目录
前文列表
《多进程、多线程与多处理器计算平台的性能问题》
《OpenStack 高性能虚拟机之 CPU 绑定》
《OpenStack 高性能虚拟机之 NUMA 亲和》
虚拟存储器系统
在早期的计算机系统中,程序员会直接对主存储器的物理地址进行操作,这种编程方式导致了当程序出现寻址错误时有可能会导致整个系统崩溃,当一个进程出现寻址错误时也可能会导致另一个进程崩溃。显然,直接操作主存的物理地址不是一个好的方法。而且,由于不存在分页或分段的存储空间管理手段,所以 CPU 寻址宽度就成为了存储容量的限制,例如:32 位 CPU 只支持 4GB 内存的寻址。这导致了该计算机无法运行存储空间需求大于实际内存容量的应用程序。
为了解决这些问题,现代计算机系统通过操作系统和硬件的结合,把主存储器和辅存储器从逻辑上统一成了一个整体,这就是虚拟存储器,或称为虚拟存储系统。虚拟存储器是硬件异常、硬件地址翻译、主存、磁盘文件和内核软件的完美交互,它为每个进程提供了一个大的、一致的和私有的地址空间。
虚拟存储器的两大特点:
- 允许用户程序使用比实际主存空间大得多的空间来访问主存
- 每次访存都要进行虚实地址转换。
- 物理地址,即物理主存的地址空间。主存被组织成一个由 M 个连续的、字节大小的单元组成的数组,每字节都有一个唯一的物理地址(Physical Address,PA)。第一个字节的地址为 0,接下来的字节的地址为 1,依此类推。给定这种简单的结构,CPU 访问存储器的最自然的方式就是使用物理地址,即物理寻址。
- 虚拟地址,即虚拟存储地址空间,它能够让应用程序误以为自己拥有一块连续可用的 “物理” 地址,但实际上从程序视角所见的都是虚拟地址,而且这些虚拟地址对应的物理主存空间通常可能是碎片的,甚至有部分数据还可能会被暂时储存在外部磁盘设备上,在需要时才进行数据交换。
虚拟存储器的核心思路是根据程序运行时的局部性原理,一个程序运行时,在一小段时间内,只会用到程序和数据的很小一部分,仅把这部分程序和数据装入主存即可,更多的部分可以在需要用到时随时从辅存调入主存。在操作系统和相应硬件的支持下,数据在辅存和主存之间按程序运行的需要自动成批量地完成交换。
页式虚拟存储器
在页式虚拟存储器中,通过将虚拟存储空间分割成为了大小固定的虚拟页(Vitual Page,VP),简称虚页,每个虚拟页的大小为 P=2^n 字节。类似地,物理存储空间被分割为物理页(Physical Page,PP)也称为页帧(Page Frame),简称实页,大小也为 P 字节。
同任何缓存设计一样,虚拟存储器系统必须有某种方法来判定一个虚拟页是否存放在物理主存的某个地方。如果存在,系统还必须确定这个虚拟页存放在哪个物理页中。如果物理主存不命中,系统必须判断这个虚拟页存放在磁盘的哪个位置中,并在物理主存中选择一个牺牲页,然后将目标虚拟页从磁盘拷贝到物理主存中,替换掉牺牲页。这些功能是由许多软硬件联合提供,包括操作系统软件,MMU(存储器管理单元)地址翻译硬件和一个存放在物理主存中的叫做页表(Page Table)的数据结构,页表将虚拟页映射到物理页。页表的本质就是一个页表条目(Page Table Entry,PTE)数组。
CPU 通过虚拟地址(Virtual Address,VA)来访问存储空间,这个虚拟地址在被送到存储器之前需要先转换成适当的物理地址。将一个虚拟地址转换为物理地址的任务叫做地址翻译(Address Translation)。就像异常处理一样,地址翻译需要 CPU 硬件和操作系统之间的紧密合作。比如:Linux 操作系统的交换空间(Swap Space)。如果当 CPU 寻址时发现虚拟地址找不到对应的物理地址,那么就会触发一个异常并挂起寻址错误的进程。在这个过程中,对其他进程没有任何影响。
虚拟地址与物理地址之间的转换主要有 CPU 芯片上内嵌的存储器管理单元(Memory Management Unit,MMU)完成,它是一个专用的硬件,利用存放在主存中的查询表(地址映射表)来动态翻译虚拟地址,该表的内容由操作系统管理。
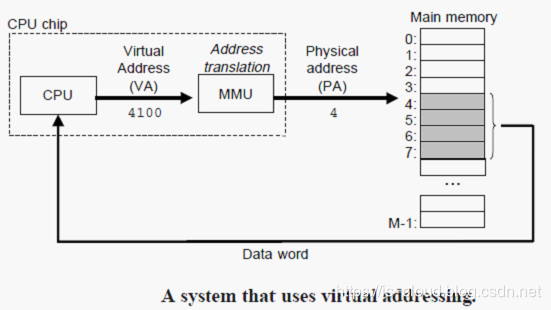
当页表已经存放在主存中,那么当 CPU 访问(虚拟)存储器时,首先要查询页面得到物理主存地址之后再访问主存完成存取。显然,地址转换机制让 CPU 多了一次访问主存的操作,相当于访问速度下降一半。而且当发生页面失效时,还要进行主存-辅助的页面交换,那么 CPU 访问主存的次数就更多了。为了解决这个问题,在一些影响访问速度的关键地方引入了硬件的支持。例如:采用按内容查找的相联存储器并行查找。此外,还进一步提出了 “快表” 的概念。把页表中最活跃的部分存放在快速存储器中组成快表,是减少 CPU 访问时间开销的一种方法。
快表由硬件(门电路和触发器)组成,属于 MMU 的部件之一,通常称为转换旁路缓冲器(Translation lookaside buffer,TLB)。TLB 的本质也是一个 Cache,它比页表小得多,一般在 16 个条目 ~ 128 个条目之间,快表只是页表的一个小小的副本。查表时,带着虚页好同时差快表和慢表(原页面),当在快表中找打条目时,则马上返回主存物理地址到主存地址寄存器,并使慢表查询作废。此时,虽然使用了虚拟存储器但实际上 CPU 访问主存的速度几乎没有下降(CPU 不再需要多次访问主存)。如果快表不命中,则需要花费一个访主存时间查慢表,然后再返回主存物理地址到主存地址寄存器,并将此条目送入到快表中,替换到快表的某一行条目。
大页内存
在页式虚拟存储器中,会在虚拟存储空间和物理主存空间都分割为一个个固定大小的页,为线程分配内存是也是以页为单位。比如:页的大小为 4K,那么 4GB 存储空间就需要 4GB/4KB=1M 条记录,即有 100 多万个 4KB 的页。我们可以相待,如果页太小了,那么就会产生大量的页表条目,降低了查询速度的同时还浪费了存放页面的主存空间;但如果页太大了,又会容易造成浪费,原因就跟段式存储管理方式一般。所以 Linux 操作系统默认的页大小就是 4KB,可以通过指令查看:
$ getconf PAGE_SIZE
4096
但在某些对性能要求非常苛刻的场景中,页面会被设置得非常的大,比如:1GB、甚至几十 GB,这些页被称之为 “大页”(Huge Page)。大页能够提升性能的主要原因有以下几点:
- 减少页表条目,加快检索速度。
- 提升 TLB 快表的命中率,TLB 一般拥有 16 ~ 128 个条目之间,也就是说当大页为 1GB 的时候,TLB 能够对应 16GB ~ 128GB 之间的存储空间。
值得注意的是,首先使用大页的同时一般会禁止主存-辅存页面交换(Swap),原因跟段式存储管理方式一样,大容量交换会让辅存读写成为 CPU 处理的瓶颈。 虽然现今在数据中心闪存化的环境中,这个问题得到了缓解,但代价就是昂贵的 SSD 存储设备。再一个就是大页也会使得页内地址检索的速度变慢,所以并非是页面的容量越大越好,而是需要对应用程序进行大量的测试取得页面容量与性能的曲线峰值才对。
启用 HugePage 的优点:
- 无需交换,不存在页面由于内存空间不足而换入换出的问题。
- 减轻 TLB Cache 的压力,也就是降低了 CPU Cache 可缓存的地址映射压力。
- 降低 Page Table 的负载。
- 消除 Page Table 地查找负载。
- 提高内存的整体性能。
启用 HugePage 的缺点:
- HugePages 会在系统启动时,直接分配并保留对应大小的内存区域
- HugePages 在开机之后,如果没有管理员的介入,是不会释放和改变的。
Linux 的大页内存
在 Linux 中,物理内存是以页为单位来管理的。默认的,页的大小为 4KB。 1MB 的内存能划分为 256 页; 1GB 则等同于 256000 页。 CPU 中有一个内置的内存管理单元(MMU),用于存储这些页的列表(页表),每页都有一个对应的入口地址。4KB 大小的页面在 “分页机制” 提出的时候是合理的,因为当时的内存大小不过几十兆字节。然而,当前计算机的物理内存容量已经增长到 GB 甚至 TB 级别了,操作系统仍然以 4KB 大小为页面的基本单位的话,会导致 CPU 中 MMU 的页面空间不足以存放所有的地址条目,则会造成内存的浪费。
同时,在 Linux 操作系统上运行内存需求量较大的应用程序时,采用的默认的 4KB 页面,将会产生较多 TLB Miss 和缺页中断,从而大大影响应用程序的性能。当操作系统以 2MB 甚至更大作为分页的单位时,将会大大减少 TLB Miss 和缺页中断的数量,显著提高应用程序的性能。
为了解决上述问题,自 Linux Kernel 2.6 起,引入了 Huge pages(巨型页)的概念,目的是通过使用大页内存来取代传统的 4KB 内存页面, 以适应越来越大的内存空间。Huge pages 有 2MB 和 1GB 两种规格,2MB 大小(默认)适合用于 GB 级别的内存,而 1GB 大小适合用于 TB 级别的内存。
大页的实现原理
为了能以最小的代价实现大页面支持,Linux 采用了 hugetlb 和 hugetlbfs 两个概念。其中,hugetlb 是记录在 TLB 中的条目并指向 hugepages,而 hugetlbfs 则是一个特殊文件系统(本质是内存文件系统)。hugetlbfs 主要的作用是使得应用程序可以根据需要灵活地选择虚拟存储器页面的大小,而不会全局性的强制使用某个大小的页面。在 TLB 中通过 hugetlb 来指向 hugepages,可以通过 hugetlb entries 来调用 hugepages,这些被分配的 hugepages 再以 hugetlbfs 内存文件系统的形式提供给进程使用。
- Regular Page 的分配:当一个进程请求内存时,它需要访问 PageTable 去调用一个实际的物理内存地址,继而获得内存空间。
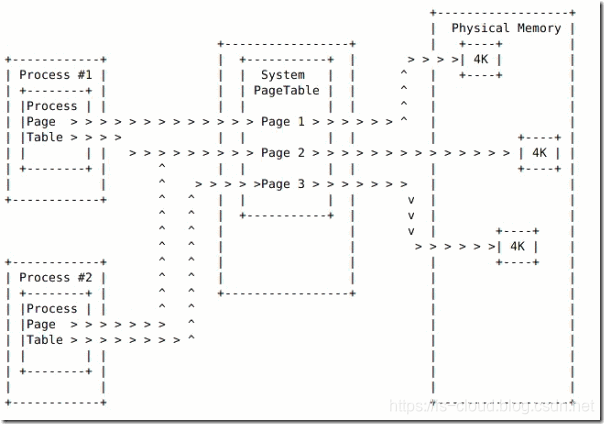
- Huge Page 的分配:当系统配置 Huge pages 后,进程依然通过普通的 PageTable 来获取到实际的物理内存地址。但不同的是,在 Process PageTable 和 System PageTable 第增加了 Hugepage(HPage)属性。
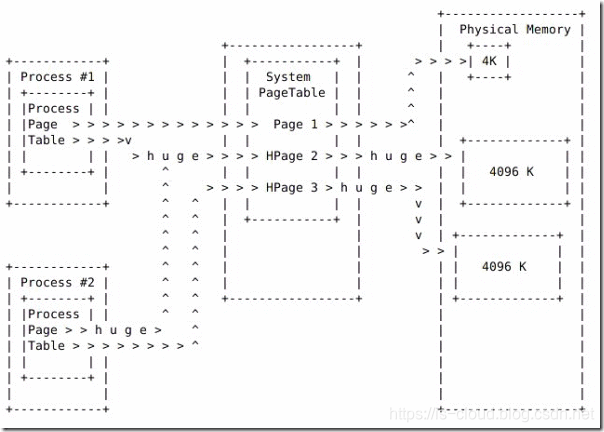
可见,进程当需要使用 Huge pages 时,只需要声明 Hugepage 属性,让系统分配 PageTable 中的 Huge pages 条目即可实现。所以,实际上 Regular page 和 Huge page 是共享一个 PageTable 的,这就是所谓的以最小的代码来支持 Huge pages。
使用 Huge pages 的好处是很明显的,假设应用程序需要 2MB 的内存,如果操作系统以 4KB 作为分页的单位,则需要 512 个页面,进而在 TLB 中需要 512 个表项,同时也需要 512 个页表项,操作系统需要经历至少 512 次 TLB Miss 和 512 次缺页中断才能将 2MB 应用程序空间全部映射到物理内存;然而,当操作系统采用 2MB 作为分页的基本单位时,只需要一次 TLB Miss 和一次缺页中断,就可以为 2MB 的应用程序空间建立虚实映射,并在运行过程中无需再经历 TLB Miss 和缺页中断(假设未发生 TLB 项替换和 Swap)。
此外,使用 Huge pages 还能减少系统管理和处理器访问内存页的时间(扩大了 TLB 快页表查询的内存地址范围),Linux 内核中的 Swap(内存交换)守护进程也不会管理大页面占用的这部分空间。合理设置大页面能减少内存操作的负担,减少访问页表造成性能瓶颈的可能性,从而提升系统性能。由此,如果你的系统经常碰到因为 Swap 而引发的性能问题,或者你的计算机内存空间非常大时,都可以考虑启用大页内存。
大页内存配置
大页面配置需要连续的内存空间,因此在开机时就分配是最可靠的设置方式。配置大页面的参数有:
-
hugepages :在内核中定义了开机启动时就分配的永久大页面的数量。默认为 0,即不分配。只有当系统有足够的连续可用页时,分配才会成功。由该参数保留的页不能用于其他用途。
-
hugepagesz: 在内核中定义了开机启动时分配的大页面的大小。可选值为 2MB 和 1GB 。默认是 2MB 。
-
default_hugepagesz:在内核中定义了开机启动时分配的大页面的默认大小。
-
Step 1. 查看 Linux 操作系统是否启动了大页内存,如果 HugePages_Total 为 0,意味着 Linux 没有设置或没有启用 Huge pages。
$ grep -i HugePages_Total /proc/meminfo
HugePages_Total: 0
- Step 2. 查看是否挂载了 hugetlbfs
$ mount | grep hugetlbfs
hugetlbfs on /dev/hugepages type hugetlbfs (rw,relatime)
- Step 3. 如果没有挂载则手动挂载
$ mkdir /mnt/huge_1GB
$ mount -t hugetlbfs nodev /mnt/huge_1GB
$ vim /etc/fstab
nodev /mnt/huge_1GB hugetlbfs pagesize=1GB 0 0
- Step 4. 修改 grub2,例如为系统配置 10 个 1GB 的大页面
$ vim /etc/grub2.cfg
# 定位到 linux16 /vmlinuz-3.10.0-327.el7.x86_64 在行末追加
default_hugepagesz=1G hugepagesz=1G hugepages=10
NOTE:配置大页面后,系统在开机启动时会首选尝试在内存中找到并预留连续的大小为 hugepages * hugepagesz 的内存空间。如果内存空间不满足,则启动会报错 Kernel Panic, Out of Memory 等错误。
- Step 5. 重启系统,查看更详细的大页内存信息
$ cat /proc/meminfo | grep -i Huge
AnonHugePages: 1433600 kB # 匿名 HugePages 数量
HugePages_Total: 0 # 分配的大页面数量
HugePages_Free: 0 # 没有被使用过的大页面数量
HugePages_Rsvd: 0 # 已经被分配预留但是还没有使用的大页面数目,应该尽量保持 HugePages_Free - HugePages_Rsvd = 0
HugePages_Surp: 0 # surplus 的缩写,表示大页内存池中大于 /proc/sys/vm/nr_hugepages 中值的大页面数量
Hugepagesize: 1048576 kB # 每个大页面的 Size,与 HugePages_Total 的相乘得到大页面池的总容量
如果大页面的 Size 一致,则可以通过 /proc/meminfo 中的 Hugepagesize 和 HugePages_Total 计算出大页面所占内存空间的大小。这部分空间会被算到已用的内存空间里,即使还未真正被使用。因此,用户可能观察到下面现象:使用 free 命令查看已用内存很大,但 top 或者 ps 中看到 %mem 的使用总量加起来却很少。
- Step 6. 如果上述输出看见 Hugepagesize 已经设置成 1GB,但 HugePages_Total 还是为 0,那么需要修改内核参数设定大页面的数量
$ sysctl -w vm.nr_hugepages=10
# 或者
$ echo 'vm.nr_hugepages = 10' > /etc/sysctl.conf
$ sysctl -p
NOTE:一般情况下,配置的大页面可能主要供特定的应用程序或服务使用,其他进程是无法共享这部分空间的(如 Oracle SGA)。 请根据系统物理内存和应用需求来设置合适的大小,避免大页面使用的浪费;以及造成其他进程因竞争剩余可用内存而出现内存溢出的错误,进而导致系统崩溃的现象。默认的,当存在大页面时,会在应用进程或者内核进程申请大页内存的时候,优先为它们分配大页面,大页面不足以分配时,才会分配传统的 4KB 页面。查看哪个程序在使用大页内存:
grep -e AnonHugePages /proc/*/smaps | awk '{if(2>4)print0}' | awk -F "/" '{print0;system("ps−fp"3)}'
透明巨型页 THP
Transparent Huge pages(THP,透明大页) 自 RHEL 6 开始引入。由于传统的 Huge pages 很难手动的管理,对于程序而言,可能需要修改很多的代码才能有效的使用。THP 的引入就是为了便于系统管理员和开发人员使用大页内存。THP 是一个抽象层,能够自动创建、管理和使用传统大页。操作系统将大页内存看作是一种系统资源,在 THP 开启的情况下,其他的进程也可以申请和释放大页内存。
Huge pages 和 Transparent Huge pages 在大页内存的使用方式上存在区别,前者是预分配的方式,而后者则是动态分配的方式,显然后者更适合程序使用。需要注意的是,THP 虽然方便,但在某些场景种仍然会建议我们关闭,这个需要结合实际应用场景慎重考虑。
手动关闭 THP:
$ echo never > /sys/kernel/mm/transparent_hugepage/enabled
$ echo never > /sys/kernel/mm/transparent_hugepage/defrag
$ cat /sys/kernel/mm/transparent_hugepage/enabled
[always] madvise never
# - [always] 表示启用了 THP
# - [never] 表示禁用了 THP
# - [madvise] 表示只在 MADV_HUGEPAGE 标志的 VMA 中使用 THP
永久关闭 THP:
vim /etc/grub2.cfg
# 在 cmdline 追加:
transparent_hugepage=never
大页面对内存的影响
需要注意的是,为大页面分配的内存空间会被计算到已用内存空间中,即使它们还未真正被使用。因此,你可能观察到下面现象:使用 free 命令查看已用内存很大,但 top 或者 ps 指令中看到 %MEM 的使用总量加起来却很少。
例如:总内存为 32G,并且分配了 12G 大页面的 free 如下
[root@localhost ~]# free -g
total used free shared buff/cache available
Mem: 31 16 14 0 0 14
Swap: 3 0 3
命令 top 输出, Shift+m 按内存使用量进行排序:

命令 ps -eo uid,pid,rss,trs,pmem,stat,cmd,查看进程的内存使用量:
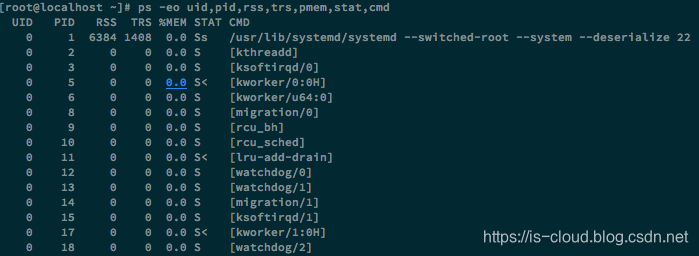
这种情况就导致了一个问题,如果盲目的去提高大页内存空间的占比,就很可能会出现胖的胖死,饿的饿死的问题。导致大页内存空间的浪费,因为普通程序是未必能够使用大页内存的。
Nova 虚拟机的大页内存设置
绝大多数现代 CPU 都支持多种内存页尺寸,从 4KB 到 2M/4M,最大可以达到 1GB。所有 CPU 都默认使用最小的 4KB 页,如果具有较大的内存可以选择启用大页内存进行分配,这将会明显减少 CPU 的页表项,因此会增加 TLB 页表缓存的命中率,降低内存访问延迟。如果操作系统使用默认的小页内存,随着运行时间,系统会出现越来越多的碎片,以至于后来难以申请到大页的内存。在大页内存大小越大时,该问题越严重。因此,如果当你有使用大页内存的需求时,最好的办法是在系统启动时就预留好内存空间。当前的 Linux 内核不允许针对特定的 NUMA 节点进行这样的设定,不过,在不久的将来这个限制将被取消。更进一步的限制是,由于 MMIO 空洞的存在,内存开始的 1GB 不能使用 1GB 的大页。
Linux 内核已经支持 THP(Transparent Huge Pages,透明巨型页)特性,该特性会尝试为应用程序预分配大页内存。依赖该特性的一个问题是,虚拟机的拥有者并不能保证给虚拟机使用的是大页内存还是小页内存。
内存块是直接指定给特定的 NUMA 单元的,这就意味着大页内存也是直接指定在 NUMA 单元上的。因此在 NUMA 单元上分配虚拟机时,计算服务需要考虑在 NUMA 单元或者主机上可能会用到的大页内存。为虚拟机内存启用大页内存时,可以不用考虑虚拟机操作系统是否会使用。
Linux 内核有一项特性,叫做内核共享存储(KSM),该特性使得不同的 CPU 可以共享相同内容的内存页。内核会主动扫描内存,合并内容相同的内存页。如果有 CPU 改变这个共享的内存页时,会采用写时复制(COW)的方式写入新的内存页。当一台主机上的多台虚拟机使用相同操作系统或者虚拟机使用很多相同内容内存页时,KSM 可以显著提高内存的利用率。因为内存扫描的消耗,使用 KSM 的代价是增加了 CPU 的负载,并且如果虚拟机突然做写操作时,会引发大量共享的页面,此时会存在潜在的内存压力峰值。虚拟化管理层必须因此积极地监控内存压力情况并做好现有虚拟机迁移到其他主机的准备,如果内存压力超过一定的水平限制,将会引发大量不可预知的 Swap 操作,甚至引发 OOM。所以在性能要求严格的场景中,我们建议关闭内存共享特性。
计算节点可以配置 CPU 与内存的超配比例,但是一旦使用了大页内存,内存便不能再进行超配。因为当使用大页内存时,虚拟机内存页必须与主机内存页一一映射,并且主机操作系统能通过 Swap 分区分配大页内存,这也排除了内存超配的可能。大页内存的使用,意味着需要支持内存作为专用资源的虚拟机类型。
尽管设置专用资源时,不会超配内存与 CPU,但是 CPU 与内存的资源仍然需要主机操作系统提前预留。如果使用大页内存,必须在主机操作系统中明确预留。对于 CPU 则有一些灵活性。因为尽管使用专用资源绑定 CPU,主机操作系统依然会使用这些 CPU 的一些时间。不管怎么样,最好可以预留一定的物理 CPU 专门为主机操作系统服务,以避免操作系统过多占用虚拟机 CPU,而造成对虚拟机性能的影响。Nova可以保留一部分 CPU 专门为操作系统服务,这部分功能将会在后续的设计中加强。
允许内存超配时,超出主机内存的部分将会使用到 Swap。ZSWAP 特性允许压缩内存页被写入 Swap 设备,这样可以大量减少 Swap 设备的 I/O 执行,减少了交换主机内存页面中固有的性能下降。Swap 会影响主机整体 I/O 性能,所以尽量不要把需要专用内存的虚拟机机与允许内存超配的虚拟机放在同一台物理主机上。如果专用 CPU 的虚拟机与允许超配的虚拟机竞争 CPU,由于 Cache 的影响,将会严重影响专用 CPU 的虚拟机的性能,特别在同一个 NUMA 单元上时。因此,最好将使用专用 CPU 的虚拟机与允许超配的虚拟机放在不同的主机上,其次是不同的 NUMA 单元上。
关于虚拟机在主机上的 CPU 与内存的布局决策,也会影响其他的主机资源分配。例如,PCI 设备与 NUMA 单元关系密切,PCI 设备的 DMA 操作使用的内存最好在本地 NUMA 单元上。因此,在哪个 NUMA 单元上分配虚拟机,将会影响到 PCI 设备的分配。
Nova 内存页设置:
openstack flavor set FLAVOR-NAME
--property hw:mem_page_size=PAGE_SIZE
PAGE_SIZE:
-
small (default):使用最小的 page size,e.g. x86 平台的 4KB。
-
large:只使用最大的 page size,e.g. x86 平台的 2MB 或 1GB。
-
any:取决于 Hypervisor 类型。如果是 Libvirt 的话,会根据服务器的大页内存设置进行决策,优先使用大的大页,依次递减。
-
pagesize:指定具体的 pape size,e.g. 4KB、2MB、2048、1GB。
e.g.
openstack flavor create --vcpus 2 --ram 2048 --disk 40
--property hw:mem_page_size=2MB Flavor1
openstack flavor create --vcpus 2 --ram 2048 --disk 40
--property hw:mem_page_size=1GB Flavor2
NOTE:Large pages can be enabled for guest RAM without any regard to whether the guest OS will use them or not. If the guest OS chooses not to use huge pages, it will merely see small pages as before. Conversely, if a guest OS does intend to use huge pages, it is very important that the guest RAM be backed by huge pages. Otherwise, the guest OS will not be getting the performance benefit it is expecting.
手动为 KVM 虚拟机中设置大页内存(http://www.linux-kvm.org/page/UsingLargePages):
# 2G 内存设置 256
# 4G 内存设置 512
# 8G 内存设置 1024
echo 1024 > /proc/sys/vm/nr_hugepages
实战经验
- 大页内存要求内存页对齐,即 Flavor RAM 可以被 hw:mem_page_size 整除(单位为 kb)。e.g.
openstack flavor create --vcpus 2 --ram 2048 --disk 40
--property hw:mem_page_size=1GB Flavor2
# 当 hw:mem_page_size=1GB 时,RAM 必须为 1024 的倍数
- 宿主机的大页面是平均分到每个 NUMA 节点上的,除非某个 NUMA 节点本身没有足够的可用连续内存来生成大页面,那么此时大页面将由另外一个 NUMA 节点生成。通过
/proc/sys/vm/nr_hugepages_mempolicy可以指定大页面具体由哪个 NUMA 节点来生成。查看 NUMA 节点的大页面资源,e.g.
# 当大页面的总数为 256,有 2 个 NUMA 节点时,那么每个 NUMA 节点的大页数为 256/2 = 128 个
$ cat /sys/devices/system/node/node*/meminfo | fgrep Huge
Node 0 AnonHugePages: 120832 kB
Node 0 HugePages_Total: 128
Node 0 HugePages_Free: 127
Node 0 HugePages_Surp: 0
Node 1 AnonHugePages: 0 kB
Node 1 HugePages_Total: 128
Node 1 HugePages_Free: 127
Node 1 HugePages_Surp: 0
- 大页面数量与单个大页面容量的乘积就是某个 NUMA 节点的大页容量。当 Flavor 的 RAM 大于单个 NUMA 节点的 Free Huge Page Size 时,需要将 Flavor RAM 分配到不同的 NUMA 节点上。否则,虚拟机会应该资源不足而创建失败。e.g.
openstack flavor set <FLAVOR>
--property hw:numa_nodes=2
--property hw:numa_cpus.0=0
--property hw:numa_cpus.1=1,2,3
--property hw:numa_mem.0=1024
--property hw:numa_mem.1=3072
参考文档
https://www.ibm.com/developerworks/cn/linux/l-cn-hugetlb/index.html