1 拉链表 概述
1.1 什么是拉链表?(定义)
拉链表,其实是数仓工程师针对变化数据的修改问题的一种解决方案下的某一类同一性质的表。
拉链表是针对数据仓库设计中表存储数据的方式而定义的,顾名思义,所谓拉链,就是记录历史。记录一个事物从开始,一直到当前状态的所有变化的信息。
1.2拉链表的优点
- 既可以保存历史数据,又防止了对历史数据的过多冗余存储(全量数据集越大,越节省磁盘存储空间)
比如:用户的任一一个增、删,改操作,若都对一f条数据进行存储,这样就会出现大量重复的冗余数据,增加不必要的存储空间。
1.3 拉链表的缺点?
- 降低系统检索、处理数据的效率。
1.4 拉链表的适用场景
- 需要查看某一个时间点或者时间段的历史快照信息。比如,查看某一个订单在历史某一个时间点的状态;查看某一个用户在过去某一段时间内,更新过几次等等
- 适合基于历史数据【更新频率低】(如果每天1000w订单,每天更新1000次以上)
- 适合【更新数据集】占【全量数据集】的比例低
- 须【节约存储空间】。如果对数据同步任务的目标表每天都保留1份全量,那么,每次全量数据集中会保存大量不变的信息,对存储是极大的浪费
2 拉链表场景1:每个周期仅对【增量更新(UPDATE + INSERT)】数据同步到数仓
2.1 需求描述
假定:对刚同步过来的【增量更新数据集】内每一条数据行是INSERT新增的,还是更新UPDATE更新的情况是未知的。
假定:数仓(ODS/DWD)是未开启(ACID特性) / 不支持对数据行 UPDATE、DELETE 操作的 HIVE 数仓。(即 拉链表的更新操作,需要全量取出,再全量写入)
局限性: 无法识别出 被删除的数据。(因为每个周期都是增量同步到数据仓库)
2.2 模型设计
exam_system.tb_examinee
id / name / idcard / birthdate / sex / height / school_name
ods.ods_examinee; -- [T+1周期增量切片表 := T+1周期更新数据集] 仅存储应用系统在每个周期同步过来的 增量更新(INSERT + UPDATE) 数据集
id / name / idcard / birthdate / sex / height / school_name
ods_time(在ODS库的最新[插入]更新时间; 假定在MYSQL数仓中数据类型:datetime,在HIVE数仓中数据类型:timestamp)
dwd.ods_examinee_his; -- [拉链表] 存储来源应用数据表的所有(含:过去0-T(+1)周期中未变化或变化过的)数据集: (T周期拉链表) + (T+1周期更新数据集) ==> (T+1周期拉链表)
id / name / idcard / birthdate / sex / height / school_name
dwd_start_time / dwd_end_time (在DWD库的插入时间、结束时间;通过这2个时间字段,限定了该行数据的生命周期;假定在MYSQL数仓中数据类型:datetime,在HIVE数仓中数据类型:timestamp)
dwd_data_state (当前周期当前数据行的状态: INIT[针对初始数据集] / INSERT[针对T+1周期数据集] / UPDATE[针对T+1周期数据集] / UPDATED[针对T周期数据集] / DELETED[针对T周期数据集])
2.3 ETL任务设计
仅描述核心步骤
- step1 T+1周期开始时:【增量更新数据集】同步到 ODS库的周期切片表
-- T+1周期开始时: tb_examinee --> ods_examinee
select id , name , idcard , birthdate , sex , height , school_name from tb_examinee;
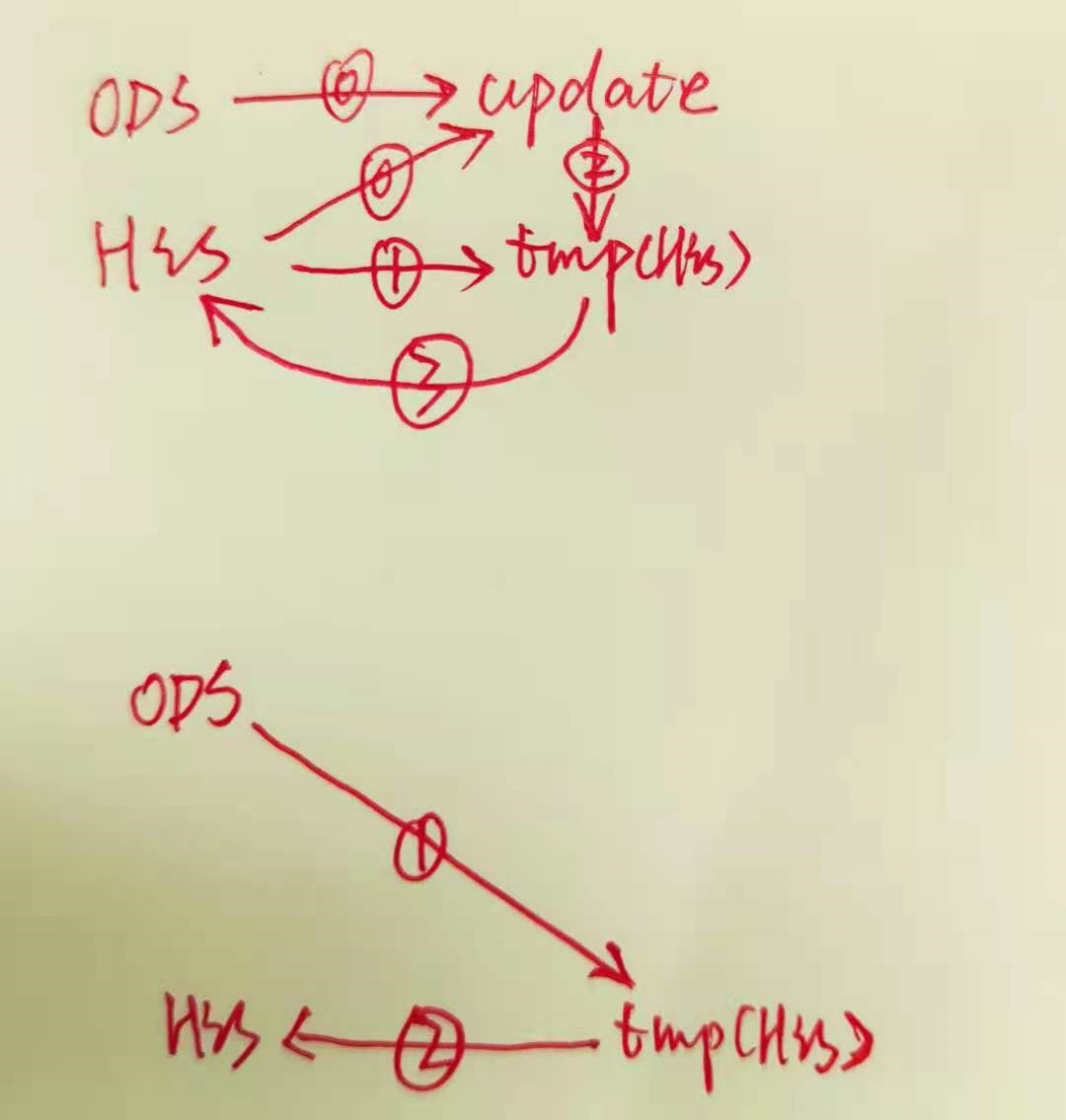
- step2 T+1周期开始时: 通过 ods_examinee(T+1周期增量切片表) UNION(by: join 或 in /not in) ods_examinee_his(T周期的拉链表) ==> 生成 T+1周期的拉链表
[SQL-1] 方式1(JOIN)
-- (INSERT 新增) LEFT JOIN update表A.key = 拉链表B.key WHERE 拉链表b.key IS NULL
-- (UPDATE 更新) INNER JOIN update表A.key = 拉链表B.key
INSERT OVERWRITE TABLE dwd_examinee_his_tmp -- 输出到【(拉链表的)临时表】;然后,再清空【HIS拉链表】;最后,把【临时表的数据】全量覆盖式(更新)到【拉链表】
-- 1 处理/加载 T+1 周期内的 INSERT 数据
UNION
-- 2 处理/加载 T+1 周期内的 UPDATE(D) 数据 : T+1周期的数据 & T周期的被更新数据
UNION
-- 3 处理/加载 T 周期前的 [历史/无效]数据 (或可理解为: 处理 非T、非T+1周期的数据集)
DEMO : JOIN 简易版 ↑↑↑
[SQL-2] 方式2(IN) - NOT IN(INSERT 新增) 和 IN(UPDATE更新)
INSERT OVERWRITE TABLE dwd_examinee_his_tmp -- 输出到【(拉链表的)临时表】;然后,再清空【HIS拉链表】;最后,把【临时表的数据】全量覆盖式(更新)到【拉链表】
-- 1 处理/加载 INSERT 数据
SELECT -- 针对 T+1 周期内 的 INSERT (最新/有效)数据 By 【 NOT IN 】
tmp_update.*,
current_timestamp() AS dwd_start_time, '9999-12-31 00:00:00' AS dwd_end_time,
'INSERT' AS dwd_data_state
FROM dwd.ods_examinee tmp_update WHERE tmp_update.id NOT IN ( -- 通过 NOT IN 筛选出 被 UPDATE 的数据
SELECT id FROM dwd.dwd_examinee_his WHERE dw_end_time >= '9999-12-31 00:00:00' -- 通过 dw_end_time = '9999-12-31 00:00:00' 筛选出本表中[最新周期的]全部有效数据集
)
UNION -- UNION ALL(不会去重) / UNION(会去重)
-- 2 处理/加载 UPDATE(D) 数据
SELECT -- 针对 T+1 周期内 的 UPDATE (最新/有效)数据 By 【 IN 】
tmp_update.*,
current_timestamp() AS dwd_start_time, '9999-12-31 00:00:00' AS dwd_end_time,
'UPDATE' AS dwd_data_state
FROM dwd.ods_examinee tmp_update WHERE tmp_update.id IN ( -- 通过 IN 筛选出 被 UPDATE 的数据
SELECT id FROM dwd.dwd_examinee_his WHERE dw_end_time >= '9999-12-31 00:00:00' -- 通过 dwd_end_time = '9999-12-31 00:00:00' 筛选出本表中[最新周期的]全部有效数据集
)
UNION
SELECT -- 针对 T 周期的 UPDATED (T+1周期时过期的)数据 By 【 IN 】
tmp_his.*,
dwd_start_time, '9999-12-31 00:00:00' AS dwd_end_time,
'UPDATED' AS dwd_data_state
FROM dwd.dwd_examinee_his tmp_his
WHERE 1 =1
AND tmp_his.dwd_end_time >= '9999-12-31 00:00:00' -- 通过 dwd_end_time = '9999-12-31 00:00:00' 筛选出 本表中[最新周期的]全部有效数据集
AND tmp_his.id IN ( -- 通过 IN 筛选出 被 UPDATE 的数据
SELECT * from dwd.ods_examinee AS tmp_update
)
UNION
-- 3 处理/加载 T周期前的[历史/无效]数据 (或可理解为: 处理 非T、非T+1周期的数据集)
SELECT
tmp_his.*
dwd_start_time, dwd_end_time, -- 保持原样即可
dwd_data_state -- 保持原样即可
FROM dwd.dwd_examinee_his tmp_his
WHERE
1 = 1
AND tmp_his.dwd_end_time <= current_date() -- 通过 end_time <= current_date() 筛选出 历史/无效 数据集
3 拉链表场景2:每个周期【全量数据集(ALL: UPDATE + INSERT + ...)】数据同步到数仓
3.1 需求描述
假定:对刚同步过来的【全量数据集】内每一条数据行是INSERT新增的,还是UPDATE更新的、DELETE删除的状态信息是未知的。
假定:数仓(ODS/DWD)是未开启(ACID特性) / 不支持对数据行 UPDATE、DELETE 操作的 HIVE 数仓。(即 拉链表的更新操作,需要全量取出,再全量写入)
特性:
- 能够识别出 被删除的数据。(因为每个周期都是全量同步到数据仓库)
- 相比增量更新场景,全量更新会产生1个问题:如何计算出【更新数据集(INSERT新增、UPDATE修改、DELETE删除)】
3.2 模型设计
注1:同增量同步相比,在模型设计上也完全可以不做变化(切片表1张、拉链表1张)。
- 上述的增量更新场景的模型设计已经是较为简洁的了(已尽量省去了中间表) 【故此,推荐】
- 只不过需要注意的是,取T周期的全量数据,需要换成其它的表;新增1个问题:如何计算出更新数据集(重点、难点)
注2:下面提供的这种建模方式,建立的表较多(目的1:为的是更好地理解整个过程;目的2:提供另一种建模思路————空间换时间)

exam_system.tb_examinee
id / name / idcard / birthdate / sex / height / school_name
ods.ods_examinee -- [T+1周期全量切片表 := T+1周期全量数据集] 仅存储应用系统在每个周期(T+1)同步过来的 全量数据集(... + INSERT + UPDATE)
id / name / idcard / birthdate / sex / height / school_name
ods_time(在ODS库的最新[插入]更新时间; 假定在MYSQL数仓中数据类型:datetime,在HIVE数仓中数据类型:timestamp)
ods.ods_examinee_previous -- [T周期全量切片表 := T周期全量数据集] 仅存储应用系统在每个周期(T)同步过来的 全量数据集(... + INSERT + UPDATE)
id / name / idcard / birthdate / sex / height / school_name
ods_time(在ODS库的最新[插入]更新时间; 假定在MYSQL数仓中数据类型:datetime,在HIVE数仓中数据类型:timestamp)
dwd.dwd_examinee_update -- [T+1周期更新数据集 := T+1周期增量切片表] :T+1周期全量切片表 +T期全量切片表 ==> T+1周期更新数据集
id / name / idcard / birthdate / sex / height / school_name
dwd_time(在DWD库的最新[插入]更新时间; 假定在MYSQL数仓中数据类型:datetime,在HIVE数仓中数据类型:timestamp)
dwd_data_state (当前周期当前数据行的状态: INIT[针对初始数据集] / INSERT[针对T+1周期数据集] / UPDATE[针对T+1周期数据集] / UPDATED[针对T周期数据集] / DELETED[针对T周期数据集])
dwd.ods_examinee_his -- [拉链表] 存储来源应用数据表的所有(含:过去0-T(+1)周期中未变化或变化过的)数据集: (T周期拉链表) + (T+1周期更新数据集) ==> (T+1周期拉链表)
id / name / idcard / birthdate / sex / height / school_name
dwd_start_time / dwd_end_time (在DWD库的插入时间、结束时间;通过这2个时间字段,限定了该行数据的生命周期;假定在MYSQL数仓中数据类型:datetime,在HIVE数仓中数据类型:timestamp)
dwd_data_state (当前周期当前数据行的状态: INIT[针对初始数据集] / INSERT[针对T+1周期数据集] / UPDATE[针对T+1周期数据集] / UPDATED[针对T周期数据集] / DELETED[针对T周期数据集])
特补充: 应用系统((MYSQL))应用表的DDL、DML(初始化数据集)
use exam_system;
-- ----------------------------
-- Table structure for tb_examinee
-- ----------------------------
DROP TABLE IF EXISTS `tb_examinee`; -- 考生
CREATE TABLE `tb_examinee` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`birthdate` date DEFAULT NULL,
`idcard` varchar(255) DEFAULT NULL,
`sex` char(255) DEFAULT NULL,
`height` double DEFAULT NULL,
`school_name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4;
-- ----------------------------
-- Records of tb_examinee
-- ----------------------------
use exam_system;
TRUNCATE TABLE `tb_examinee`;
INSERT INTO `tb_examinee` VALUES ('1','王麻子', '2004-05-23', '532345200405231998', '1', '167.5', '南京师范大学附属中学');
INSERT INTO `tb_examinee` VALUES ('2','李二娃', '2005-07-17', '532367200507171994', '1', '178.2', '南京市金陵中学');
INSERT INTO `tb_examinee` VALUES ('3','张小花', '2005-02-28', '532367200502281786', '2', '165.6', null);
INSERT INTO `tb_examinee` VALUES ('4','赵树人', '2005-06-30', '532367200506302850', '1', '178.3', '南京市梅园中学');
INSERT INTO `tb_examinee` VALUES ('5','宋汇汇', '2006-01-04', '532367200601044529', '2', '160.7', '南京市金陵中学');
INSERT INTO `tb_examinee` VALUES ('6','张大牛', '2006-09-25', null, '2', '165.02', '南京市梅园中学');
INSERT INTO `tb_examinee` VALUES ('7','钱伟伟', '2005-07-29', '321002200507293629', '1', '178.4', '南京师范大学附属中学');
3.3 ETL任务设计
step1 数仓表的建模
- 1 test_ods.ods_edu_es_tb_fm_examinee_previous
-- HIVE存储
use test_ods;
DROP TABLE IF EXISTS `ods_edu_es_tb_fm_examinee_previous`;
-- 考生信息 [全量切片表(上一周期的全量数据]
CREATE TABLE `ods_edu_es_tb_fm_examinee_previous` (
`id` int COMMENT 'ID',
`name` varchar(255) COMMENT '姓名',
`birthdate` date COMMENT '出生日期',
`idcard` varchar(255) COMMENT '身份证号码',
`sex` varchar(255) COMMENT '性别',
`height` double COMMENT '身高',
`school_name` varchar(255) COMMENT '学校',
`etl_time` timestamp COMMENT '数据入仓的ETL时间'
) COMMENT '考生信息表[[previous]全量切片表]'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ' '
LINES TERMINATED BY '
'
STORED AS orc tblproperties ("orc.compress"="SNAPPY");
- 2 test_ods.ods_edu_es_tb_fm_examinee
use test_ods;
DROP TABLE IF EXISTS `ods_edu_es_tb_fm_examinee`;
-- 考生信息 [全量切片表(最新周期的全量数据]
CREATE TABLE `ods_edu_es_tb_fm_examinee` (
`id` int COMMENT 'ID',
`name` varchar(255) COMMENT '姓名',
`birthdate` date COMMENT '出生日期',
`idcard` varchar(255) COMMENT '身份证号码',
`sex` varchar(255) COMMENT '性别',
`height` double COMMENT '身高',
`school_name` varchar(255) COMMENT '学校',
`etl_time` timestamp
) COMMENT '考生信息表[(最新周期)全量切片表]'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ' '
LINES TERMINATED BY '
'
STORED AS orc tblproperties ("orc.compress"="SNAPPY");
- 3 test_dwd.dwd_edu_es_tb_im_examinee_update
use test_dwd;
DROP TABLE IF EXISTS `dwd_edu_es_tb_im_examinee_update`;
-- 考生信息更新表 [更新表(筛选出:更新的、新增的、删除的)]
CREATE TABLE `dwd_edu_es_tb_im_examinee_update` (
`id` int COMMENT 'ID',
`name` varchar(255) COMMENT '姓名',
`birthdate` date COMMENT '出生日期',
`idcard` varchar(255) COMMENT '身份证号码',
`sex` varchar(255) COMMENT '性别',
`height` double COMMENT '身高',
`school_name` varchar(255) COMMENT '学校',
`etl_time` timestamp,
`etl_data_state` varchar(50) -- 标记: UPDATE / INSERT / DELETE
) COMMENT '考生信息表[update表]'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ' '
LINES TERMINATED BY '
'
STORED AS orc tblproperties ("orc.compress"="SNAPPY");
- 4 test_dwd.dwd_edu_es_tb_fm_examinee_his
use test_dwd;
DROP TABLE IF EXISTS `dwd_edu_es_tb_fm_examinee_his`;
-- 考生信息更新表 [更新表(筛选出:更新的、新增的、删除的)]
CREATE TABLE `dwd_edu_es_tb_fm_examinee_his` (
`id` int COMMENT 'ID',
`name` varchar(255) COMMENT '姓名',
`birthdate` date COMMENT '出生日期',
`idcard` varchar(255) COMMENT '身份证号码',
`sex` varchar(255) COMMENT '性别',
`height` double COMMENT '身高',
`school_name` varchar(255) COMMENT '学校',
`etl_time` timestamp, -- 最新周期切片数据集 的 原始业务数据记录插入到数仓的时间
`etl_data_state` varchar(50) , -- 标记 UPDATE / INSERT / DELETE
`his_start_time` timestamp, -- 拉链表字段 (生命周期的开始时间)
`his_end_time` timestamp -- 拉链表字段 (生命周期的结束时间)
) COMMENT '考生信息表[HIS(拉链)表]'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ' '
LINES TERMINATED BY '
'
STORED AS orc tblproperties ("orc.compress"="SNAPPY");
step1 T+1周期前,[业务系统数据集]全量抽取到[最新周期全量切片表(init)]
仅在拉链表建模后的首次进行此初始化操作。
此操作的目的:对当前周期的数据进行全量地快照,作为拉链表的初始化数据集。
-- ktr_tr_es_ods-ods_edu_es_tb_fm_examinee
-- ETL TASK [全量切片表 : 按需要的频率,随时可全量备份一次数据]
-- SQL (mysql(业务系统) --> hive(ods.最新周期全量切片表))
-- 【最新周期切片表初始化的数据 - just first time】
-- 表输入组件SQL:
select id, name, birthdate, idcard, sex, school_name, now() as etl_time
from exam_system.tb_examinee;
-- Hive表输出组件: ods_edu_es_tb_fm_examinee [数据覆盖]
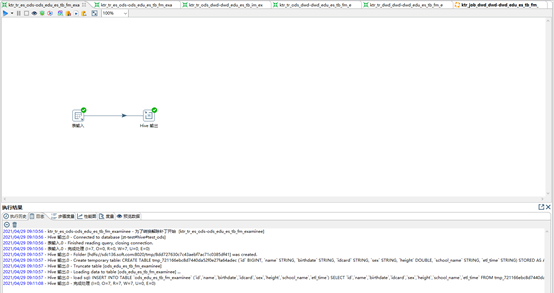
step2 T+1周期前,[最新周期全量切片表]全量抽取到[拉链表(init)]
仅在拉链表建模后的首次进行此初始化操作。
此操作的目的:对当前周期的数据进行全量地快照,作为拉链表的初始化数据集。
-- ktr_tr_ods_dwd-dwd_edu_es_tb_fm_examinee_his
-- ETL TASK [最新数据]
-- SQL (mysql(ods.最新周期 全量切片表) ----> hive(dwd.his拉链表)) [just first time for init](最初周期的初始化数据)
--- truncate table test_dwd.dwd_edu_es_tb_fm_examinee_his;
-- insert into test_dwd.dwd_edu_es_tb_fm_examinee_his(id, name, birthdate, idcard, sex, height, school_name, etl_time, etl_data_state, his_start_time, his_end_time) select id, name, birthdate, idcard, sex, height, school_name, etl_time, 'INIT' as etl_data_state, current_timestamp() as his_start_time, '9999-12-31 00:00:00' as his_end_time from test_ods.ods_edu_es_tb_fm_examinee
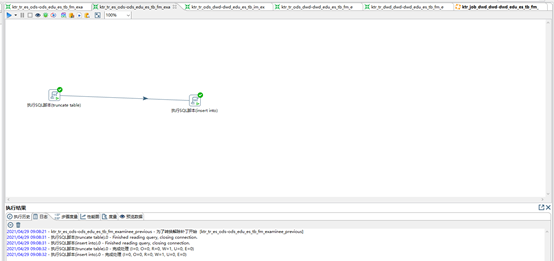
step3 T+1周期前,[最新周期全量切片表]全量抽取到[上一周期全量切片表]
-- ktr_tr_es_ods-ods_edu_es_tb_fm_examinee_previous
-- ETL TASK [全量切片表 : 按需要的频率,随时可全量备份一次数据]
---- SQL(mysql(ods.最新周期全量切片表) --> hive(ods.上一周期全量切片表))
-- SQL组件1
truncate table test_ods.ods_edu_es_tb_fm_examinee_previous;
-- SQL组件2
insert into test_ods.ods_edu_es_tb_fm_examinee_previous(
id, name, birthdate, idcard, sex, height, school_name, etl_time
)
select id, name, birthdate, idcard, sex, height, school_name, etl_time
from test_ods.ods_edu_es_tb_fm_examinee;
step4 T+1周期内,对业务系统表的数据进行增删改操作[假定]
MYSQL
-- MYSQL
INSERT INTO exam_system.`tb_examinee`(
name, birthdate, idcard, sex, height, school_name
) VALUES ('欧阳云茵', '2006-01-01', '3210022005010142853', '2', '163.4', '南京师范大学附属中学'); -- insert
update exam_system.tb_examinee set height =186.3,sex='M' where name = '张大牛' ; -- update
DELETE FROM exam_system.tb_examinee where id=7 AND name= '钱伟伟'; -- delete
step5 T+1周期时,重复执行步骤1 (业务系统→最新周期全量切片表)
-- ktr_tr_es_ods-ods_edu_es_tb_fm_examinee
-- ETL TASK [全量切片表 : 按需要的频率,随时可全量备份一次数据]
-- SQL (mysql(业务系统) --> hive(ods.最新周期全量切片表))
-- 表输入组件SQL:
select id, name, birthdate, idcard, sex, school_name, now() as etl_time
from exam_system.tb_examinee;
-- Hive表输出组件: ods_edu_es_tb_fm_examinee [数据覆盖]
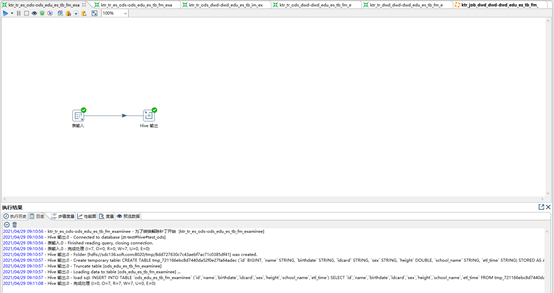
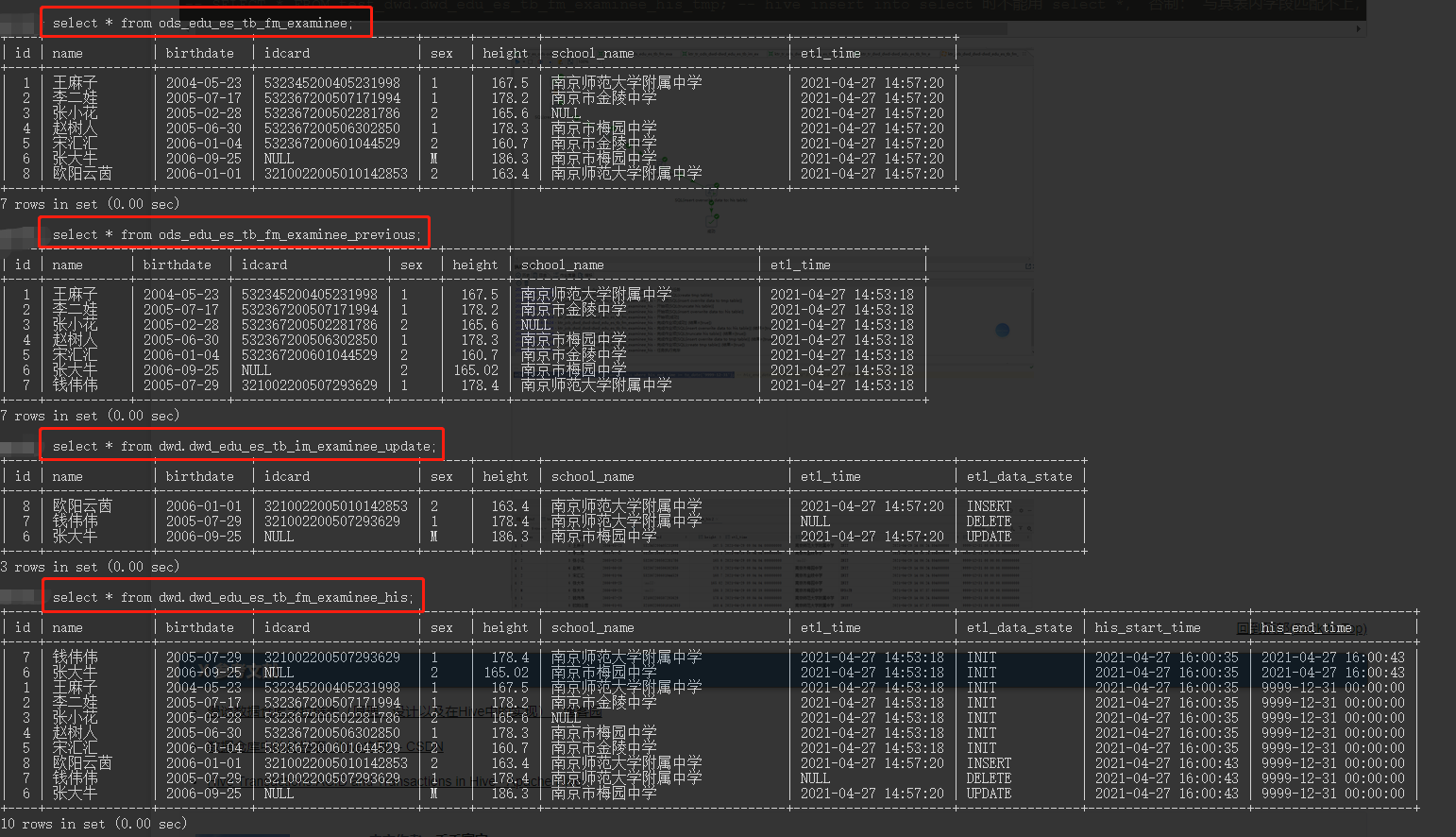
【step6】 T+1周期时,[最新周期全量切片表]+[上一周期全量切片表]覆盖式抽取生成[更新数据集]
找出T+1周期内的“更新数据集”(包括:新增、修改、删除),是最关键的一步。
找出“更新数据集”的方式方法有很多,例如,可通过:数据库日志 、其它的数据库专门工具(mysql:canal等)、全量比对T周期与T+1周期数据等方案来找出“更新数据集”。本方案中以较为通用的、与具体数据库类型无关的第三种方式——全量比对T周期与T+1周期数据集来实现对“更新数据集”的抽取。
本案例中假定的是每个周期全量抽取数据到2张切片表,故可以通过[T+1周期的全量切片表]+[T周期的全量切片表],通过各种join操作,比对出最新周期(T+1)的数据变更情况:新增的、删除的、修改过的。修改过的数据集如何查找?可通过比对2个周期中对拼接成一个字符串的表内所有字段的MD5摘要值,若MD5不同,则为被修改的。
但,若每个周期增量抽取数据到2张切片表,这种场景有几个不同之处:
- 1)增量,非全量;
- 2)可能有新增的、修改的,乃至删除的数据,甚至未做过修改的数据(后2者情况较少);
此时,怎么生成[更新数据集]?
实现思路是:通过[最新周期全量切片表(此时,其表内仅有业务系统推送的增量数据集)]+[拉链表(需筛选出T周期时有效的数据集)],来生成[更新数据集]。本质上,是异曲同工的。
-- HIVE
-- ktr_tr_ods_dwd-dwd_edu_es_tb_im_examinee_update
-- ETL TASK [生成 变化数据集 到 update表]
-- SQL (hive(ods.最新周期全量切片表)、hive(ods.上一周期全量切片表) ----> hive(dwd.update表))
-- SQL组件1
truncate table test_dwd.dwd_edu_es_tb_im_examinee_update;
-- SQL组件2
insert into test_dwd.dwd_edu_es_tb_im_examinee_update -- 增量、修改数据
select -- 新增 INSERT
a.id, a.name, a.birthdate, a.idcard, a.sex, a.height, a.school_name
,a.etl_time -- (最新周期)切片表的etl_time
,'INSERT' as etl_data_state
from (
select
id, name, birthdate, idcard, sex, height, school_name
,etl_time
-- ,concat(id, ',', name, ',', birthdate, ',', idcard, ',', sex, ',', height, ',', school_name) as linedata
-- ,md5(concat(id, ',', name, ',', birthdate, ',', idcard, ',', sex, ',', height, ',', school_name)) as md5_linedata
from test_ods.ods_edu_es_tb_fm_examinee
) a
left join test_ods.ods_edu_es_tb_fm_examinee_previous b
on a.id = b.id
where b.id is null
union
select -- 删除 DELETE
a.id, a.name, a.birthdate, a.idcard, a.sex, a.height, a.school_name
, b.etl_time -- (最新周期)切片表的etl_time (NULL)
,'DELETE' as etl_data_state
from (
select
id, name, birthdate, idcard, sex, height, school_name
-- ,concat(id, ',', name, ',', birthdate, ',', idcard, ',', sex, ',', height, ',', school_name) as linedata
-- ,md5(concat(id, ',', name, ',', birthdate, ',', idcard, ',', sex, ',', height, ',', school_name)) as md5_linedata
from test_ods.ods_edu_es_tb_fm_examinee_previous
) a
left join test_ods.ods_edu_es_tb_fm_examinee b
on a.id = b.id
where b.id is null
union
select -- 修改 UPDATE
a.id, a.name, a.birthdate, a.idcard, a.sex, a.height, a.school_name
, a.etl_time -- (最新周期)切片表的 etl_time
,'UPDATE' as etl_data_state
from (
select
id, name, birthdate, idcard, sex, height, school_name
,etl_time
-- ,concat(ifnull(id, '-'), ',', ifnull(name, '-'), ',', ifnull(birthdate, '-'), ',', ifnull(idcard, '-'), ',', ifnull(sex, '-'), ',', ifnull(height, '-'), ',', ifnull(school_name, '-') ) as linedata,
,md5( concat(nvl(id, '-'), ',', nvl(name, '-'), ',', nvl(birthdate, '-'), ',', nvl(idcard, '-'), ',', nvl(sex, '-'), ',', nvl(height, '-'), ',', nvl(school_name, '-') ) ) as md5_linedata
from test_ods.ods_edu_es_tb_fm_examinee
) a
inner join test_ods.ods_edu_es_tb_fm_examinee_previous b
on a.id = b.id
where a.md5_linedata != md5( concat(nvl(b.id, '-'), ',', nvl(b.name, '-'), ',', nvl(b.birthdate, '-'), ',', nvl(b.idcard, '-'), ',', nvl(b.sex, '-'), ',', nvl(b.height, '-'), ',', nvl(b.school_name, '-') ) )
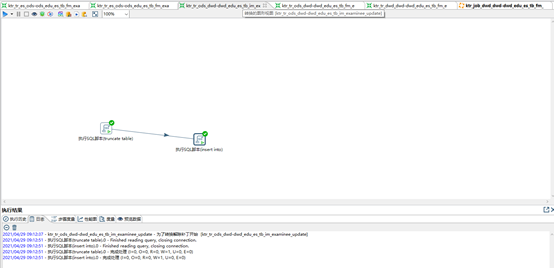
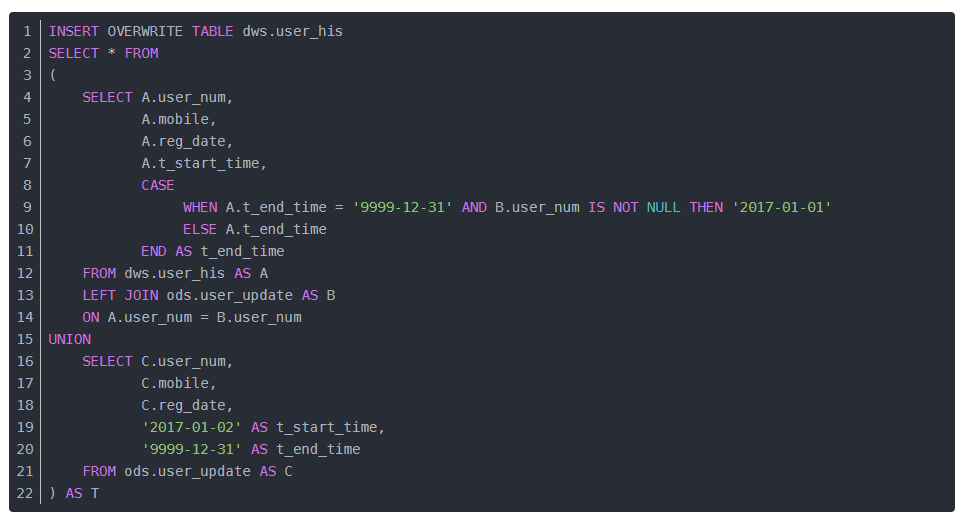
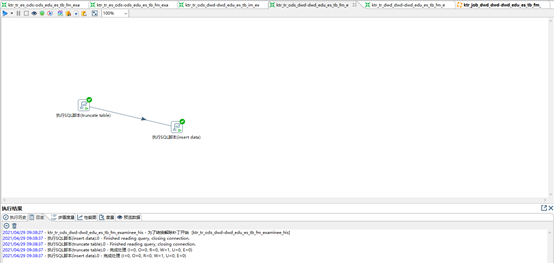
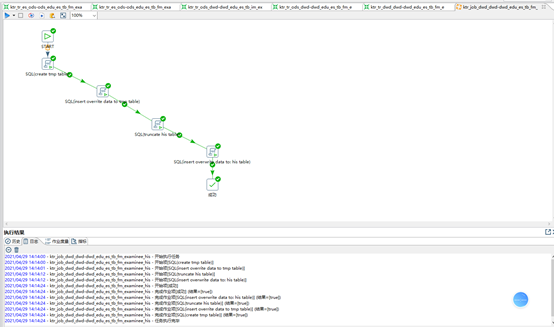
【step7】 T+1周期时,[拉链表]+[更新数据集]合并覆盖抽取到[拉链表]
-- ktr_job_dwd_dwd-dwd_edu_es_tb_fm_examinee_his (使用JOB编排流程,TR不支持流程编排,其并行执行会导致结果错误)
-- ETL TASK [最新数据]
-- SQL (hive(dwd.his拉链表表)、hive(dwd.update表) ----> hive(dwd.his拉链表))
-- SQL组件
CREATE TABLE IF NOT EXISTS test_dwd.dwd_edu_es_tb_fm_examinee_his_tmp
STORED AS ORC
AS
SELECT
id, name, birthdate, idcard, sex, height, school_name, etl_time, etl_data_state, his_start_time, his_end_time
FROM
test_dwd.dwd_edu_es_tb_fm_examinee_his
WHERE id= 0
-- 空操作组件
-- SQL组件
INSERT OVERWRITE TABLE test_dwd.dwd_edu_es_tb_fm_examinee_his_tmp
SELECT
id, name, birthdate, idcard, sex, height, school_name, etl_time, etl_data_state, his_start_time, his_end_time
FROM
(
SELECT -- 筛选出 UPDATE 、 DELETE 的记录
a.id, a.name, a.birthdate, a.idcard, a.sex, a.height, a.school_name,
a.etl_time, a.etl_data_state,
a.his_start_time,
(CASE
WHEN a.his_end_time = '9999-12-31' AND b.id IS NOT NULL THEN from_unixtime(unix_timestamp(current_timestamp()), 'YYYY-MM-dd HH:mm:ss')
-- WHEN a.his_end_time = '9999-12-31' AND b.id IS NOT NULL THEN from_unixtime(unix_timestamp('2021-04-26'), '%Y-%m-%d %H:%i:%s')
ELSE a.his_end_time END
) AS his_end_time
FROM test_dwd.dwd_edu_es_tb_fm_examinee_his AS a
LEFT JOIN test_dwd.dwd_edu_es_tb_im_examinee_update AS b
ON a.id = b.id
-- select *, from_unixtime(unix_timestamp('2021-04-27'), '%Y-%m-%d %H:%i:%s') as his_start_time, '9999-12-31 00:00:00' AS his_end_time from test_dwd.dwd_edu_es_tb_im_examinee_update
UNION -- UNION 去重 (UNION ALL 不去重)
SELECT -- 筛选出 INSERT 的记录
c.id, c.name, c.birthdate, c.idcard, c.sex, c.height, c.school_name,
c.etl_time, c.etl_data_state,
-- from_unixtime(unix_timestamp('2021-04-27'), '%Y-%m-%d %H:%i:%s') AS his_start_time,
from_unixtime(unix_timestamp(current_timestamp()), 'YYYY-MM-dd HH:mm:ss') AS his_start_time,
-- from_unixtime(unix_timestamp('9999-12-31'), '%Y-%m-%d %H:%i:%s') AS his_end_time
'9999-12-31 00:00:00' AS his_end_time
FROM test_dwd.dwd_edu_es_tb_im_examinee_update AS c
) AS T
-- SQL组件
TRUNCATE TABLE test_dwd.dwd_edu_es_tb_fm_examinee_his
-- SQL组件
INSERT OVERWRITE TABLE test_dwd.dwd_edu_es_tb_fm_examinee_his
SELECT id,name,birthdate,idcard, sex, height, school_name, etl_time, etl_data_state, his_start_time,his_end_time FROM test_dwd.dwd_edu_es_tb_fm_examinee_his_tmp
-- SELECT * FROM test_dwd.dwd_edu_es_tb_fm_examinee_his_tmp; -- hive insert into select 时不能用 select *, 否制: 与其表内字段匹配不上,数据 全为 null
X 参考文献
- 漫谈数据仓库之拉链表(原理、设计以及在Hive中的实现) - 博客园
- 数据仓库中的拉链表(hive实现) - CSDN
- Hive Transactions:ACID and Transactions in Hive - Apache Hive
Y 彩蛋
彩蛋1
建议1: 用于比对当前数据行是否被修改的MD5值,建议在数据入库时即单独存储好。(避免后期运算量太大,影响性能)
彩蛋2
with tmp_t_his as (
select
id, name, birthdate, idcard, sex, height, school_name
,dwd_time, dwd_start_time, dwd_end_time, data_state
,md5( concat(nvl(id, '-'), ',', nvl(name, '-'), ',', nvl(birthdate, '-'), ',', nvl(idcard, '-'), ',', nvl(sex, '-'), ',', nvl(height, '-'), ',', nvl(school_name, '-') ) ) as md5_linedata
FROM
test_dwd.dwd_examinee_his
WHERE
dwd_end_time >= to_date('9999-12-31', 'yyyy-MM-dd') -- 从拉链表中筛选出 T 周期的(有效)数据集
-- limit 5
)
insert overwrite table test_dwd.dwd_examinee_his_tmp
select -- 1 拉链表 [0, T-1]
id, name, birthdate, idcard, sex, height, school_name
,dwd_time, dwd_start_time, dwd_end_time, data_state
FROM
test_dwd.dwd_examinee_his
WHERE 1 = 1 AND dwd_end_time < to_date('9999-12-31', 'yyyy-MM-dd') -- [0, T-1] 周期 的 历史记录
-- limit 5
union
select -- 2 拉链表 [T] 未被 UPDATE的 (保持原样即可) + 被 UPDATE 的 (拉链表T周期的原记录 : end_time 标记为当前时间戳 ; 数据状态 被标记为 UPDATED)
b.id, b.name, b.birthdate, b.idcard, b.sex, b.height, b.school_name
, a.dwd_time, a.dwd_start_time, -- a.dwd_end_time,
(CASE
WHEN md5( concat(nvl(a.id, '-'), ',', nvl(a.name, '-'), ',', nvl(a.birthdate, '-'), ',', nvl(a.idcard, '-'), ',', nvl(a.sex, '-'), ',', nvl(a.height, '-'), ',', nvl(a.school_name, '-') ) )= md5( concat(nvl(b.id, '-'), ',', nvl(b.name, '-'), ',', nvl(b.birthdate, '-'), ',', nvl(b.idcard, '-'), ',', nvl(b.sex, '-'), ',', nvl(b.height, '-'), ',', nvl(b.school_name, '-') ) )
THEN current_timestamp() -- 标识 此数据行的生命周期在此刻结束
ELSE a.dwd_end_time
END) as dwd_end_time,
(CASE
WHEN md5( concat(nvl(a.id, '-'), ',', nvl(a.name, '-'), ',', nvl(a.birthdate, '-'), ',', nvl(a.idcard, '-'), ',', nvl(a.sex, '-'), ',', nvl(a.height, '-'), ',', nvl(a.school_name, '-') ) ) = md5( concat(nvl(b.id, '-'), ',', nvl(b.name, '-'), ',', nvl(b.birthdate, '-'), ',', nvl(b.idcard, '-'), ',', nvl(b.sex, '-'), ',', nvl(b.height, '-'), ',', nvl(b.school_name, '-') ) )
THEN 'UPDATED' -- 标识 此数据行的生命周期在此刻结束
ELSE a.data_state
END) as data_state
from test_dwd.dwd_examinee_his a
inner join test_ods.ods_examinee b on a.id = b.id
where 1 = 1
AND a.dwd_end_time >= to_date('9999-12-31', 'yyyy-MM-dd')
-- AND a.md5_linedata = md5( concat(nvl(b.id, '-'), ',', nvl(b.name, '-'), ',', nvl(b.birthdate, '-'), ',', nvl(b.idcard, '-'), ',', nvl(b.sex, '-'), ',', nvl(b.height, '-'), ',', nvl(b.school_name, '-') ) )
-- union
-- select -- 3 拉链表 [T] 被 UPDATE 的 (拉链表T周期的原记录 : end_time 标记为当前时间戳 ; 数据状态 被标记为 UPDATED)
-- a.id, a.name, a.birthdate, a.idcard, a.sex, a.height, a.school_name
-- , a.dwd_time, a.dwd_start_time, current_timestamp as dwd_end_time,'UPDATED' as data_state
-- ,'UPDATE' as etl_data_state
-- from tmp_t_his a
-- inner join test_dwd.dwd_examinee_his b on a.id = b.id
-- where 1 = 1 AND a.md5_linedata = md5( concat(nvl(b.id, '-'), ',', nvl(b.name, '-'), ',', nvl(b.birthdate, '-'), ',', nvl(b.idcard, '-'), ',', nvl(b.sex, '-'), ',', nvl(b.height, '-'), ',', nvl(b.school_name, '-') ) )
union
select -- 4 修改 UPDATE
a.id, a.name, a.birthdate, a.idcard, a.sex, a.height, a.school_name
, b.dwd_time, b.dwd_start_time, '9999-12-31 00:00:00' as dwd_end_time, -- 'UPDATE' as data_state
-- (CASE
-- WHEN b.md5_linedata = md5( concat(nvl(a.id, '-'), ',', nvl(a.name, '-'), ',', nvl(a.birthdate, '-'), ',', nvl(a.idcard, '-'), ',', nvl(a.sex, '-'), ',', nvl(a.height, '-'), ',', nvl(a.school_name, '-') ) )
-- THEN 'UPDATED'
-- ELSE a.data_state
-- END) as data_state
'UPDATED' as data_state
from test_ods.ods_examinee a
inner join tmp_t_his b on a.id = b.id
where 1 = 1 AND b.md5_linedata = md5( concat(nvl(a.id, '-'), ',', nvl(a.name, '-'), ',', nvl(a.birthdate, '-'), ',', nvl(a.idcard, '-'), ',', nvl(a.sex, '-'), ',', nvl(a.height, '-'), ',', nvl(a.school_name, '-') ) )
union
select -- 5 新增 INSERT
a.id, a.name, a.birthdate, a.idcard, a.sex, a.height, a.school_name
, current_timestamp as dwd_time, current_timestamp as dwd_start_time, '9999-12-31 00:00:00' as dwd_end_time, 'INSERT' as data_state
-- ,'INSERT' as etl_data_state
from test_ods.ods_examinee a
left join tmp_t_his b on a.id = b.id
where 1 = 1 AND b.id is null
彩蛋3