网络化部署一直是我非常想做的,现在已经基本看到了门路。今天早上实验,发现在手机上的支持也非常好(对于相机的支持还差一点),证明B/S结构的框架是非常有生命力的。下一步就是要将这个过程深化、总结,并且封装出来。我罗列了以下具体工作,分为三天完成
1、如何将服务长期运行;
2、将cbir模型移植过来,解决垂直领域问题;
3、B/S方式是未来,学习现有框架中B/S的构建方法,还需要一些修改界面的知识;
4、webapi的实现原理;
5、styletransform模型移植,特别是手机;
6、docker离线,实验;
7、成为服务,blog,发布出去;
现在我们已经有很棒的cbir分类了,下一步我会进一步将其优化成多个服务的模式。现在是研究styletransform的时候了。
5、styletransform模型移植,特别是手机;
sf 一直是我一直以来最想实现的一个效果,好在最新版本的sf直接就带了这样一个可以运行的例子,并且直接可以运行
python neural_style_transfer.py
第一个参数-你的基图像路径
第二个参数-你的风格图像路径
第三个参数-你要保存的生产图片路径加名称(注意不需要有.jpg后缀)
第一个参数-你的基图像路径
第二个参数-你的风格图像路径
第三个参数-你要保存的生产图片路径加名称(注意不需要有.jpg后缀)
例:
python neural_style_transfer.py '/home/xxx/Documents/Test/tiananmen.png' '/home/xxx/Documents/Test/fangao.jpg' '/home/xxx/Documents/Test/tiananmen_fangao'

最后的结果是这样,有点意思。现在的问题就是速度太慢了,无法达到prisma准实时的效果。(啊,嘴巴好红)
5.2如何查看服务器的数据
现在存在的问题是,大量的数据运算都需要依赖服务器;而我现在服务器又无法直接看到,所以需要搭建一个服务。
winscp完全解决这个问题,很好
可以发现,一旦项目落地,网络传输的实际问题就会被提出来,可能必须在开始的时候就需要考虑图像的压缩。但是现在还不思考这个问题。
5.3现在就是需要修改界面,能够将这一套上传上去,再显示出来。
5.4更重要的问题是,现有的运算条件,无法支持实时运算(实际上vps就不给运算)。有什么提速方法吗?
参考相关资料,肯定是需要预先训练模型的。而且这个模型不仅仅是vgg模型,而是将迁移后的结果已经放在里面的模型,这样速度才能够快。
也就是现在找到的代码,还没有完全解决问题。我需要的,仍然是更强的预训练算法。
这里我找到的是 fast-neural-style-tensorflow
提供了更多资料。
5.5那么,首先如何在应用层次上面解决问题?
运行它的命令,可以得到这样的图片(信大内湖)效果是不错,但是即使是应用层次的,我也想能够训练一个自己想要的图片的。
python eval.py --model_file <your path to wave.ckpt-done> --image_file img/test.jpg

最近在关心穆夏,那么就训练这个吧。

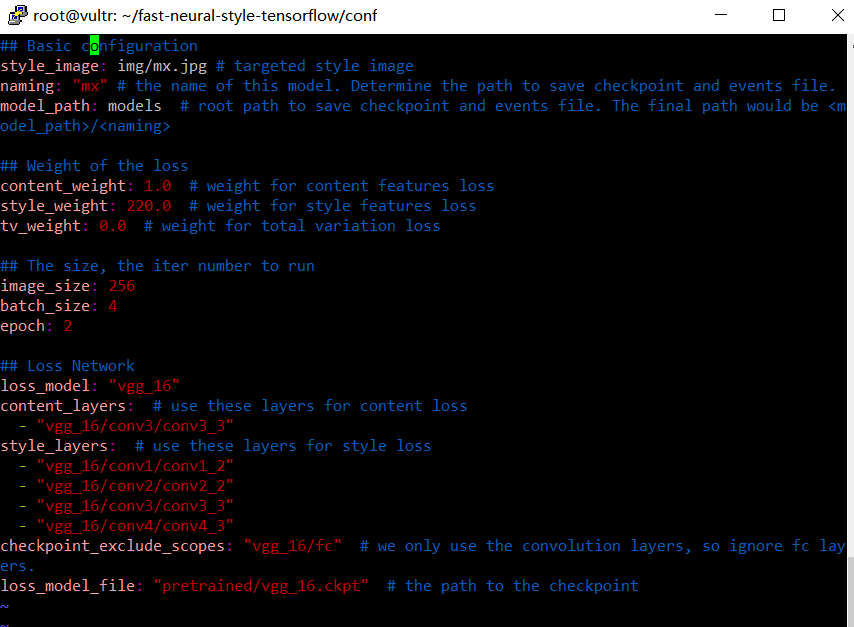
模型中wave.yml是配置文件,比如
## Basic configuration
style_image: img/wave.jpg # targeted style image
naming: "wave" # the name of this model. Determine the path to save checkpoint and events file.
model_path: models # root path to save checkpoint and events file. The final path would be <model_path>/<naming>
## Weight of the loss
content_weight: 1.0 # weight for content features loss
style_weight: 220.0 # weight for style features loss
tv_weight: 0.0 # weight for total variation loss
## The size, the iter number to run
image_size: 256
batch_size: 4
epoch: 2
## Loss Network
loss_model: "vgg_16"
content_layers: # use these layers for content loss
- "vgg_16/conv3/conv3_3"
style_layers: # use these layers for style loss
- "vgg_16/conv1/conv1_2"
- "vgg_16/conv2/conv2_2"
- "vgg_16/conv3/conv3_3"
- "vgg_16/conv4/conv4_3"
checkpoint_exclude_scopes: "vgg_16/fc" # we only use the convolution layers, so ignore fc layers.
loss_model_file: "pretrained/vgg_16.ckpt" # the path to the checkpoint
style_image: img/wave.jpg # targeted style image
naming: "wave" # the name of this model. Determine the path to save checkpoint and events file.
model_path: models # root path to save checkpoint and events file. The final path would be <model_path>/<naming>
## Weight of the loss
content_weight: 1.0 # weight for content features loss
style_weight: 220.0 # weight for style features loss
tv_weight: 0.0 # weight for total variation loss
## The size, the iter number to run
image_size: 256
batch_size: 4
epoch: 2
## Loss Network
loss_model: "vgg_16"
content_layers: # use these layers for content loss
- "vgg_16/conv3/conv3_3"
style_layers: # use these layers for style loss
- "vgg_16/conv1/conv1_2"
- "vgg_16/conv2/conv2_2"
- "vgg_16/conv3/conv3_3"
- "vgg_16/conv4/conv4_3"
checkpoint_exclude_scopes: "vgg_16/fc" # we only use the convolution layers, so ignore fc layers.
loss_model_file: "pretrained/vgg_16.ckpt" # the path to the checkpoint
看上去是如何训练的基础方法。但是它需要下载整个coco来进行训练,也就是将vgg重新迅雷一下。这样所谓的wave-ckpt其实就是一个简化版的vgg,而不是模型迁移,整个就是模型重新训练。这个概念是之前没有的。
这个是12.6g,,让vps下一会吧,这里要把相关资料都整理一下。
如果在学习tensorflow的过程中,想使用tensorboard,但是由于本地主机计算性能等的局限性,很多时候我们都是在远程服务器上运行tensor flow并训练相关模型,所以学会相关远程的操作至关重要,主要是ssh命令和scp命令,这里我们只简述一下如何访问远程的tensor board。
但是也有一种说法是,tensorboar开在0.0.0.0上,如果是这样的话外面不是就可以直接访问吗?
过程
在登录远程服务器的时候使用命令:
ssh -L 16006:127.0.0.1:6006 account@server.address
(代替一般ssh远程登录命令:ssh account@server.address)
训练完模型之后使用如下命令:
tensorboard --logdir="/path/to/log-directory"
(其中,/path/to/log-directory为自己设定的日志存放路径,因人而异)
最后,在本地访问地址:http://127.0.0.1:16006/
建立ssh隧道,实现远程端口到本地端口的转发
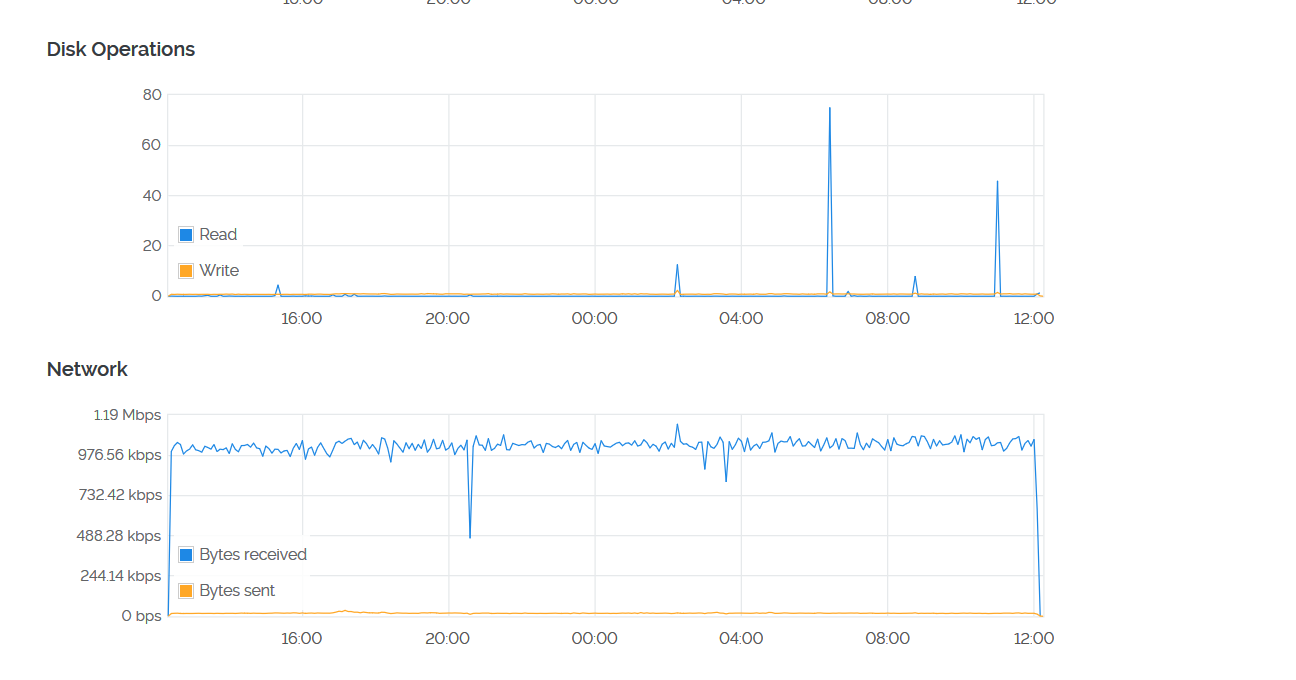
具体来说就是将远程服务器的6006端口(tensorboard默认将数据放在6006端口)转发到本地的16006端口,在本地对16006端口的访问即是对远程6006端口的访问,当然,转发到本地某一端口不是限定的,可自由选择。现在就是等待下载完成了,要等到明天晚上开始来做。
OK,现在是晚上了,那么下载下来的12.6g是否完整了
网络的使用上,是已经结束了
实际看上去,也确实是下载完了(我想要一个可以脱机随便下载的地方)
但是硬盘是明显不够了
选择直接升级的方式

首先是做快照,后面可能还会给换回来,但是至少是整个实验完成后。
OK! NICE
开始训练
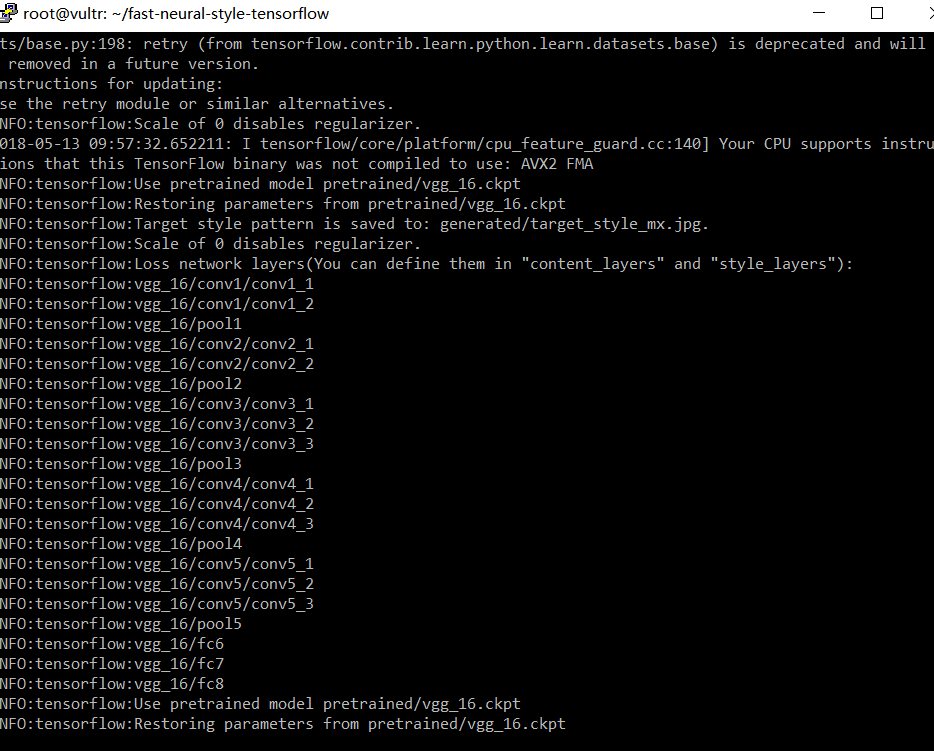
仍然是被killed掉了
 现在的瓶颈应该主要是内存,如果是这样那还是比较好解决的。但是目前即使成功地进行了转换,也还是需要相当长的时间来进行跟踪研究,并且找到产业化部署的方法,让这个工具和平台能够真正发展下去。我一定会去做成的,但现在还有其它一些东西需要去关心。
现在的瓶颈应该主要是内存,如果是这样那还是比较好解决的。但是目前即使成功地进行了转换,也还是需要相当长的时间来进行跟踪研究,并且找到产业化部署的方法,让这个工具和平台能够真正发展下去。我一定会去做成的,但现在还有其它一些东西需要去关心。在调小batch_size之后,能够训练

但是需要多少时间了?原来的github似乎给出了一个新的方法:
就是查看tensorboard
目前还看不懂,但是不重要,训练已经开始了。将其搞成后台运行的。
用到了爆表,这就对了
{kind=link}