注意,本文中所指“机器学习"(ML)技术,特指SVM、随机森林等”传统“技术。
一、应用场景
相比较当下发展迅速的各路“端到端”技术,SVM、随机森林等”传统“技术它的应用价值,在于”以更贴合现有系统的方式提供一种识别的途径“。比如你使用tf、keras或者openvino,那么首先你需要按照这些平台的方式搭建一个运行环境并且编写相关的接口,而后在现有系统中调用这个接口,获得一个定量的分类。如果对结果不满意,那么能够做的首先是对参数的调节、对模型的重新分类。包括OpenCV自己的DNN也是类似的方式。这些都需要并且依赖训练成功的识别模型,但是在现实的识别项目中,能够获得的标注结果是随着项目进展而不断出现的,在这种情况下,我们更需要的是”一种能够对现有识别进行验证的方法“,这个时候“机器学习"(ML)技术足够使用。
Opencv支持的机器学习算法(参考《学习OpenCV4》)
| 算法名称 | 描述 |
| Mahalanobis | 通过除以协方差来对数据空间进行变换,由此得到一个标志着空间拉伸程度的距离度量。如果协方差矩阵是单位矩阵,那么这个度量等价于欧氏距离[Mahalanobis36]。 |
| K-均值算法 | 这是一种非监督的聚类方法,用k个聚类中心表示数据的分布,k的大小由用户定义。该方法与期望最大化算法(expectation maximization)的区别在于k-均值的中心不是符合高斯分布的。而由于每个聚类中心都竞争着去俘获与之距离较近的点,所以聚类的结果更像是肥皂泡,聚类区域经常被用作稀疏直方图的bin,用来描述数据。该方法由Steinhaus [Steinhaus56]提出,由Lloyd [Lloyd57]推广。 |
| 正态/朴素贝叶斯 | 这是一个生成式的分类器。它假设特征符合高斯分布且在统计学上服从独立同分布。但是这个过于苛刻的假设在很多情况下是不能满足的。因此,它又被称为“朴素”贝叶斯分类器。尽管如此,在许多情况下,这个方法的效果却出奇的好。该方法最早出自[Maron61; Minsky61] |
| 决策树 | 这是一个判别分类器。该树在当前节点通过寻找数据特征和一个阈值来实现数据到不同类别的最优划分。处理流程是不断将数据进行划分,然后下降到树的左侧子节点或者右侧子节点。虽然该算法的性能不是最好的,但往往是测试时的首选,因为它运行速度快,性能好。[Breiman84] |
| 期望最大化算法(EM) | 这是一种用于聚类的无监督生成算法。它会用N维高斯分布去拟合数据,其中N的大小是由用户自己定义的。这样仅仅用很少的几个参数(方差和均值)就可以表示一个较为复杂的数据分布。该方法经常用于分割,它与k-均值算法的比较见文献[Dempster77]。 |
| Boosting | 它是由一组判别分类器组成。最终的决策是由组成它的各个分类器的加权组合来决定。在训练中,逐个训练子分类器。且每个子分类器都是弱分类器(性能上只是优于随机选择)。这些弱分类器由单变量决策树构成,被称为“桩(stumps)”。在训练中,决策桩(decision stump)不仅从数据中学习分类决策而且根据预测精度学习“投票”的权重。当训练下一个分类器的时候,数据样本的权重会被重新分配。使之能够给予分错的数据更多的注意力。训练过程不停地执行,直到总错误(加权组合所有决策树组成的分类器产生的错误)低于某个已经设置好的阈值。为了达到好的效果,这个方法通常需要很大量训练的训练数据[Freund97]。 |
| 随机森林 | 它是由许多决策树组成的“森林”,每个决策树向下递归以获取最大深度。在学习过程中,每棵树的每个节点只从特征数据的一个随机子集中选择。这保证了每棵树是统计意义上不相关的分类器。在识别过程中,将每棵树的结果进行投票来确定最终结果,每棵树的权重相同。这个分类器方法经常很有效,而且对每棵树的输出进行平均,可以处理回归问题[Ho95; Criminisi13; Breiman01]。 |
| K近邻 | K近邻可能是最简单的分类器。训练数据跟类别标签存放在一起,离测试数据最近的(欧氏距离最近)K个样本进行投票,确定测试数据的分类结果。该方法通常比较有效,但是速度比较慢且对内存需求比较大[Fix51],详见FLANN 入口 |
| 快速近似最近邻算法(FLANN)a | Opencv包含了完整的快速近似最近邻算法函数库,该库由Marius Muja开发,可实现K近邻的快速近似和匹配[Muja09]。 |
| 支持向量机(SVM) | 它可以进行分类,也可以进行回归。该算法需要定义一个高维空间中任两点的距离函数。(将数据投影到高维空间会使数据更容易地线性可分。)该算法可以学习一个分类超平面,用来在高维空间里实现最优分类器。当数据有限的时候,该算法可以获得非常好的性能,而boosting和随机森林只能在拥有大量训练数据b时才有好的效果。 |
| 人脸识别/级联分类器 | 这个物体检测算法巧妙地使用了boosting算法。OpenCV提供了正面人脸检测的检测器,它的检测效果非常好。你可以使用OpenCV提供的训练算法,也可以使用这个分类器提取你自己想要的特征或使用其他的特征,使之能够检测其他物体。该算法非常擅长检测特定视角的刚性物体。这个分类器也俗称“Viola-Jones分类器”,这是以它发明者的名字命名的(Viola04)。 |
| Waldboost | 它是Viola 算法的衍生算法(参见上一条),Waldboost是一个非常快的目标检测器,它在一系列任务中的表现都要优于传统的级联分类器 (Sochman05)。它存在于在…/ opencv_contrib /模块中。 |
| 隐变量支持向量机 | 隐变量支持向量机是一个局部模型。通过识别目标的各个独立部分并学习一个模型去发现这些部分之间联系来识别复杂目标[Felzenszwalb10]。 |
| 词袋模型 | 词袋模型是在文档分类和视觉图像分类中都有大量应用的技术。该算法功能强大,因为它不仅可以用来b识别单个目标,还可以用来识别场景和环境。 |
并且提供了StatModel作为Opencv中的标准学习模型,现在ML库中的例程都是在公共基类cv::ml::StatModel的派生类中实现。 这个基类定义了可用于所有算法的通用接口。(具体请参考 https://docs.opencv.org/master/db/d7d/classcv_1_1ml_1_1StatModel.html)
二、技术细节
以easyPr中使用SVM识别”图像中是否存在车牌“为例,说明相关技术的使用:
#include "pch.h"
#include <iostream>
#include <string>
#include <cstring>
#include <cstdlib>
#include <vector>
#include "gocvhelper.h"
using namespace std;
using namespace cv;
//解决具体的“判定当前图片中是否存在车牌”问题,使用SVM方法。
typedef enum {
kForward = 1, // correspond to "has plate"
kInverse = 0 // correspond to "no plate"
} SvmLabel;
typedef struct {
std::string file;
SvmLabel label;
} TrainItem;
std::vector<TrainItem> train_file_list_;
std::vector<TrainItem> test_file_list_;
std::vector<std::string> getFiles(const std::string &folder,const bool all = true ) {
std::vector<std::string> files;
std::list<std::string> subfolders;
subfolders.push_back(folder);
while (!subfolders.empty()) {
std::string current_folder(subfolders.back());
if (*(current_folder.end() - 1) != '/') {
current_folder.append("/*");
}
else {
current_folder.append("*");
}
subfolders.pop_back();
struct _finddata_t file_info;
auto file_handler = _findfirst(current_folder.c_str(), &file_info);
while (file_handler != -1) {
if (all &&
(!strcmp(file_info.name, ".") || !strcmp(file_info.name, ".."))) {
if (_findnext(file_handler, &file_info) != 0) break;
continue;
}
if (file_info.attrib & _A_SUBDIR) {
// it's a sub folder
if (all) {
// will search sub folder
std::string folder(current_folder);
folder.pop_back();
folder.append(file_info.name);
subfolders.push_back(folder.c_str());
}
}
else {
// it's a file
std::string file_path;
// current_folder.pop_back();
file_path.assign(current_folder.c_str()).pop_back();
file_path.append(file_info.name);
files.push_back(file_path);
}
if (_findnext(file_handler, &file_info) != 0) break;
} // while
_findclose(file_handler);
}
return files;
}
const char* plates_folder_ = "E:/代码资源/EasyPR/resources/train/svm";
void prepare() {
srand(unsigned(time(NULL)));
char buffer[260] = { 0 };
sprintf_s(buffer, "%s/has/train", plates_folder_);
auto has_file_train_list = getFiles(buffer);
std::random_shuffle(has_file_train_list.begin(), has_file_train_list.end());
sprintf_s(buffer, "%s/has/test", plates_folder_);
auto has_file_test_list = getFiles(buffer);
std::random_shuffle(has_file_test_list.begin(), has_file_test_list.end());
sprintf_s(buffer, "%s/no/train", plates_folder_);
auto no_file_train_list = getFiles(buffer);
std::random_shuffle(no_file_train_list.begin(), no_file_train_list.end());
sprintf_s(buffer, "%s/no/test", plates_folder_);
auto no_file_test_list = getFiles(buffer);
std::random_shuffle(no_file_test_list.begin(), no_file_test_list.end());
fprintf(stdout, ">> Collecting train data...
");
for (auto file : has_file_train_list)
train_file_list_.push_back({ file, kForward });
for (auto file : no_file_train_list)
train_file_list_.push_back({ file, kInverse });
fprintf(stdout, ">> Collecting test data...
");
for (auto file : has_file_test_list)
test_file_list_.push_back({ file, kForward });
for (auto file : no_file_test_list)
test_file_list_.push_back({ file, kInverse });
}
//特征提取
float countOfBigValue(Mat &mat, int iValue) {
float iCount = 0.0;
if (mat.rows > 1) {
for (int i = 0; i < mat.rows; ++i) {
if (mat.data[i * mat.step[0]] > iValue) {
iCount += 1.0;
}
}
return iCount;
}
else {
for (int i = 0; i < mat.cols; ++i) {
if (mat.data[i] > iValue) {
iCount += 1.0;
}
}
return iCount;
}
}
Mat ProjectedHistogram(Mat img, int t, int threshold) {
int sz = (t) ? img.rows : img.cols;
Mat mhist = Mat::zeros(1, sz, CV_32F);
for (int j = 0; j < sz; j++) {
Mat data = (t) ? img.row(j) : img.col(j);
mhist.at<float>(j) = countOfBigValue(data, threshold);
}
// Normalize histogram
double min, max;
minMaxLoc(mhist, &min, &max);
if (max > 0)
mhist.convertTo(mhist, -1, 1.0f / max, 0);
return mhist;
}
Mat getHistogram(Mat in) {
const int VERTICAL = 0;
const int HORIZONTAL = 1;
// Histogram features
Mat vhist = ProjectedHistogram(in, VERTICAL,20);
Mat hhist = ProjectedHistogram(in, HORIZONTAL,20);
// Last 10 is the number of moments components
int numCols = vhist.cols + hhist.cols;
Mat out = Mat::zeros(1, numCols, CV_32F);
int j = 0;
for (int i = 0; i < vhist.cols; i++) {
out.at<float>(j) = vhist.at<float>(i);
j++;
}
for (int i = 0; i < hhist.cols; i++) {
out.at<float>(j) = hhist.at<float>(i);
j++;
}
return out;
}
void getHistogramFeatures(const Mat& image, Mat& features) {
Mat grayImage;
cvtColor(image, grayImage, cv::COLOR_RGB2GRAY);
//grayImage = histeq(grayImage);
Mat img_threshold;
threshold(grayImage, img_threshold, 0, 255, cv::THRESH_OTSU + cv::THRESH_BINARY);
//Mat img_threshold = grayImage.clone();
//spatial_ostu(img_threshold, 8, 2, getPlateType(image, false));
features = getHistogram(img_threshold);
}
void getColorFeatures(const Mat& src, Mat& features) {
Mat src_hsv;
//grayImage = histeq(grayImage);
cvtColor(src, src_hsv, cv::COLOR_BGR2HSV);
int channels = src_hsv.channels();
int nRows = src_hsv.rows;
// consider multi channel image
int nCols = src_hsv.cols * channels;
if (src_hsv.isContinuous()) {
nCols *= nRows;
nRows = 1;
}
const int sz = 180;
int h[sz] = { 0 };
uchar* p;
for (int i = 0; i < nRows; ++i) {
p = src_hsv.ptr<uchar>(i);
for (int j = 0; j < nCols; j += 3) {
int H = int(p[j]); // 0-180
if (H > sz - 1) H = sz - 1;
if (H < 0) H = 0;
h[H]++;
}
}
Mat mhist = Mat::zeros(1, sz, CV_32F);
for (int j = 0; j < sz; j++) {
mhist.at<float>(j) = (float)h[j];
}
// Normalize histogram
double min, max;
minMaxLoc(mhist, &min, &max);
if (max > 0)
mhist.convertTo(mhist, -1, 1.0f / max, 0);
features = mhist;
}
void getHistomPlusColoFeatures(const Mat& image, Mat& features) {
Mat feature1, feature2;
getHistogramFeatures(image, feature1);
getColorFeatures(image, feature2);
hconcat(feature1.reshape(1, 1), feature2.reshape(1, 1), features);
}
void test(cv::Ptr<cv::ml::SVM> svm_) {
if (test_file_list_.empty()) {
prepare();
}
double count_all = test_file_list_.size();
double ptrue_rtrue = 0;
double ptrue_rfalse = 0;
double pfalse_rtrue = 0;
double pfalse_rfalse = 0;
for (auto item : test_file_list_) {
auto image = cv::imread(item.file);
if (!image.data) {
std::cout << "no" << std::endl;
continue;
}
cv::Mat feature;
getHistomPlusColoFeatures(image, feature);
auto predict = int(svm_->predict(feature));
//std::cout << "predict: " << predict << std::endl;
auto real = item.label;
if (predict == kForward && real == kForward) ptrue_rtrue++;
if (predict == kForward && real == kInverse) ptrue_rfalse++;
if (predict == kInverse && real == kForward) pfalse_rtrue++;
if (predict == kInverse && real == kInverse) pfalse_rfalse++;
}
std::cout << "count_all: " << count_all << std::endl;
std::cout << "ptrue_rtrue: " << ptrue_rtrue << std::endl;
std::cout << "ptrue_rfalse: " << ptrue_rfalse << std::endl;
std::cout << "pfalse_rtrue: " << pfalse_rtrue << std::endl;
std::cout << "pfalse_rfalse: " << pfalse_rfalse << std::endl;
double precise = 0;
if (ptrue_rtrue + ptrue_rfalse != 0) {
precise = ptrue_rtrue / (ptrue_rtrue + ptrue_rfalse);
std::cout << "precise: " << precise << std::endl;
}
else {
std::cout << "precise: "
<< "NA" << std::endl;
}
double recall = 0;
if (ptrue_rtrue + pfalse_rtrue != 0) {
recall = ptrue_rtrue / (ptrue_rtrue + pfalse_rtrue);
std::cout << "recall: " << recall << std::endl;
}
else {
std::cout << "recall: "
<< "NA" << std::endl;
}
double Fsocre = 0;
if (precise + recall != 0) {
Fsocre = 2 * (precise * recall) / (precise + recall);
std::cout << "Fsocre: " << Fsocre << std::endl;
}
else {
std::cout << "Fsocre: "
<< "NA" << std::endl;
}
}
//数据准备
cv::Ptr<cv::ml::TrainData> tdata() {
cv::Mat samples;
std::vector<int> responses;
for (auto f : train_file_list_) {
auto image = cv::imread(f.file);
if (!image.data) {
fprintf(stdout, ">> Invalid image: %s ignore.
", f.file.c_str());
continue;
}
cv::Mat feature;
getHistomPlusColoFeatures(image, feature);
feature = feature.reshape(1, 1);
samples.push_back(feature);
responses.push_back(int(f.label));
}
cv::Mat samples_, responses_;
samples.convertTo(samples_, CV_32FC1);
cv::Mat(responses).copyTo(responses_);
return cv::ml::TrainData::create(samples_, cv::ml::SampleTypes::ROW_SAMPLE, responses_);
}
int main(int argc, char** argv)
{
//initial SVM
cv::Ptr<cv::ml::SVM> svm = cv::ml::SVM::create();
svm->setType(cv::ml::SVM::Types::C_SVC);
svm->setKernel(cv::ml::SVM::KernelTypes::RBF);//使用推荐的参数
svm->setDegree(0.1);
svm->setGamma(0.1);
svm->setCoef0(0.1);
svm->setC(1);
svm->setNu(0.1);
svm->setP(0.1);
svm->setTermCriteria(cv::TermCriteria(cv::TermCriteria::MAX_ITER, 20000, 0.0001));
//数据准备
prepare();
if (train_file_list_.size() == 0) {
fprintf(stdout, "No file found in the train folder!
");
fprintf(stdout, "You should create a folder named "tmp" in EasyPR main folder.
");
fprintf(stdout, "Copy train data folder(like "SVM") under "tmp".
");
return -1;
}
auto train_data = tdata();
fprintf(stdout, ">> Training SVM model, please wait...
");
svm->trainAuto(train_data, 10, cv::ml::SVM::getDefaultGrid(cv::ml::SVM::C),
cv::ml::SVM::getDefaultGrid(cv::ml::SVM::GAMMA), cv::ml::SVM::getDefaultGrid(cv::ml::SVM::P),
cv::ml::SVM::getDefaultGrid(cv::ml::SVM::NU), cv::ml::SVM::getDefaultGrid(cv::ml::SVM::COEF),
cv::ml::SVM::getDefaultGrid(cv::ml::SVM::DEGREE), true);
//svm->save("svm.xml");
test(svm);
cv::waitKey(0);
return 0;
}

其中,两个目录下的图片基本是这样,一个是包含车牌的、一个是不包含车牌的,通过SVM训练,得到识别“图像中是否存在车牌”这样的能力。【SVM是小样本二分类的典型模型】
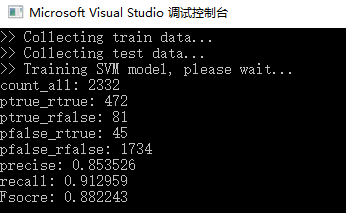
从这个结果来看,相关结果只能作为参考,而不能作为决定。(precise 精准率、recall 召回率、fscore 精確度常用的指標)
在同样的数据集下,对原始例子丰富,并且采用“随机森林”方法进行检测。对RT的参数配置进行研究。
#include "pch.h"
#include <iostream>
#include <string>
#include <cstring>
#include <cstdlib>
#include <vector>
#include "gocvhelper.h"
using namespace std;
using namespace cv;
//解决具体的“判定当前图片中是否存在车牌”问题。
typedef enum {
kForward = 1, // correspond to "has plate"
kInverse = 0 // correspond to "no plate"
} SvmLabel;
typedef struct {
std::string file;
SvmLabel label;
} TrainItem;
std::vector<TrainItem> train_file_list_;
std::vector<TrainItem> test_file_list_;
std::vector<std::string> getFiles(const std::string &folder,const bool all = true ) {
std::vector<std::string> files;
std::list<std::string> subfolders;
subfolders.push_back(folder);
while (!subfolders.empty()) {
std::string current_folder(subfolders.back());
if (*(current_folder.end() - 1) != '/') {
current_folder.append("/*");
}
else {
current_folder.append("*");
}
subfolders.pop_back();
struct _finddata_t file_info;
auto file_handler = _findfirst(current_folder.c_str(), &file_info);
while (file_handler != -1) {
if (all &&
(!strcmp(file_info.name, ".") || !strcmp(file_info.name, ".."))) {
if (_findnext(file_handler, &file_info) != 0) break;
continue;
}
if (file_info.attrib & _A_SUBDIR) {
// it's a sub folder
if (all) {
// will search sub folder
std::string folder(current_folder);
folder.pop_back();
folder.append(file_info.name);
subfolders.push_back(folder.c_str());
}
}
else {
// it's a file
std::string file_path;
// current_folder.pop_back();
file_path.assign(current_folder.c_str()).pop_back();
file_path.append(file_info.name);
files.push_back(file_path);
}
if (_findnext(file_handler, &file_info) != 0) break;
} // while
_findclose(file_handler);
}
return files;
}
//数据集准备
const char* plates_folder_ = "E:/代码资源/EasyPR/resources/train/svm";
void prepare() {
srand(unsigned(time(NULL)));
char buffer[260] = { 0 };
sprintf_s(buffer, "%s/has/train", plates_folder_);
auto has_file_train_list = getFiles(buffer);
std::random_shuffle(has_file_train_list.begin(), has_file_train_list.end());
sprintf_s(buffer, "%s/has/test", plates_folder_);
auto has_file_test_list = getFiles(buffer);
std::random_shuffle(has_file_test_list.begin(), has_file_test_list.end());
sprintf_s(buffer, "%s/no/train", plates_folder_);
auto no_file_train_list = getFiles(buffer);
std::random_shuffle(no_file_train_list.begin(), no_file_train_list.end());
sprintf_s(buffer, "%s/no/test", plates_folder_);
auto no_file_test_list = getFiles(buffer);
std::random_shuffle(no_file_test_list.begin(), no_file_test_list.end());
fprintf(stdout, ">> Collecting train data...
");
for (auto file : has_file_train_list)
train_file_list_.push_back({ file, kForward });
for (auto file : no_file_train_list)
train_file_list_.push_back({ file, kInverse });
fprintf(stdout, ">> Collecting test data...
");
for (auto file : has_file_test_list)
test_file_list_.push_back({ file, kForward });
for (auto file : no_file_test_list)
test_file_list_.push_back({ file, kInverse });
}
float countOfBigValue(Mat &mat, int iValue) {
float iCount = 0.0;
if (mat.rows > 1) {
for (int i = 0; i < mat.rows; ++i) {
if (mat.data[i * mat.step[0]] > iValue) {
iCount += 1.0;
}
}
return iCount;
}
else {
for (int i = 0; i < mat.cols; ++i) {
if (mat.data[i] > iValue) {
iCount += 1.0;
}
}
return iCount;
}
}
Mat ProjectedHistogram(Mat img, int t, int threshold) {
int sz = (t) ? img.rows : img.cols;
Mat mhist = Mat::zeros(1, sz, CV_32F);
for (int j = 0; j < sz; j++) {
Mat data = (t) ? img.row(j) : img.col(j);
mhist.at<float>(j) = countOfBigValue(data, threshold);
}
// Normalize histogram
double min, max;
minMaxLoc(mhist, &min, &max);
if (max > 0)
mhist.convertTo(mhist, -1, 1.0f / max, 0);
return mhist;
}
Mat getHistogram(Mat in) {
const int VERTICAL = 0;
const int HORIZONTAL = 1;
// Histogram features
Mat vhist = ProjectedHistogram(in, VERTICAL,20);
Mat hhist = ProjectedHistogram(in, HORIZONTAL,20);
// Last 10 is the number of moments components
int numCols = vhist.cols + hhist.cols;
Mat out = Mat::zeros(1, numCols, CV_32F);
int j = 0;
for (int i = 0; i < vhist.cols; i++) {
out.at<float>(j) = vhist.at<float>(i);
j++;
}
for (int i = 0; i < hhist.cols; i++) {
out.at<float>(j) = hhist.at<float>(i);
j++;
}
return out;
}
void getHistogramFeatures(const Mat& image, Mat& features) {
Mat grayImage;
cvtColor(image, grayImage, cv::COLOR_RGB2GRAY);
//grayImage = histeq(grayImage);
Mat img_threshold;
threshold(grayImage, img_threshold, 0, 255, cv::THRESH_OTSU + cv::THRESH_BINARY);
//Mat img_threshold = grayImage.clone();
//spatial_ostu(img_threshold, 8, 2, getPlateType(image, false));
features = getHistogram(img_threshold);
}
//获得图片特征
void getColorFeatures(const Mat& src, Mat& features) {
Mat src_hsv;
//grayImage = histeq(grayImage);
cvtColor(src, src_hsv, cv::COLOR_BGR2HSV);
int channels = src_hsv.channels();
int nRows = src_hsv.rows;
// consider multi channel image
int nCols = src_hsv.cols * channels;
if (src_hsv.isContinuous()) {
nCols *= nRows;
nRows = 1;
}
const int sz = 180;
int h[sz] = { 0 };
uchar* p;
for (int i = 0; i < nRows; ++i) {
p = src_hsv.ptr<uchar>(i);
for (int j = 0; j < nCols; j += 3) {
int H = int(p[j]); // 0-180
if (H > sz - 1) H = sz - 1;
if (H < 0) H = 0;
h[H]++;
}
}
Mat mhist = Mat::zeros(1, sz, CV_32F);
for (int j = 0; j < sz; j++) {
mhist.at<float>(j) = (float)h[j];
}
// Normalize histogram
double min, max;
minMaxLoc(mhist, &min, &max);
if (max > 0)
mhist.convertTo(mhist, -1, 1.0f / max, 0);
features = mhist;
}
void getHistomPlusColoFeatures(const Mat& image, Mat& features) {
Mat feature1, feature2;
getHistogramFeatures(image, feature1);
getColorFeatures(image, feature2);
hconcat(feature1.reshape(1, 1), feature2.reshape(1, 1), features);
}
void test(cv::Ptr<cv::ml::StatModel> svm_) {
if (test_file_list_.empty()) {
prepare();
}
double count_all = test_file_list_.size();
double ptrue_rtrue = 0;
double ptrue_rfalse = 0;
double pfalse_rtrue = 0;
double pfalse_rfalse = 0;
for (auto item : test_file_list_) {
auto image = cv::imread(item.file);
if (!image.data) {
std::cout << "no" << std::endl;
continue;
}
cv::Mat feature;
getHistomPlusColoFeatures(image, feature);
auto predict = int(svm_->predict(feature));
//std::cout << "predict: " << predict << std::endl;
auto real = item.label;
if (predict == kForward && real == kForward) ptrue_rtrue++;
if (predict == kForward && real == kInverse) ptrue_rfalse++;
if (predict == kInverse && real == kForward) pfalse_rtrue++;
if (predict == kInverse && real == kInverse) pfalse_rfalse++;
}
std::cout << "count_all: " << count_all << std::endl;
std::cout << "ptrue_rtrue: " << ptrue_rtrue << std::endl;
std::cout << "ptrue_rfalse: " << ptrue_rfalse << std::endl;
std::cout << "pfalse_rtrue: " << pfalse_rtrue << std::endl;
std::cout << "pfalse_rfalse: " << pfalse_rfalse << std::endl;
double precise = 0;
if (ptrue_rtrue + ptrue_rfalse != 0) {
precise = ptrue_rtrue / (ptrue_rtrue + ptrue_rfalse);
std::cout << "precise: " << precise << std::endl;
}
else {
std::cout << "precise: "
<< "NA" << std::endl;
}
double recall = 0;
if (ptrue_rtrue + pfalse_rtrue != 0) {
recall = ptrue_rtrue / (ptrue_rtrue + pfalse_rtrue);
std::cout << "recall: " << recall << std::endl;
}
else {
std::cout << "recall: "
<< "NA" << std::endl;
}
double Fsocre = 0;
if (precise + recall != 0) {
Fsocre = 2 * (precise * recall) / (precise + recall);
std::cout << "Fsocre: " << Fsocre << std::endl;
}
else {
std::cout << "Fsocre: "
<< "NA" << std::endl;
}
}
//数据准备
cv::Ptr<cv::ml::TrainData> tdata() {
cv::Mat samples;
std::vector<int> responses;
for (auto f : train_file_list_) {
auto image = cv::imread(f.file);
if (!image.data) {
fprintf(stdout, ">> Invalid image: %s ignore.
", f.file.c_str());
continue;
}
cv::Mat feature;
getHistomPlusColoFeatures(image, feature);
feature = feature.reshape(1, 1);
samples.push_back(feature);
responses.push_back(int(f.label));
}
cv::Mat samples_, responses_;
samples.convertTo(samples_, CV_32FC1);
cv::Mat(responses).copyTo(responses_);
return cv::ml::TrainData::create(samples_, cv::ml::SampleTypes::ROW_SAMPLE, responses_);
}
int main(int argc, char** argv)
{
//init RT
Ptr<cv::ml::RTrees> m_trees;
m_trees = cv::ml::RTrees::create();
m_trees->setMaxDepth(10);
m_trees->setMinSampleCount(10);
m_trees->setRegressionAccuracy(0);
m_trees->setUseSurrogates(false);
m_trees->setMaxCategories(2);//设置/获取最大的类别数,默认值为10;
//m_trees->setPriors(0); //setPriors/getPriors函数:设置/获取先验概率数值,用于调整决策树的偏好,默认值为空的Mat;
m_trees->setCalculateVarImportance(true);//方法setCalculateVarImportance()是用来设置是否在训练期间计算每个特征变量的重要性(会有一些额外时间开销)。
m_trees->setActiveVarCount(false); //树节点随机选择特征子集的大小 setActiveVarCount()方法是用来设置给定节点上要测试特征集规模,这些特征集是随机选择的。如果用户未明确设置,则通常将其设置为总数量的平方根。
m_trees->setTermCriteria({ cv::TermCriteria::MAX_ITER + cv::TermCriteria::EPS,100, 0.01});
//数据准备
prepare();
if (train_file_list_.size() == 0) {
fprintf(stdout, "No file found in the train folder!
");
fprintf(stdout, "You should create a folder named "tmp" in EasyPR main folder.
");
fprintf(stdout, "Copy train data folder(like "SVM") under "tmp".
");
return -1;
}
auto train_data = tdata();
fprintf(stdout, ">> Training ML model, please wait...
");
//m_trees.train(features, CV_ROW_SAMPLE, categ_mat, cv::Mat(), cv::Mat(), cv::Mat(), cv::Mat(), m_rt_params);//这些参数可能 不是 全部都能够使用的
m_trees->train(train_data);
//mlmodel->save("mlmodel.xml");
test(m_trees);
cv::waitKey(0);
return 0;
}其中相关参数解释:
m_trees->setMaxDepth(10);弱分类器的数量不同于每个分类器的最大深度由setMaxDepth()控制,表示单个弱分类器可以具有的最大层数。
m_trees->setMinSampleCount(10);
setMinSampleCount/getMinSampleCount函数:设置/获取最小训练样本数,默认值为10;。
m_trees->setRegressionAccuracy(0);setRegressionAccuracy/getRegressionAccuracy函数:设置/获取回归时用于终止的标准,默认值为0.01;
m_trees->setUseSurrogates(false);setUseSurrogates/getUseSurrogates函数:设置/获取是否使用surrogatesplits方法,默认值为false;
m_trees->setMaxCategories(3);setMaxCategories/getMaxCategories函数:设置/获取最大的类别数,默认值为10;
//m_trees->setPriors(0); setPriors/getPriors函数:设置/获取先验概率数值,用于调整决策树的偏好,默认值为空的Mat;
m_trees->setCalculateVarImportance(true);方法setCalculateVarImportance()是用来设置是否在训练期间计算每个特征变量的重要性(会有一些额外时间开销)。
m_trees->setActiveVarCount(false) 树节点随机选择特征子集的大小 setActiveVarCount()方法是用来设置给定节点上要测试特征集规模,这些特征集是随机选择的。如果用户未明确设置,则通常将其设置为总数量的平方根。
目前参数的结果为:
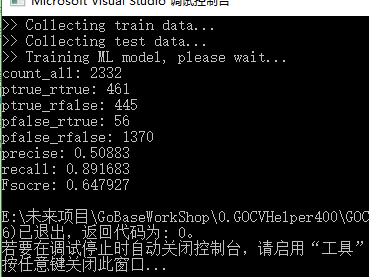
【这几乎和瞎猜没有区别了,感觉RT的训练比svm要快一些,也可能是我参数选择错误】
三、项目实践
在比较著名的OpenCFU中,采用“随机森林”方法来检测分割出来的blob的性质。
“Yes, of course. The ML predictor is updated compared to the original publication. It is a Random forest classifier that sort contours. Each contour is represented by a vector of features created/defined in https://github.com/qgeissmann/OpenCFU/blob/master/src/processor/src/Features.cpp. The classifier predicts one of three levels: the object is {single colony, multiple colonies, background}.”
【要想办法向作者要更多的信息】
四、反思小结
虽然相比较DL算法要简单, 但是在实现的过程中涉及到的参数配置,仍然是非常多的。如果没有相关的边界设置,那么很可能是训练不出来的。所以OpenCFU的重要价值就在这里。此外,确定数据集、选择训练方法、设置训练参数、最后融合形成一个新的定制算法,这个是CV工程师的价值。
参考:《RF,SVM和NN的优缺点》 https://blog.csdn.net/weixin_37933986/article/details/70160591