hive版本:0.9.0
数据存储及解析
我们先来看下hive中如何建表,并通过分析建表语句了解hive中数据的存储解析方式
create table tutorial (
name string, //string类型字段name
number int, //int类型字段number
resource array<string>, //string数组类型字段
detail map<string, int> //字典类型(key为字符串,value为整型)
) partitioned by (dt string) //按dt分区,dt类型为string
row format delimited fields terminated by ' ' //指定列分隔符为tab
collection items terminated by ',' //指定数组中字段分隔符为逗号
map keys terminated by ':' ; //指定字典中KV分隔符为冒号
根据上面的建表语句,对应的数据应该长这样:
balabala2 222 str1,str2,str3 a:1,b:2,c:3
balabala3 333 str4,str5,str6 d:4,e:5,f:6
....
hive在读取数据时,首先根据TAB对列进行分隔,得到name, number, source, detail,name和number不用继续处理,可直接使用
source和detail属于复杂数据类型,hive需要再次进行解析:根据逗号分隔source,detail,再根据冒号分隔detail中每一项的key和value
ps. 这其中涉及到一个概念:读时模式 和 写时模式
读时模式:加载数据时进行数据检验(hive)
写时模式:写入数据时对照模式进行检查(传统RDBMS)
元数据
hive中的表由两部分组成:一是元数据(可以简单理解为表结构),二是数据,数据解析刚才分析过了,接下来看下元数据
元数据有三种存储方式:
1. 内嵌derby:缺点不支持多会话
2. 本机mysql
3. 远端mysql
目前我们的hadoop机器采用本机mysql的方式,数据存放在mysql中的metastore数据库内
metastore中几个重要的表:
1. dbs:存放hive所有数据库信息
2. tbls:存放hive所有表格信息
3. table_params:存放hive所有表格的参数信息
4. columns_v2:存放表格的字段信息
刚才表的信息在mysql中存储为:

分区partition
按照某几列的值对数据进行划分
tutorial表按照列dt进行划分,目录结构如下图:

桶bucket
两个用途:
1. 采样:用于对一小部分数据进行测试
2. 加速map-side join:HiveQL相关,不做讨论
索引
创建索引的语句:
CREATE INDEX idx ON TABLE db_player (yys, server_name, player_id) AS 'COMPACT' WITH DEFERRED REBUILD;
ALTER INDEX idx ON db_player REBUILD;
测试数据:
文件大小721MB,创建索引所需时间66s,索引大小531MB
查询速度对比:无索引16s,有索引11s
在创建索引后,发现索引文件是保存在HDFS上的,目录为:/user/hive/warehouse/gcld.db/gcld__db_player_idx__/
我们来看下索引文件的具体内容:
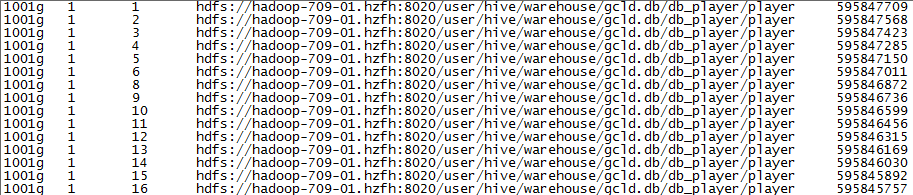
看到上图相信大家就一目了然了,前三列是建立索引时指定的列(yys, server_name, player_id),第四列是数据的绝对路径,第五列是一个数字,应该是类似地址的东西
在利用索引进行查询时,首先查询索引文件,然后根据前三列直接定位到数据在文件中的位置