ActiveMQ原理
这篇文章:https://www.cnblogs.com/wuzhenzhao/p/10084058.html
ActiveMQ 主从数据复制
死锁
死锁条件:
1.互斥条件:进程对于所分配到的资源具有排它性,即一个资源只能被一个进程占用,直到被该进程释放
2.请求和保持条件:一个进程因请求被占用资源而发生阻塞时,对已获得的资源保持不放。
3.不剥夺条件:任何一个资源在没被该进程释放之前,任何其他进程都无法对他剥夺占用
4.循环等待条件:当发生死锁时,所等待的进程必定会形成一个环路(类似于死循环),造成永久阻塞。
怎么防止死锁:
1.尽量采用tryLock(timeout)的方法,可以设置超时时间,这样超时之后,就可以主动退出,防止死锁(关键)
2.减少同步代码块嵌套操作
3.降低锁的使用粒度,不要几个功能共用一把锁
怎么查看生产堆栈信息 JDK提供了什么工具
jps -lvm 用于查看当前机器上运行的java进程。
我们使用 jstack -l pid查看我们的应用堆栈信息,同时可以看到死锁信息。
Redis主从怎么复制数据:
这篇文章:https://www.cnblogs.com/luao/p/10682830.html
游标是用来干什么的?
游标(Cursor)是处理数据的一种方法,为了查看或者处理结果集中的数据,游标提供了在结果集中一次一行或者多行前进或向后浏览数据的能力。
聚集索引和非聚集索引
聚集索引和非聚集索引的根本区别是表记录的排列顺序和与索引的排列顺序是否一致,聚集索引表记录的排列顺序与索引的排列顺序一致,优点是查询速度快,因为一旦具有第一个索引值的纪录被找到,具有连续索引值的记录也一定物理的紧跟其后。聚集索引的缺点是对表进行修改速度较慢,这是为了保持表中的记录的物理顺序与索引的顺序一致,而把记录插入到数据页的相应位置,必须在数据页中进行数据重排,降低了执行速度。建议使用聚集索引的场合为:
a.此列包含有限数目的不同值;
b.查询的结果返回一个区间的值;
c.查询的结果返回某值相同的大量结果集。
非聚集索引指定了表中记录的逻辑顺序,但记录的物理顺序和索引的顺序不一致
,聚集索引和非聚集索引都采用了B+树的结构,但非聚集索引的叶子层并不与实际的
数据页相重叠,而采用叶子层包含一个指向表中的记录在数据页中的指针的方式。非
聚集索引比聚集索引层次多,添加记录不会引起数据顺序的重组。建议使用非聚集索
引的场合为:
a.此列包含了大量数目不同的值;
b.查询的结束返回的是少量的结果集;
c.order by 子句中使用了该列。
线程阻塞
这篇文章:https://www.cnblogs.com/mhq-martin/p/9035640.html
队列,阻塞对列
HashMap为什么要用红黑树
https://www.jianshu.com/p/37436ed14cc6
concurrentHashMap 7和8的区别
从JDK1.7版本的ReentrantLock+Segment+HashEntry,到JDK1.8版本中synchronized+CAS+HashEntry+红黑树。
1.数据结构:取消了Segment分段锁的数据结构,取而代之的是数组+链表+红黑树的结构。
2.保证线程安全机制:JDK1.7采用segment的分段锁机制实现线程安全,其中segment继承自ReentrantLock。JDK1.8采用CAS+Synchronized保证线程安全。
3.锁的粒度:原来是对需要进行数据操作的Segment加锁,现调整为对每个数组元素加锁(Node)。
4.链表转化为红黑树:定位结点的hash算法简化会带来弊端,Hash冲突加剧,因此在链表节点数量大于8时,会将链表转化为红黑树进行存储。
5.查询时间复杂度:从原来的遍历链表O(n),变成遍历红黑树O(logN)。
https://www.cnblogs.com/liuqing576598117/p/10572764.html
CAS并发包的应用
Oracle事务
唯一索引和主键索引的区别
一 主键和唯一索引都要求值唯一,但是它们还是有区别的:
①.主键是一种约束,唯一索引是一种索引;
②.一张表只能有一个主键,但可以创建多个唯一索引;
③.主键创建后一定包含一个唯一索引,唯一索引并一定是主键;
④.主键不能为null,唯一索引可以为null;
⑤.主键可以做为外键,唯一索引不行;
二 主键约束比唯一索引约束严格,当没有设定主键时,非空唯一索引自动称为主键。对于主键和唯一索引的一些区别主要如下:
1.主键不允许空值,唯一索引允许空值
2.主键只允许一个,唯一索引允许多个
3.主键产生唯一的聚集索引,唯一索引产生唯一的非聚集索引
注:聚集索引确定表中数据的物理顺序,所以是主键是唯一的(聚集就是整理数据的意思)
联合索引有什么要注意的地方
1.单个索引需要注意的事项,组合索引全部通用。比如索引列不要参与计算啊、or的两侧要么都索引列,要么都不是索引列啊、模糊匹配的时候%不要在头部啦等等
2.最左匹配原则。(A,B,C) 这样3列,mysql会首先匹配A,然后再B,C.
3.如果用(B,C)这样的数据来检索的话,就会找不到A使得索引失效。如果使用(A,C)这样的数据来检索的话,就会先找到所有A的值然后匹配C,此时联合索引是失效的。
把最常用的,筛选数据最多的字段放在左侧。
https://blog.csdn.net/nakiri_arisu/article/details/79702461
Spring 事务
什么是事务:
事务逻辑上的一组操作,组成这组操作的各个逻辑单元,要么一起成功,要么一起失败.
原子性 (atomicity):强调事务的不可分割.
一致性 (consistency):事务的执行的前后数据的完整性保持一致.
隔离性 (isolation):一个事务执行的过程中,不应该受到其他事务的干扰
持久性(durability) :事务一旦结束,数据就持久到数据库
脏读 :一个事务读到了另一个事务的未提交的数据
不可重复读 :一个事务读到了另一个事务已经提交的 update 的数据导致多次查询结果不一致.
虚幻读 :一个事务读到了另一个事务已经提交的 insert 的数据导致多次查询结果不一致.
DEFAULT 这是一个PlatfromTransactionManager默认的隔离级别,使用数据库默认的事务隔离级别.
未提交读(read uncommited) :脏读,不可重复读,虚读都有可能发生
已提交读 (read commited):避免脏读。但是不可重复读和虚读有可能发生
可重复读 (repeatable read) :避免脏读和不可重复读.但是虚读有可能发生.
串行化的 (serializable) :避免以上所有读问题.
Mysql 默认:可重复读
Oracle 默认:读已提交
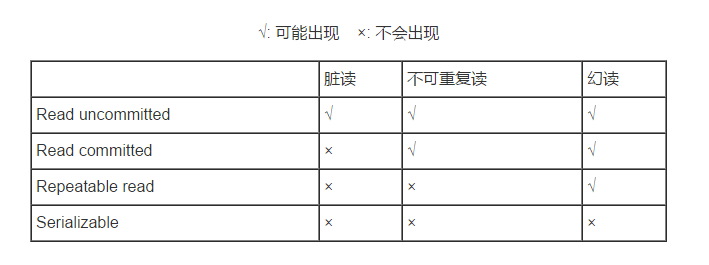
read commited:保证一个事物提交后才能被另外一个事务读取。另外一个事务不能读取该事物未提交的数据。
repeatable read:这种事务隔离级别可以防止脏读,不可重复读。但是可能会出现幻象读。它除了保证一个事务不能被另外一个事务读取未提交的数据之外还避免了以下情况产生(不可重复读)。
serializable:这是花费最高代价但最可靠的事务隔离级别。事务被处理为顺序执行。除了防止脏读,不可重复读之外,还避免了幻象读(避免三种)。
PROPAGION_XXX :事务的传播行为
* 保证同一个事务中
PROPAGATION_REQUIRED 支持当前事务,如果不存在 就新建一个(默认)
PROPAGATION_SUPPORTS 支持当前事务,如果不存在,就不使用事务
PROPAGATION_MANDATORY 支持当前事务,如果不存在,抛出异常
* 保证没有在同一个事务中
PROPAGATION_REQUIRES_NEW 如果有事务存在,挂起当前事务,创建一个新的事务
PROPAGATION_NOT_SUPPORTED 以非事务方式运行,如果有事务存在,挂起当前事务
PROPAGATION_NEVER 以非事务方式运行,如果有事务存在,抛出异常
PROPAGATION_NESTED 如果当前事务存在,则嵌套事务执行
JVM线程进来怎么分配内存
指令重排序:
两个String相加,编译后是怎样的:
两个字符串相加底层会生成StringBuilder对象,然后使用append来拼接,如果不在循环中使用,可以不用StringBuilder,
Volatile关键字
关键字volatile可以用来修饰字段,就是告知程序任何对该变量的访问均需要从共享内存中获取,而对它的改变必须同步刷新回共享内存,它能保证所有线程对变量访问的可见性。
对volatile语义的扩展保证了volatile变量在一些情况下不会重排序,volatile的64位变量double和long的读取和赋值操作都是原子的。
synchronized关键字
关键字synchronized可以修饰方法或者同步块的形式来进行使用,它主要确保多个线程在同一个时刻,只能有一个线程处于方法或者同步块中,它保证了线程对变量访问的可见性和排他性。
如何设计一个秒杀系统
https://yq.aliyun.com/articles/618443
乐观锁和悲观锁
悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库如果提供类似于write_condition机制的其实都是提供的乐观锁。
分布式锁是怎样
1、基于数据库
2、基于redis或者memcached
3、基于Zookeeper
分布式事务是怎样
Spring 切面的五种类型的通知
before after afterReturning afterThrowing around
Spring 通过IOC实现松散耦合
MyBatis缓存
mybatis的查询缓存分为一级缓存和二级缓存,一级缓存是SqlSession级别的缓存,二级缓存时mapper级别的缓存,二级缓存是多个SqlSession共享的。mybatis通过缓存机制减轻数据压力,提高数据库性能。
TCP三次握手四次挥手
https://www.cnblogs.com/zmlctt/p/3690998.html
SpringMVC工作过程
1.spring mvc所有的请求都提交给DispatcherServlet,它会委托应用系统的其他模块负责对请求进行真正的处理工作。
2.DispatcherServlet查询一个或多个HandlerMapping,找到处理请求的Controller.
3.DispatcherServlet请请求提交到目标Controller
4.Controller进行业务逻辑处理后,会返回一个ModelAndView
5.Dispathcher查询一个或多个ViewResolver视图解析器,找到ModelAndView对象指定的视图对象
6.视图对象负责渲染返回给客户端。
CopyOnWriteArrayList介绍下
CopyOnWrite容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
lambda表达式介绍下
“Lambda 表达式”(lambda expression)是一个匿名函数,Lambda表达式基于数学中的λ演算得名,直接对应于其中的lambda抽象(lambda abstraction),是一个匿名函数,即没有函数名的函数。Lambda表达式可以表示闭包(注意和数学传统意义上的不同)。
steam跟list的循环有什么区别
ReentrantLock介绍下
如何不让一个线程一直等待获取锁
负载均衡的原理
1、轮询(默认)
每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。
upstream backserver {
server 192.168.0.14;
server 192.168.0.15;
} 2、指定权重
指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。
upstream backserver {
server 192.168.0.14 weight=8;
server 192.168.0.15 weight=10;
} 3、IP绑定 ip_hash
每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。
upstream backserver {
ip_hash;
server 192.168.0.14:88;
server 192.168.0.15:80;
} 4、fair(第三方)
按后端服务器的响应时间来分配请求,响应时间短的优先分配。
upstream backserver {
server server1;
server server2;
fair;
} 5、url_hash(第三方)
按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,后端服务器为缓存时比较有效。
upstream backserver {
server squid1:3128;
server squid2:3128;
hash $request_uri;
hash_method crc32;
}
在需要使用负载均衡的server中增加
proxy_pass http://backserver/;
upstream backserver{
ip_hash;
server 127.0.0.1:9090 down; (down 表示当前的server暂时不参与负载)
server 127.0.0.1:8080 weight=2; (weight 默认为1.weight越大,负载的权重就越大)
server 127.0.0.1:6060;
server 127.0.0.1:7070 backup; (其它所有的非backup机器down或者忙的时候,请求backup机器)
}
max_fails :允许请求失败的次数默认为1.当超过最大次数时,返回proxy_next_upstream 模块定义的错误
fail_timeout:max_fails次失败后,暂停的时间
https://blog.csdn.net/qq_35119422/article/details/81505732
SpringBoot 启动的时候加载些什么?
Redis集群?哨兵?
哨兵(sentinel) 是一个分布式系统,你可以在一个架构中运行多个哨兵(sentinel) 进程,这些进程使用流言协议(gossipprotocols)来接收关于Master是否下线的信息,并使用投票协议(agreement protocols)来决定是否执行自动故障迁移,以及选择哪个Slave作为新的Master。
https://blog.csdn.net/u012240455/article/details/81843714
Java类加载机制
https://blog.csdn.net/m0_38075425/article/details/81627349
https://blog.csdn.net/shengmingqijiquan/article/details/77508471
Nginx原理
https://www.jianshu.com/p/6215e5d24553
http和https
select 加什么可以实现悲观锁?加 for update.
redis的数据结构?五种,String, Hash, list ,set , zset.
Spring 的BeanFactory和ApplicationContext有什么区别?
BeanFactory:
是Spring里面最低层的接口,提供了最简单的容器的功能,只提供了实例化对象和拿对象的功能;
ApplicationContext:
应用上下文,继承BeanFactory接口,它是Spring的一各更高级的容器,提供了更多的有用的功能;
1) 国际化(MessageSource)
2) 访问资源,如URL和文件(ResourceLoader)
3) 载入多个(有继承关系)上下文 ,使得每一个上下文都专注于一个特定的层次,比如应用的web层
4) 消息发送、响应机制(ApplicationEventPublisher)
5) AOP(拦截器)
两者装载bean的区别
BeanFactory:
BeanFactory在启动的时候不会去实例化Bean,中有从容器中拿Bean的时候才会去实例化;
ApplicationContext:
ApplicationContext在启动的时候就把所有的Bean全部实例化了。它还可以为Bean配置lazy-init=true来让Bean延迟实例化;
hash碰撞
通常有两类方法处理碰撞:开放寻址(Open Addressing)法和链接(Chaining)法。
常见的加密算法
SQL查询的深分页问题
拦截器和AOP的区别
Redis的事务操作
HTTPS和HTTP的区别
HTTPS和HTTP的区别主要如下:
1、https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
2、http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全