1 0 0 0
0 2 0 3 0 0
0 0 0 0 0 0
进行转置。
第十二讲 二进制、位运算、移位运算符
一、二进制
1、掌握计算机二进制(源码、反码和补码)
2、充分理解java为运算和移位运算符
1、基本概念
①、什么是二进制?
二进制是缝2进位的进位制,0,1是基本算符。
计算机为什么采用二进制?因为在计算机中只有通过高低电平两个电位计算机在信号表示上才最稳定。也就是说在计算机中的电位要么是高电位要么是低电位,而高电位计作1,低电位计作0.
现代的电子计算机技术全部采用的是二进制,因为它只使用0、1两个数字符号,非常方便,易于用电子方式实现。计算机内部处理的信息,都是采用二进制数来表示的。二进制数用0,1两个数字及其组合来表示任何数。进位规则是逢2进1,数字1在不同的位上代表不同的值,按从右至左的次序,这个值以二倍递增。
②、什么是原码、反码、补码?
这三个概念是对有符号【就是有可以表示正数也可以表示负数】的数字而言的。
二进制的最高位是符号位,0表示正数,1表示负数。
③、原码、反码、补码的转换规则
①、正数的原码、反码、补码都一样,是该正数直接转换成二进制。
②、负数的反码=它的原码符号位不变,其他位取反
③、负数的补码=负数的反码+1
④、0的反码,补码都是0
⑤、java没有无符号数,换言之,java中的数都是有符号的
⑥、在计算机运算的时候,都是以补码的方式来运算的
⑦、整数类型的存储范围计算公式
小技巧:对一个数两次求补码得到的结果仍然是这个数本身。
二、位运算符和移位运算符
1、位运算符基本知识
java中有4个位运算符,分别是“按位与&、按位或|、按位异或^,按位取反~”,它们的运算符规则是:
按位与&:两位全为1,结果为1
按位或|: 两位一个为1结果为1
按位异或^:两位不同为1相同为0
按位取反~:0->1,1->0
案例介绍
比如:~2=-3 2&3=2 2|3=3 2^3=1
小技巧:(A^B)^A=B
2、移位运算符基本知识
java中有四个位移运算符:
>>、<<算术右移和算术左移,
运算规则:
算术右移:低位溢出,符号位不变,并用符号位补溢出的高位
算术左移:符号位不变,低位补0
>>>逻辑右移,运算规则是:低位溢出。高位补0
小技巧:当正数和负数进行算术左移n位的时候相当于在原来的数值乘以2的n次方,当正数进行算术右移的时候,每移一位相当于除以一次2
第十三讲 集合框架
集合框架
目标:掌握常用的集合类
什么是集合类?【个人理解:集合类就相当于一个容器,我们创建了一个集合对象后就相当于创建了一个容器实例,然后我们把要处理的实例当成一个处理单元装入集合类,通过集合类进行管理,然后我们通过操作集合类的实例中的方法对我们的数据进行操作。总的来说,集合类是将多个元素组成一个单元的对象。集合类的作用是用于储存、检索和操纵数据,以及将数据从一个方法传输至另一个方法。集合操作的目标是对象。集合类的使用都大同小异。】
一、案例
请做一个公司职员薪水管理系统,要求完成如下功能
1、当有新员工时,将该员工加入到管理系统
2、可以根据员工工号,显示该员工的信息
3、可以显示所有员工信息
4、可以修改员工的薪水
5、当员工离职时,将该员工从系统管理中删除
6、可以按照薪水从低到高顺序排序【思考题】
7、可以统计员工的平均工资和最低、最高工资
根据以上的要求,很显然不能通过定义数组的方式进行解决,因为数组不能完成上面的增加和删除员工。
以我们以前的知识,第一个能想到的解决的问题就是定义链表进行解决。因为链表可以动态的改变由链表构成的数组的长度。但是链表的实现过程过于繁琐,为了解决此类方法,java的设计者们为我们提供了一系列的集合类。但是当我们遇到某些非常奇怪的问题的时候就需要自己手写链表进行解决,一般情况下采用链表进行解决就可以了。
二、使用
我们先来看一下集合框架图
图一
图例介绍:上述类图中,实线边框的是实现类,比如ArrayList,LinkedList,HashMap等,折线边框的是抽象类,比如AbstractCollection,AbstractList,AbstractMap等,而点线边框的是接口,比如Collection,Iterator,List等。
图二
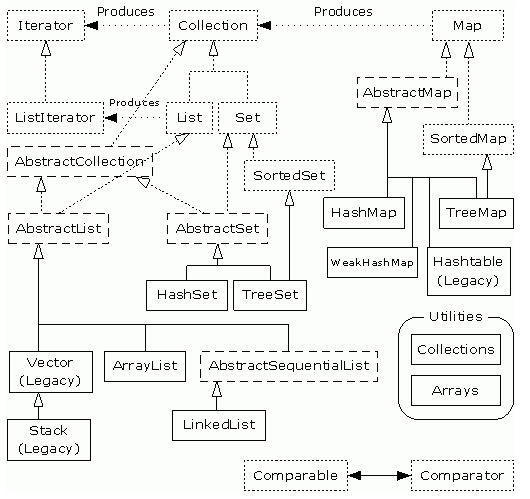
图二是图一的简化图,从图中可以看出上述所有的集合类,都实现了Iterator(迭代器)接口,这是一个用于遍历集合中元素的接口,主要包含hashNext(),next(),remove()三种方法。它的一个子接口LinkedIterator在它的基础上又添加了三种方法,分别是add(),previous(),hasPrevious()。也就是说如果是先Iterator接口,那么在遍历集合中元素的时候,只能往后遍历,被遍历后的元素不会在遍历到,通常无序集合实现的都是这个接口,比如HashSet,HashMap;而那些元素有序的集合,实现的一般都是LinkedIterator接口,实现这个接口的集合可以双向遍历,既可以通过next()访问下一个元素,又可以通过previous()访问前一个元素,比如ArrayList。
拓展:迭代器(Iterator)
迭代器是一种设计模式,它是一个对象,它可以遍历并选择序列中的对象,而开发人员不需要了解该序列的底层结构。迭代器通常被称为“轻量级”对象,因为创建它的代价小。
Java中的Iterator功能比较简单,并且只能单向移动:
(1) 使用方法iterator()要求容器返回一个Iterator。第一次调用Iterator的next()方法时,它返回序列的第一个元素。注意:iterator()方法是java.lang.Iterable接口,被Collection继承。
(2) 使用next()获得序列中的下一个元素。
(3) 使用hasNext()检查序列中是否还有元素。
(4) 使用remove()将迭代器新返回的元素删除。
Iterator是Java迭代器最简单的实现,为List设计的ListIterator具有更多的功能,它可以从两个方向遍历List,也可以从List中插入和删除元素。
还有一个特点就是抽象类的使用。如果要自己实现一个集合类,去实现那些抽象的接口会非常麻烦,工作量很大。这个时候就可以使用抽象类,这些抽象类中给我们提供了许多现成的实现,我们只需要根据自己的需求重写一些方法或者添加一些方法就可以实现自己需要的集合类,工作流昂大大降低。
从上面的图一可以看出java集合类主要有以下几种
1、List结构的集合类
ArrayList类,LinkedList类,Vector类,Stack类
2、Map结构的集合类
HashMap类,Hashtable类
3、Set结构的集合类
HashSet类、TreeSet类
4、Queue结构的集合
Queue接口
集合类的功能是能实现动态的增删改查。是java设计者给我们提供的便利。下面介绍常用集合类及其常用方法。
在我们调用集合类之前首先要引入一个包,java.util.*;因为我们所有的集合类基本上都在这个包下。
1、List结构的集合类
i. ArrayList集合类【以下方法通过ArrayList实例进行调用】
ArrayList的使用案例如下
Clerk类-》属性name、age、salary
实现增删改查长度操作
ii. LinkedList集合类【以下方法需通过LinkedList实例进行调用】
方法1、addFirst(Object object);后加的对象在前面
方法2、addLast(Object object);后加的在后面
方法3、removeFirst();删除第一个
方法4、removeLast();删除最后一个
iii. Vector集合类
iv. Stack集合类
Stack集合类的add()方法是往前面加的。和ArrayList不同
案例:现在我们可以通过以上集合实现员工管理系统。
将集合就离不开>>范型<<
记住集合使用泛型与不使用泛型有区别,如果在容器后面不注明尖括号<>,即不适用的范型的话创建的实例是object类型的,需要强制类型转换,而修饰后返回的就是我们需要的类型。
拓展:对比——ArrayList和Vector的区别
ArrayList和Vector的区别
ArrayList与Vector都是Java的集合类,都可以用来存放Java对象,这是他们的相同点,但是他们也有区别。
一、同步性
Vector是同步的。这个类中的一些方法保证了Vector中的对象是线程安全的。而ArrayList则是异步的,因此ArrayList中的对象并不是线程安全的。因此同步的要求会影响执行的效率,多以如果你不需要线程安全的集合那么使用ArrayList是一种很好的选择,这样可以避免由于同步带来的不必要的性能开销。
二、数据增长
从内部实现机制来讲ArrayList和Vector都是使用数组(Array)来控制集合中的对象。当你向这两种类型中增加元素的时候,如果元素的数目超出了内部数组目前的长度,他们都需要拓展内部数组的长度,Vector缺省情况下自动增长原来的一倍的数组长度,ArrayList是原来的50%,所以最后你获得的这个集合所占的空间总是比你需要的要大。所以如果你要在集合中保存大量的数据那么使用Vector有一些优势,因为你可以通过设置集合的初始化大小来避免不必要的资源开销。
2、Map结构的集合类
Map结构的集合类与上面的List结构的集合类不一样,因为Map中存储的是键值对。
i. HashMap集合类
增加方法:put(key,Object value);
是否包含某键值:containsKey(key);
查找HashMap中的对象:getObject(key);
注意,Map集合中不允许有相同的两个键存储在该集合中。如果后来再加入相同的键加入集合,后者的值会覆盖前者的值。
HashMap的遍历:Iterator 迭代器,因为HashMap它存放了多少它自己是不知道的,而Iterator迭代器可以探测。遍历方式如下
//这一步将hm中的键全部返回 Iterator it=hm.keySet().iterator(); //hashNext返回一个boolean,用于判断还有没有下一个 while(it.hasNext()){ //取出key String key=it.next().toString(); //通过key取出value ***=hm.get(key); }
ii.Hashtable集合类
基本上可以这么理解,Hashtable和HashMap的用法基本上都一样。
拓展:HashMap和Hashtable的区别。
HashMap与Hashtable都是java的集合类,都可以用来存放java对象,这是他们的相同点,但是他们也有区别:
一、历史原因:
Hashtable是基于陈旧的Dictionary类的,HashMap是Java 1.2引进的Map接口的一个实现。
二、同步性
Hashtable时同步的。这个类中的一些方法保证了Hashtable中的对象是线程安全的。而HashMap则是异步的,因此HashMap中的对象并不是线程安全的。因为同步的要求会影响执行的效率,所以如果不需要线程安全的集合,那么使用HashMap是一个很好的选择,这样可以避免由于同步带来的不必要的性能开销,从而提高效率。
三、值
HashMap可以让你将空值作为一个表的条目的key或value,但是Hashtable是不能放入空值的(null)
------------------------------------------------
集合框架--总结
Java的设计者们给我们提供了这些集合类,在后面编程中是相当有用的,具体什么时候用什么集合,要根据我们刚才分析的集合异同来选取。
总结为以下几点
①、如果要求线程安全使用Vector、Hashtable
②、如果不要求线程安全使用ArrayList、HashMap、LinkedList
③、如果要求键值对,则使用HashMap,Hashtable
④、如果数据量很大,使用Vector
要求:用合适的集合完成上方的薪资管理系统。
练习题:目的联系对List、Map、Set的不同
练习一、大圣准备带着小猴去操练,但是队伍实在太不成队伍,非常散漫,唐僧建议用Java里面的容器和和接口去装小猴,重新组织队伍。
第一关、设计程序使用List接口来容纳10只小猴
第二关、用Set来装在10只猴,对他们可执行查找和替换功能
第三关、用Map接口来装载10只小猴,对他们执行最快的查找和替换功能
练习二、如果做一个词典(英汉),如果不使用数据库,你会怎样实现。
第十四讲 范型
目标:充分理解什么是泛型
1. 概述
泛型在java中有很重要的地位,在面向对象编程及各种设计模式中有非常广泛的应用。
什么是泛型?为什么要使用泛型?
泛型,即“参数化类型”。一提到参数,最熟悉的就是定义方法时有形参,然后调用此方法时传递实参。那么参数化类型怎么理解呢?
顾名思义,就是将类型由原来的具体的类型参数化,类似于方法中的变量参数,此时类型也定义成参数形式(可以称之为类型形参),
然后在使用/调用时传入具体的类型(类型实参)。
泛型的本质是为了参数化类型(在不创建新的类型的情况下,通过泛型指定的不同类型来控制形参具体限制的类型)。也就是说在泛型使用过程中,
操作的数据类型被指定为一个参数,这种参数类型可以用在类、接口和方法中,分别被称为泛型类、泛型接口、泛型方法。
2. 案例引入
List arrayList = new ArrayList();
arrayList.add("aaaa");
arrayList.add(100);
for(int i = 0; i< arrayList.size();i++){
String item = (String)arrayList.get(i);
Log.d("泛型测试","item = " + item);
}
毫无疑问,程序的运行结果会以崩溃结束: java.lang.ClassCastException: java.lang.Integer cannot be cast to java.lang.String ArrayList可以存放任意类型,例子中添加了一个String类型,添加了一个Integer类型,再使用时都以String的方式使用,因此程序崩溃了。为了解决类似这样的问题(在编译阶段就可以解决),泛型应运而生。
我们将第一行声明初始化list的代码更改一下,编译器会在编译阶段就能够帮我们发现类似这样的问题。
List<String> arrayList = new ArrayList<String>();
...
//arrayList.add(100); 在编译阶段,编译器就会报错
3. 特性
泛型只在编译阶段有效。看下面的代码:
List<String> stringArrayList = new ArrayList<String>();
List<Integer> integerArrayList = new ArrayList<Integer>();
Class classStringArrayList = stringArrayList.getClass();
Class classIntegerArrayList = integerArrayList.getClass();
if(classStringArrayList.equals(classIntegerArrayList)){
Log.d("泛型测试","类型相同");
}
输出结果:D/泛型测试: 类型相同。
通过上面的例子可以证明,在编译之后程序会采取去泛型化的措施。也就是说Java中的泛型,只在编译阶段有效。在编译过程中,正确检验泛型结果后,会将泛型的相关信息擦出,并且在对象进入和离开方法的边界处添加类型检查和类型转换的方法。也就是说,泛型信息不会进入到运行时阶段。
对此总结成一句话:泛型类型在逻辑上看以看成是多个不同的类型,实际上都是相同的基本类型。
4. 泛型的使用
泛型有三种使用方式,分别为:泛型类、泛型接口、泛型方法
4.3 泛型类
泛型类型用于类的定义中,被称为泛型类。通过泛型可以完成对一组类的操作对外开放相同的接口。最典型的就是各种容器类,如:List、Set、Map。
泛型类的最基本写法(这么看可能会有点晕,会在下面的例子中详解):
class 类名称 <泛型标识:可以随便写任意标识号,标识指定的泛型的类型>{
private 泛型标识 /*(成员变量类型)*/ var;
.....
}
}
一个最普通的泛型类:
//此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型
//在实例化泛型类时,必须指定T的具体类型
public class Generic<T>{
//key这个成员变量的类型为T,T的类型由外部指定
private T key;
public Generic(T key) { //泛型构造方法形参key的类型也为T,T的类型由外部指定
this.key = key;
}
public T getKey(){ //泛型方法getKey的返回值类型为T,T的类型由外部指定
return key;
}
}
//泛型的类型参数只能是类类型(包括自定义类),不能是简单类型
//传入的实参类型需与泛型的类型参数类型相同,即为Integer.
Generic<Integer> genericInteger = new Generic<Integer>(123456);
//传入的实参类型需与泛型的类型参数类型相同,即为String.
Generic<String> genericString = new Generic<String>("key_vlaue");
Log.d("泛型测试","key is " + genericInteger.getKey());
Log.d("泛型测试","key is " + genericString.getKey());
输出结果
12-27 09:20:04.432 13063-13063/? D/泛型测试: key is 123456
12-27 09:20:04.432 13063-13063/? D/泛型测试: key is key_vlaue
定义的泛型类,就一定要传入泛型类型实参么?并不是这样,在使用泛型的时候如果传入泛型实参,则会根据传入的泛型实参做相应的限制,此时泛型才会起到本应起到的限制作用。如果不传入泛型类型实参的话,在泛型类中使用泛型的方法或成员变量定义的类型可以为任何的类型。
看一个例子:
Generic generic = new Generic("111111");
Generic generic1 = new Generic(4444);
Generic generic2 = new Generic(55.55);
Generic generic3 = new Generic(false);
Log.d("泛型测试","key is " + generic.getKey());
Log.d("泛型测试","key is " + generic1.getKey());
Log.d("泛型测试","key is " + generic2.getKey());
Log.d("泛型测试","key is " + generic3.getKey());
输出结果
D/泛型测试: key is 111111
D/泛型测试: key is 4444
D/泛型测试: key is 55.55
D/泛型测试: key is false
注意:
泛型的类型参数只能是类类型,不能是简单类型。 不能对确切的泛型类型使用instanceof操作。如下面的操作是非法的,编译时会出错。 if(ex_num instanceof Generic<Number>){ }
4.4 泛型接口
泛型接口与泛型类的定义及使用基本相同。泛型接口常被用在各种类的生产器中,可以看一个例子:
//定义一个泛型接口
public interface Generator<T> {
public T next();
}
当实现泛型接口的类,未传入泛型实参时:
/**
* 未传入泛型实参时,与泛型类的定义相同,在声明类的时候,需将泛型的声明也一起加到类中
* 即:class FruitGenerator<T> implements Generator<T>{
* 如果不声明泛型,如:class FruitGenerator implements Generator<T>,编译器会报错:"Unknown class"
*/
class FruitGenerator<T> implements Generator<T>{
当实现泛型接口的类,传入泛型实参时:
/**
* 传入泛型实参时:
* 定义一个生产器实现这个接口,虽然我们只创建了一个泛型接口Generator<T>
* 但是我们可以为T传入无数个实参,形成无数种类型的Generator接口。
* 在实现类实现泛型接口时,如已将泛型类型传入实参类型,则所有使用泛型的地方都要替换成传入的实参类型
* 即:Generator<T>,public T next();中的的T都要替换成传入的String类型。
*/
public class FruitGenerator implements Generator<String> {
private String[] fruits = new String[]{"Apple", "Banana", "Pear"};
4.5 泛型通配符
我们知道Ingeter是Number的一个子类,同时在特性章节中我们也验证过Generic<Ingeter>与Generic<Number>实际上是相同的一种基本类型。那么问题来了,在使用Generic<Number>作为形参的方法中,能否使用Generic<Ingeter>的实例传入呢?在逻辑上类似于Generic<Number>和Generic<Ingeter>是否可以看成具有父子关系的泛型类型呢?
为了弄清楚这个问题,我们使用Generic<T>这个泛型类继续看下面的例子:
public void showKeyValue1(Generic<Number> obj){
Log.d("泛型测试","key value is " + obj.getKey());
}
Generic<Integer> gInteger = new Generic<Integer>(123);
Generic<Number> gNumber = new Generic<Number>(456);
showKeyValue(gNumber);
// showKeyValue这个方法编译器会为我们报错:Generic<java.lang.Integer>
// cannot be applied to Generic<java.lang.Number>
// showKeyValue(gInteger);
通过提示信息我们可以看到Generic<Integer>不能被看作为`Generic<Number>的子类。由此可以看出:同一种泛型可以对应多个版本(因为参数类型是不确定的),不同版本的泛型类实例是不兼容的。
回到上面的例子,如何解决上面的问题?总不能为了定义一个新的方法来处理Generic<Integer>类型的类,这显然与java中的多台理念相违背。因此我们需要一个在逻辑上可以表示同时是Generic<Integer>和Generic<Number>父类的引用类型。由此类型通配符应运而生。
我们可以将上面的方法改一下:
public void showKeyValue1(Generic<?> obj){
Log.d("泛型测试","key value is " + obj.getKey());
}
类型通配符一般是使用?代替具体的类型实参,注意了,此处’?’是类型实参,而不是类型形参 。重要说三遍!此处’?’是类型实参,而不是类型形参 ! 此处’?’是类型实参,而不是类型形参 !再直白点的意思就是,此处的?和Number、String、Integer一样都是一种实际的类型,可以把?看成所有类型的父类。是一种真实的类型。
可以解决当具体类型不确定的时候,这个通配符就是 ? ;当操作类型时,不需要使用类型的具体功能时,只使用Object类中的功能。那么可以用 ? 通配符来表未知类型。
4.6 泛型方法
在java中,泛型类的定义非常简单,但是泛型方法就比较复杂了。
尤其是我们见到的大多数泛型类中的成员方法也都使用了泛型,有的甚至泛型类中也包含着泛型方法,这样在初学者中非常容易将泛型方法理解错了。
泛型类,是在实例化类的时候指明泛型的具体类型;泛型方法,是在调用方法的时候指明泛型的具体类型 。
/**
* 泛型方法的基本介绍
* @param tClass 传入的泛型实参
* @return T 返回值为T类型
* 说明:
* 1)public 与 返回值中间<T>非常重要,可以理解为声明此方法为泛型方法。
* 2)只有声明了<T>的方法才是泛型方法,泛型类中的使用了泛型的成员方法并不是泛型方法。
* 3)<T>表明该方法将使用泛型类型T,此时才可以在方法中使用泛型类型T。
* 4)与泛型类的定义一样,此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型。
*/
public <T> T genericMethod(Class<T> tClass)throws InstantiationException ,
IllegalAccessException{
T instance = tClass.newInstance();
return instance;
}
Object obj = genericMethod(Class.forName("com.test.test"));
4.6.1 泛型方法的基本用法
光看上面的例子有的同学可能依然会非常迷糊,我们再通过一个例子,把我泛型方法再总结一下。
public class GenericTest {
//这个类是个泛型类,在上面已经介绍过
public class Generic<T>{
private T key;
public Generic(T key) {
this.key = key;
}
//我想说的其实是这个,虽然在方法中使用了泛型,但是这并不是一个泛型方法。
//这只是类中一个普通的成员方法,只不过他的返回值是在声明泛型类已经声明过的泛型。
//所以在这个方法中才可以继续使用 T 这个泛型。
public T getKey(){
return key;
}
/**
* 这个方法显然是有问题的,在编译器会给我们提示这样的错误信息"cannot reslove symbol E"
* 因为在类的声明中并未声明泛型E,所以在使用E做形参和返回值类型时,编译器会无法识别。
public E setKey(E key){
this.key = keu
}
*/
}
/**
* 这才是一个真正的泛型方法。
* 首先在public与返回值之间的<T>必不可少,这表明这是一个泛型方法,并且声明了一个泛型T
* 这个T可以出现在这个泛型方法的任意位置.
* 泛型的数量也可以为任意多个
* 如:public <T,K> K showKeyName(Generic<T> container){
* ...
* }
*/
public <T> T showKeyName(Generic<T> container){
System.out.println("container key :" + container.getKey());
//当然这个例子举的不太合适,只是为了说明泛型方法的特性。
T test = container.getKey();
return test;
}
//这也不是一个泛型方法,这就是一个普通的方法,只是使用了Generic<Number>这个泛型类做形参而已。
public void showKeyValue1(Generic<Number> obj){
Log.d("泛型测试","key value is " + obj.getKey());
}
//这也不是一个泛型方法,这也是一个普通的方法,只不过使用了泛型通配符?
//同时这也印证了泛型通配符章节所描述的,?是一种类型实参,可以看做为Number等所有类的父类
public void showKeyValue2(Generic<?> obj){
Log.d("泛型测试","key value is " + obj.getKey());
}
/**
* 这个方法是有问题的,编译器会为我们提示错误信息:"UnKnown class 'E' "
* 虽然我们声明了<T>,也表明了这是一个可以处理泛型的类型的泛型方法。
* 但是只声明了泛型类型T,并未声明泛型类型E,因此编译器并不知道该如何处理E这个类型。
public <T> T showKeyName(Generic<E> container){
...
}
*/
/**
* 这个方法也是有问题的,编译器会为我们提示错误信息:"UnKnown class 'T' "
* 对于编译器来说T这个类型并未项目中声明过,因此编译也不知道该如何编译这个类。
* 所以这也不是一个正确的泛型方法声明。
public void showkey(T genericObj){
}
*/
public static void main(String[] args) {
}
}
4.6.2 类中的泛型方法
当然这并不是泛型方法的全部,泛型方法可以出现杂任何地方和任何场景中使用。但是有一种情况是非常特殊的,当泛型方法出现在泛型类中时,我们再通过一个例子看一下
public class GenericFruit {
class Fruit{
4.6.3 泛型方法与可变参数
再看一个泛型方法和可变参数的例子:
public <T> void printMsg( T... args){
for(T t : args){
Log.d("泛型测试","t is " + t);
}
}
printMsg("111",222,"aaaa","2323.4",55.55);
4.6.4 静态方法与泛型
静态方法有一种情况需要注意一下,那就是在类中的静态方法使用泛型:静态方法无法访问类上定义的泛型;如果静态方法操作的引用数据类型不确定的时候,必须要将泛型定义在方法上。
即:如果静态方法要使用泛型的话,必须将静态方法也定义成泛型方法 。
public class StaticGenerator<T> {
....
....
/**
* 如果在类中定义使用泛型的静态方法,需要添加额外的泛型声明(将这个方法定义成泛型方法)
* 即使静态方法要使用泛型类中已经声明过的泛型也不可以。
* 如:public static void show(T t){..},此时编译器会提示错误信息:
"StaticGenerator cannot be refrenced from static context"
*/
public static <T> void show(T t){
}
}
4.6.5 泛型方法总结
泛型方法能使方法独立于类而产生变化,以下是一个基本的指导原则:
无论何时,如果你能做到,你就该尽量使用泛型方法。也就是说,如果使用泛型方法将整个类泛型化,
那么就应该使用泛型方法。另外对于一个static的方法而已,无法访问泛型类型的参数。
所以如果static方法要使用泛型能力,就必须使其成为泛型方法。
4.6.6 泛型上下边界
在使用泛型的时候,我们还可以为传入的泛型类型实参进行上下边界的限制,如:类型实参只准传入某种类型的父类或某种类型的子类。
为泛型添加上边界,即传入的类型实参必须是指定类型的子类型
public void showKeyValue1(Generic<? extends Number> obj){
Log.d("泛型测试","key value is " + obj.getKey());
}
Generic<String> generic1 = new Generic<String>("11111");
Generic<Integer> generic2 = new Generic<Integer>(2222);
Generic<Float> generic3 = new Generic<Float>(2.4f);
Generic<Double> generic4 = new Generic<Double>(2.56);
//这一行代码编译器会提示错误,因为String类型并不是Number类型的子类
//showKeyValue1(generic1);
showKeyValue1(generic2);
showKeyValue1(generic3);
showKeyValue1(generic4);
如果我们把泛型类的定义也改一下:
public class Generic<T extends Number>{
private T key;
public Generic(T key) {
this.key = key;
}
public T getKey(){
return key;
}
}
//这一行代码也会报错,因为String不是Number的子类
Generic<String> generic1 = new Generic<String>("11111");
再来一个泛型方法的例子:
//在泛型方法中添加上下边界限制的时候,必须在权限声明与返回值之间的<T>上添加上下边界,即在泛型声明的时候添加
//public <T> T showKeyName(Generic<T extends Number> container),编译器会报错:"Unexpected bound"
public <T extends Number> T showKeyName(Generic<T> container){
System.out.println("container key :" + container.getKey());
T test = container.getKey();
return test;
}
通过上面的两个例子可以看出:泛型的上下边界添加,必须与泛型的声明在一起 。
4.7 关于泛型数组要提一下
看到了很多文章中都会提起泛型数组,经过查看sun的说明文档,在java中是”不能创建一个确切的泛型类型的数组”的。 也就是说下面的这个例子是不可以的:
List<String>[] ls = new ArrayList<String>[10];
而使用通配符创建泛型数组是可以的,如下面这个例子:
List<?>[] ls = new ArrayList<?>[10];
这样也是可以的:
List<String>[] ls = new ArrayList[10];
List<String>[] lsa = new List<String>[10]; // Not really allowed.
Object o = lsa;
Object[] oa = (Object[]) o;
List<Integer> li = new ArrayList<Integer>();
li.add(new Integer(3));
oa[1] = li; // Unsound, but passes run time store check
String s = lsa[1].get(0); // Run-time error: ClassCastException.
这种情况下,由于JVM泛型的擦除机制,在运行时JVM是不知道泛型信息的,所以可以给oa[1]赋上一个ArrayList而不会出现异常,
但是在取出数据的时候却要做一次类型转换,所以就会出现ClassCastException,如果可以进行泛型数组的声明,
上面说的这种情况在编译期将不会出现任何的警告和错误,只有在运行时才会出错。
而对泛型数组的声明进行限制,对于这样的情况,可以在编译期提示代码有类型安全问题,比没有任何提示要强很多。
下面采用通配符的方式是被允许的:数组的类型不可以是类型变量,除非是采用通配符的方式,因为对于通配符的方式,最后取出数据是要做显式的类型转换的。
List<?>[] lsa = new List<?>[10]; // OK, array of unbounded wildcard type.
Object o = lsa;
Object[] oa = (Object[]) o;
List<Integer> li = new ArrayList<Integer>();
li.add(new Integer(3));
oa[1] = li; // Correct.
Integer i = (Integer) lsa[1].get(0); // OK
5. 最后
本文中的例子主要是为了阐述泛型中的一些思想而简单举出的,并不一定有着实际的可用性。另外,一提到泛型,相信大家用到最多的就是在集合中,其实,在实际的编程过程中,自己可以使用泛型去简化开发,且能很好的保证代码质量。
一、范型的产生历史
1、范型是Java SE1.5的新特性,范型的本质是参数化类型,也就是说所操作的数据类型被指定为。这种参数类型可以用在类、接口和方法的创建中,分别称为范型类、范型接口、范型方法。
2、Java语言引入范型的好处是安全简单。
Java SE1.5之前,没有范型的情况下,是通过对范型Object的引用实现参数的“任意化”,“任意化”的缺点是要进行显式的强制类型转换,而这种转换是要求开发者对实际参数类型可以预知的情况下进行的。对于强制类型转换错误的情况,编译器可能不提示错误,但是在运行的时候出现异常,这是一个安全隐患。
范型的好处是在编译的时候检查类型安全,并且所有的强制转换都是自动和隐式的,提高代码的重用率。
二、案例:定义狗类
在测试类创建ArrayList实例,把狗加进去,注意说明<>含义。如果<>不加那么在从ArrayList中再取出该对象的话取出的是Object,如果在定义一只猫,加入ArrayList后再从中取出,强转为狗类交给狗的实例,但是编译器不会报错。
关于什么是范型,我们可以先定义一个范型类,体会一下。它体现了Java的一种反射机制。源码如下
class Gen<T>{ private T o; //构造函数 public Gen(T a){ o=a; } //得到T的类型名称 public void showTypeName(){ System.out.println("类型是"+o.getClass().getName()); } }
下方是测试类中的代码
//得到T这个类型的名字 Gen<String> str=new Gen<String>("jjaljglajlkgj"); str.showTypeName(); //通过反射机制得到这个T类型的很多信息(比如方法名) Method[] m=o.getClass().getDeclaredMethods(); //打印 for(int i=0;i<m.length;i++) { System.out.println(m[i].getName()); }
通过反射机制,我们可以得到T这个类型的方法个数以及成员函数的函数名等。
就像我们写了同一个类,但是我们这个类的可用范围很广,在不同的而类型之间都可以使用,但是我们不可能为每个类型都写一个这样的类,所以我们就可以通过范型解决这个问题,提高了代码的复用率。
三、范型的优点
使用范型有下面几个优点
①、类型安全
②、向后兼容
③、层次清晰
④、性能较高,用GJ(范型代码)编写的代码可以为Java编译器和虚拟机带来更多的类型信息,这些信息为Java程序做进一步优化提供条件(如自动类型转换和类型检测等)。范型的反射机制为范型在类型转换的时候提供了参考依据。简单说泛型的反射机制就是通过获取以参数形式传过来的类型中的方法以继方法中的返回值和方法名等来进行自动类型转换时的检测。
第十五讲 异常
定义:当程序出现控制外部环境问题(如用户提供的文件不存在,文件损坏,或者网络不可用),Java就会用异常对象来描述。
Java中用2中方法处理异常
1、在发生异常的地方直接处理异常
2、将异常抛给调用者,让调用者去处理
一、异常分类
①、编译异常(又称检查性异常)java.lang.Exception
当程序还没有运行的时候编译器就已发现错误,此时编程者就需要处理。
②、运行异常java.lang.RuntimeException
当程序在运行的过程中发生异常,如数组访问越界。再如int a=4/0;编写过程中都不会报错。
③、ERROR java.lang.Error
这种错误是最难解决的,但一般更可能源于环境问题,如内存耗尽,杀毒软件的阻碍等。
顶层时java.lang.Throwable类,检查性异常,运行期异常,错误都是这个类的子孙类。java.lang.Error和java.lang.Exception都继承自java.lang.Throwable,而java.lang.RuntimeException继承自java.lang.Exception
二、如何处理异常
1、try{...}catch(Exception e1){.....}catch(Exception e2){...}...
程序运行产生异常时,将从程序异常发生点中断程序并抛出异常信息。也就是可以捕获然后处理。
在try中编写可能发生异常的代码块,通过catch进行捕获并处理。如果有多个catch语句,就会在发生异常的catch捕获信息。
2、finally
如果把finally块置try......catch.....语句后,finally快一般都会得到执行,它相当于一个万能的保险,即使前面的try块发生异常,而又没有对应的异常的catch块,finally块将马上执行。
以下情形,finally块将不会被执行:
(1)finally块发生了异常
(2)程序所有线程死亡
(3)在前面的代码中使用了System.exit();
(4)关闭CPU
finally语句块无论前面有没有发生异常都将执行finally语句块。
try.....catch...finally语句中catch是非必须的。但是必须有try和另两个中的至少一个。
3、将异常抛给调用者【throws Exception】
如果一个类(A)调用另一个类(B)的实例执行某个方法,而被调用的类(B)的那个方法并没有处理可能出现的异常,那么就由调用那个方法的调用者(A)进行处理。不建议这样使用,因为会导致最后我们在排错的过程中十分艰难。
----我是内容与扩充的分割线----
内容扩充模块
期望在以后的编码中BUG与我无缘---佛祖保佑无BUG源码---从网上扒来的,非本人原创。
// _ooOoo_ // o8888888o // 88" . "88 // (| -_- |) // O = /O // ____/`---'\____ // . ' \| |// `. // / \||| : |||// // / _||||| -:- |||||- // | | \ - /// | | // | \_| ''---/'' | | // .-\__ `-` ___/-. / // ___`. .' /--.-- `. . __ // ."" '< `.___\_<|>_/___.' >'"". // | | : `- \`.;` _ /`;.`/ - ` : | | // `-. \_ __ /__ _/ .-` / / // ======`-.____`-.___\_____/___.-`____.-'====== // `=---=' // // ............................................. // 佛祖保佑 永无BUG // 佛曰: // 写字楼里写字间,写字间里程序员; // 程序人员写程序,又拿程序换酒钱。 // 酒醒只在网上坐,酒醉还来网下眠; // 酒醉酒醒日复日,网上网下年复年。 // 但愿老死电脑间,不愿鞠躬老板前; // 奔驰宝马贵者趣,公交自行程序员。 // 别人笑我忒疯癫,我笑自己命太贱; // 不见满街漂亮妹,哪个归得程序员?
一、数在内存中的存储
一、原码,反码,补码
在 C 语言里数据类型有 有符号数 和 无符号数 之分。
只有有符号数才有原码,反码,补码的概念,因为有符号数的最高位表示正负。
而无符号数不管怎么样都是表示正数,所以它的原码,反码,补码都是一样。
在计算机中为了计算方便,所有数据都是以补码的形式存储的。
因为这样减法运算也可以按照加法来运算,这就很巧妙了。
举个例子:0,-0,21.65625,-21.65625的原码,反码,补码分别是多少?
(所有的数据类型都可以这样运算,为了方便,这里仅展示计算方式,不涉及相关数据大小)
| 十进制数 | 原码 | 反码 | 补码 |
| 0 | 0000 0000 0000 0000 | 0000 0000 0000 0000 | 0000 0000 0000 0000 |
| -0 | 1000 0000 0000 0000 | 1111 1111 1111 1111 | 0000 0000 0000 0000 |
| 18 | 0000 0000 0001 0010 | 0000 0000 0001 0010 | 0000 0000 0001 0010 |
| -18 | 1000 0000 0001 0010 | 1111 1111 1110 1101 | 1111 1111 1110 1110 |
| 21.65625 | 0001 0101.1010 1000 | 0001 0101.1010 1000 | 0001 0101.1010 1000 |
| -21.65625 | 1001 0101.1010 1000 | 1110 1010.0101 0111 | 1110 1010.0101 1000 |
(从这个表中可以清楚的看到所有的加减法运算都可以用加法来进行运算)
原码,反码,补码的运算方式:
[原码]:计算机中将一个数字转换为二进制,并在其最高位加上符号的一种表示方法。
[反码]:根据表示规定,正数的反码就是本身,而负数的反码,除符号位外,其余位依次取反。
[补码]:根据表示规定,正数的补码就是本身,而负数的补码,是在其反码的末位加1。
举个例子:
正数 5 和 负数 5
5 原码:00000101 -5 原码:10000101
反码:00000101 -5 反码:11111010
补码:00000101 -5 补码:11111011
二、逻辑运算
| 逻辑运算符 | 名称 | 说明 |
| << | 左移 | 左移n位代表乘2^n |
| >> | 右移 | 右移n位代表除2^n |
| | | 位或 | 即全为0则为0 |
| & | 位与 | 即全为1则为1 |
| ~ | 位非 | 即 ~1 得 0,~0 得 1 |
| ^ | 位异或 | 即相同为 0,不同为 1 |
二、进制换算
三、float和double的取值范围和表示
一、存储结构介绍
C 语言和C#语言中,对于浮点类型的数据采用单精度类型(float)和双精度类型(double)来存储,float数据占用32bit, double数据占用64bit,我们在声明一个变量float f= 2.25f的时候,是如何分配内存的呢?如果胡乱分配,那世界岂不是乱套了么,其实不论是float还是double在存储方式上都是遵从IEEE的规范的,float遵从的是IEEE R32.24 ,而double 遵从的是R64.53。
无论是单精度还是双精度在存储中都分为三个部分:
1.符号位(Sign) : 0代表正,1代表为负
2.指数位(Exponent):用于存储科学计数法中的指数数据,并且采用移位存储
3.尾数部分(Mantissa):尾数部分
Float的存储方式
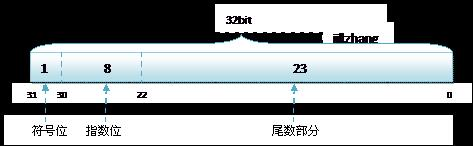
double的存储方式

float和double的精度是由尾数的位数来决定的。
浮点数在内存中是按科学计数法来存储的,其整数部分始终是一个隐含着的“1”,由于它是不变的,故不能对精度造成影响。
float:2^23 = 8388608,共七位,意味着最多能有7位有效数字,但绝对能保证的为6位,也即float的精度为6~7位有效数字;
double:2^52 = 4503599627370496,一共16位,同理,double的精度为15~16位。
float的范围为-2^128 ~ +2^128,也即-3.40E+38 ~ +3.40E+38;
double的范围为-2^1024 ~ +2^1024,也即-1.79E+308 ~ +1.79E+308
二、符号位,阶码,尾数
在计算机内部实数都是以 (符号位-阶码-尾数) 的形式表示的。
一个 float 型实数在内存中占 4byte,即 32bit。
从低位到高位依次叫 第0位 到 第31位。这 32位 可以分成 3个部分:
1、符号位(第31位) --- 0表示正数,1表示负数。
2、阶码(第30位 到 第 23位) ---
这8个二进制位表示该实数转化为规格后的二进制实数后的指数与127之和(即所谓的阶码)。(127即所谓的偏移量)
规格化后的二进制实数的指数只能在 -127 到 +127 之间。
3、尾数(余下的23位) --- 即小数点后的23位。
double 类型:(8byte,即 64bit)
1、符号位(第31位) --- 0表示正数,1表示负数。
2、阶码(第30位 到 第20位)。规格化后的二进制实数的指数只能在 -1023 到 +1023 之间。
3、尾数(余下的52位) --- 即小数点后的52位。
举个例子(float类型):1.5,-1.5 符号位,阶码,尾数,及在计算机内存中的表示(16进制)
| 十进制数 | 二进制实数 | 符号位 | 阶码 | 尾数 | 内存中的表示(2进制) | 内存中的表示(16进制) |
| 0.75 | 1.1*2^-1 | 0 | 0111 1110 | 1 | 0011 1111 0100 0000 0000 0000 0000 0000 | 3F 40 00 00 |
| -0.75 | -1.1*2^-1 | 1 | 0111 1110 | 1 | 1011 1111 0100 0000 0000 0000 0000 0000 | BF 40 00 00 |
| 1.5 | 1.1*2^0 | 0 | 0111 1111 | 1 | 0011 1111 1100 0000 0000 0000 0000 0000 | 3F C0 00 00 |
| -1.5 | -1.1*2^0 | 1 | 0111 1111 | 1 | 1011 1111 1100 0000 0000 0000 0000 0000 | BF C0 00 00 |
| 3.0 | 1.1*2^1 | 0 | 1000 0000 | 1 | 0100 0000 0100 0000 0000 0000 0000 0000 | 40 40 00 00 |
| -3.0 | -1.1*2^1 | 1 | 1000 0000 | 1 | 1100 0000 0100 0000 0000 0000 0000 0000 | C0 40 00 00 |
| 5.625 | 1.01101*2^2 | 0 | 1000 0001 | 01101 | 0100 0000 1011 0100 0000 0000 0000 0000 | 40 B4 00 00 |
| -5.625 | -1.01101*2^2 | 1 | 1000 0001 | 01101 | 1100 0000 1011 0100 0000 0000 0000 0000 | C0 B4 00 00 |
四、Java 基本数据类型boolean在内存中到底占用多少字节
为什么要问这个问题,首先在Java中定义的八种基本数据类型中,boolean类型没有给出具体的占用字节数,因为对虚拟机来说根本就不存在 boolean 这个类型,boolean类型在编译后会使用其他数据类型来表示,那boolean类型究竟占用多少个字节?答案五花八门,基本有以下几种:
1、1个bit
理由是boolean类型的值只有true和false两种逻辑值,在编译后会使用1和0来表示,这两个数在内存中只需要1位(bit)即可存储,位是计算机最小的存储单位。
2、1个字节
理由是虽然编译后1和0只需占用1位空间,但计算机处理数据的最小单位是1个字节,1个字节等于8位,实际存储的空间是:用1个字节的最低位存储,其他7位用0填补,如果值是true的话则存储的二进制为:0000 0001,如果是false的话则存储的二进制为:0000 0000。
3、4个字节
在Java虚拟机中没有任何供boolean值专用的字节码指令,Java语言表达式所操作的boolean值,在编译之后都使用Java虚拟机中的int数据类型来代替,而boolean数组将会被编码成Java虚拟机的byte数组,每个元素占8位
显然第三条是更准确的说法,那虚拟机为什么要用int来代替boolean呢?为什么不用byte或short,这样不是更节省内存空间吗。大多数人都会很自然的这样去想,我同样也有这个疑问,经过查阅资料发现,使用int的原因是,对于当下32位的处理器(CPU)来说,一次处理数据是32位(这里不是指的是32/64位系统,而是指CPU硬件层面),具有高效存取的特点。
可以看出,boolean类型没有给出精确的定义,《Java虚拟机规范》给出了boolean类型占4个字节,和boolean数组1个字节的定义,具体还要看虚拟机实现是否按照规范来,所以1个字节、4个字节都是有可能的。这其实是运算效率和存储空间之间的博弈,两者都非常的重要。
原文:https://blog.csdn.net/dingpf1209/article/details/80259500
五、ASCII美国信息交换标准代码
由于计算机只认识二进制数,即0或1,所以每一个字符都被用一种编码方式转化成二进制存储在计算机中,这种编码方式就是ASCII
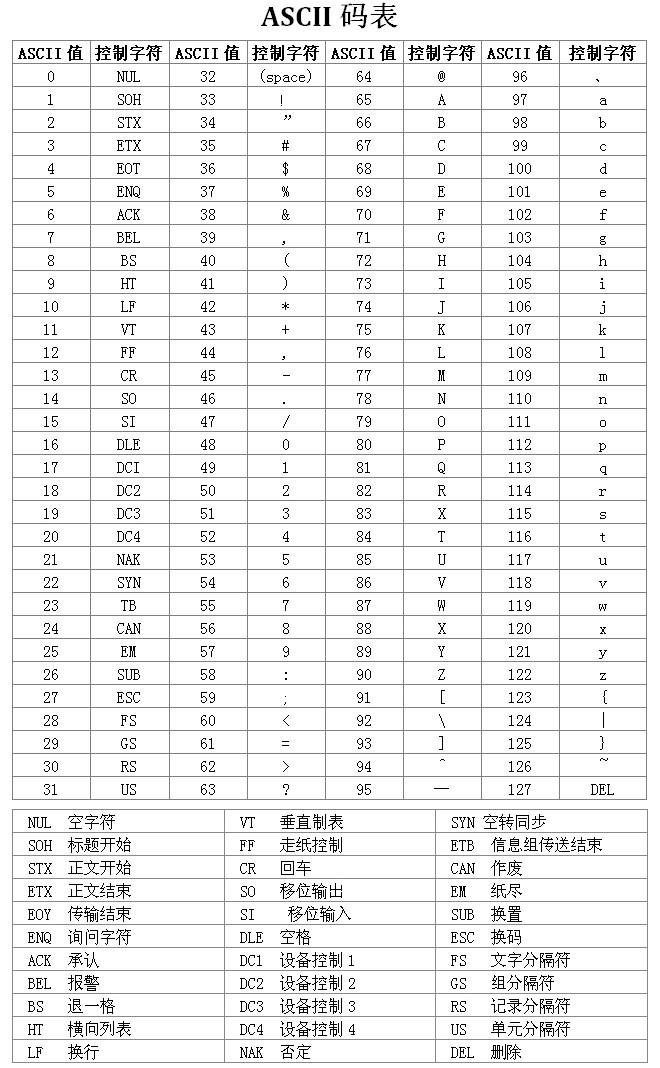
六、对《数据结构》重新仔细学习
七、自加与自减的注意事项
++:自增
a.自增运算符只能作用于变量,作用是让该变量的值增加1
规律:
如果++变量和变量++是单独一个式子(在编程语言中,一句话是以英文的;分号结尾的) ,那么++在前和在后没有任何区别
如: ++i;和i++;的结果是一样的,都是在i的原来数值上加1。
如果++变量和变量++是混合式子,那么++在前,先加后用
那么++在后,先用后加;
比如:
int j = 10; //int k = j++; // ++在后,先用后加 int k = ++j; // ++在前,先加后用 System.out.println(k); // 11 System.out.println(j); // 11
自减--的情况和自加相同,不再赘述。
规律:
如果--变量和变量--是单独一个式子 ,那么--在前和在后没有任何区别
如果--变量和变量--是混合式子,那么--在前,先减后用
那么--在后,先用后减
再深入:特别注意请看代码
/* * 作者:Alvin * 功能:前、后自加和自减的危险使用方法 * 时间:2019年2月22日10:33:38 * */ public class Test { public static void main(String[] args) { // TODO Auto-generated method stub //定义两个变量 int i=0; //==================对变量i进行操作=========== /* * 下方报错,原因是和栈的进出顺序有关如果,在java
*可以这么认为,自加和自减运算在进行操作的时候都会
*返回一个计算后的结果常量并改变被操作变量的值,而
*常量又不可以进行自加和自减操作所以会报错。 * */ --(i++); System.out.println(i); } }
拓展阅读: j=j++和j=++j; 的区别
八、i+=1;、++i;和i=i+1;这三个表达式的比较
我们先看一下在编译器中的情况。
/* * 作者:Alvin * 功能:i+=1;、++i;和i=i+1;这三个表达式的比较 * 时间:2019年2月22日09:58:08 * */ public class Test { public static void main(String[] args) { // TODO Auto-generated method stub //定义两个变量 byte c=0;//此处的byte、short变量结果相同,char不考虑比较没有意义 int b=0; //==================对变量c进行操作=========== //自加运算 c++; System.out.println(c); //符合赋值运算 c+=1; c+=c; System.out.println(c); //数学运算 c=c+1; System.out.println(c); //==================对变量b进行操作=========== //自加运算 b++; System.out.println(b); //符合赋值运算 b+=1; b+=b; System.out.println(b); //数学运算 b=b+1; System.out.println(b); } }
在开发工具中会报错。
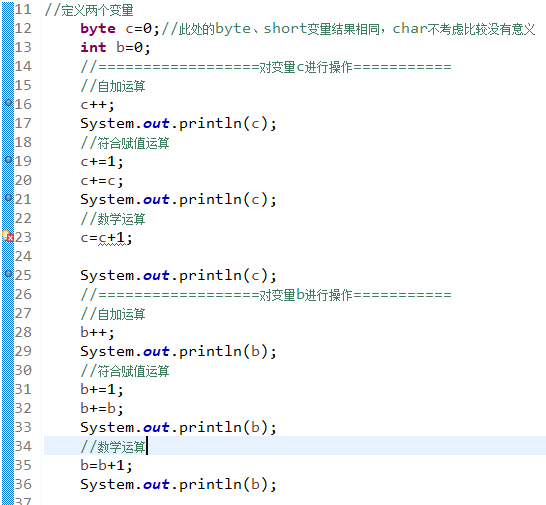
在上面的结果中可以看到,在23行已经报错,其他代码正常。数学运算符中的+、-、*、/、%存在着类型的自动转换,而++和+=运算符进行运算的时候,编译器存在着对变量和常量的运算的优化
以+=为例【++的情况和此类似,不再赘述。】
+=运算符
int a = 10;
a += 5; 等价于 a = a + 5;
short s = 10;
s+=5; 等价于 s = (short)(s + 5);
System.out.println(s);
byte b = 10;
b+=5;等价于 b = (byte)(b + 5)
九、enum类型讲解
十、Java中的关键字
| 关键字 | 含义 |
| abstract | 表明类或者成员方法具有抽象属性 |
| assert | 断言,用来进行程序调试 |
| boolean | 基本数据类型之一,布尔类型 |
| break | 提前跳出一个块 |
| byte | 基本数据类型之一,字节类型 |
| case | 用在switch语句之中,表示其中的一个分支 |
| catch | 用在异常处理中,用来捕捉异常 |
| char | 基本数据类型之一,字符类型 |
| class | 声明一个类 |
| const | 保留关键字,没有具体含义 |
| continue | 回到一个块的开始处 |
| default | 默认,例如,用在switch语句中,表明一个默认的分支 |
| do | 用在do-while循环结构中 |
| double | 基本数据类型之一,双精度浮点数类型 |
| else | 用在条件语句中,表明当条件不成立时的分支 |
| enum | 枚举 |
| extends | 表明一个类型是另一个类型的子类型,这里常见的类型有类和接口 |
| final | 用来说明最终属性,表明一个类不能派生出子类,或者成员方法不能被覆盖,或者成员域的值不能被改变,用来定义常量 |
| finally | 用于处理异常情况,用来声明一个基本肯定会被执行到的语句块 |
| float | 基本数据类型之一,单精度浮点数类型 |
| for | 一种循环结构的引导词 |
| goto | 保留关键字,没有具体含义 |
| if | 条件语句的引导词 |
| implements | 表明一个类实现了给定的接口 |
| import | 表明要访问指定的类或包 |
| instanceof | 用来测试一个对象是否是指定类型的实例对象 |
| int | 基本数据类型之一,整数类型 |
| interface | 接口 |
| long | 基本数据类型之一,长整数类型 |
| native | 用来声明一个方法是由与计算机相关的语言(如C/C++/FORTRAN语言)实现的 |
| new | 用来创建新实例对象 |
| package | 包 |
| private | 一种访问控制方式:私用模式 |
| protected | 一种访问控制方式:保护模式 |
| public | 一种访问控制方式:共用模式 |
| return | 从成员方法中返回数据 |
| short | 基本数据类型之一,短整数类型 |
| static | 表明具有静态属性 |
| strictfp | 用来声明FP_strict(单精度或双精度浮点数)表达式遵循IEEE 754算术规范 [1] |
| super | 表明当前对象的父类型的引用或者父类型的构造方法 |
| switch | 分支语句结构的引导词 |
| synchronized | 表明一段代码需要同步执行 |
| this | 指向当前实例对象的引用 |
| throw | 抛出一个异常 |
| throws | 声明在当前定义的成员方法中所有需要抛出的异常 |
| transient | 声明不用序列化的成员域 |
| try | 尝试一个可能抛出异常的程序块 |
| void | 声明当前成员方法没有返回值 |
| volatile | 表明两个或者多个变量必须同步地发生变化 |
| while | 用在循环结构中 |
十一、>>堆和栈的区别<<
以下采用C/C++语言的知识进行讲解
一、预备知识—程序的内存分配
一个由c/C++编译的程序占用的内存分为以下几个部分
1、栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
2、堆区(heap) — 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表,呵呵。
3、全局区(静态区)(static)—,全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。 - 程序结束后有系统释放
4、文字常量区—常量字符串就是放在这里的。 程序结束后由系统释放
5、程序代码区—存放函数体的二进制代码。
二、例子程序
这是一个前辈写的,非常详细
//main.cpp
int a = 0; 全局初始化区
char *p1; 全局未初始化区
main()
{
int b; 栈
char s[] = "abc"; 栈
char *p2; 栈
char *p3 = "123456"; 123456�在常量区,p3在栈上。
static int c =0; 全局(静态)初始化区
p1 = (char *)malloc(10);
p2 = (char *)malloc(20);
分配得来得10和20字节的区域就在堆区。
strcpy(p1, "123456"); 123456�放在常量区,编译器可能会将它与p3所指向的"123456"优化成一个地方。
}
三、堆和栈的理论知识
3.1申请方式
stack:
由系统自动分配。 例如,声明在函数中一个局部变量 int b; 系统自动在栈中为b开辟空间
heap:
需要程序员自己申请,并指明大小,在c中malloc函数
如p1 = (char *)malloc(10);
在C++中用new运算符
如p2 = (char *)malloc(10);
但是注意p1、p2本身是在栈中的。
3.2 申请后系统的响应
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
堆:首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,
会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。另外,由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。
3.3申请大小的限制
栈:在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在WINDOWS下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
2.4申请效率的比较:
栈由系统自动分配,速度较快。但程序员是无法控制的。
堆是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便.
另外,在WINDOWS下,最好的方式是用VirtualAlloc分配内存,他不是在堆,也不是在栈是直接在进程的地址空间中保留一快内存,虽然用起来最不方便。但是速度快,也最灵活。
2.5堆和栈中的存储内容
栈: 在函数调用时,第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条可执行语句)的地址,然后是函数的各个参数,在大多数的C编译器中,参数是由右往左入栈的,然后是函数中的局部变量。注意静态变量是不入栈的。
当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。
堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。
2.6存取效率的比较
char s1[] = "aaaaaaaaaaaaaaa";
char *s2 = "bbbbbbbbbbbbbbbbb";
aaaaaaaaaaa是在运行时刻赋值的;
而bbbbbbbbbbb是在编译时就确定的;
但是,在以后的存取中,在栈上的数组比指针所指向的字符串(例如堆)快。
比如:
#include
void main()
{
char a = 1;
char c[] = "1234567890";
char *p ="1234567890";
a = c[1];
a = p[1];
return;
}
对应的汇编代码
10: a = c[1]; 00401067 8A 4D F1 mov cl,byte ptr [ebp-0Fh] 0040106A 88 4D FC mov byte ptr [ebp-4],cl 11: a = p[1]; 0040106D 8B 55 EC mov edx,dword ptr [ebp-14h] 00401070 8A 42 01 mov al,byte ptr [edx+1] 00401073 88 45 FC mov byte ptr [ebp-4],al
第一种在读取时直接就把字符串中的元素读到寄存器cl中,而第二种则要先把指针值读到edx中,在根据edx读取字符,显然慢了。
2.7小结:
堆和栈的区别可以用如下的比喻来看出:
使用栈就象我们去饭馆里吃饭,只管点菜(发出申请)、付钱、和吃(使用),吃饱了就走,不必理会切菜、洗菜等准备工作和洗碗、刷锅等扫尾工作,他的好处是快捷,但是自由度小。
使用堆就象是自己动手做喜欢吃的菜肴,比较麻烦,但是比较符合自己的口味,而且自由度大。
四、windows进程中的内存结构
在阅读本文之前,如果你连堆栈是什么多不知道的话,请先阅读文章后面的基础知识。
接触过编程的人都知道,高级语言都能通过变量名来访问内存中的数据。那么这些变量在内存中是如何存放的呢?程序又是如何使用这些变量的呢?下面就会对此进行深入的讨论。下文中的C语言代码如没有特别声明,默认都使用VC编译的release版。
首先,来了解一下 C 语言的变量是如何在内存分部的。C 语言有全局变量(Global)、本地变量(Local),静态变量(Static)、寄存器变量(Regeister)。每种变量都有不同的分配方式。先来看下面这段代码:
#include <stdio.h>
int g1=0, g2=0, g3=0;
int main()
{
static int s1=0, s2=0, s3=0;
int v1=0, v2=0, v3=0;
//打印出各个变量的内存地址
printf("0x%08x
",&v1); //打印各本地变量的内存地址
printf("0x%08x
",&v2);
printf("0x%08x
",&v3);
printf("0x%08x
",&g1); //打印各全局变量的内存地址
printf("0x%08x
",&g2);
printf("0x%08x
",&g3);
printf("0x%08x
",&s1); //打印各静态变量的内存地址
printf("0x%08x
",&s2);
printf("0x%08x
",&s3);
return 0;
}
编译后的执行结果是[不同电脑会打印出不同的结果]:
0x0012ff78
0x0012ff7c
0x0012ff80
0x004068d0
0x004068d4
0x004068d8
0x004068dc
0x004068e0
0x004068e4
输出的结果就是变量的内存地址。其中v1,v2,v3是本地变量,g1,g2,g3是全局变量,s1,s2,s3是静态变量。你可以看到这些变量在内存是连续分布的,但是本地变量和全局变量分配的内存地址差了十万八千里,而全局变量和静态变量分配的内存是连续的。这是因为本地变量和全局/静态变量是分配在不同类型的内存区域中的结果。对于一个进程的内存空间而言,可以在逻辑上分成3个部份:代码区,静态数据区和动态数据区。动态数据区一般就是“堆栈”。“栈(stack)”和“堆(heap)”是两种不同的动态数据区,栈是一种线性结构,堆是一种链式结构。进程的每个线程都有私有的“栈”,所以每个线程虽然代码一样,但本地变量的数据都是互不干扰。一个堆栈可以通过“基地址”和“栈顶”地址来描述。全局变量和静态变量分配在静态数据区,本地变量分配在动态数据区,即堆栈中。程序通过堆栈的基地址和偏移量来访问本地变量。
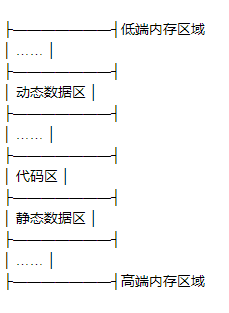
堆栈是一个先进后出的数据结构,栈顶地址总是小于等于栈的基地址。我们可以先了解一下函数调用的过程,以便对堆栈在程序中的作用有更深入的了解。不同的语言有不同的函数调用规定,这些因素有参数的压入规则和堆栈的平衡。windows API的调用规则和ANSI C的函数调用规则是不一样的,前者由被调函数调整堆栈,后者由调用者调整堆栈。两者通过“__stdcall”和“__cdecl”前缀区分。先看下面这段代码:
#include <stdio.h> void __stdcall func(int param1,int param2,int param3) { int var1=param1; int var2=param2; int var3=param3; printf("0x%08x ",¶m1); //打印出各个变量的内存地址 printf("0x%08x ",¶m2); printf("0x%08x ",¶m3); printf("0x%08x ",&var1); printf("0x%08x ",&var2); printf("0x%08x ",&var3); return; } int main() { func(1,2,3); return 0; } 编译后的执行结果是[不同变量会打印出不同结果]: 0x0012ff78 0x0012ff7c 0x0012ff80 0x0012ff68 0x0012ff6c 0x0012ff70
上图就是函数调用过程中堆栈的样子了。首先,三个参数以从又到左的次序压入堆栈,先压“param3”,再压“param2”,最后压入“param1”;然后压入函数的返回地址(RET),接着跳转到函数地址接着执行(这里要补充一点,介绍UNIX下的缓冲溢出原理的文章中都提到在压入RET后,继续压入当前EBP,然后用当前ESP代替EBP。然而,有一篇介绍windows下函数调用的文章中说,在windows下的函数调用也有这一步骤,但根据我的实际调试,并未发现这一步,这还可以从param3和var1之间只有4字节的间隙这点看出来);第三步,将栈顶(ESP)减去一个数,为本地变量分配内存空间,上例中是减去12字节(ESP=ESP-3*4,每个int变量占用4个字节);接着就初始化本地变量的内存空间。由于“__stdcall”调用由被调函数调整堆栈,所以在函数返回前要恢复堆栈,先回收本地变量占用的内存(ESP=ESP+3*4),然后取出返回地址,填入EIP寄存器,回收先前压入参数占用的内存(ESP=ESP+3*4),继续执行调用者的代码。参见下列汇编代码:
;--------------func 函数的汇编代码------------------- :00401000 83EC0C sub esp, 0000000C //创建本地变量的内存空间 :00401003 8B442410 mov eax, dword ptr [esp+10] :00401007 8B4C2414 mov ecx, dword ptr [esp+14] :0040100B 8B542418 mov edx, dword ptr [esp+18] :0040100F 89442400 mov dword ptr [esp], eax :00401013 8D442410 lea eax, dword ptr [esp+10] :00401017 894C2404 mov dword ptr [esp+04], ecx ……………………(省略若干代码) :00401075 83C43C add esp, 0000003C ;恢复堆栈,回收本地变量的内存空间 :00401078 C3 ret 000C ;函数返回,恢复参数占用的内存空间 ;如果是“__cdecl”的话,这里是“ret”,堆栈将由调用者恢复 ;-------------------函数结束------------------------- ;--------------主程序调用func函数的代码-------------- :00401080 6A03 push 00000003 //压入参数param3 :00401082 6A02 push 00000002 //压入参数param2 :00401084 6A01 push 00000001 //压入参数param1 :00401086 E875FFFFFF call 00401000 //调用func函数 ;如果是“__cdecl”的话,将在这里恢复堆栈,“add esp, 0000000C”
聪明的读者看到这里,差不多就明白缓冲溢出的原理了。先来看下面的代码:
#include <stdio.h> #include <string.h> void __stdcall func() { char lpBuff[8]="�"; strcat(lpBuff,"AAAAAAAAAAA"); return; } int main() { func(); return 0; }
编译后执行一下回怎么样?哈,“"0x00414141"指令引用的"0x00000000"内存。该内存不能为"read"。”,“非法操作”喽!"41"就是"A"的16进制的ASCII码了,那明显就是strcat这句出的问题了。"lpBuff"的大小只有8字节,算进结尾的�,那strcat最多只能写入7个"A",但程序实际写入了11个"A"外加1个�。再来看看上面那幅图,多出来的4个字节正好覆盖了RET的所在的内存空间,导致函数返回到一个错误的内存地址,执行了错误的指令。如果能精心构造这个字符串,使它分成三部分,前一部份仅仅是填充的无意义数据以达到溢出的目的,接着是一个覆盖RET的数据,紧接着是一段shellcode,那只要着个RET地址能指向这段shellcode的第一个指令,那函数返回时就能执行shellcode了。但是软件的不同版本和不同的运行环境都可能影响这段shellcode在内存中的位置,那么要构造这个RET是十分困难的。一般都在RET和shellcode之间填充大量的NOP指令,使得exploit有更强的通用性。

windows下的动态数据除了可存放在栈中,还可以存放在堆中。了解C++的朋友都知道,C++可以使用new关键字来动态分配内存。来看下面的C++代码:
#include <stdio.h> #include <iostream.h> #include <windows.h> void func() { char *buffer=new char[128]; char bufflocal[128]; static char buffstatic[128]; printf("0x%08x ",buffer); //打印堆中变量的内存地址 printf("0x%08x ",bufflocal); //打印本地变量的内存地址 printf("0x%08x ",buffstatic); //打印静态变量的内存地址 } void main() { func(); return; }
程序执行结果为【不同电脑输出结果不同】: 0x004107d0 0x0012ff04 0x004068c0
可以发现用new关键字分配的内存即不在栈中,也不在静态数据区。VC编译器是通过windows下的“堆(heap)”来实现new关键字的内存动态分配。在讲“堆”之前,先来了解一下和“堆”有关的几个API函数:
HeapAlloc 在堆中申请内存空间
HeapCreate 创建一个新的堆对象
HeapDestroy 销毁一个堆对象
HeapFree 释放申请的内存
HeapWalk 枚举堆对象的所有内存块
GetProcessHeap 取得进程的默认堆对象
GetProcessHeaps 取得进程所有的堆对象
LocalAlloc
GlobalAlloc
当进程初始化时,系统会自动为进程创建一个默认堆,这个堆默认所占内存的大小为1M。堆对象由系统进行管理,它在内存中以链式结构存在。通过下面的代码可以通过堆动态申请内存空间:
HANDLE hHeap=GetProcessHeap(); char *buff=HeapAlloc(hHeap,0,8);
其中hHeap是堆对象的句柄,buff是指向申请的内存空间的地址。那这个hHeap究竟是什么呢?它的值有什么意义吗?看看下面这段代码吧:
#pragma comment(linker,"/entry:main") //定义程序的入口
#include <windows.h>
_CRTIMP int (__cdecl *printf)(const char *, ...); //定义STL函数printf
/*---------------------------------------------------------------------------
写到这里,我们顺便来复习一下前面所讲的知识:
(*注)printf函数是C语言的标准函数库中函数,VC的标准函数库由msvcrt.dll模块实现。
由函数定义可见,printf的参数个数是可变的,函数内部无法预先知道调用者压入的参数个数,函数只能通过分析第一个参数字符串的格式来获得压入参数的信息,由于这里参数的个数是动态的,所以必须由调用者来平衡堆栈,这里便使用了__cdecl调用规则。BTW,Windows系统的API函数基本上是__stdcall调用形式,只有一个API例外,那就是wsprintf,它使用__cdecl调用规则,同printf函数一样,这是由于它的参数个数是可变的缘故。
---------------------------------------------------------------------------*/
void main()
{
HANDLE hHeap=GetProcessHeap();
char *buff=HeapAlloc(hHeap,0,0x10);
char *buff2=HeapAlloc(hHeap,0,0x10);
HMODULE hMsvcrt=LoadLibrary("msvcrt.dll");
printf=(void *)GetProcAddress(hMsvcrt,"printf");
printf("0x%08x
",hHeap);
printf("0x%08x
",buff);
printf("0x%08x
",buff2);
}
执行结果为【不同电脑输出信息不同】:
0x00130000 0x00133100 0x00133118
hHeap的值怎么和那个buff的值那么接近呢?其实hHeap这个句柄就是指向HEAP首部的地址。在进程的用户区存着一个叫PEB(进程环境块)的结构,这个结构中存放着一些有关进程的重要信息,其中在PEB首地址偏移0x18处存放的ProcessHeap就是进程默认堆的地址,而偏移0x90处存放了指向进程所有堆的地址列表的指针。windows有很多API都使用进程的默认堆来存放动态数据,如windows 2000下的所有ANSI版本的函数都是在默认堆中申请内存来转换ANSI字符串到Unicode字符串的。对一个堆的访问是顺序进行的,同一时刻只能有一个线程访问堆中的数据,当多个线程同时有访问要求时,只能排队等待,这样便造成程序执行效率下降。
最后来说说内存中的数据对齐。所位数据对齐,是指数据所在的内存地址必须是该数据长度的整数倍,DWORD数据的内存起始地址能被4除尽,WORD数据的内存起始地址能被2除尽,x86 CPU能直接访问对齐的数据,当他试图访问一个未对齐的数据时,会在内部进行一系列的调整,这些调整对于程序来说是透明的,但是会降低运行速度,所以编译器在编译程序时会尽量保证数据对齐。同样一段代码,我们来看看用VC、Dev-C++和lcc三个不同编译器编译出来的程序的执行结果:
#include <stdio.h> int main() { int a; char b; int c; printf("0x%08x ",&a); printf("0x%08x ",&b); printf("0x%08x ",&c); return 0; }
这是用VC编译后的执行结果:
0x0012ff7c 0x0012ff7b 0x0012ff80
变量在内存中的顺序:b(1字节)-a(4字节)-c(4字节)。
这是用Dev-C++编译后的执行结果:
0x0022ff7c 0x0022ff7b 0x0022ff74
变量在内存中的顺序:c(4字节)-中间相隔3字节-b(占1字节)-a(4字节)。
这是用lcc编译后的执行结果:
0x0012ff6c 0x0012ff6b 0x0012ff64
变量在内存中的顺序:同上。
三个编译器都做到了数据对齐,但是后两个编译器显然没VC“聪明”,让一个char占了4字节,浪费内存哦。
基础知识:
堆栈是一种简单的数据结构,是一种只允许在其一端进行插入或删除的线性表。允许插入或删除操作的一端称为栈顶,另一端称为栈底,对堆栈的插入和删除操作被称为入栈和出栈。有一组CPU指令可以实现对进程的内存实现堆栈访问。其中,POP指令实现出栈操作,PUSH指令实现入栈操作。CPU的ESP寄存器存放当前线程的栈顶指针,EBP寄存器中保存当前线程的栈底指针。CPU的EIP寄存器存放下一个CPU指令存放的内存地址,当CPU执行完当前的指令后,从EIP寄存器中读取下一条指令的内存地址,然后继续执行。
参考:《Windows下的HEAP溢出及其利用》by: isno
《windows核心编程》by: Jeffrey Richter
摘要: 讨论常见的堆性能问题以及如何防范它们。(共 9 页)
前言
您是否是动态分配的 C/C++ 对象忠实且幸运的用户?您是否在模块间的往返通信中频繁地使用了“自动化”?您的程序是否因堆分配而运行起来很慢?不仅仅您遇到这样的问题。几乎所有项目迟早都会遇到堆问题。大家都想说,“我的代码真正好,只是堆太慢”。那只是部分正确。更深入理解堆及其用法、以及会发生什么问题,是很有用的。
1、什么是堆?
(如果您已经知道什么是堆,可以跳到“什么是常见的堆性能问题?”部分)
在程序中,使用堆来动态分配和释放对象。在下列情况下,调用堆操作:
事先不知道程序所需对象的数量和大小。
2、对象太大而不适合堆栈分配程序。
堆使用了在运行时分配给代码和堆栈的内存之外的部分内存。下图给出了堆分配程序的不同层。
GlobalAlloc/GlobalFree:Microsoft Win32 堆调用,这些调用直接与每个进程的默认堆进行对话。
LocalAlloc/LocalFree:Win32 堆调用(为了与 Microsoft Windows NT 兼容),这些调用直接与每个进程的默认堆进行对话。
COM 的 IMalloc 分配程序(或 CoTaskMemAlloc / CoTaskMemFree):函数使用每个进程的默认堆。自动化程序使用“组件对象模型 (COM)”的分配程序,而申请的程序使用每个进程堆。
C/C++ 运行时 (CRT) 分配程序:提供了 malloc() 和 free() 以及 new 和 delete 操作符。如 Microsoft Visual Basic 和 Java 等语言也提供了新的操作符并使用垃圾收集来代替堆。CRT 创建自己的私有堆,驻留在 Win32 堆的顶部。
Windows NT 中,Win32 堆是 Windows NT 运行时分配程序周围的薄层。所有 API 转发它们的请求给 NTDLL。
Windows NT 运行时分配程序提供 Windows NT 内的核心堆分配程序。它由具有 128 个大小从 8 到 1,024 字节的空闲列表的前端分配程序组成。后端分配程序使用虚拟内存来保留和提交页。
在图表的底部是“虚拟内存分配程序”,操作系统使用它来保留和提交页。所有分配程序使用虚拟内存进行数据的存取。
分配和释放块不就那么简单吗?为何花费这么长时间?
3、堆实现的注意事项
传统上,操作系统和运行时库是与堆的实现共存的。在一个进程的开始,操作系统创建一个默认堆,叫做“进程堆”。如果没有其他堆可使用,则块的分配使用“进程堆”。语言运行时也能在进程内创建单独的堆。(例如,C 运行时创建它自己的堆。)除这些专用的堆外,应用程序或许多已载入的动态链接库 (DLL) 之一可以创建和使用单独的堆。Win32 提供一整套 API 来创建和使用私有堆。有关堆函数(英文)的详尽指导,请参见 MSDN。
当应用程序或 DLL 创建私有堆时,这些堆存在于进程空间,并且在进程内是可访问的。从给定堆分配的数据将在同一个堆上释放。(不能从一个堆分配而在另一个堆释放。)
在所有虚拟内存系统中,堆驻留在操作系统的“虚拟内存管理器”的顶部。语言运行时堆也驻留在虚拟内存顶部。某些情况下,这些堆是操作系统堆中的层,而语言运行时堆则通过大块的分配来执行自己的内存管理。不使用操作系统堆,而使用虚拟内存函数更利于堆的分配和块的使用。
典型的堆实现由前、后端分配程序组成。前端分配程序维持固定大小块的空闲列表。对于一次分配调用,堆尝试从前端列表找到一个自由块。如果失败,堆被迫从后端(保留和提交虚拟内存)分配一个大块来满足请求。通用的实现有每块分配的开销,这将耗费执行周期,也减少了可使用的存储空间。
Knowledge Base 文章 Q10758,“用 calloc() 和 malloc() 管理内存” (搜索文章编号), 包含了有关这些主题的更多背景知识。另外,有关堆实现和设计的详细讨论也可在下列著作中找到:“Dynamic Storage Allocation: A Survey and Critical Review”,作者 Paul R. Wilson、Mark S. Johnstone、Michael Neely 和 David Boles;“International Workshop on Memory Management”, 作者 Kinross, Scotland, UK, 1995 年 9 月(http://www.cs.utexas.edu/users/oops/papers.html)(英文)。
Windows NT 的实现(Windows NT 版本 4.0 和更新版本) 使用了 127 个大小从 8 到 1,024 字节的 8 字节对齐块空闲列表和一个“大块”列表。“大块”列表(空闲列表[0]) 保存大于 1,024 字节的块。空闲列表容纳了用双向链表链接在一起的对象。默认情况下,“进程堆”执行收集操作。(收集是将相邻空闲块合并成一个大块的操作。)收集耗费了额外的周期,但减少了堆块的内部碎片。
单一全局锁保护堆,防止多线程式的使用。(请参见“Server Performance and Scalability Killers”中的第一个注意事项, George Reilly 所著,在 “MSDN Online Web Workshop”上(站点:http://msdn.microsoft.com/workshop/server/iis/tencom.asp(英文)。)单一全局锁本质上是用来保护堆数据结构,防止跨多线程的随机存取。若堆操作太频繁,单一全局锁会对性能有不利的影响。
4、什么是常见的堆性能问题?
以下是您使用堆时会遇到的最常见问题:
分配操作造成的速度减慢。光分配就耗费很长时间。最可能导致运行速度减慢原因是空闲列表没有块,所以运行时分配程序代码会耗费周期寻找较大的空闲块,或从后端分配程序分配新块。
释放操作造成的速度减慢。释放操作耗费较多周期,主要是启用了收集操作。收集期间,每个释放操作“查找”它的相邻块,取出它们并构造成较大块,然后再把此较大块插入空闲列表。在查找期间,内存可能会随机碰到,从而导致高速缓存不能命中,性能降低。
堆竞争造成的速度减慢。当两个或多个线程同时访问数据,而且一个线程继续进行之前必须等待另一个线程完成时就发生竞争。竞争总是导致麻烦;这也是目前多处理器系统遇到的最大问题。当大量使用内存块的应用程序或 DLL 以多线程方式运行(或运行于多处理器系统上)时将导致速度减慢。单一锁定的使用—常用的解决方案—意味着使用堆的所有操作是序列化的。当等待锁定时序列化会引起线程切换上下文。可以想象交叉路口闪烁的红灯处走走停停导致的速度减慢。
竞争通常会导致线程和进程的上下文切换。上下文切换的开销是很大的,但开销更大的是数据从处理器高速缓存中丢失,以及后来线程复活时的数据重建。
堆破坏造成的速度减慢。造成堆破坏的原因是应用程序对堆块的不正确使用。通常情形包括释放已释放的堆块或使用已释放的堆块,以及块的越界重写等明显问题。(破坏不在本文讨论范围之内。有关内存重写和泄漏等其他细节,请参见 Microsoft Visual C++(R) 调试文档 。)
频繁的分配和重分配造成的速度减慢。这是使用脚本语言时非常普遍的现象。如字符串被反复分配,随重分配增长和释放。不要这样做,如果可能,尽量分配大字符串和使用缓冲区。另一种方法就是尽量少用连接操作。
竞争是在分配和释放操作中导致速度减慢的问题。理想情况下,希望使用没有竞争和快速分配/释放的堆。可惜,现在还没有这样的通用堆,也许将来会有。
在所有的服务器系统中(如 IIS、MSProxy、DatabaseStacks、网络服务器、 Exchange 和其他), 堆锁定实在是个大瓶颈。处理器数越多,竞争就越会恶化。
5、尽量减少堆的使用
现在您明白使用堆时存在的问题了,难道您不想拥有能解决这些问题的超级魔棒吗?我可希望有。但没有魔法能使堆运行加快—因此不要期望在产品出货之前的最后一星期能够大为改观。如果提前规划堆策略,情况将会大大好转。调整使用堆的方法,减少对堆的操作是提高性能的良方。
如何减少使用堆操作?通过利用数据结构内的位置可减少堆操作的次数。请考虑下列实例:
struct ObjectA { // objectA 的数据 } struct ObjectB { // objectB 的数据 } // 同时使用 objectA 和 objectB // // 使用指针 // struct ObjectB { struct ObjectA * pObjA; // objectB 的数据 } // // 使用嵌入 // struct ObjectB { struct ObjectA pObjA; // objectB 的数据 } // // 集合 – 在另一对象内使用 objectA 和 objectB // struct ObjectX { struct ObjectA objA; struct ObjectB objB; }
避免使用指针关联两个数据结构。如果使用指针关联两个数据结构,前面实例中的对象 A 和 B 将被分别分配和释放。这会增加额外开销—我们要避免这种做法。
把带指针的子对象嵌入父对象。当对象中有指针时,则意味着对象中有动态元素(百分之八十)和没有引用的新位置。嵌入增加了位置从而减少了进一步分配/释放的需求。这将提高应用程序的性能。
合并小对象形成大对象(聚合)。聚合减少分配和释放的块的数量。如果有几个开发者,各自开发设计的不同部分,则最终会有许多小对象需要合并。集成的挑战就是要找到正确的聚合边界。
内联缓冲区能够满足百分之八十的需要(aka 80-20 规则)。个别情况下,需要内存缓冲区来保存字符串/二进制数据,但事先不知道总字节数。估计并内联一个大小能满足百分之八十需要的缓冲区。对剩余的百分之二十,可以分配一个新的缓冲区和指向这个缓冲区的指针。这样,就减少分配和释放调用并增加数据的位置空间,从根本上提高代码的性能。
在块中分配对象(块化)。块化是以组的方式一次分配多个对象的方法。如果对列表的项连续跟踪,例如对一个 {名称,值} 对的列表,有两种选择:选择一是为每一个“名称-值”对分配一个节点;选择二是分配一个能容纳(如五个)“名称-值”对的结构。例如,一般情况下,如果存储四对,就可减少节点的数量,如果需要额外的空间数量,则使用附加的链表指针。
块化是友好的处理器高速缓存,特别是对于 L1-高速缓存,因为它提供了增加的位置 —不用说对于块分配,很多数据块会在同一个虚拟页中。
正确使用 _amblksiz。C 运行时 (CRT) 有它的自定义前端分配程序,该分配程序从后端(Win32 堆)分配大小为 _amblksiz 的块。将 _amblksiz 设置为较高的值能潜在地减少对后端的调用次数。这只对广泛使用 CRT 的程序适用。
使用上述技术将获得的好处会因对象类型、大小及工作量而有所不同。但总能在性能和可升缩性方面有所收获。另一方面,代码会有点特殊,但如果经过深思熟虑,代码还是很容易管理的。
6、其他提高性能的技术
下面是一些提高速度的技术:
使用 Windows NT5 堆
由于几个同事的努力和辛勤工作,1998 年初 Microsoft Windows(R) 2000 中有了几个重大改进:
改进了堆代码内的锁定。堆代码对每堆一个锁。全局锁保护堆数据结构,防止多线程式的使用。但不幸的是,在高通信量的情况下,堆仍受困于全局锁,导致高竞争和低性能。Windows 2000 中,锁内代码的临界区将竞争的可能性减到最小,从而提高了可伸缩性。
使用 “Lookaside”列表。堆数据结构对块的所有空闲项使用了大小在 8 到 1,024 字节(以 8-字节递增)的快速高速缓存。快速高速缓存最初保护在全局锁内。现在,使用 lookaside 列表来访问这些快速高速缓存空闲列表。这些列表不要求锁定,而是使用 64 位的互锁操作,因此提高了性能。
7、内部数据结构算法也得到改进。
这些改进避免了对分配高速缓存的需求,但不排除其他的优化。使用 Windows NT5 堆评估您的代码;它对小于 1,024 字节 (1 KB) 的块(来自前端分配程序的块)是最佳的。GlobalAlloc() 和 LocalAlloc() 建立在同一堆上,是存取每个进程堆的通用机制。如果希望获得高的局部性能,则使用 Heap(R) API 来存取每个进程堆,或为分配操作创建自己的堆。如果需要对大块操作,也可以直接使用 VirtualAlloc() / VirtualFree() 操作。
上述改进已在 Windows 2000 beta 2 和 Windows NT 4.0 SP4 中使用。改进后,堆锁的竞争率显著降低。这使所有 Win32 堆的直接用户受益。CRT 堆建立于 Win32 堆的顶部,但它使用自己的小块堆,因而不能从 Windows NT 改进中受益。(Visual C++ 版本 6.0 也有改进的堆分配程序。)
使用分配高速缓存
分配高速缓存允许高速缓存分配的块,以便将来重用。这能够减少对进程堆(或全局堆)的分配/释放调用的次数,也允许最大限度的重用曾经分配的块。另外,分配高速缓存允许收集统计信息,以便较好地理解对象在较高层次上的使用。
典型地,自定义堆分配程序在进程堆的顶部实现。自定义堆分配程序与系统堆的行为很相似。主要的差别是它在进程堆的顶部为分配的对象提供高速缓存。高速缓存设计成一套固定大小(如 32 字节、64 字节、128 字节等)。这一个很好的策略,但这种自定义堆分配程序丢失与分配和释放的对象相关的“语义信息”。
与自定义堆分配程序相反,“分配高速缓存”作为每类分配高速缓存来实现。除能够提供自定义堆分配程序的所有好处之外,它们还能够保留大量语义信息。每个分配高速缓存处理程序与一个目标二进制对象关联。它能够使用一套参数进行初始化,这些参数表示并发级别、对象大小和保持在空闲列表中的元素的数量等。分配高速缓存处理程序对象维持自己的私有空闲实体池(不超过指定的阀值)并使用私有保护锁。合在一起,分配高速缓存和私有锁减少了与主系统堆的通信量,因而提供了增加的并发、最大限度的重用和较高的可伸缩性。
需要使用清理程序来定期检查所有分配高速缓存处理程序的活动情况并回收未用的资源。如果发现没有活动,将释放分配对象的池,从而提高性能。
可以审核每个分配/释放活动。第一级信息包括对象、分配和释放调用的总数。通过查看它们的统计信息可以得出各个对象之间的语义关系。利用以上介绍的许多技术之一,这种关系可以用来减少内存分配。
分配高速缓存也起到了调试助手的作用,帮助您跟踪没有完全清除的对象数量。通过查看动态堆栈返回踪迹和除没有清除的对象之外的签名,甚至能够找到确切的失败的调用者。
MP 堆
MP 堆是对多处理器友好的分布式分配的程序包,在 Win32 SDK(Windows NT 4.0 和更新版本)中可以得到。最初由 JVert 实现,此处堆抽象建立在 Win32 堆程序包的顶部。MP 堆创建多个 Win32 堆,并试图将分配调用分布到不同堆,以减少在所有单一锁上的竞争。
本程序包是好的步骤 —一种改进的 MP-友好的自定义堆分配程序。但是,它不提供语义信息和缺乏统计功能。通常将 MP 堆作为 SDK 库来使用。如果使用这个 SDK 创建可重用组件,您将大大受益。但是,如果在每个 DLL 中建立这个 SDK 库,将增加工作设置。
重新思考算法和数据结构
要在多处理器机器上伸缩,则算法、实现、数据结构和硬件必须动态伸缩。请看最经常分配和释放的数据结构。试问,“我能用不同的数据结构完成此工作吗?”例如,如果在应用程序初始化时加载了只读项的列表,这个列表不必是线性链接的列表。如果是动态分配的数组就非常好。动态分配的数组将减少内存中的堆块和碎片,从而增强性能。
减少需要的小对象的数量减少堆分配程序的负载。例如,我们在服务器的关键处理路径上使用五个不同的对象,每个对象单独分配和释放。一起高速缓存这些对象,把堆调用从五个减少到一个,显著减少了堆的负载,特别当每秒钟处理 1,000 个以上的请求时。
如果大量使用“Automation”结构,请考虑从主线代码中删除“Automation BSTR”,或至少避免重复的 BSTR 操作。(BSTR 连接导致过多的重分配和分配/释放操作。)
摘要
对所有平台往往都存在堆实现,因此有巨大的开销。每个单独代码都有特定的要求,但设计能采用本文讨论的基本理论来减少堆之间的相互作用。
评价您的代码中堆的使用。
改进您的代码,以使用较少的堆调用:分析关键路径和固定数据结构。
在实现自定义的包装程序之前使用量化堆调用成本的方法。
如果对性能不满意,请要求 OS 组改进堆。更多这类请求意味着对改进堆的更多关注。
要求 C 运行时组针对 OS 所提供的堆制作小巧的分配包装程序。随着 OS 堆的改进,C 运行时堆调用的成本将减小。
操作系统(Windows NT 家族)正在不断改进堆。请随时关注和利用这些改进。
Murali Krishnan 是 Internet Information Server (IIS) 组的首席软件设计工程师。从 1.0 版本开始他就设计 IIS,并成功发行了 1.0 版本到 4.0 版本。Murali 组织并领导 IIS 性能组三年 (1995-1998), 从一开始就影响 IIS 性能。他拥有威斯康星州 Madison 大学的 M.S.和印度 Anna 大学的 B.S.。工作之外,他喜欢阅读、打排球和家庭烹饪。
http://community.csdn.net/Expert/FAQ/FAQ_Index.asp?id=172835
我在学习对象的生存方式的时候见到一种是在堆栈(stack)之中,如下
CObject object;
还有一种是在堆(heap)中 如下
CObject* pobject=new CObject();
请问
(1)这两种方式有什么区别?
(2)堆栈与堆有什么区别??
---------------------------------------------------------------
1) about stack, system will allocate memory to the instance of object automatically, and to the
heap, you must allocate memory to the instance of object with new or malloc manually.
2) when function ends, system will automatically free the memory area of stack, but to the
heap, you must free the memory area manually with free or delete, else it will result in memory
leak.
3)栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
4)堆上分配的内存可以有我们自己决定,使用非常灵活。
---------------------------------------------------------------
十二、>>Java中几种常量池的区分<<
十三、>>Java中IO流,输入输出流概述与总结<<
待定序号、拓展的程序设计
1、约瑟夫问题[Josephus 问题]
问题详情:
据说著名犹太历史学家 Josephus有过以下的故事:在罗马人占领乔塔帕特后,39 个犹太人与Josephus及他的朋友躲到一个洞中,39个犹太人决定宁愿死也不要被敌人抓到,于是决定了一个自杀方式,41个人排成一个圆圈,由第1个人开始报数,每报数到第3人该人就必须自杀,然后再由下一个重新报数,直到所有人都自杀身亡为止。然而Josephus 和他的朋友并不想遵从。
首先看一下约瑟夫是怎么解决的
首先从一个人开始,越过k-2个人(因为第一个人已经被越过),并杀掉第k个人。接着,再越过k-1个人,并杀掉第k个人。这个过程沿着圆圈一直进行,直到最终只剩下一个人留下,这个人就可以继续活着。问题是,给定了和,一开始要站在什么地方才能避免被处决?Josephus要他的朋友先假装遵从,他将朋友与自己安排在第16个与第31个位置,于是逃过了这场死亡游戏。
2、把图中的数组转置
3、一元多项式的相加
提示:
第一种方法:一元多项式的表示问:对于任意一元多项式:
Pn(x)=P0+P1X1+P2X2+P3X3+P4X4+............PnXn
可以抽象为一个由“系数-指数”对构成的线性表,且线性表中各元素的指数项递增:即
P=((P0,0),(P1,1),(P2,2),(P3,3),(P4,4).........(Pn,n))
第二种方法:用一个单链表表示上述线性表,结点结构为:
typedef struct node{ float coef;/*系数域*/ int exp;/*指数域*/ struct node *next;/*指针域*/ }PloyNode;
结点图示