渲染管线
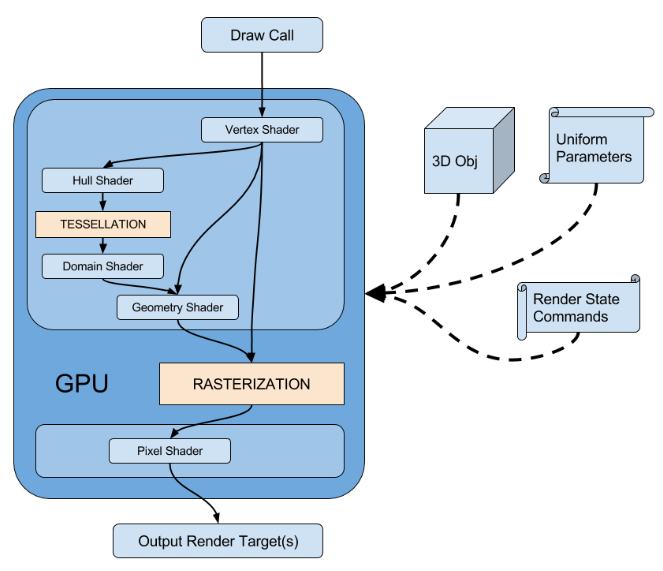
图形渲染管线(Graphics Pipeline):将三维模型渲染到二维屏幕上的过程。为了满足实时性,管线在GPU硬件上进行实现,其与CPU流水线一样,各个步骤都会以并行的形式运行。
固定管线(Fixed-Function Pipeline):通常是指在较旧的GPU上实现的渲染流水线,通过DX、OpenGL等图形接口函数,开发者来对渲染流水线进行配置,控制权十分有限。
可编程管线(Programmable Pipeline):随着人们对画面品质和GPU硬件能力的提升,在原有固定管线流程中插入了Vertex Shader、Geometry Shader(非必需)、Fragment(Pixel) Shader等可编程的阶段,让开发者对管线拥有更大控制权
例如:Vertex Shader修改顶点属性(如顶点空间变换、逐顶点关照、uv变换)以及通过自定义属性向管线传入一些数据,Geometry Shader可增删和修改图元,Fragment(Pixel) Shader来进行逐像素的渲染
管线资源
材质(Material):用于描述光与物体的交互方式的程序(即shader)、贴图以及其他属性的集合。
在执行光照计算时,需要用到一些材质属性才能得到表面的最终颜色。
常见的几种属性有Diffuse(漫反射)、Emissive(自发光)、Specular(高光)、Normal(法线)等。
着色器(Shader):是执行在GPU上可编程图形管线的算法片段,用于告诉图形硬件如何绘制物体。包括:Vertex Shader、Fragment(Pixel) Shader、Geometry Shader。
Shader在早期是用汇编来编写的,后面出现更高级的着色语言,如DirectX的HLSL(High Level Shading Language)、OpenGL的GLSL(OpenGL Shading Language)以及nVidia的Cg(C for Graphic)。
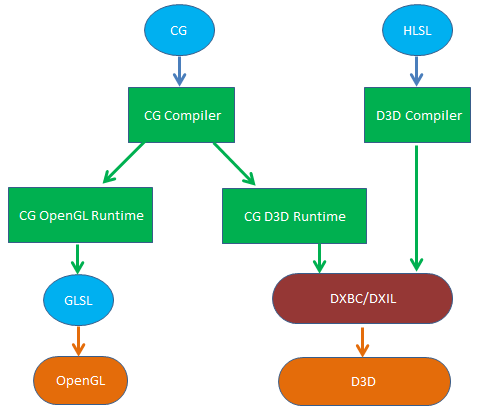
GLSL具有跨平台性,其在被OpenGL使用前不需要进行额外编译,而是由显卡驱动直接编译成GPU使用的机器指令。
HLSL仅能在windows平台上使用,需预先编译成与硬件无关的DX中间字节码(DXBC/DXIL)才能被D3D使用。
CG语法上与HLSL高度相似,具有真正意义上的跨平台:在不同的平台上实现了shader编译器,并通过CG OpenGL Runtime和CG D3D Runtime来将CG转换成GLSL和DX中间字节码。
纹理(Texture):可以理解为运行时的贴图,可以通过UV坐标映射到模型的表面。另外,其拥有一些渲染相关的属性,如:纹理地址模式(ADDRESSU、ADDRESSV),纹理过滤方法(MAGFILTER、MINFILTER、MIPFILTER)等
图形API概念
DrawCall:为CPU向GPU发起的一个命令(如:OpenGL中的glDrawElements函数、D3D9中的DrawIndexPrimitive函数、D3D11中的Draw、DrawIndexed函数)。
这个命令仅仅会指向一个需要被渲染的图元(primitives)列表(IBO,Index Buffer Object)。发起DrawCall时,GPU就会根据渲染状态和输入的顶点数据(VBO,Vertex Buffer Object)来计算,最终输出成屏幕上显示的像素。
渲染状态(RenderState):这些状态定义了场景中Mesh是怎样被渲染的。如:使用哪个vs、哪个fs、光源属性、材质、纹理等
颜色缓冲区(Color Buffer):即帧缓冲区(Frame Buffer,Back Buffer),用于存放渲染出来的图像。D3D存放在一个RTV(RenderTargetView)中。
深度缓冲区(Depth Buffer):用于存放深度的图像。D3D存放在一个DSV(DepthStencilView)中。
模板缓冲区(Stencil Buffer):用于获得某种特定效果的离屏缓存。分辨率与颜色缓冲区及深度缓冲区一致,因此模板缓冲区中的像素与颜色缓冲区及深度缓冲区是一一对应的。
其功能与模版类似,允许动态地、有针对性地决定是否将某个像素写入后台缓存中
D3D中,与深度缓冲区一起存放在一个DSV(DepthStencilView)中。
表面(Surface):D3D在显存中用于存储2D图像数据的一个像素矩阵。D3D9中对应的COM接口为IDirect3DSurface9。
Render Target(RT,渲染目标):对应显卡中一个内存块, D3D中概念(OpenGL中叫做FBO,Framebuffer object),常用于是离屏渲染。
渲染管线默认使用后备缓冲区(BackBuffer)RT来存放渲染结果,可通过调用CreateRenderTarget或RTT来创建多个额外的RT来进行离屏渲染,最后将它们组装到后备缓冲区(BackBuffer)中以产生最终的渲染画面。
注1:调用Device->CreateRenderTarget创建RT成功后,会返回IDirect3DSurface9* pRTSurface;然后调用Device->SetRenderTarget(0, pRTSurface)绑定pRTSurface到指定的RT索引。
在执行SetRenderTarget前可调用Device->GetRenderTarget(0, pOriginRTSurface),以便在完成RT绘制后还原回pOriginRTSurface所指向RT的Surface
对于不支持MRT的显卡,只会有一个索引为0的RT;对于支持MRT(N个)的显卡,索引可以为0,1, ...N-1,可同时绑定N个Surface到N个RT的索引上
注2:成功绑定RT后:对于不支持MRT的显卡,在Pixel Shader中通过标识COLOR0来写入内容到索引为0的RT中;对于支持MRT(N个)的显卡,在Pixel Shader中通过标识COLOR0, COLOR1, ...COLOR(N-1)来写入内容到对应的RT中
注3:可以调用Device->StretchRect来将RT的Surface拷贝到后备缓冲区(BackBuffer)或者另外一个Surface中
注4:可以调用Device->GetBackBuffer(0,0,D3DBACKBUFFER_TYPE_MONO,&pRTBackBuffer))来得到后备缓冲区(BackBuffer)的Surface
进一步可参考:Render to Surface
RTT(Render To Texture,渲染到纹理):用法与上面的RT一致,只是先调用Device->CreateTexture来创建出IDirect3DTexture9* pTexture,然后再通过pTexture->GetSurfaceLevel(0, IDirect3DSurface9**)来创建RT返回IDirect3DSurface9* pRTSurface
注:与上面RT相比,RTT不支持MultiSample 进一步可参考:渲染到纹理(Render To Texture, RTT)详解
MRT(Multiple Render Targets,多渲染目标):在一个pass中将渲染信息保存到多个render target,并可在后续的管线流程中被其他shader使用或作为3D模型的纹理使用。
MRT需要显卡硬件和图形API(从OpenGL2.0和D3D9起)支持(对于不支持MRT的硬件可以使用多次渲染解决),提供了单个pass同时操作多个render target的能力,
MRT技术提高了渲染过程存储中间数据(如:Normal、Diffuse、Depth、Specular和Shininess等)的容量和渲染效率,是一种典型空间换时间的例子。注:Shininess值决定Specular光圈的大小
然而使用多个render target来渲染也并不是百利无一害,多个render target的读写IO开销也会不小,因此要紧凑地使用render target各bit来存储信息,能用一张就不要用两张,要尽量省以提升渲染效率。
(1) D3D9使用DirectX Caps Viewer查看显卡支持MRT个数
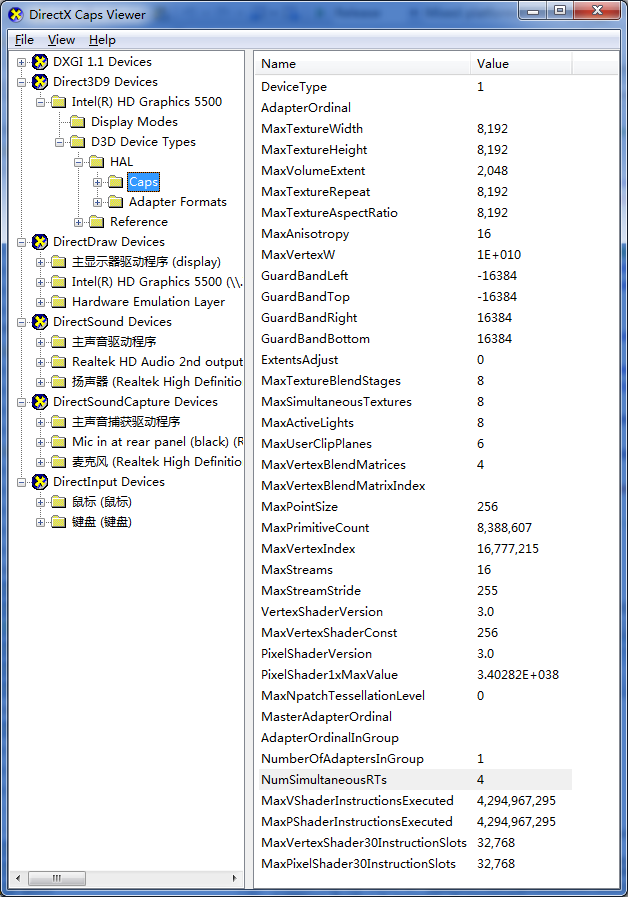
(2)D3D9可使用下列方法查询显卡支持MRT个数
D3DCAPS9 DeviceCaps; UINT AdapterIndex = D3DADAPTER_DEFAULT; D3DDEVTYPE DeviceType = D3DDEVTYPE_HAL; if(SUCCEEDED(Direct3D->GetDeviceCaps(AdapterIndex,DeviceType,&DeviceCaps))) { UINT32 MRTCount = DeviceCaps.NumSimultaneousRTs; // 支持MRT的个数 }
(3)D3D10最大支持MRT个数为D3D10_SIMULTANEOUS_RENDER_TARGET_COUNT // 8
D3D11最大支持MRT个数为D3D11_SIMULTANEOUS_RENDER_TARGET_COUNT // 8
实际支持多少个MRT由硬件显卡决定。mobile平台上,MRT最多只有4个,每个的bit数最多为32。
MRT的限制:
① 设定的RT需要具有相同的宽高
② 设定的RT一般需要有相同的位宽,比如同是16bits或32bits
G-Buffer(Geometry Buffer,几何缓冲区):延迟渲染管线中,在渲染场景物件时,用来存储几何和材质信息的RT图像(实际实现中常将各信息紧凑地挤进1个RT或MRT技术多个RT中),使得能在屏幕空间进行光照计算
渲染路径(Rendering Path)
前向渲染(Forward Rendering):逐光源逐物体进行光照计算
For each light:
For each object affected by the light:
framebuffer += object * light
对于多光源,使用Forward Rendering的效率会极其低下。 因为如果在vs中计算光照,其复杂度将是 O(num_geometry_vertexes∗num_lights)
而如果在fs中计算光照,其复杂度为 O(num_geometry_fragments∗num_lights) 。可见光源数目和复杂度是成线性增长的 。
延迟渲染(Deferred Shading):最早由Michael Deering在1988年的论文The triangle processor and normal vector shader: a VLSI system for high performance graphics提出,是一种基于屏幕空间着色的技术。
它的核心思想是将场景的物体绘制分离成两个Pass:几何Pass和光照Pass,目的是将计算量大的光照Pass延后,和物体数量和光照数量解耦,以提升着色效率。
计算光照的复杂度为 O(num_geometry_fragments + num_lights) 。在目前的主流渲染器和商业引擎中,有着广泛且充分的支持。
光照(lighting)
球谐光照(Spherical harmonic lighting):https://huailiang.github.io/blog/2019/harmonics/
基于图像的光照(Image Based Lighting,IBL):将要反射的“环境”渲染为一张图,然后渲染时通过查询这个贴图来计算来自周围的环境光照。https://huailiang.github.io/blog/2019/ibl/
局部光照:只考虑光源对物体的影响(直接关照),不考虑光线被不同的物体表面反射而产生的间接光照。
全局光照(GI,global illumination):模拟光线是如何在场景中传播的,不仅会考虑那些直接光照(direct illumination)的结果,还会计算光线被不同的物体表面反射而产生的间接光照(indirect illumination)。
在使用基于物理的着色技术时,当渲染表面上一点时,我们需要计算该点的半球范围内所有会反射到观察方向的入射光线的关照结果,这些入射光线中就包含了直接光照和间接光照。
离线渲染light map来实现静态场景、静态光源的GI。接着出现了PRT,可以处理静态场景、动态光源的GI。
环境光遮蔽(Ambient Occlusion,简称AO):是全局光照明的一种近似替代品,可以产生重要的视觉明暗效果,通过描绘物体之间由于遮挡而产生的阴影, 能够更好地捕捉到场景中的细节。
可以解决漏光,阴影漂浮等问题,改善场景中角落、锯齿、裂缝等细小物体阴影不清晰等问题,增强场景的深度和立体感。
SSAO(Screen Space Ambient Occlusion),屏幕空间AO,用于延迟管线。
GTAO(Ground Truth Ambient Occlusion),UE4.26在移动端集成了该AO,具体实现在:FMobileSceneRenderer::RenderAmbientOcclusion函数中。
逐顶点着色:在VS中进行着色计算
① Flat Shading(平直着色法):认为在同一多边形上任意点的法线都相同,因此多边形上所有像素为同一颜色值。该方法简单,常用于高速渲染。
② Gouraud Shading(Gouraud着色法):用多边形顶点颜色进行双线性插值得到内部各像素的颜色,会得到较为平滑的颜色渐变。
渲染一些与相机位置相关的光照效果(比如高光)时,得到的效果会有问题。如果在多边形的中心有高光,而且这个高光没有扩散到该多边形的任何顶点,高光将不会被渲染出来。
而如果正好是多边形的顶点上有高光,那么这个点上的高光是正确的,但插值会导致高光以很不自然的形式扩散到相邻的多边形上。
逐像素着色:在PS中进行着色计算
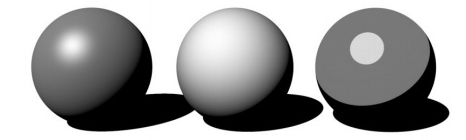
Phone Shading(Phone着色法):在光栅化阶段,用多边形顶点法线插值得到内部各像素的法线,然后进行像素颜色计算。这种方法计算量大,渲染效果最好。

Phong光照:经验模型,没有实际的物理意义。

Ambient(环境光)用来模拟全局光照效果,其实就是在物体光照基础上叠加一个较小的光照常量,用来表示场景中其他物体反射的间接光照。
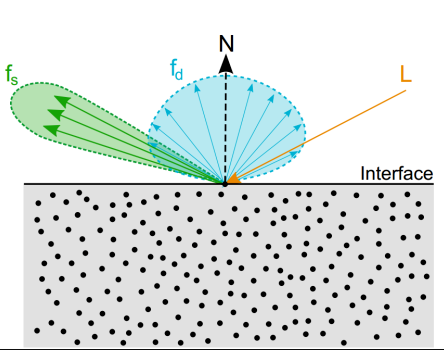
使用Lambert漫反射模型来计算Diffuse(漫反射光),上图的fd。无论观察者从哪个方向观察,漫反射效果是一样的,所以我们认为漫反射和观察位置是无关的。
漫反射的大小取决于表面法线N和光线L的夹角,即dot(N, -L)。光线越水平,夹角越大,漫反射分量越小;当夹角接近90度时,漫反射几乎为0。
镜面反射与观察方向是有关系的,在描述其性质时,需要知道观察者位置信息。
Blinn-Phong光照:Blinn-Phong为优化性能之后的Phong,主要对镜面反射做了改进。
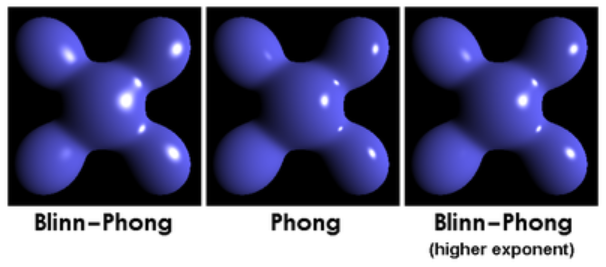
PBR(Physically Based Rendering,基于物理的渲染;PBS,基于物理的着色):是一套尝试基于真实世界光照物理模型的渲染技术合集,使用了一种更符合物理学规律的方式来模拟光线和介质表面的交互方式,达到更真实的渲染效果。
标准的PBR材质(Base Color、Metallic、Roughness、Normal、Ambient Occlusion):
BRDF(Bidirectional Reflectance Distribution Function,双向反射分布函数):不透明物体(可细分为金属与非金属)的反射模型
SBRDF(SVBRDF):一个捕获基于空间位置BRDF变化的函数被称为空间变化的BRDF(Spatially Varying BRDF ,SVBRDF)或称空间BRDF,空间双向反射分布函数(Spatial BRDF ,SBRDF)。
BTDF(Bidirectional Transmittance Distribution Function,双向透射分布函数):半透明物体的折射和透射模型
BSDF(Bidirectional Scattering Distribution Function,双向散射分布函数):BSDF = BRDF + BTDF,BSDF可以看做BRDF和BTDF更一般的形式
BSSRDF(Bidirectional Scattering-Surface Reflectance Distribution Function,双向散射表面反射分布函数):与BRDF的不同之处在于,BSSRDF可以指定不同的光线入射位置和出射位置。如:皮肤、玉、蜡、大理石、牛奶等半透明物体,需用次表面散射模型来渲染
NPR(Non-photorealistic rendering,非真实感的渲染):其主要目标是使用一些渲染方法使得画面达到和某些特殊的绘画风格相似的效果,例如卡通、水彩风格等。
Toon Rendering(Cel shading,cell shading,卡通渲染):是NPR的一种。与常规渲染不同的是,卡通渲染的光照效果是经过去真实感处理的。常规光源(明暗间有平滑过渡)的取值被逐一像素计算并投射到一小片独立的明暗区域上,以产生卡通式的单调色彩。
卡通着色基本的三个要素:
① 锐利的阴影(Sharp shadows)
② 少有或没有高亮的点(Little or no highlight)
③ 对物体轮廓进行描边(Outline around objects)
实现方法:
对于含有纹理但没有光照的模型来说,可以通过对纹理进行量化来近似具有实心填充颜色的卡通风格。
对于明暗处理,有两种最为常见的方法,一种是用实心颜色填充多边形区域。但这种方式实用价值不大。另一种是使用 2-tone方法来表示光照效果和阴影区域。
也称为硬着色方法(Hard Shading),可以通过将传统光照方程元素重新映射到不同的调色板上来实现。此外,一般用黑色来绘制图形的轮廓,可以达到增强卡通视觉效果的目的。

抗锯齿(Anti-Aliasing,AA)
AA也被称为边缘柔化、消除混叠、抗图像折叠有损等。主要是处理图像有锯齿的边缘,使图像更清晰。
锯齿的来源是因为场景的定义在三维空间中是连续的,而最终显示的像素则是一个离散的二维数组。所以判断一个点到底没有被某个像素覆盖的时候单纯是一个“有”或者“没有"问题,丢失了连续性的信息,导致锯齿。
SSAA(超级采样抗锯齿 Super-Sampling Anti-Aliasing):也叫做FSAA(全屏抗锯齿 Full Scene Anti-Aliasing)。比较早期的抗锯齿方法,比较消耗资源,但简单直接。
这种抗锯齿方法先把图像映射到缓存并把它放大,再用超级采样把放大后的图像像素进行采样。一般选取2个或4个邻近像素,把这些采样混合起来后,还原回原来大小的图像,生成最终像素。
拿4xSSAA举例子,假设最终屏幕输出的分辨率是800x600, 4xSSAA就会先渲染到一个分辨率1600x1200的buffer上,然后再直接把这个放大4倍的buffer下采样致800x600。
这种做法在数学上是最完美的抗锯齿。但是劣势也很明显,光栅化和着色的计算负荷都比原来多了4倍,render target的大小也涨了4倍。
MSAA(多重采样抗锯齿 MultiSampling Anti-Aliasing):对边缘(锯齿最明显的地方)像素进行细分成更多像素,然后加权显示。相当于对边缘像素放大渲染再缩小。提取边缘,主要是结合深度技术。MSAA是种硬件AA,一般只支持前向渲染。
FXAA(快速近似抗锯齿 Fast Approximate Anti-Aliasing):也是种取边缘的技术。但是和MSAA不同,MSAA提边缘是在图形管线的前段(跟深度有关)。
FXAA是种后处理技术,性能开销最小,后处理技术一般在画面完成后,通过像素颜色检测边缘(色彩差异太大时,不是边缘也被认为成边缘,精度有问题)。优缺点:消耗低,速度快;但是是一种粗糙的模糊处理。
SMAA(增强亚像素形态学抗锯齿 Enhanced Subpixel Morphological Anti-Aliasing):与 FXAA类似,性能消耗小,相比FXAA也更清晰。
SMAA是后处理抗锯齿技术的一种,它的基本处理流程建立在Jimenez优化改造后的MLAA(形态学抗锯齿)算法之上。缺点:动态画面时,锯齿抖动厉害。
TXAA(时间混叠反锯齿):只能在nVIDIA显卡上用。计算量最大,效果最好的AA算法。常用于电影CG。
MFAA(多帧采样抗锯齿 Multi-Frame AA):与MSAA基于像素采样有所不同,MFAA是基于帧采样的,MFAA在相邻的两帧上各执行一次抗锯齿采样,然后通过NVIDIA自行开发的图像合成处理技术来整合采样结果,最后输出完成抗锯齿运算的图像。
TAA(随机采样抗锯齿, 时域抗锯齿,Temporal Anti-Aliasing):帧渲染时抖动相机0~1个像素内,和历史帧加权平均。会导致画面轻微模糊。
性能上FXAA和TAA不会增加着色像素,具有计算量优势,一般比MSAA要快。TAA相比FXAA则需要额外的buffer保存历史帧,有一定内存和带宽占用。
相比FXAA和TAA,MSAA只影响边缘,效果最好。TAA和FXAA都会造成图像上一定的模糊,一般TAA要比FXAA要好一些。
参考
【《Real-Time Rendering 3rd》 提炼总结】(四) 第五章 · 图形渲染与视觉外观 The Visual Appearance