https://www.analyticsvidhya.com/blog/2015/07/difference-machine-learning-statistical-modeling/
http://normaldeviate.wordpress.com/2012/06/12/statistics-versus-machine-learning-5-2/
https://www.quora.com/What-is-the-difference-between-statistics-and-machine-learning
machine learning is an algorithm that can learn from data without relying on rules-based programming.
Statistical modelling is formalization of relationships between variables in the form of mathematical equations.
共同的目标:
learn from data,但是statistical learning的目标更多的是从手头上的数据学习后实现统计推断:得出结论
不同点从以下几个方面来阐述:
schools they come from:
machine learning是计算机科学和人工智能的一个子领域,用于构建可以从数据中学习到model,而不需要显示地编程学习rule
statistical model:是数学的一个分支,用于发现多个变量之间的关系,从而可以预测输出
diffrent eras(不同时代的产物)
statistical modelling已经存在几世纪的时间了,而machine learning实际上从1990年代才变得清晰,随着计算资源便宜化和能力巨大提高而开始成为现实
假设依赖:
统计模型往往有一些预设的假设,比如一个简单的线性回归模型会有以下假设:
1. 自变量和因变量之间是线性关系;
2. 随机变量是同方差同分布
3. 因变量的误差均值为0
4. 观测值之间是互相独立的;
5.每个因变量的值是正态分布
同样地,逻辑回归也会有其一堆预设的假设,只有当假设得到满足时,模型的效果才会比较好。而机器学习算法虽然也有部分假设,但是大大少于统计模型的假设。机器学习我们也无需指出自变量或者因变量所服从的分布
处理的数据类型:
机器学习可以处理的数据具有wide(变量的维数),deep(样本的数量巨大),而statistical model则仅适用于低维度,少样本数据集的情况,否则及其容易产生过拟合。
命名范式:
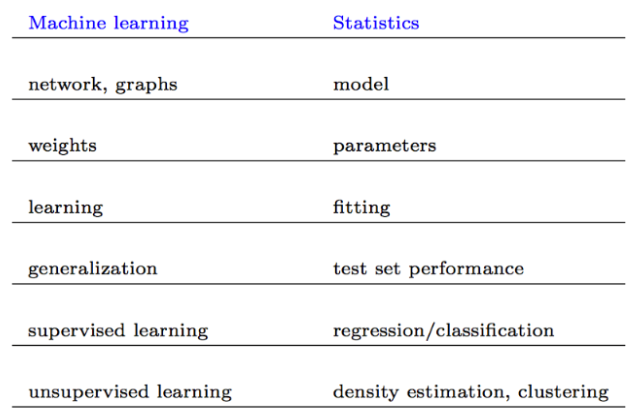
formulation:
虽然统计学模型和机器学习模型的目标是类似的,但是其最终学习的模型公式却有明显的区别:
对于统计模型,我们往往需要估计出特定样式的函数f:
Dependent Variable ( Y ) = f(Independent Variable) + error function
而,对于机器学习,则直接剔除上述f,而直接从输入到输出(可能是线性,也可能是非线性的函数)
Output(Y) ----- > Input (X)
预测能力:
"自然之力不会在发生一件事情之前做出任何假设。。"
因此,在一个预测model中,越少的假设条件,预测的能力会越强。机器学习正如名字所蕴含的意义其需要更少的人为参与。机器学习通过不断地迭代使得计算机自己发现隐藏在数据中的pattern.由于机器综合了所有的样本数据并且没有任何(或仅有少量)的预定假设,因此预测能力会大大强于统计模型。统计模型更多的是数学密集并且基于系数估计,它要求建模人员本身已经理解了变量之间本身存在的关系,只有这样建设的模型才会有用。
统计学家和机器学习工程师对模型输出的不同描述:
- ML professional: “The model is 85% accurate in predicting Y, given a, b and c.”
- Statistician: “The model is 85% accurate in predicting Y, given a, b and c; and I am 90% certain that you will obtain the same result.”