【前言】
【本篇为原创】网络遥感,Network telemetry,为什么叫“telemetry”呢?我个人的理解是将网络中的数据进行一种“采集”,也就是实际上是一种网络数据的采集手段。由于工作需要,接触了一些网络遥感方面的技术,本篇文章就来谈一谈主流的网络遥感技术。本篇文章会介绍传统网络中基于“流”的遥感技术,以思科的Netflow技术为代表和IETF的IPFIX标准,再到最近比较流行的INT技术,INT技术会着重介绍思科的IOAM和华为的PBT两种。
【场景】
网络遥感是一种网络信息采集技术,目的是为了采集网络中的信息,网络越大,出了问题越难排查,因此需要一些技术对网络进行史实的流量分析监控或是可以自动化排查网络中的“断路”,并且在DCN网络中(Datacenter Network)更需要一套手段来实现对网络的监控与探测,对网络的实时监控需要一套技术来实现,那么网络遥感就是用来解决这个问题而诞生的一种技术。网络遥感一般分为两种,分别是主动探测和被动探测。被动探测以思科的Netflow技术为代表,而主动探测则大多数类似于微软Everflow中的guided probe组件为代表(还有vmware为代表的虚拟网络的Traceflow,以及华为的FusionNetDoctor,当然华为做的有点low...实话实说)。
【主动探测】
主动探测,顾名思义,就是“主动去探测网络中的状态”,为代表的以微软Everflow系统中的guided probe组件为代表,微软于2016年在SIGCOMM发了一篇名为《Packet-Level Telemetry in Large Datacenter Networks》文章,这篇文章主要介绍了微软的一套实现数据包级别的网络遥感技术,感兴趣的可以去google一下,我个人觉得写的非常好的一篇文章。其中提到了一个重要组件,叫做“guided probe”,那么这个guided probe是用来做什么的呢?
 图1.典型的虚拟网络拓扑
图1.典型的虚拟网络拓扑
图1是一个典型的虚拟网络拓扑,虚拟机A到虚拟机B需要经过三个虚拟交换机,两个虚拟路由器,那么假设某一时刻“正在发生”虚拟机A到虚拟机B发生了“断路”导致虚拟机A到虚拟机B的业务流量不通,怎么定位到具体发生故障的位置以及发生故障的原因呢?
微软的guided probe和vmware的traceflow就是做这个事情的。guided probe会在VM A注入一种“探测数据包”,然后在网元上设置一些“探测识别点”,这个数据包每经过一个网元都会上传状态信息,例如图2.
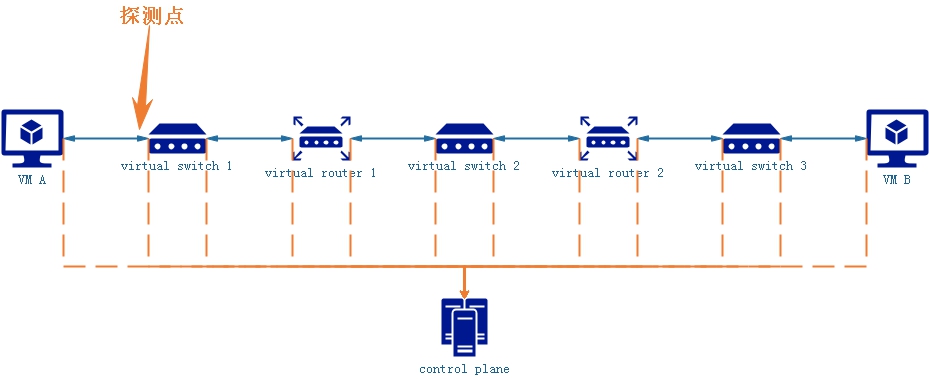
图2.主动探测的一种实现
以图2为例,我在每一个网元的输入和输出设置一些“探测识别点”,“探测数据包”经过“探测识别点”会向控制器上传状态信息,那么假设虚拟机A到虚拟机B中的虚拟交换机3的输入出发生故障,那么最终上传的信息会缺少“虚拟交换机3的OUT”,那么控制器就可以判断出虚拟交换机3处存在“正在发生“的故障,那么就可以通过北向通道告知管理面,管理面再告知用户,或直接发出告警。
当然还不止这样,如果数据面是自家公司研发的话还有一种升级的玩法,如果可以感知到“某条具体的背景流发生了断路”,“流“可以用5-tuple来标识(src ip、dst ip、src port、dst port、l4 protocol或者加上tos),那么我便在注入探测数据包的时候,拿出现“断流”的背景流量作为模板,构造出与出现“断路”的背景流量相同的数据包进行主动探测,并且如果数据面是自家公司研发的话,完全可以在数据面转发中的丢包处设置“探测识别点”,那么这样不仅知道出现断流的背景流具体的断流位置,还可以知道断流的原因,这样可以直接告诉用户“xxx条流量出现了断流,在xxx的位置,断流丢包的原因是xxx”,例如图3是VMWare的Traceflow的显示结果。
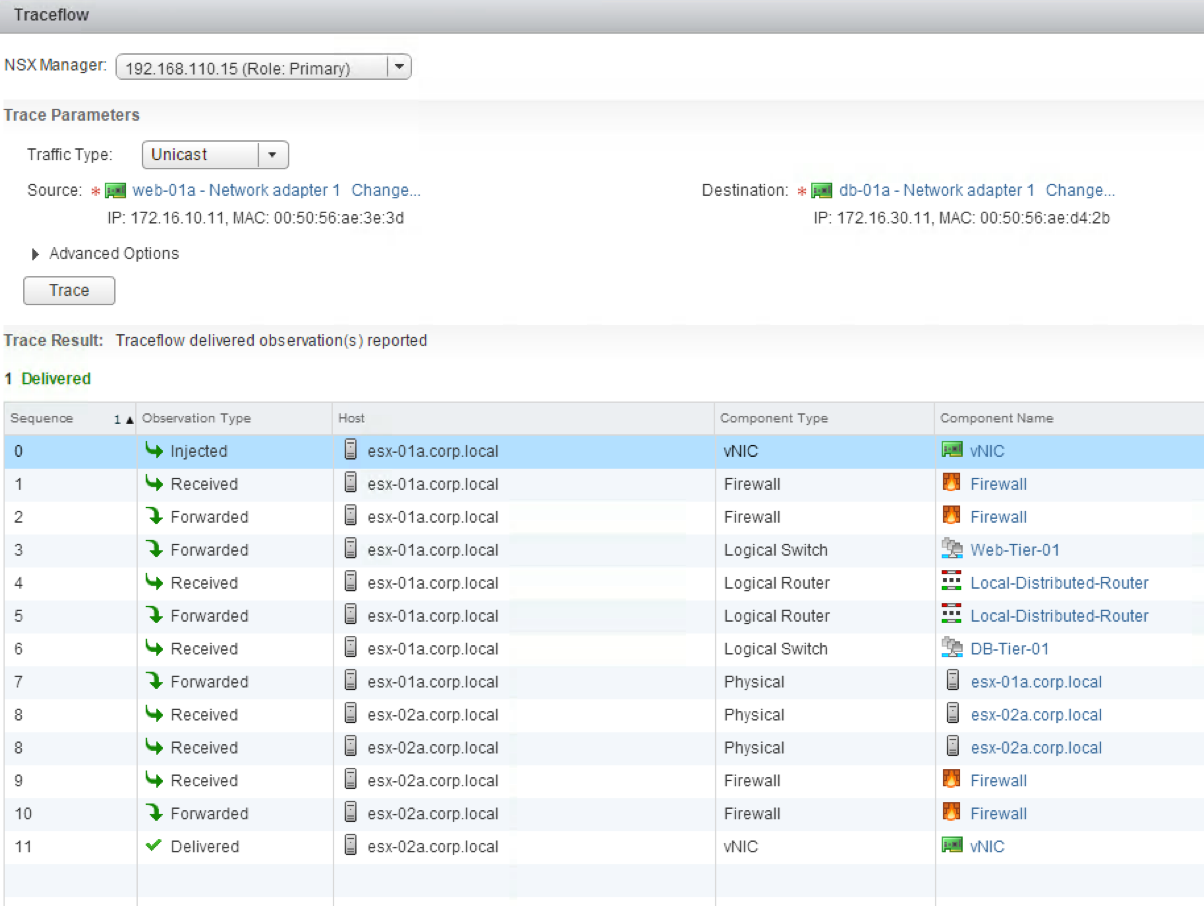
图3.VMWare的Traceflow使用效果图
上述流程便是主动探测的大多数实现,微软的Everflow、Vmware的Traceflow以及华为的FusionNetDoctor都是这样实现的(这里我一定要吹一波Vmware,做的真的有点好,真尼玛炫酷...)但是主动探测同样存在一些致命缺点:
- 只能探测正在发生的故障。如果故障是时断时续的,那主动探测这种手段就无能为力了。
- 探测的力度有限,例如正在发生的故障是丢包,并且丢包是只丢一部分,那么发出的探测数据包很有可能没有被丢,呈现出与现实世界不通的结果。(但是这种方法可以批量注入来观察)
- 无法回溯。这点与第一点基本相同,如果断流是某个过去的时间点发生的,例如半夜,那主动探测便无法得知过去某个时间点出现断路的原因与位置了。
- 需要在数据面设置探测识别点,探测识别点识别探测数据包不能影响正常的数据面转发性能。
微软的Everflow中提到,这种主动探测主要就是探测正在发生的断路,因为正在发生的断路的故障优先级最高,能实现这点已经足够,没办法指望单纯的一种技术来应付所有场景。
当然主动探测以后我会写一篇专门的文章来讲解其中存在的一些技术难点和实现方法。
【被动探测】
被动探测是与主动探测相对应的一种探测,被动探测的定义是在“不影响当前网络流量的情况下进行探测”,由于主动探测“注入探测数据包”会对当前网络中的流量做出一些影响(出现了一条新的流量)。被动探测以思科的Netflow作为代表,但是近年来也有一些新的技术分别亮相,比如思科提出的INT技术以及其具体应用IOAM,以及华为根据思科IOAM技术进行优化提出的PBT技术。由于被动探测的技术内容比主动探测的内容复杂一些,因此接下来会分别介绍,先介绍Netflow技术。
【Netflow】
Netflow技术由思科与1996年提出(和我同一年生....),到现在已经过了24年,已经是一种非常成熟的技术了,并且各家根据思科Netflow的思想还发展处了一些方言版本,例如jFlow,sFlow等等等等。Netflow的架构常常如图4所示。
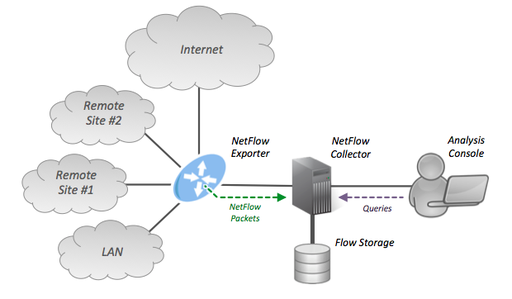
图4.Netflow架构图
只要是基于Netflow的采集技术(其实不光是Netflow,主要是流量采集技术基本都差不多...),无论做成什么样,做的多大,基本都离不开Netflow架构的这几个组件。
- Netflow Exporter。Netflow导出器,用处是将流数据通过Netflow协议进行导出至Netflow Collector中。
- Netflow Collector。Netflow收集器,用处是将Netflow数据包收上来后进行解析,解析出流数据后存至Flow Storage中。
- Flow Storage。流数据库,存解析后的Netflow数据,通常流数据库用的基本以TSDB为主(时序数据库),因为需要常常回溯某个时间点,或过去一段时间内流量分布的变化与状态信息,因此TSDB更适合,比较流行的有influxDB、Prometheus。
- Analyzer/Monitor。分析器,用于对流数据库中的数据进行分析与呈现。
当然还有一个最终要的组件便是Netflow设备的Flow cache。在Netflow设备中会存在一张表,这张表会存放流的信息,如图

图5.Netflow Main Cache原理图
原理也非常简单,即:
当某条流的数据包第一次进入当前Netflow设备后,Netflow设备会根据此数据包的5-tuple信息(这里随意定义)提取并在Netflow cache中添加一条Flow Entry,这条Flow Entry便代表此条流,那么便可以统计这条流的信息,并定时(Netflow cache通常都有老化机制)导出封装为Netflow协议数据包送往Netflow Collector
Netflow技术的原理非常简单,就是采集流信息,上传,然后分析。当然Netflow也有缺点,便是:
- 采集粒度为“流”,无法到达更细粒度的“数据包”,所以统计丢包、时延有一定难度。
- 会给Netflow设备带来性能损耗,性能的损耗往往会带来“观察者效应”。比如某一网络现象,拿网络拥塞或丢包为例,原本网络中不会有拥塞或丢包,但是由于开启了Netflow采集功能,采集功能消耗Netflow设备的性能,导致Netflwo设备处理网络流量的性能下降,进而产生了拥塞或丢包,那么便是“观察者效应”,最终的结果并不是已经存在的,而是由于去“观察”这一动作才会发生,不观察就不会发生,那么这种情况就比较蛋疼。而性能问题又会带来如下几种问题。
- 性能下降导致在DCN网络无法对每一个数据包都进行更新Flow cache,所以往往会存在采样频率一说,比较常见的是“每100个数据包采集第一个数据包”,用这种方法来降低性能消耗,但是这种方法又会产生额外的问题,比如在网络中通常会存在一些“大象流”和“老鼠流”,大象流的代表如FTP数据流,这些流量的特点是量大,持续一段时间后就会消失;而“老鼠流”的一些代表是一些控制协议或者是协商协议,这些流量的特点是量少,但是会一直持续,可靠性要求较高。但是如果存在采样频率,很可能会出现采集不到“老鼠流”,最后看起来就是“大象流”覆盖了“老鼠流”,只能看见有FTP协议流量,其他一些TCP协议流量看不到。
- Netflow协议上传的信息有限,尽管Netflow v9已经支持模板的方式去采集数据,但是仍然是有限的,并且无法采集一些企业的私有数据,并且Netflow v9的传输层协议为UDP协议,UDP协议本身可靠性较差,一旦出现上传信息丢失,还得额外处理。
- Netflow协议存在太多的方言版本,例如sFlow、jFlow,兼容性会有一定的问题,并且Netflow协议属于思科提出的一种流量导出协议,并不是一种标准。
Netflow的缺点中,第一种其实并不是Netflow技术的缺陷,而是基于“流”的网络信息采样的共性缺陷,第三种为Netflow这种传输层协议在设计的时候出现的缺陷,而第二种更偏向于“哲学”问题,“想看的更多就得花费更多的代价”,不想付出代价还想对网络进行细粒度的观察,是不可能的,就好比“你不能要一把枪射程又长,精度又高,为例又大,体积又小,射击速度又高”,这是不现实的。
【IPFIX】
IPFIX协议,IETF提出的一种“标准流信息导出协议”,目的就是为了替代Netflow v9协议和众多的方言版本协议,可以看做是未来的趋势,大多数厂商都已经兼容IPFIX协议,例如思科、华三、华为的交换机,VMware同样将IPFIX导出协议作为一种标准的流信息导出协议。
但是要注意的是IPFIX协议只是一种“信息导出协议”,目的是为了替代Netflow架构中的Exporter到Collector中的信息导出协议,但是整体架构基本如Netflow架构。IPFIX协议由Netflow v9协议发展而来,Netflow协议中的协议头的version为9,意味Netflow v9,而IPFIX协议中的协议头与Netflow v9基本一致,并且version为a(10),也就是Netflow v10,如图6.

图6.IPFIX头格式和Netflow v9头格式对比
而IPFIX作为IETF推出的标准流信息协议,在Netflow v9的基础上做了如下的改进:
- IPFIX的传输层协议较于Netflow v9支持更加多样化,支持UDP、TCP、SCTP协议作为传输层协议的选择;(这点请见RFC 7011的10.1节)
- IPFIX相较于Netflow v9协议新增了企业字段、变长内容等新特性,可以支持一些企业内部私有的数据导出(这个是我认为最方便的一点特性);(rfc 7012有详细解释)
- IPFIX协议的模板内容相较于Netflow v9增加了非常多,可以导出更多的信息。(同见rfc 7012)
可以看到,IPFIX相较于思科的Netflow更是一种协议标准,其中的企业字段可以很好的兼容一些方言版本的流信息导出协议,解决了很多兼容的麻烦,并且从功能的角度讲,IPFIX是兼容Netflow v9的(注意这里的功能值指的是导出内容上IPFIX要更全于Netflow v9),但是单纯从协议的角度讲是没法兼容的(也就是仍然得增加IPFIX的开发量)。
【INT】
INT技术是最近几年一种新型的网络遥感技术,全称是Inband Network Telemetry,意味“带内网络遥感技术”,是由思科提出的一个技术,INT是一种技术手段,一种思想,在思科产品中的应用叫做IOAM(inband OAM)那么这里就有一个新的概念,什么是“inband”?inband的意思直译是“带内”,但是“带内“又如何理解呢?
我个人的理解是:类似于Netflow或是IPFIX这类流监控技术,可以称之为”outband“,也就是带外。举个生活中的例子,带外就好比你是一个监控人,你在监控这条流的状态,你仍然处于一个旁观者的位置,既然是在一个旁观者的位置,那么观测的方法和观测的位置势必会对观测的结果有很大误差;而怎么最大化消除这种误差呢?生后中的经验告诉我们叫做”设身处地“,也就是我们把自己摆在当事人的视角去看待事情,那么我们可以看到更多有关事情的真面目,而inband就是这样,inband Network telemetry就是这么实现的,将旁观者监测流,改为将检测信息植入到数据包内部,这样就相当于监测点挂载到了流中的每一个数据包,那么这样数据包所经历的,必然是监测点所经历的。

图7.INT的实现方式
如图7所示,INT的实现方式就是将监测检查点插入到数据包的内部,也就是途中的OAM层,INT通常的做法就是将数据包的头(header)和数据包内部数据(payload)之间插入一块OAM层,那么这个数据包就从一个普通的网络数据包变成了一个被我们打上”标记“的数据包。再举个例子,相信看过动物世界节目的朋友都知道,海洋学家为了监测一些动物的行为轨迹,会在海洋动物身上装上遥感器,比如海龟、海豚、企鹅之类的,那么最后海洋学家就可以回收海豚的探测器,并根据探测器中记录的数据来分析这个海豚的行动轨迹,海豚的行为特征。那么INT就是这个原理,间图8.
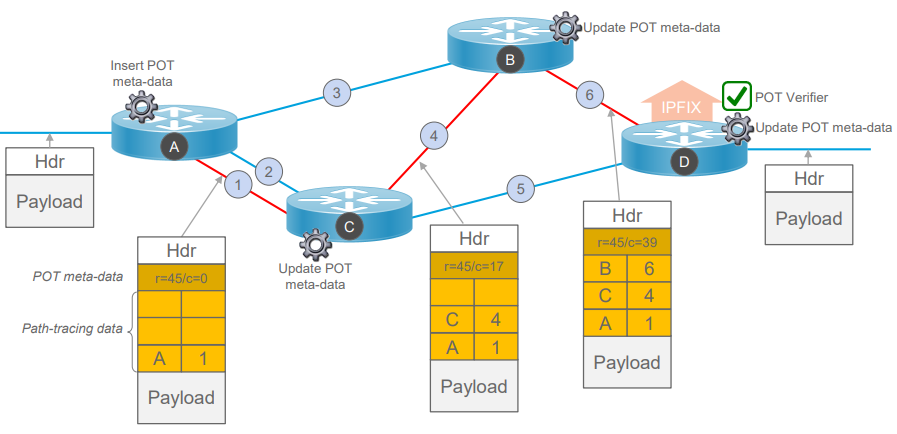
图8.INT技术监测网络状况的原理示意
如图8中的例子,一个数据包(就好比一只海豚)进入”起点“网元设备(被科学家捕获)后,被插上了OAM层(被装上了探测器),而后数据包经过每一个网元(每一片海洋),都会将探测信息插入到OAM层中(被探测器记录),包括网元对数据包的行为,是转发还是丢弃(海豚死亡),最后数据包到达终点后,数据包中的OAM层被剥离出来,通过信息导出协议上传到远程的分析服务器(探测器被科学家回收分析数据)。那么这里有一个问题,网元设备,也就是OAM域内的传输节点怎么知道要收集哪些信息呢?

图8.IOAM数据包中的OAM层
实际上,OAM层是由两部分组成的,一部分叫做instruction,也就是指令,另一部分就是data,也就是数据,指令中会携带需要收集的信息,translation node只需要根据指令把相应的信息塞入data部分中即可完成数据的收集。
可以看到INT技术本身的原理还是非常简单的,就是在数据包内部插入一个自定义的层,然后记录经过每一个网元的信息,最后再将探测信息上传至远程的分析服务器。那么INT技术会带来什么样的优势,或者换句话说,可以怎么应用这种技术呢?
- 数据包粒度级别的丢包监测,由于监测的粒度从流变成了更细粒度的包,那么理想情况下,INT技术是可以得知网络中丢包的情况以及丢包的原因还有丢包的位置。
- 捕获网络中的jitter现象,网络中经常会出现一些jitter,jitter的特征往往是短暂难以捕获的,而由于INT技术是一种带内技术,那么理想情况下仍然是可以捕获到网络中的时延或是丢包的jitter。
- 智能路由和选路,根据OAM数据信息,可以得知网络中的每一条链路的时延、带宽以及丢包情况,那么就可以根据这些数据进行智能选路,将一些重要的流量进行重新reroute。
但是INT技术同样带来一些显而易见的缺点,以传统的INT技术,也就是思科的IOAM为例:
- DCN网络或者是运营商网络中,数据包数量巨大,对每一个数据包进行插入OAM层,并进行监测,会产生巨量的信息,这么多巨量的信息该如何压缩、去重分析?
- ”起点设备“(在INT技术中被称为encapsulation node)要对每一个数据包进行插入一个新的OAM层,这会产生巨大的性能消耗,如果是转发设备的转发过程是软件实现的,那对转发性能更是毁灭性的打击(你需要不断的申请新的空间,并将原有的数据包进行拷贝,然后再插入一个新的层,事实上思科也注意到了这一点,所以在encapsulation node插入新的OAM层时有两种实现,这点以后在详细分析INT时再说)。
- 转发设备需要不停的将探测数据插入到数据包内部,并对数据包的checksum需要重新计算,同样是一个性能消耗点。
- IOAM技术中,转发节点会不断的向hdr与payload间插入OAM层,那么考虑到数据包会被分片,OAM层的长度必然有限制,也进一步等于OAM数据包所经过的转发设备(在IOAM技术中,这些转发设备所组成的域称之为OAM域,OAM domain)不能太多。
IOAM的软件实现可以去看VPP的源代码,VPP 17.xx版本以后的版本中都带有IPv6的IOAM实现。
【PBT】
PBT(Postcards-Based Telemetry)技术本质上也是INT技术,是由华为提出的一种基于思科IOAM技术的”升级版“,可以理解为一种优化版,华为主要是针对IOAM缺陷中的第2条、第3条以及第4条进行了优化,并且华为推出了两种优化版,一种是PBT-I,另外一种是PBT-M,前者为超级版,后者为兼容版。那么PBT是怎么做的呢?其实PBT的优化有点类似与之前说的主动探测的包注入技术。既然PBT技术本质上和IOAM技术并无不同,同样拿海豚的例子来举例:
- IOAM:一条海豚被海洋学家捕获,海洋学家向海豚身上装了一个探测器,探测器不能联网,但是有内置硬盘,海豚带着这个探测器游遍太平洋,每经过一片海域,探测器就会收集信息,然后一年后被海洋学家蹲点捕获,拆掉探测器,海洋学家根据探测器的内置硬盘中的数据进行分析。
- PBT:一条海豚被海洋学家捕获,海洋学家向海豚身上装了一个探测器,探测器内部没有硬盘,但是有通信模块,海豚带着这个探测器游遍太平洋,每经过一片海域,探测器就会收集信息并立刻传给远程的海洋学家的服务器,海洋学家根据服务器接收的数据就可以分析,或者是可以先将数据存储到数据中心,等一年过后,海洋学家捕获了海豚,考虑到保护海洋动物的责任感,拆除了探测器,并根据数据中心完整的数据进行分析。
可以看到,PBT和IOAM技术最大的不同是PBT是没有携带OAM探测数据的,而是没经过一个转发节点(严格来说是OAM域内的translate node)都会立刻上传信息,具体如PBT-I技术的实现原理可以如图9所示。

图9.PBT-I技术的实现原理
那么PBT-T的原理叙述如下,数据包经过OAM域(可以理解为INT的监测域),并进入“起始节点”(encapsulation node),起始节点对数据包进行标记,注意这里是标记,并不是插入OAM层,和主动探测中的包注入技术相同,那么被标记的数据包,接下来可以称之为PBT探测数据包,接下来PBT探测数据包经过OAM域中每一个网络设备(translation node),传输节点都会去检查数据包中的标记位,观察是否时PBT探测数据包,如果是PBT探测数据包,则立刻上传监测数据。
但是这里仍然有一个问题,既然从原始的IOAM数据包的“监测模板” + “监测数据”缩小到只有1个bit的标记位,那么设备怎么知道要收集并上传那些信息呢?这个地方可以通过类似于ipfix的模板来实现,也就是实现管里面或者控制面向OAM域中的每一个传输节点下配置通知收集哪些信息。这样的话,管控面需要对OAM域中的所有节点下发数据收集的模板配置,而不像IOAM一样,只需要给encapsulation node下发数据收集的模板配置就好了。
那么根据上述的原理介绍,我们至少可以知道,PBT-I相较于IOAM做了如下几种较为明显的改进:
- 收集的数据多少不再受限于数据包的长度,因为收集的数据不再插入在数据包的内部。
- 不用对每一个数据包进行十分浪费性能的插入收集数据,重新计算checksum等操作,对于ipv4数据包,只需要看一下ipv4 header中的标记为,例如TOS中的reserve bit,就可以知道要上传哪些信息。
光这两点改进,其实就已经是质变了,尤其是第二条的改进,大大的增加了INT技术在软件转发平台上的可行性(软件实现的转发平台最怕的就是对数据包进行重新分配内存+内存拷贝+重新计算checksum,这些会带来大量的性能消耗),但是世界上没有一种完美的技术,PBT-I技术的改进同样带来了其他的缺点:
- 管控面需要对OAM域中所有的节点下发模板配置信息,告知OAM域中的节点碰见PBT探测数据包要上报哪些信息。
- 由于没经过一个translate node都需要上传信息,所以上传的信息次数会进一步变多,这样同样带来了某一个节点上传的信息丢失的风险。
- 需要时间同步和信息重组,即一个PBT探测数据包经过了n个网元,如何将这n个网元上传的信息进行联系组装。
- 不灵活,没办法定制化,例如网络中有A、B、C、D、E五条流,其中我需要对A、B两条流收集的信息集合为M,对C、D、E三条流收集的信息集合为N。但是标记位只有一个,没有办法进行更细粒度的进行区分。
虽然带来了这几个缺点,但是PBT-I的改进确实让人看到了软件实现INT技术的可行性。说完了PBT-I,接着说说“折中版”PBT-M,华为提出的draft中同样承认了PBT-I技术做得太绝,导致了上述几个问题的出现,那么能不能稍微做的不那么绝,来个折中点的方案呢?所以就来了PBT-M这种折中版本。
PBT-M相较于PBT-I技术,没有完全舍弃OAM层,而相比于IOAM技术,又放弃了在OAM层中插入探测数据,因此PBT-M就是相当于IOAM与PBT-I的折中,即:
数据包第一次经过encapsulation node,同样会插入OAM层,但是,直插入instruction,不插入data,相当于只插入收集指令,用于告知当前PBT探测数据包经过的每一个网元,要给这个数据包收集什么样的信息,然后再将这个信息导出至远程的分析服务器。那么根据这个特征,我们可以知道,实际上PBT-M时对PBT-T的4条缺点中的1、4进行了优化,管控面只需要给encapsulation node下发配置即可,举个例子,网络中有A、B、C、D、E五条流,其中我需要对A、B两条流收集的信息集合为M,对C、D、E三条流收集的信息集合为N。A、B两条流的数据包经过encapsulation node时,encapsulation node根据管控面下发的配置,对A、B中插入OAM层,instruction为M,对C、D、E插入OAM层,instruction为N,倘若A流的数据包经过translation node时,translation node根据内置的OAM层中的instruction M就知道该上传instruction M所对应的数据,这样灵活性大大加强。不过PBT-M这种折中版仍然会带来IOAM技术中的缺点2,也就是encapsulation node需要对这个数据包插入OAM层,对软件实现来说仍然不友好。
【总结-说一说我自己的一些看法】
- 主动包注入技术只能排查当前正在发生的一些网络故障,因此局限性较大,但是性能消耗小且易用,但是诊断的粒度很细,可以立刻得到网络中正在发生的故障、故障位置以及故障原因
- Netflow或是IPFIX这种传统的基于流的被动网络探测技术,相较于主动探测技术性能消耗要大,并且存在测不准有误差的情况,粒度也不尽人意,但是作为一种监控出身的技术,仍然是主流且容易实现的一种技术。
- INT技术对于网络探测可以说是吊打Netflow或是IPFIX这种基于流的被动监测技术,但是INT技术中的IOAM技术目前看来不适合软件实现,当然barefoot推出了支持INT技术的转发芯片,让IOAM技术可以得以应用,不过芯片的价格感人,据说一片要8000刀(去抢吧...),目前barefoot已经被intel收购,后续什么情况还犹未可知,目前IOAM这种INT技术的具体实现更多的都是基于硬件实现,然后与P4编程打组合拳。
- INT技术中的PBT技术,目前对软件实现比较友好的是PBT-I,当然对于PBT-M技术而言,如果encapsulation node是支持INT的硬件转发设备,那么PBT-M的灵活性确实是要比PBT-I更胜一筹的。
唉,网络遥感技术这块领域,大佬打架,我等渣渣只能吃瓜了....
先站一个坑,以后再慢慢具体说一说这些技术的一些具体细节,以及该怎么实现。