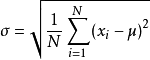1. sklearn.preprocessing.scale 怎么算的,示例:
from sklearn import preprocessing
import numpy as np
X_train = np.array([[ 1., -1., 2.], [ 2., 0., 0.], [ 0., 1., -1.]]))
X_train
array([[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.]])
执行X_train.scale()后,得到
array([[ 0. , -1.22474487, 1.33630621], [ 1.22474487, 0. , -0.26726124], [-1.22474487, 1.22474487, -1.06904497]])
解释:将数据转化为标准正态分布。默认按特征列,以均值为中心,以分量为单位方差。
对应公式: (X - mean) / std 。其中 mean是平均值,std是标准差(方差的平方根)。
标准差的公式又是: std=sqrt(((x1-x)^2 +(x2-x)^2 +......(xn-x)^2)/n) ,其中 x 是均值。公式又如下图