0.发展
在hive公布源代码之后
公司又公布了presto,这个比较快,是基于内存的。
impala:3s处理1PB数据。
1.Hive 能做什么,与 MapReduce 相比优势在哪里
关于hive这个工具,hive学习成本低,入手快,对于熟悉sql语法的人来说,操作简单,熟悉。
其实,还有一个,就是统一的数据管理,可与impala/spark等共享元数据。
2.为什么说 Hive 是 Hadoop 数据仓库,从【数据存储和分析】方 面理解
对于有固定格式的文件,使用HIVE把他存储到HDFS上,然后使用hive操作这些数据,语句执行依赖hadoop,这就是hive的由来。
所以说,Hive是建立在hadoop之上的。
下面具体说明一下:
1.hive构建在Hadoop之上,所有的数据存储在hadoop中hdfs上。
2.分析数据查询数据都是讲任务转化为底层的MapReduce模板,在hadoop上运行。
3.执行的程序可以在yarn上运行。
正是因为hive是hadoop的数据仓库,所以,也有了hive的其他特点:
1.优势在于处理大数据
2.Hive适合离线情况,所以延迟情况比较大。
3.扩张性较好,可以自定义数据类型
3.hive补充
将结构化的结构映射成表。
本质,将SQL转换成mapreduce,也算是hadoop的客户端,不干事情。
4. Hive 架构,分为三个部分来理解,最好通过画图理解
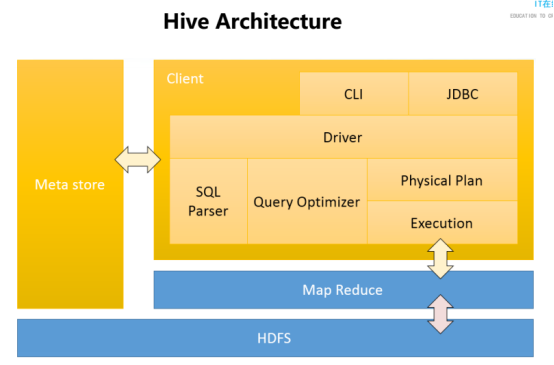
Hive分为Meta store,HDFS,Client三部分。
1.Meta srore 是元数据,默认存储在derby数据库,建议修改配置时修改。
2.HDFS,说明hive的数据存储在很多粉丝上。
3.Client:用户的接口是Cli。通过JDBC链接Driver驱动。
Sql parser是SQL解析器
Query optimizer是优化器。
Physical plan是物理计划。
一步步执行,生成的物理计划,存储在HDFS 上,并随后有mapreduce调用执行。
5.扩展性与灵活性
比较好,因为支持UDF,自定义存储格式。
同时,可以扩展集群规模。
6.总结
构建在hadoop之上的数据仓库
使用HQL作为查询接口,使用HBase存储,使用mapreduce进行计算。