- 常用的正则表达式匹配规则
d 表示一个数字字符,等价于 [0-9]
D 表示一个非数字字符,等价于 [^d]
s 表示一个空白字符,等价于 [<空格> fv]
S 表示一个非空白字符,等价于 [^s]
w 表示一个单词字符(数字或字母),等价于 [A-Za-z0-9_]
W 表示一个非单词字符,等价于 [^w]
. 匹配除换行符
之外的任意一个字符
.* 在一行内,贪婪(尽可能多)匹配任意个字符
.*? 在一行内,非贪婪(尽可能少)匹配任意个字符
(?P<name>pattern) 和 (P=name) 用来多次匹配同一模式的字符串,pattern为匹配该模式的正则表达式
- 习题1:(爬虫)获取网页内容中的skuid字段和对应图片
1 # 爬虫:获取网页内容中的skuid字段和对应图片 2 import re 3 import requests 4 5 url = "http://qwd.jd.com/fcgi-bin/qwd_searchitem_ex?skuid=26878432382%7C1658610413%7C26222795271%7C25168000024%7C11731514723%7C26348513019%7C20000220615%7C4813030%7C25965247088%7C5327182%7C19588651151%7C1780924%7C15495544751%7C10114188069%7C27036535156%7C10123099847%7C26016197600%7C10503200866%7C16675691362%7C15904713681" 6 7 session = request.session() 8 r = session.get(url) 9 html = r.text 10 11 reg = re.compile(r""skuid":"(d+)",s+"S+s+"skuurl"S+s+"skuimgurl":"(S+)",") 12 result = reg.findall(html) 13 print(result)
- 习题2:将指定文件中的每个Upstream和Location都保存为一个文件
备注:先在regex101网站上,将相应的正则表达式写正确,然后再写python代码
匹配upstream的正则表达式如下:
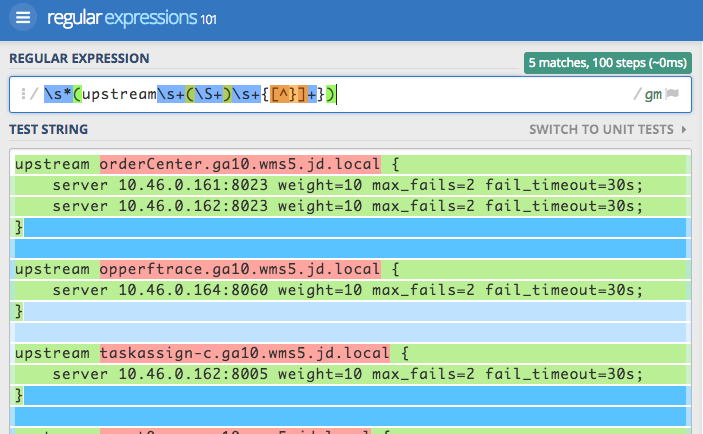
匹配location的正则表达式如下:
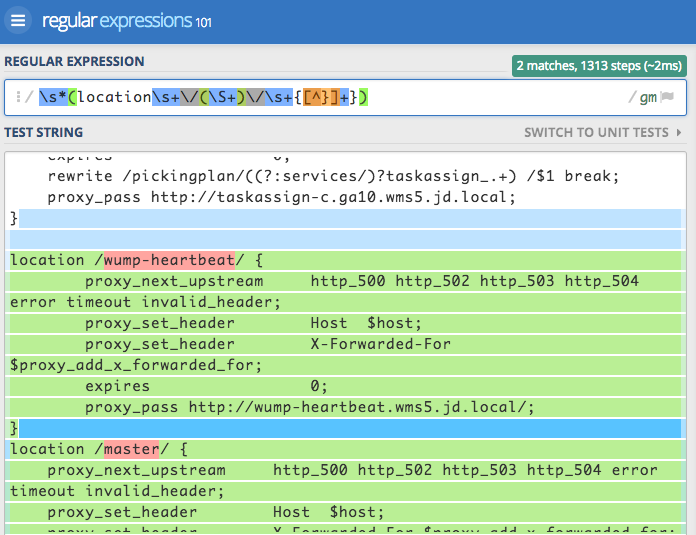
python代码如下:
1 import codecs 2 import re 3 import os 4 5 regUpstream =re.compile(r"s*(upstreams+(S+)s+{[^}]+})") 6 with codecs.open("ga10.txt") as fu: 7 textUpstream = regUpstream.findall(fu.read()) 8 if not os.path.exists("upstream"): 9 os.mkdir("upstream") 10 os.chdir("upstream") 11 for item in textUpstream: 12 with codecs.open(item[1], "w") as fw: 13 fw.write(item[0]) 14 os.chdir("..") 15 16 17 regLocation = re.compile(r"s*(locations+/(S+)/s+{[^}]+})") 18 with codecs.open("ga10.txt") as fl: 19 textLocation = regLocation.findall(fl.read()) 20 if not os.path.exists("location"): 21 os.mkdir("location") 22 os.chdir("location") 23 for item in textLocation: 24 file = item[1] + ".location.conf" 25 with codecs.open(file, "w") as fw2: 26 fw2.write(item[0])