转: https://www.cnblogs.com/wangmingtao/p/9372611.html
22、上下文与出入栈
22.1 请求过程
请求过来,flask会实例化一个Request Context,就是请求上下文(这个请求上下文封装了请求的相关信息)生成请求上下文之后,将请求上下文推入栈中(栈:后进先出;队列:先进先出,flask中用LocalStack来表示栈,LocalStack是一个类,需要实例化,成_request_ctx_stack和_app_ctx_stack)
请求过来,通过push入栈
22.2 入栈顺序
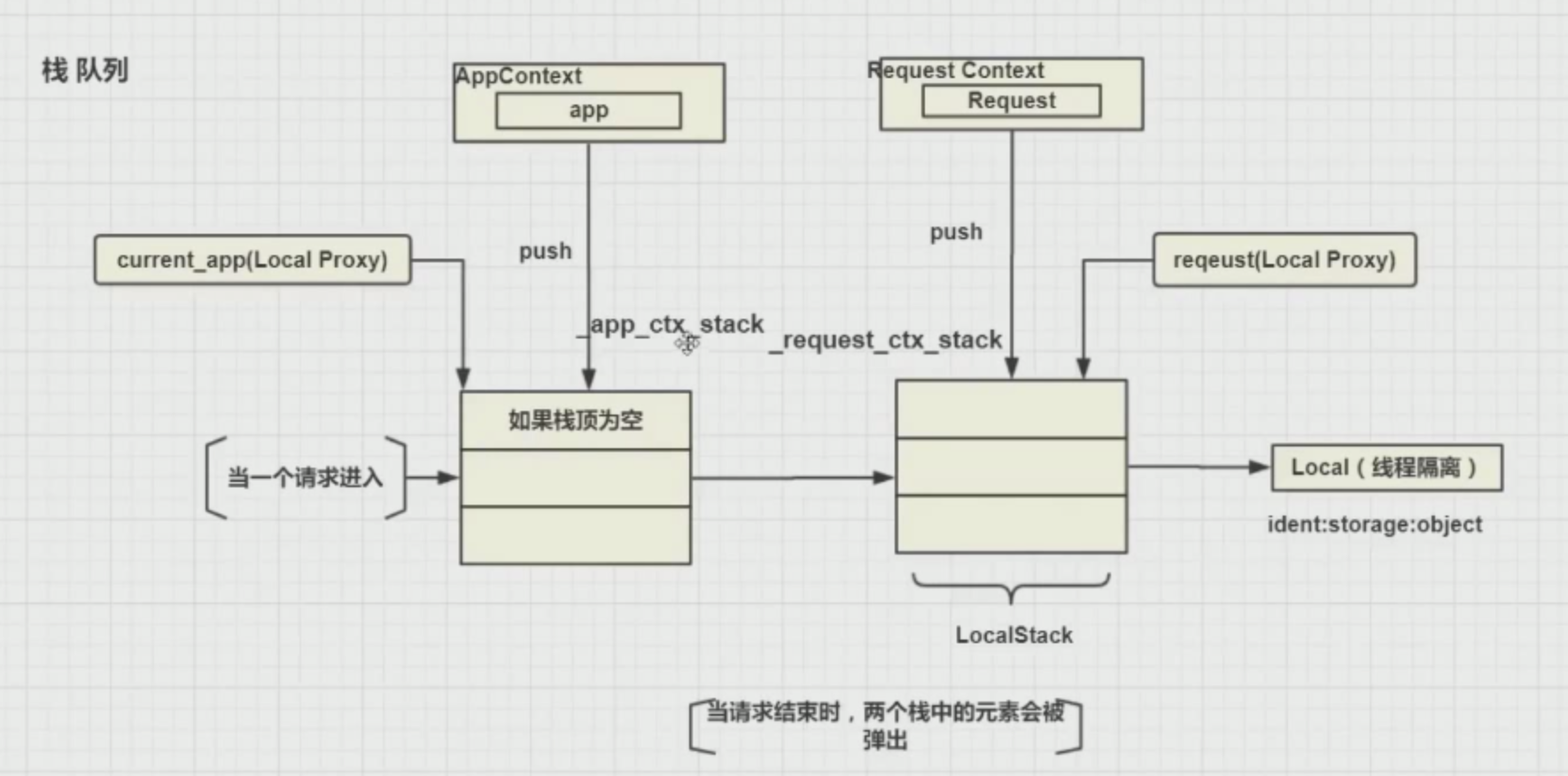
request入栈的时候,会先检查app的栈,如果栈顶为空,会先将AppContext推入栈中,然后才会推入RequestContext,所以test.py中需要手动推入栈,而request请求不需要手动推,直接用就可以
current_app和request都是栈顶元素,在操作这俩对象时,其实就是操作栈顶元素,这俩栈顶元素都是上下文,如果直接引入到外文件,元素是空的
离线应用、单元测试



# -*- coding=utf-8 -*- from flask import Flask, current_app app = Flask(__name__) ctx = app.app_context() ctx.push() a = current_app d = current_app.config['DEBUG'] ctx.pop()
23、flask上下文与with语句
# -*- coding=utf-8 -*- from flask import Flask, current_app app = Flask(__name__) class MyResource: def __enter__(self): print('connect to resoure') return self def __exit__(self, exc_type, exc_val, exc_tb): print('close resource connection') def query(self): print('query data') with MyResource as resource: resource.query()
23.1 实现了上下文协议的对象使用with
23.2 对于实现了上下文协议的对象,通常称为上下文管理器
23.3 一个上下文管理器如何实现上下文协议?只要一个对象实现了__enter__和__exit__就可以
23.4 一个上下文表达式必须返回一个上下文管理器
23.5 with语句,对资源的管理
24、阅读源码
control+alt+左键/右键,返回或者进入函数内部
# -*- coding=utf-8 -*- from flask import Flask from app.models.book import db from app.web.book import web def create_app(): app = Flask(__name__) app.config.from_object('app.secure') app.config.from_object('app.setting') register_blueprint(app) db.init_app(app) with app.app_context(): db.create_all() # db.create_all(app=app) return app def register_blueprint(app): app.register_blueprint(web) db create_all
25、进程(竞争计算机资源的基本单位)
25.1 操作系统用来调度、分配资源的单位,每个应用程序至少有一个进程
25.2 单核CPU 永远只能够执行一个应用程序?no,CPU可以在不同的应用程序进程之间切换
25.3 进程/线程,切换时开销是非常大的,因为上下文是需要保存和加载消耗大
26、线程(是进程的一部分,可以只有一个进程 多个进程)
26.1 线程之间切换所消耗的资源更小
线程非常轻量,本身不负责管理资源也不用有资源,所以线程是去使用进程的相关资源的,所以让线程切换起来更加快速
26.2 进程 分配资源
26.3 线程 利用CPU执行代码
eg:代码 指令 CPU来执行 资源,线程没有资源,有指令
26.4 线程 自己不拥有资源,但是可以访问进程的资源
27、多线程
27.1 主线程启用新的线程
# -*- coding=utf-8 -*- import threading def worker(): print('i am thread') t = threading.current_thread() print(t.getName()) t = threading.current_thread() print(t.getName()) new_t = threading.Thread(target=worker, name='qiyue_thread') new_t.start()
27.2 新的线程和主线程没有区别了,不会等线程执行完再执行下一个线程
# -*- coding=utf-8 -*- import time import threading def worker(): print('i am thread') t = threading.current_thread() time.sleep(100) print(t.getName()) new_t = threading.Thread(target=worker, name='qiyue_thread') new_t.start() t = threading.current_thread() print(t.getName())
中间部分改为worker(),则会等worker执行结束再执行下面的,不是通过线程的方式调用,而是直接在主线程中调用的
27.3 多线程编程好处
(1)更加充分地利用CPU的性能优势,从而加快代码的执行速度
(2)异步编程
(3)单核CPU,同一时间只允许一个线程来使用CPU执行代码
(4)多核CPU,完全有能力让不同的核去处理不同的线程,并行执行程序
(5)python不能充分利用多核CPU的优势
28、全局解释器锁GIL(global interpreter lock)
28.1 因为有GIL的存在,让python代码不管CPU有多少个核,开了多少个线程,同一时间只能在同一个核上面执行一个线程
28.2 锁:线程安全
多个线程共享一个进程的资源,可能多个线程同时访问一个资源,造成 线程不安全一般,为了保证线程安全,采用锁的机制。一旦对某个资源进行了加锁操作,只有拿到锁的线程才能对资源进行操作,执行完被释放之后才能被别的线程使用
28.3 锁
(1)细粒度锁 程序员 主动加锁
(2)粗粒度锁 解释器 GIL
(3)虽然多核CPU可以跑多个线程,但是python是需要解释器来解释的,由于GIL的存在,在python解释器上面,同一时刻只允许一个线程来执行
(4)总结:CPU硬件是没有限制的,但是由于解释器,GIL只允许一个线程同时执行,一定程度上保证线程安全。可以采用多进程,可是多进程之间是不能互相访问的,如果想在进程之间共享资源,需要用到进程通信技术,相当麻烦,切换成本高
28.4 对于IO密集型程序,多线程有意义
(1)CPU密集型程序:非常严重的依赖CPU计算(圆周率计算、视频解码)
(2)IO密集型程序:查询数据库、请求网络资源、读写文件
按照时间段消耗在那种操作上面来划分的
(3)IO密集型主要花费在等待上面,不如让别的线程来使用CPU
29、开启flask多线程
29.1 通过webserver开启多线程
app.run(host='0.0.0.0', debug=app.config['DEBUG'], port=5000, threaded=True)
单进程多线程
29.2 对象是保存状态的地方。实例化三个不同的request对象分别用来保存三个请求的状态
29.3 字典,用不同线程id号来线程隔离
多线程,每个线程都有唯一标识,唯一标识为key,每个线程所实例化的Request对象作为value值
一个request对象,一个request对象指向了一个字典的数据结构,字典包含了不同线程所创建的不同的Request实例化对象
29.4 线程隔离对象
(1)flask内部引用了werkzeug库,库内部有local模块,local模块有Local对象,线程隔离由Local对象完成,通过字典的方式
(2)Local
# -*- coding=utf-8 -*- import time import threading from werkzeug.local import Local my_obj = Local() my_obj.b = 1 def worker(): my_obj.b = 2 print('in new thread b is:' + str(my_obj.b)) new_t = threading.Thread(target=worker, name='qiyue_thread') new_t.start() time.sleep(1) # 主线程 print('in main thread b is:' + str(my_obj.b))
29.5 线程隔离的栈
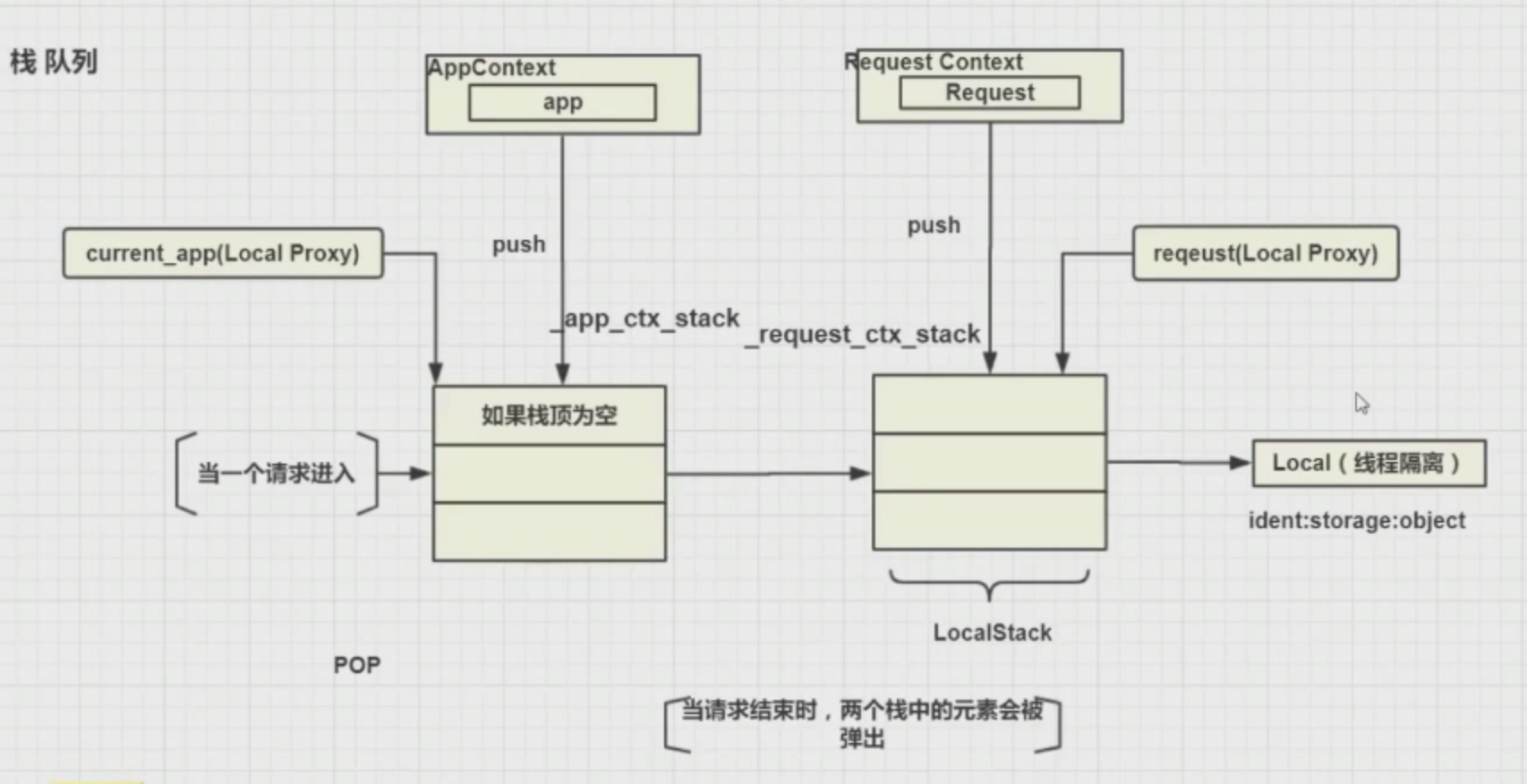
(1)两个上下文,一个请求上下文,一个应用上下文,会在请求进来的时候被推进到栈中,_app_ctx_stack和_request_ctx_stack这两个变量名所指向的对象都是LocalStack()这样的类型,就是可以用来做线程隔离的栈
(2)LocalStack Local 字典
Local使用字典的方式实现的线程隔离
LocalStack封装了线程对象,把Local对象作为它自己的一个属性,从而实现的一个线程隔离的栈结构
(3)LocalStack基本用法
# -*- coding=utf-8 -*- from werkzeug.local import LocalStack s = LocalStack() s.push(1) # 将一个元素推入到栈顶 print(s.top) # 将栈顶的元素取出来,只是取,不会删除 print(s.top) # top上方加了@property,作为属性,不需要括号 print(s.pop()) # pop是方法 print(s.top) s.push(1) s.push(2) print(s.top) print(s.top) print(s.pop()) print(s.top)