环境:
OS:Window10
python:3.7
描述
打开下面的网址,之后抓取其中的图片
https://music.163.com/#/artist/album?id=101988&limit=120&offset=0
安装一些库文件
首先看你的网页版本,查看方法,打开【https://sites.google.com/a/chromium.org/chromedriver/downloads】之后显示如下图1,说明你的版本是2.45,
下载对应的版本的驱动下载地址【https://chromedriver.storage.googleapis.com/index.html】如下图2

(图1)

(图2)
上面的包文件下载到本地之后,把bin里面的EXE文件放到你本地安装的Python的【Scripts】文件夹路径下
自己的本地路径【C:UsersXXXXXXXAppDataLocalProgramsPythonPython37Scripts】
整体代码如下
1 import time 2 3 import requests 4 import os 5 6 from bs4 import BeautifulSoup 7 from selenium import webdriver 8 9 10 class GetMuisc: 11 12 def __init__(self): 13 self.init_url = 'http://music.163.com/#/artist/album?id=101988&limit=120&offset=0' 14 self.folder_path = r"C:pythonProjectwangyi" 15 16 def request(self, url): 17 r = requests.get(url) 18 return r 19 20 def mkdir(self, path): 21 path = path.strip() 22 isExists = os.path.exists(path) 23 24 if not isExists: 25 print('创建名字叫做', path, '的文件夹') 26 os.makedirs(path) 27 print('创建成功!') 28 return True 29 else: 30 print(path, '文件夹已经存在了,不再创建') 31 return False 32 33 def save_img(self, url, file_name): 34 print("开始请求图片地址...") 35 img = self.request(url) 36 print('开始保存图片') 37 with(open(file_name, "ab")) as ff: 38 ff.write(img.content) 39 print(file_name, '图片保存成功!') 40 41 # f = open(file_name, "ab") 42 # f.write(img.content) 43 # f.close() 44 45 def get_files(self, path): 46 pic_name = os.listdir(path) 47 return pic_name 48 49 def spider(self): 50 print("Start!") 51 driver = webdriver.Chrome() 52 driver.get(self.init_url) 53 driver.switch_to.frame("g_iframe") 54 iframe_html = driver.page_source 55 driver.close() 56 57 self.mkdir(self.folder_path) 58 file_name = self.get_files(self.folder_path) 59 os.chdir(self.folder_path) 60 61 idstr = 'm-song-module' 62 moduleHtml = BeautifulSoup(iframe_html, 'lxml').find(id=idstr) 63 if moduleHtml is None: 64 print("标签{}没有找到,请检查是否有问题。".format(idstr)) 65 else: 66 all_li = moduleHtml.find_all('li') 67 for li in all_li: 68 album_img = li.find("img")["src"] 69 album_name = li.find("p", class_="dec")["title"] 70 album_date = li.find("span", class_="s-fc3").get_text() 71 end_pos = album_img.index("?") 72 album_img_url = album_img[:end_pos] 73 74 photo_name = album_date + " - " + album_name.replace("/", "").replace(":", ",") + ".jpg" 75 print(album_img_url, photo_name) 76 77 if photo_name in file_name: 78 print('图片已经存在,不再重新下载') 79 else: 80 self.save_img(album_img_url, photo_name) 81 82 83 album_cover = GetMuisc() 84 album_cover.spider()
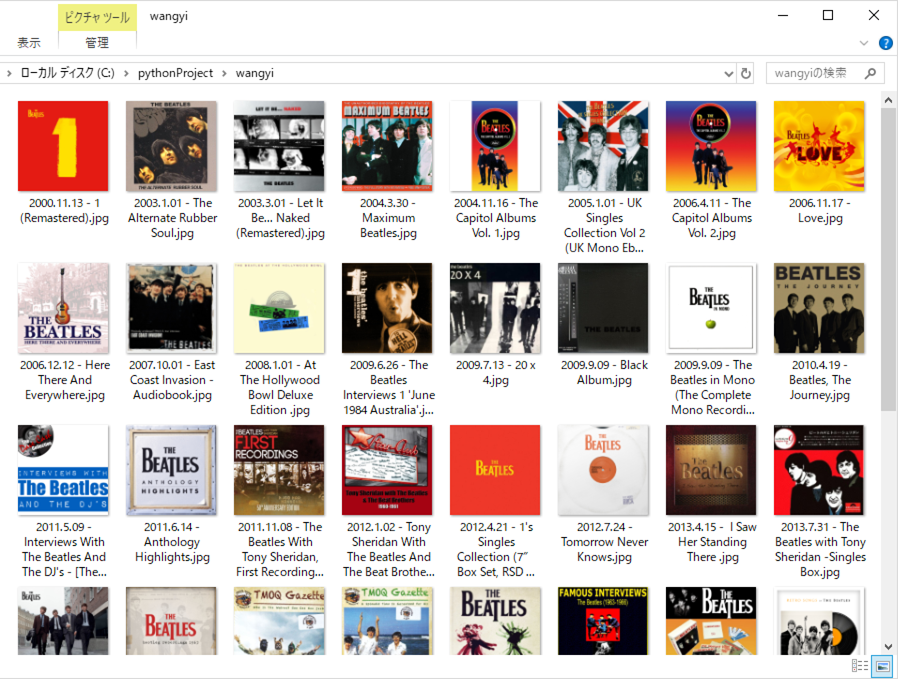
运行效果