数据库相关的SQL
查看所有数据库 show databases; 创建数据库 格式:create database 数据库名称; create database db1; 删除 格式:drop database 数据库名称; 查看数据库详情 格式:show create database 数据库名称; show create database db1; 创建数据库指定字符集 格式:create database 数据库名称 character set utf8/gbk; create database db2 character set gbk; 使用数据库 格式: use 数据库名称 use db1;
表相关SQL
- 创建表 create table t1(name varchar(10),age int) engine=myisam/innodb charset=gbk/utf8;
- 查询所有表 show tables;
- 查询表详情 show create table t1;
- 查看表字段 desc t1;
- 修改表名 rename table t1 to t2;
- 修改表引擎字符集 alter table t1 engine=myisam/innodb charset=gbk/utf8;
- 添加表字段 alter table t1 add age int first/after xxx;
- 删除表字段 alter table t1 drop age;
- 修改表字段名称和类型 alter table t1 change age xxx 类型;
- 修改表字段的类型和位置 alter table t1 modify age 新类型 first/after xxx;
- 删除表 drop table t1;
数据相关
插入数据 insert into t1 (字段名1,字段名2,字段名3) values(1,2,3),(1,2,3);
查询数据 select * from t1 where id<5;
修改数据 update t1 set name='xxx' where id=2;
删除数据 delete from t1 where id<5;
主键约束
主键:用于表示数据唯一性的字段称为主键
约束:就是对表字段的值添加限制条件
主键约束:保证主键的值唯一并且非空
格式: create table t1(id int primary key,name varchar(10));
主键约束+自增
格式: create table t2(id int primary key auto_increment,name varchar(10));
自增数值只增不减,从历史最大值的基础上+1
truncate table t2; //删除表并创建新表 自增数值清零
注释 comment
格式: create table t3(id int primary key auto_increment comment '这是个主键',name varchar(10) comment '这是名字'); 查看注释内容: show create table t3;
事务
事务(transaction)是数据库中执行同一业务多条SQL语句的工作单元,事务可以保证多条SQL语句全部执行成功或全部执行失败
验证事务:
创建表 create table user(id int primary key auto_increment,name varchar(10),money int,state varchar(5));
插入数据 insert into user values(null,'李雷',5000,'正常'),(null,'韩梅梅',50,'正常'),(null,'Lucy',10,'冻结');
李雷给Lucy转账SQL: update user set money=4000 where id=1 and state='正常'; update user set money=1010 where id=3 and state='正常'; select * from user;
以上代码无事务保护,则导致数据库内部的数据李雷丢了1000块钱
以下操作有事务保护的步骤: -开启事务: begin; -让李雷-1000 update user set money=3000 where id=1 and state='正常'; -让Lucy+1000 update user set money=1010 where id=3 and state='正常'; -因为一条成功一条失败 所以不能把内存中的改变提交到磁盘中,所以需要执行回滚指令,执行之前可以打开另外一个窗口查看数据库中的数据是否发生改变(变的是内存中的数据,数据库里面的数据并没发生改变) rollback;
转账成功执行流程:
开启事务 begin;
让李雷-1000 update user set money=3000 where id=1 and state='正常';
让韩梅梅+1000 update user set money=1050 where id=2 and state='正常';
由于转账业务的多条SQL全部执行成功 所以可以执行提交指令 把内存中的改动提交到磁盘中 commit;
和事务相关的SQL语句:
begin: 开启事务
rollback:回滚事务 把内存中的改动清除
commit:提交事务 把内存中的改动一次性提交到磁盘中
第二种开启事务的方式 数据库中事务默认是自动提交的
查看数据库自动提交的状态 show variables like '%autocommit%';
修改自动提交的状态 0关闭 1 开启 set autocommit=0;
修改李雷钱为50000 update user set money=50000 where id=1;
savepoint:保存回滚点 set autocommit=1; 李雷开始是50000 begin; update user set money=10000 where id=1; savepoint s1 update user set money=20000 where id=1; savepoint s2 update user set money=30000 where id=1; rollback to s1;
总结事务相关指令:
begin开启事务
rollback 回滚事务
commit 提交事务
查看自动提交状态 show variables like '%autocommit%'
修改自动提交状态 set autocommit=0/1;
保存回滚点 savepoint s1;
回滚到回滚点 rollback to s1;
SQL分类
DDL Data Definition Language
数据定义语言
包括: create,alter,drop,truncate
不支持事务
DML Data Manipulation Language
数据操作语言
包括: insert delete update select(DQL)
支持事务
DQL Data Query Language
数据查询语言
只包括select
TCL Transaction Control Language
事务控制语言
包括:begin,rollback commit,savepoint xxx,rollback to xxx
DCL Data Control Language
数据控制语言
用于分配用户权限相关的SQL
数据类型
整数类型: int(m)对应java中的int, bigint(m)对应java中的long,m代表显示长度,需要结合 zerofill使用 create table tint(id int,age int(8) zerofill); insert into tint values(1,28); select * from t_int;
浮点数: double(m,d) m代表总长度,d代表小数长度 76.232(m=5 d=3),decimal超高精度小数,当涉及超高精度运算时使用。
字符串: char(m) 固定长度 最大255 char(10) "abc" 所占长度10,varchar(m) 可变长度 最大65535 varchar(10) "abc" 所占长度3,可变长度更节省空间,固定长度执行效率略高
varchar最大65535 但是建议保存255以内的长度,超过255使用text
text可变长度 最大65535,
日期:
data:只能保存年月日
time:只能保存时分秒
datetime:保存年月日时分秒,最大值9999-12-31,默认值null
timestamp:保存年月日时分秒,最大值2038-1-19,默认值为当前时间
create table t_date(d1 date,d2 time,d3 datetime,d4 timestamp);
insert into t_date values('2018-11-15','16:58:33',null,null);
insert into t_date values ('2018-11-15','16:58:33','2018-10-18 12:30:18',null);
is null 和 is not null
查询没有上级领导的员工编号,姓名,工资 select empno,ename,sal from emp where mgr is null;
查询emp表中没有奖金comm的员工姓名、工资、奖金 select ename,sal,comm from emp where comm is null;
查询emp表中有奖金的员工信息 select * from emp where comm is not null and comm>0;
别名
把查询到的员工姓名ename 改成 名字 select ename as '名字' from emp; select ename '名字' from emp; select ename 名字 from emp;
去重 distinct
查询emp表中出现的所有职位job select distinct job from emp;
比较运算符 >,<,>=,<=,=,!=和<>
查询工资小于等于1600的员工姓名和工资 select ename,sal from emp where sal<=1600;
查询部门编号是20的所有员工的姓名、职位job和部门编号deptno select ename,job,deptno from emp where deptno=20;
查询职位是manager的所有员工姓名和职位 select ename,job from emp where job='manager';
查询部门不是10号部门的所有员工姓名和部门编号(两种写法) select ename,deptno from emp where deptno!=10; select ename,deptno from emp where deptno<>10;
查询titem表中单价price 等于23的商品信息 select * from titem where price=23;
查询titem表中单价不等于8443的商品标题title和单价 select title,price from titem where price!=8443;
and 和 or
and和java中的&&效果一样
or 和java中的||效果一样
查询不是10号部门并且工资小于3000的员工信息 select * from emp where deptno!=10 and sal<3000;
查询部门编号为30号或者上级领导为7698的员工姓名,职位,上级领导和部门编号 select ename,job,mgr,deptno from emp where deptno=30 or mgr=7698;
in
当查询某个字段的值为多个的时候使用in关键字
查询emp表中工资为5000,1500,3000的员工信息
select * from emp where sal=5000 or sal=1500 or sal=3000; -使用in: select * from emp where sal in(5000,1500,3000);
查询emp表中工资不等于5000,1500,3000的员工信息 select * from emp where sal not in(5000,1500,3000);
between x and y 包括x和y
查询emp表中工资在2000到3000之间的员工信息 select * from emp where sal>=2000 and sal<=3000;
between and select * from emp where sal between 2000 and 3000;
查询emp表中工资在1000到3000之外的员工信息 select * from emp where sal not between 1000 and 3000;
模糊查询 like
_:代表单个未知字符
%:代表0或多个未知字符
举例:
查询以a开头 like 'a%'
以m结尾 like '%m'
第二个字符是a like '_a%'
第三个字符是x 倒数第二个字符是y like '_x%y'
倒数第三个字符是x like '%x__'
查询包含a like '%a%'
案例:
- 查询titem表中 标题中包含记事本的商品信息 select title from titem where title like '%记事本%';
- 查询单价低于100的记事本(title包含记事本) select * from t_item where price<100 and title like '%记事本%';
- 查询单价在50到200之间的得力商品(title包含得力) select * from t_item where price between 50 and 200 and title like '%得力%';
- 查询有图片的得力商品 (有图片image字段不为null) select * from t_item where image is not null and title like '%得力%';
- 查询分类(categoryid)为238,917的商品信息 select * from titem where category_id in(238,917);
- 查询有赠品的商品信息(卖点sellpoint包含赠字) select * from titem where sellpoint like '%赠%';
- 查询标题中不包含得力的商品标题 select title from t_item where title not like '%得力%';
排序 order by
格式 order by 字段名 desc降序/asc升序;
查询所有员工的姓名和工资,按照工资升序排序 select ename,sal from emp order by sal;
查询所有员工的姓名,工资和部门编号,按照部门编号降序排序 select ename,sal,deptno from emp order by deptno desc;
多字段排序: order by 字段名1 asc/desc,字段名2 asc/desc;
查询所有员工的姓名,工资和部门编号,按照部门编号降序排序,如果部门一致则按照工资升序排序 select ename,sal,deptno from emp order by deptno desc,sal;
分页查询 limit
格式: limit 跳过的条数,请求的数量
举例:
请求第一页20条数据 limit 0,20
请求第三页10条数据 limit 20,10
请求第5页 8条数据 limit 32,8
请求第四页 7条数据 limit 21,7
公式:limit((页数-1)*每页数量,每页数量)
练习:
查询所有商品按照单价升序排序,显示第二页每页7条数据 select price from t_item order by price limit 7,7;
查询员工表中所有员工的姓名和工资,按照工资降序排序,显示第3页每页三条数据 select ename,sal from emp order by sal desc limit 6,3;
查询所有员工中工资前三名的姓名和工资 select ename,sal from emp order by sal desc limit 0,3;
查询工资最高的员工姓名和工资 select ename,sal from emp order by sal desc limit 0,1;
数值计算 + - * / % 7%2 等效 mod(7,2)
查询员工姓名,工资,及年终奖(年终奖=工资5) select ename,sal,sal5 年终奖 from emp;
查询titem表中商品单价,库存和总金额(单价库存) select price,num,pricenum 总金额 from titem;
修每个员工的工资,每个人涨10块钱 update emp set sal=sal+10;
改回去 update emp set sal=sal-10;
日期相关的函数
获取当前 日期+时间 now() select now();
获取当前的日期 curdate() cur(current当前) select curdate();
获取当前时间 curtime() select curtime();
从年月日时分秒中提取年月日 和 提取时分秒 select date(now()); select time(now());
查询商品上传的日期 select date(createdtime) from titem; select time(createdtime) from titem;
从年月日时分秒中提取时间分量 extract(year from now()) select extract(year from now()); select extract(month from now()); select extract(day from now()); select extract(hour from now()); select extract(minute from now()); select extract(second from now());
查询每个员工入职的年份 select extract(year from hiredate) from emp;
日期格式化
格式: %Y 四位年 2018 %y两位年 18 %m 两位月 05 %c一位月 5 %d 日 %H 24小时 %h 12小时 %i 分 %s 秒
date_format(时间,格式)
举例: 把时间默认格式转成 年月日时分秒 select date_format(now(),'%Y年%m月%d日 %H时%i分%s秒');
把非标准格式的时间转回默认格式 strtodate('非标准格式的时间',格式)
举例: 把 14.08.2018 08:00:00 转成标准格式 select strtodate('14.08.2018 08:00:00','%d.%m.%Y %H:%i:%s');
ifnull(x,y)函数
age = ifnull(x,y) 如果x的值为null则age=y 如果x值不为null则age=x
把员工表中奖金为null的改成0 其它的不变 update emp set comm=ifnull(comm,0);
聚合函数
聚合函数用于对多行数据进行统计,平均值,最大值,最小值,求和,统计数量
平均值: avg(字段名称)
查询所有员工的平均工资 select avg(sal) from emp;
查询10号部门的平均工资 select avg(sal) from emp where deptno=10;
查询戴尔商品的平均单价 select avg(price) from t_item where title like '%戴尔%';
最大值: max(字段名)
查询所有员工中的最高工资 select max(sal) from emp;
查询30号部门中的最高奖金 select max(comm) from emp where deptno=30;
最小值:min(字段名)
查询20号部门的最低工资 select min(sal) from emp where deptno=20;
查询商品表中所有商品中最便宜的价格是多少 select min(price) from t_item;
求和: sum(字段名)
查询30号部门每个月需要发多少工资 select sum(sal) from emp where deptno=30;
查询戴尔商品的库存总量 select sum(num) from t_item where title like '%戴尔%';
统计数量: count(字段名)
查询员工表中的员工数量 select count(*) from emp;
查询员工表中30号部门工资大于2000块钱的人数 select count(*) from emp where deptno=30 and sal>2000;
回顾: 平均值avg() 最大值max() 最小值min() 求和sum() 统计数量count()
字符串相关
字符串拼接 concat('aa','bb') ->aabb
案例: 查询emp表中 员工姓名和工资 工资后面显示单位元
select ename,concat(sal,'元') from emp;
获取字符串的长度 char_length('abc') 3
案例 :查询员工姓名和姓名的长度 select ename,char_length(ename) from emp;
获取字符串在另一个字符串出现的位置 -格式1:instr(str,substr) select instr('abcdefg','c'); -格式2:locate(substr,str) select locate('c','abcdefg');
插入字符串 insert(str,start,length,newstr) select insert('abcdefg',3,2,'m');
转大小写
格式: upper(str) lower(str) select upper('nba'),lower('NBa');
去两端空白 select trim(' a b ');
截取字符串
left(str,num) select left('abcdefg',2);
right(str,num) select right('abcdefg',2);
substring(str,start,?length) select substring('abcdefg',2,3);
重复 repeat select repeat('ab',2);
替换 replace select replace('abcdefg','c','x');
反转 reverse select reverse('abc');
数学相关函数
向下取整 floor(num) select floor(3.84); 3
四舍五入 round(num) select round(23.8); 24
round(num,m) select round(23.879,2); 23.88
非四舍五入 select truncate(23.879,2); 23.87
随机数 rand() 0-1 获取3、4、5 随机数 select floor(rand()*3)+3;
分组查询
将某个字段的相同值分为一组,对其它字段的数据进行聚合函数的统计,称为分组查询
查询每个部门的平均工资 select deptno,avg(sal) from emp group by deptno;
查询每个职位的最高工资 select job,max(sal) from emp group by job;
查询每个部门的人数 select deptno,count(*) from emp group by deptno;
查询每个职位中工资大于1000的人数 select job,count(*) from emp where sal>1000 group by job;
查询每个领导的手下人数 select mgr,count(*) from emp where mgr is not null group by mgr;
多字段分组查询
查询每个部门每个主管的手下人数 select deptno,mgr,count(*) from emp where mgr is not null group by deptno,mgr;
案例:查询emp表中每个部门的编号,人数,工资总和,最后根据人数进行升序排列,如果人数一致,根据工资总和降序排列。 select deptno,count(),sum(sal) from emp group by deptno order by count(),sum(sal) desc;
select deptno,count(*) c,sum(sal) s from emp group by deptno order by c,s desc;
案例:查询工资在1000~3000之间的员工信息,每个部门的编号,平均工资,最低工资,最高工资,根据平均工资进行升序排列。 select deptno,avg(sal) a,min(sal),max(sal) from emp where sal between 1000 and 3000 group by deptno order by a;
案例:查询含有上级领导的员工,每个职业的人数,工资的总和,平均工资,最低工资,最后根据人数进行降序排列,如果人数一致,根据平均工资进行升序排列 select job,count(*) c,sum(sal),avg(sal) a,min(sal) from emp where mgr is not null group by job order by c desc,a;
having
having后面可以写普通字段的条件也可以写聚合函数的条件,但是不推荐在having后面写普通字段的条件
where后面不能写聚合函数的条件
having要结合分组查询使用
查询每个部门的平均工资,要求平均工资大于2000. -错误写法(where后面不能写聚合函数) select deptno,avg(sal) from emp where avg(sal)>2000 group by deptno; -正确写法: select deptno,avg(sal) a from emp group by deptno having a>2000;
查询titem表中每个分类categoryid的平均单价要求平均单价低于100 select category_id,avg(price) a from titem group by categoryid having a<100;
查询emp表中工资在1000-3000之间的员工,每个部门的编号,工资总和,平均工资,过滤掉平均工资低于2000的部门,按照平均工资进行降序排序 select deptno,sum(sal),avg(sal) a from emp where sal between 1000 and 3000 group by deptno having a>=2000 order by a desc;
查询emp表中每个部门的平均工资高于2000的部门编号,部门人数,平均工资,最后根据平均工资降序排序 select deptno,count(*),avg(sal) a from emp group by deptno having a>2000 order by a desc;
查询emp表中不是以s开头,每个职位的名字,人数,工资总和,最高工资,高滤掉平均工资是3000的职位,根据人数升序排序 如果人数一致则根据工资总和降序排序 select job,count(*) c,sum(sal) s,max(sal) from emp where job not like 's%' group by job having avg(sal)!=3000 order by c,s desc;
查询emp表中每年入职的人数。 select extract(year from hiredate) year,count(*) from emp group by year;
查询每个部门的最高平均工资(提高题) select avg(sal) a from emp group by deptno order by a desc limit 0,1;
拿最高平均工资的部门编号 (并列第一的问题无法解决) select deptno from emp group by deptno order by avg(sal) desc limit 0,1;
笛卡尔积
如果关联查询不写关联关系,则得到两张表结果的乘积,这个乘积称为笛卡尔积
笛卡尔积是错误的查询方式导致的结果,工作中切记不要出现
等值连接和内连接
这两种查询方式得到的结果是一样的
等值连接: select * from A,B where A.x=B.x and A.age=18;
内连接:select * from A join B on A.x=B.x where A.age=18;
查询每一个员工姓名和其对应的部门名称 select e.ename,d.dname from emp e join dept d on e.deptno=d.deptno;
外链接
查询A,B两张表的数据,如果查询两张表的交集数据使用内连接或等值连接,如果查询某一张表的全部数据另外一张表的交集数据则用外链接
-左外链接: select * from A left join B on A.x=B.x where A.age=18; -右外链接: select * from A right join B on A.x=B.x where A.age=18;
1. 查询所有员工和对应的部门名称 -插入新数据 insert into emp (empno,ename,sal) values(10010,'Tom',500);
- 关联查询的查询方式:1. 等值连接 2.内连接 3.外链接(左外和右外)
- 查询两张表的交集用等值或内连接,推荐使用内连接
- 查询一张表的全部数据和另外一张表的交集数据使用外链接
视图
什么是视图: 数据库中的表和视图都是其内部的对象,视图可以理解成一张虚拟的表,视图本质就是取代了一条SQL查询语句。
为什么使用视图:因为有些数据的查询需要书写大量的SQL语句,每次书写效率太低,使用视图可以起到SQL重用的作用,视图可以隐藏敏感信息
创建视图的格式: create view 视图名 as 子查询; create table 表名 as 子查询
创建一个10号部门员工的视图 create view vemp10 as (select * from emp where deptno=10); -从视图中查询数据 select * from vemp10;
创建一个没有工资的员工表视图 create view vempnosal as (select empno,ename,comm,deptno from emp); -查询 select * from vempnosal
视图的分类
简单视图:创建视图的子查询中不包含:去重,函数,分组,关联查询。可以对视图中的数据进行增删改查操作
复杂视图:和简单视图相反,只能对视图中的数据进行查询操作
创建一个复杂视图 create view vempinfo as (select avg(sal),max(sal),min(sal) from emp); -查询 select * from vempinfo;
对简单视图进行增删改查,操作方式和table一样
插入数据 insert into vemp10 (empno,ename,deptno) values(10011,'刘备',10); select * from vemp10; select * from emp;
如果插入一条在视图中不可见,但是原表中却可见的数据称为 数据污染。 insert into vemp10 (empno,ename,deptno) values(10012,'关羽',20); select * from vemp10; select * from emp;
通过 with check option 解决数据污染问题 create view vemp20 as (select * from emp where deptno=20) with check option; insert into vemp20 (empno,ename,deptno) values(10013,'赵云',20); //成功 insert into vemp20 (empno,ename,deptno) values(10014,'黄忠',30); //失败
修改和删除视图中的数据(只能修改删除视图中有的数据) update vemp20 set ename='赵云2' where ename='赵云'; update vemp20 set ename='刘备2' where ename='刘备';//修改失败 delete from vemp20 where deptno=10;//没有数据被删除
创建或替换视图 create or replace view vemp10 as (select * from emp where deptno=10 and sal>2000);
删除视图 drop view 视图名; drop view vemp10; show tables;
如果创建视图的子查询中使用了别名 则对视图操作时只能使用别名 create view vemp10 as (select ename name from emp where deptno=10); select name from vemp10;//成功 select ename from vemp10;//失败
视图总结
视图是数据库中的对象,代表一段SQL语句,可以理解成一张虚拟的表
作用: 重用SQL,隐藏敏感信息
分类:简单视图(创建视图时不使用去重、函数、分组、关联查询,可以对数据进行增删改查)和复杂视图(和简单视图相反,只能对数据进行查询操作)
插入数据时有可能出现数据污染,可以通过with check option解决
删除和修改只能操作视图中存在的数据
起了别名后只能用别名
约束
什么是约束: 约束就是给表字段添加的限制条件
主键约束+自增 primary key auto_increment
作用:唯一且非空
非空约束 not null
作用:该字段的值不能为null create table tnull(id int,age int not null); insert into tnull values(1,18); //成功 insert into t_null values(2,null);//失败
唯一约束 unique
作用: 该字段的值不能重复 create table tunique(id int,age int unique); insert into tunique values(1,28);//成功 insert into t_unique values(2,28);//失败 不能重复
默认约束 default
作用: 给字段设置默认值 create table tdefault(id int,age int default 20); insert into tdefault (id) values(1); //默认值会生效 insert into tdefault values(2,null);//默认值不会生效 insert into tdefault values(3,30);//可以赋值其它值
外键约束
外键:用来建立关系的字段称为外键
外键约束: 添加外键约束的字段,值可以为null,可以重复,但是值不能是关联表中不存在的数据,外键指向的数据不能先删除,外键指向的表也不能先删除
如何使用外键约束 use db6;
创建部门表 create table dept(id int primary key auto_increment,name varchar(10));
创建员工表 create table emp(id int primary key autoincrement,name varchar(10),deptid int,constraint fkdept foreign key(deptid) references dept(id)); -格式介绍:constraint 约束名称 foreign key(外键字段名) references 依赖的表名(依赖的字段名)
测试插入数据 insert into dept values(null,'神仙'),(null,'妖怪'); insert into emp values(null,'悟空',1); insert into emp values(null,'赛亚人',3);//失败 delete from dept where id=1;//失败 drop table dept; //失败
由于添加外键约束后 会影响测试效率,所以工作中很少使用,一般都是通过java代码实现逻辑外键。
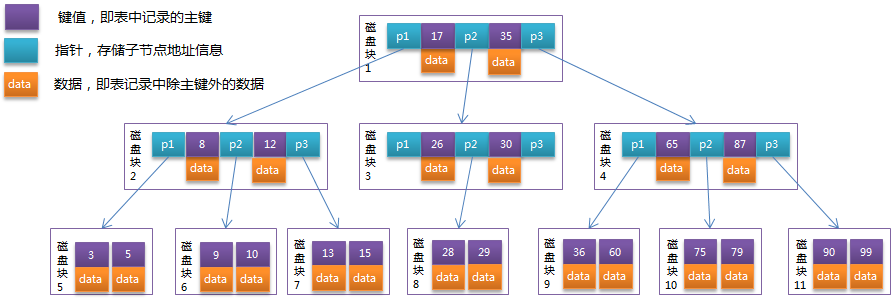
索引
什么是索引:索引是数据库中用来提高查询效率的技术,类似于目录
为什么使用索引:如果不使用索引,数据会零散的保存在磁盘块中,查询数据需要挨个遍历每一个磁盘块,直到找到数据为止,使用索引后会将磁盘块以树桩结构保存,查询数据时会大大降低磁盘块的访问数量,从而提高查询效率。
有索引就一定好吗? 如果表中的数据很少,使用索引反而会降低查询效率
索引是越多越好吗? 不是,索引会占用磁盘空间,只针对查询时常用的字段创建索引
导入数据 windows系统: source d:/itembackup.sql linux系统: source /home/soft01/桌面/itembackup.sql
导入完后: show tables; 查看是否有item2 这张表 select count(*) from item2; 172万
测试查询耗时 select * from item2 where title='100'; //耗时1.13
如何创建索引 title varchar(10)
格式: create index 索引名 on 表名(字段名(字符长度)) create index indexitemtitle on item2(title);
测试查询耗时 select * from item2 where title='100'; //耗时0.04
索引分类
- 聚集索引:通过主键创建的索引称为聚集索引,聚集索引中保存数据,只要给表添加主键约束,则会自动创建聚集索引
- 非聚集索引:通过非主键字段创建的索引称为非聚集索引,非聚集索引中没有数据
如何查看索引
- 格式:show index from 表名; show index from item2;
删除索引
- 格式: drop index 索引名 on 表名; drop index indexitemtitle on item2;
复合索引
- 通过多个字段创建的索引称为复合索引
- 格式: create index 索引名 on 表名(字段1,字段2); create index indexitemtitle_price on item2(title,price);
索引总结
- 索引是用来提高查询效率的技术,类似目录
- 因为索引会占用磁盘空间,所以不是越多越好
- 因为数据量小的时候使用索引会降低查询效率所以不是有索引就一定好
- 分类:聚集索引和非聚集索引
- 通过多个字段创建的索引称为复合索引
事务:
- 数据库中执行同一业务多条SQL语句的工作单元,可以保证全部执行成功或全部执行失败
事务的ACID特性
ACID是保证数据库事务正确执行的四大基本要素
Atomicty:原子性,最小不可拆分,保证全部成功或全部失败
Consistency:一致性,保证事务从一个一致状态到另外一个一致状态
Isolation:隔离性,多个事务之间互不影响
Durablity: 持久性,事务提交之后数据保存到数据库文件中持久生效
事务相关的SQL
开启事务 begin;
回滚 rollback;
提交 commit;
保存回滚点 savepoint s1;
回滚到某个回滚点 rollback to s1;
查看自动提交状态 show variables like '%autocommit%';
修改自动提交状态 set autocommit=0/1;
group_concat()
查询每一个部门所有员工的姓名和工资 select deptno,group_concat(ename,'-',sal) from emp group by deptno;
查询每个部门的员工姓名,要求每个部门只显示一行 select deptno,group_concat(ename) from emp group by deptno;
2019-12-04 13:48:22