本文探讨的是kaggle中的一个案例-员工离职分析,从数据集中分析员工的离职原因,并发现其中的问题。数据主要包括影响员工离职的各种因素(工资、绩效、工作满意度、参加项目数、工作时长、是否升职、等)以及员工是否已经离职的对应记录。
数据来源:Human Resources Analytics | Kaggle
参考学习视频:http://www.tianshansoft.com/
分析目的:分析员工离职原因。
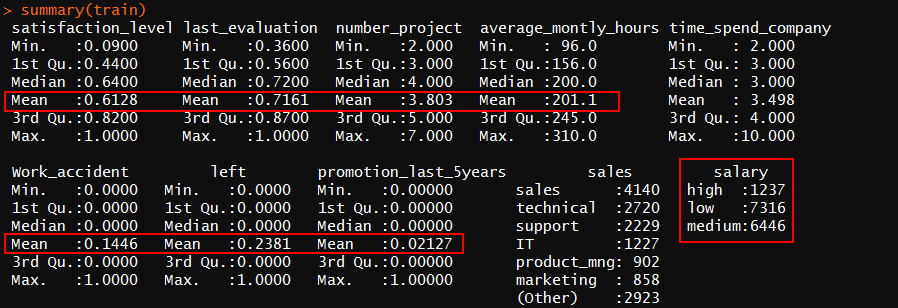
1.对数据集中变量进行描述性分析,变量说明:
2.探索是否离职与公司满意度,绩效,工作时长,工作意外的联系。
#员工离职与满意度关系 p1_sat<- ggplot(data = train,aes(left,satisfaction_level,fill=left))+geom_boxplot()+ labs(x='员工情况',y='员工对公司满意度')+ scale_x_discrete(labels=c('在职','离职'))+ stat_summary(fun.y = mean,geom="point",shape=23,size=1.8)+ #添加均值点 guides(fill=F) #除去图例
其他数据绘图类似
#呈现一页多图(Rmisc包) multiplot(p1_sat,p2_eva,p3_hours,p4_time,cols =2)
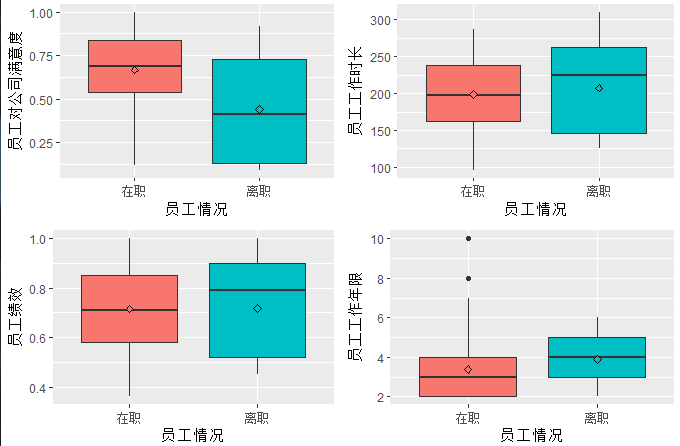
初步结论:
1.离职员工对公司满意度普遍较低,评分集中在0.4
2.离职员工工作时长较长,集中在220小时
3.50%以上的离职员工绩效都在0.8以上,超过了平均绩效0.71
3.离职员工工作年限普遍较长,平均在该公司工作了4年
3.探索是否离职与薪水水平、职业的关系
#探索是否离职与自身职业的关系 p5_sales<- ggplot(data = train,aes(sales,..count..,fill=left))+ geom_bar(stat = 'count',position = 'fill')+ labs(x='职位名称',y='比例')+ guides(fill=F) #去除图例
其他数据绘图类似
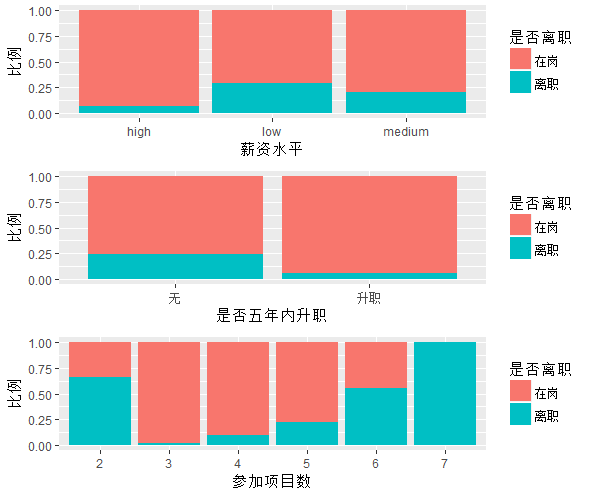
图中可看出
1.低工资的员工离职率较高,超过了25%。离职率与薪资水平呈负相关,薪水越高,离职率越低。
2.五年内无升职的员工,离职率达25%,远大于已升职的员工。
3.只参加了两个项目离职率接近65%,参加过7个项目的员工均已离职。参加项目越多,离职率越高(除去参加2个项目的员工)
接下来要进行的是
建模预测:决策树和朴素贝叶斯
建立决策树模型思路:
1.提取出优秀员工(绩效>0.7或工作年限>=4或参加项目数>=5)
2.交叉验证 (此处使用五折交叉验证)
3.划分训练集和测试集
4.训练模型,建模
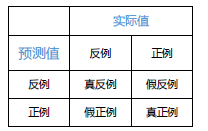
5.建立混淆矩阵
- 首先提取出优秀员工
good <-filter(.data = train,last_evaluation>0.7|time_spend_company>=4|number_project>=5) #满足三个条件中的一个均可 summary(good)
- 接着进行交叉验证(caret包)
train_control <- trainControl(method='cv',number = 5) #method = ‘cv’是设置交叉验证方法,number = 5意味着是5折交叉验证
- 划分训练集和测试集,70%作为训练集,剩下为测试集
set.seed(1234) #设置种子,使抽样结果一致 intrain <- createDataPartition(y = train$left,p = 0.7,list = F) #createDataPartition( )就是数据划分函数 #对象是left,p=0.7表示训练数据所占的比例为70% #list是输出结果的格式,默认list=FALSE
train_data <- train[intrain,] #训练集 test_data <- train[-intrain,] #测试集
- 使用训练集训练模型: train()函数
rpartmodel <- train(left ~ ., data = train_data, trControl = train_control, method = 'rpart') # 使用caret包中的trian函数对训练集使用5折交叉的方法建立决策树模型 # left ~.的意思是根据因变量与所有自变量建模;trCintrol是控制使用那种方法进行建模 # method就是设置使用哪种算法
- 利用rpartmodel模型进行预测:predict()函数
pre_model <- predict(rpartmodel,test_data[,-7])#([-7]的意思就是剔除测试集的因变量(left)这一列
- 建立混淆矩阵
con_rpart <- table(pre_model,test_data$left)
con_rpart #查看矩阵
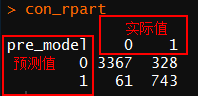
求得
查准率=743/(743+61)=92.4%
查全率=743/(743+328)=69.3%
建立朴素贝叶斯模型
思路:
1.训练模型
2.预测
1 nbmodel <-train(left ~. ,data=train_data,trControl=train_control,method='nb') 2 pre_nb_model <-predict(nbmodel,test_data[,-7]) 3 con_nb <- table(pre_nb_model,test_data$left) 4 con_nb
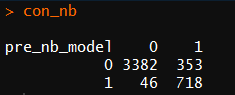
查准率: 718/(718+46)=93.97%
查全率: 718/(718+353)=67%
查全率较低于决策模型中的69%,所以使用决策树模型
模型评估
- 将预测模型转化为数值型
pre_model <- as.numeric(pre_model) #绘制ROC曲线需要将值转为数值型 pre_nb_model <-as.numeric(pre_nb_model) roc_rpart <- roc(test_data$left,pre_model) #使用决策树模型
- 求假正例率和真正例率(查全率)
#假正例率=1-真反例率 Specificity <- roc_rpart$specificities #真反例率。假正例率为ROC曲线X轴 Sensitivity <- roc_rpart$sensitivities #真正例率,为ROC曲线Y轴

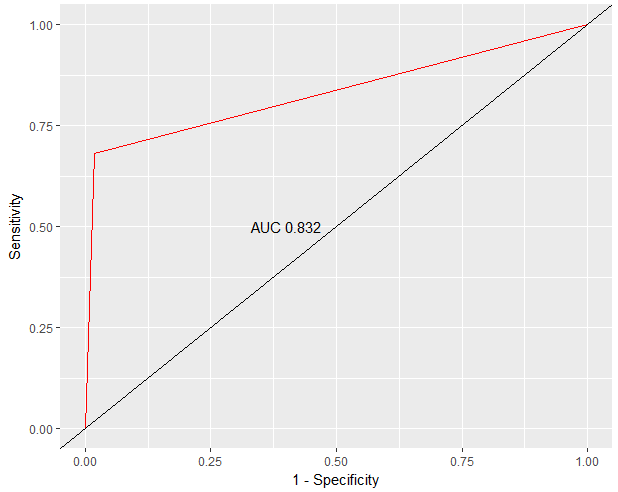
- 绘制ROC曲线(决策树模型)
ggplot(data = NULL,aes(1-Specificity,Sensitivity))+ geom_line(color='red') + #ROC曲线 geom_abline()+ #对角线 annotate(geom = 'text',x = 0.4,y=0.5,label=paste('AUC',round(roc_rpart$auc,3))) #geom='text'指图层上声明增加注释,在坐标(0.4,0.5)处添加AUC值
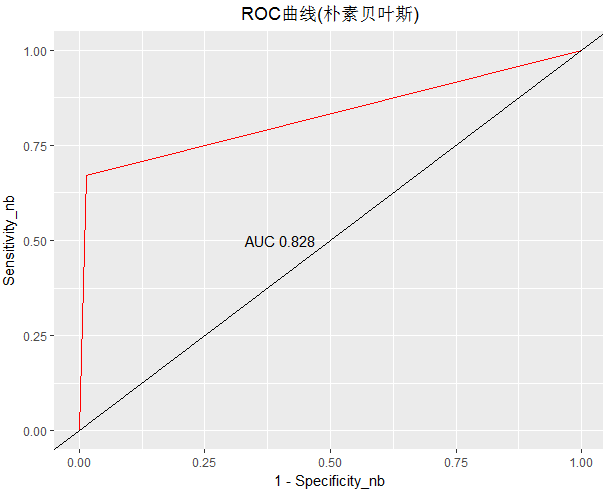
- 绘制ROC曲线(朴素贝叶斯模型)
pre_nb_model <-as.numeric(pre_nb_model) roc_nb <- roc(test_data$left,pre_nb_model) Specificity_nb <- roc_nb$specificities Sensitivity_nb <- roc_nb$sensitivities ggplot(data=NULL,aes(1-Specificity_nb,Sensitivity_nb))+ geom_line(color='red')+ geom_abline()+ geom_text(aes(0.4,0.5),data = NULL,label=paste('AUC',round(roc_nb$auc,3)))+ labs(title='ROC曲线(朴素贝叶斯)')+ theme(plot.title = element_text(hjust = 0.5))
模型应用
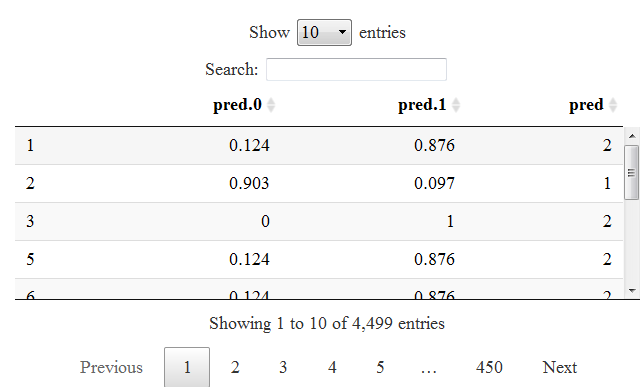
#使用回归树模型预测概率 Pre_end <- predict(rpartmodel,test_data[,-7],type='prob') data_end <- cbind(round(Pre_end,3),pre_model) names(data_end) <- c('pred.0', 'pred.1', 'pred') datatable(data_end)