一、count各种用法的区别
1、count函数是日常工作中最常用的函数之一,用来统计表中数据的总数,常用的有count(*),count(1),count(列)。count(*)和count(1)是用来统计表中共有多少数据。是针对全表的
1 SELECT COUNT(*) FROM TAB1; 2 SELECT COUNT(1) FROM TAB1; 3 SELECT COUNT(*) FROM TAB1, TAB2; #显示两表做笛卡尔积后的行数
2、count(列)是针对于某一列的,如果此列值为空的话,count(列)是不会统计这一行的。NULL不会算在行数统计之内
1 CREATE TABLE T1(I int); 2 INSERT INTO T1 VALUES(1),(2),(NULL); 3 SELECT COUNT(*) FROM T1; # 结果为3 4 SELECT COUNT(*) FROM T1; # 结果为2
二、关于count的用法,谁更快
1、由上文可知,在数据库中count(*)和count(列)根本就是不等价的,count(*)是针对于全表的,而count(列)是针对于某一列的,如果此列值为空的话,count(列)是不会统计这一行的
所以两者根本没有可比性,性能比较首先要考虑写法等价,这两个语句根本就不等价的。也没有比较的意义。
2、建一张有25个字段的表并加入数据在进行count(*)和count(列)比较,分别执行count(*)和count每一列的操作来看一下谁更快。结果如下:
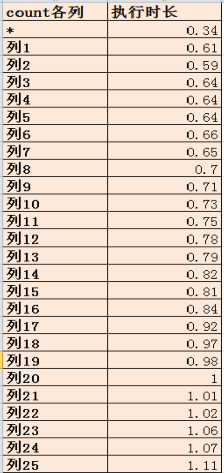
结论:列的偏移量决定性能,列越靠后,访问的开销越大。由于count(*)的算法与列偏移量无关,所以count(*) 最快,count( 最后列) 最慢所以:在设计表结构的过程中,越常用到的 列,要放在表结构的前边,不常用的列,放在表结构的后边。在工作中根据实际业务再考虑应该使用count(*)还是count(列)
PS: conut(1)和count(*)是一样的。但是在informix数据库中,对count(*)做过算法优化,远远快于count(1)。
三、关于SQL优化的一些误区
1、在联合查询中,和表的连接顺序无关。有人认为数据库的解析器是按顺序扫描from字句中的表名。应该选择小表作为基础表优先扫描(ps:如果现在的小表随着业务量的提升变成大表了,岂 不是要经常修改应用)。所以这种说法是不成立的,在联合查询中,以下的两种写法是没有区别的
1 T1(2条数据) 2 T2(1万条数据) 3 SELECT COUNT(*) FROM T1, T2; 4 SELECT COUNT(*) FROM T2, T1;
2、和where字句的连接顺序也无关。数据库在解析where字句时,也是按顺序解析(oracle是自下而上)。有些人认为where子句中排在最后的表应该是返回数据量少的表。这种说法也是不成立的
1 如:从T1表查到的数据比较少或该表的条件比较确定。 2 SELECT * FROM T1,T2 WHRE T1.A > 10 AND T2.B = 20; 3 SELECT * FROM T1,T2 WHRE T2.B = 20 AND T1.A > 10; 4 如果T2表返回数据量大,第二条SQL比第一条快(不成立)
3、用not exists取代not in是没有依据的(在oracle11g中都是采用高效的anti反连接算法)