1. 练习
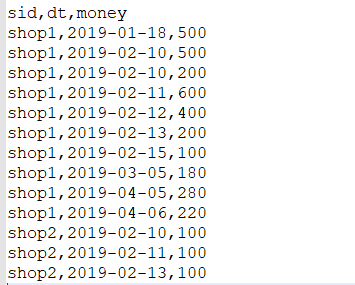
数据:
(1)需求1:统计有过连续3天以上销售的店铺有哪些,并且计算出连续三天以上的销售额
第一步:将每天的金额求和(同一天可能会有多个订单)


SELECT sid,dt,SUM(money) day_money FROM v_orders GROUP BY sid,dt

第二步:给每个商家中每日的订单按时间排序并打上编号
SELECT sid,dt,day_money, ROW_NUMBER() OVER(PARTITION BY sid ORDER BY dt) rn FROM ( SELECT sid,dt,SUM(money) day_money FROM v_orders GROUP BY sid,dt ) t1

第三步:获取date与rn的差值的字段
SELECT sid ,dt,day_money,date_sub(dt,rn) diff FROM ( SELECT sid,dt,day_money, ROW_NUMBER() OVER(PARTITION BY sid ORDER BY dt) rn FROM ( SELECT sid,dt,SUM(money) day_money FROM v_orders GROUP BY sid,dt ) t1 ) t2
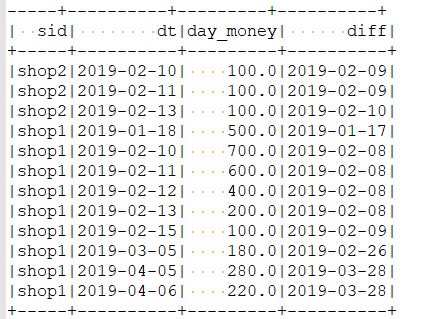
第四步: 最终结果
SELECT sid,MIN(dt),MAX(dt),SUM(day_money) cmoney,COUNT(*) cc FROM ( SELECT sid ,dt,day_money,date_sub(dt,rn) diff FROM ( SELECT sid,dt,day_money, ROW_NUMBER() OVER(PARTITION BY sid ORDER BY dt) rn FROM ( SELECT sid,dt,SUM(money) day_money FROM v_orders GROUP BY sid,dt ) t1 ) t2 ) GROUP BY sid,diff HAVING cc >=3

(2)需求2:统计店铺按月份的销售额和累计到该月的总销售额
- SQL风格(只写sq语句,省略代码部分)
SELECT sid,month,month_sales, SUM(month_sales) OVER(PARTITION BY sid ORDER BY month) total_sales // 默认是其实位置到当前位置的累加 --PARTITION BY sid ORDER BY mth ASC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW 完整的写法 FROM ( SELECT sid, DATE_FORMAT(dt,'yyyy-MM') month, --substr(dt,1,7) month, 用此函数来取月份也行 SUM(money) month_sales FROM v_orders GROUP BY sid, month )
结果
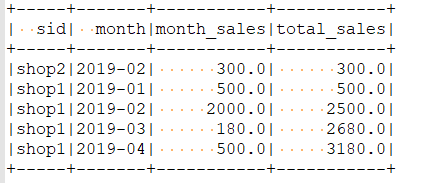
- DSL风格
object RollupMthIncomeDSL { def main(args: Array[String]): Unit = { // 创建SparkSession val spark: SparkSession = SparkSession.builder() .appName(this.getClass.getSimpleName) .master("local[*]") .getOrCreate() // 读取文件创建DataSet val orders: DataFrame = spark.read .option("header", "true") .option("inferSchema", "true") // inferSchema为true可以自动推测数据的类型,默认false,则所有的数据都是String类型的 .csv("F:\大数据第三阶段\spark\spark-day09\资料\order.csv") import spark.implicits._ import org.apache.spark.sql.functions._ // 获取月份,并按照sid和月份进行分组,聚合 val result: DataFrame = orders.groupBy($"sid", date_format($"dt", "yyyy-MM") as "month") .agg(sum($"money") as "month_sales") // withColumn相当于在原有基础上再增加一列,此处使用select重新获取表也行 //.select('sid, 'month, 'month_sales, sum('month_sales) over(Window.partitionBy('sid) // .orderBy('month).rowsBetween(Window.unboundedPreceding, Window.currentRow)) as "rollup_sales") .withColumn("rollup_sales", sum('month_sales) over (Window.partitionBy('sid) // 'sid相当于$"sid" .orderBy('month).rowsBetween(Window.unboundedPreceding, Window.currentRow))) result.show() spark.stop() } }
- RDD风格
object RollupMthIncomeRDD { def main(args: Array[String]): Unit = { // 创建SparkContext val conf = new SparkConf() .setAppName(this.getClass.getName) .setMaster("local[*]") val sc: SparkContext = new SparkContext(conf) val lines: RDD[String] = sc.textFile("F:\大数据第三阶段\spark\spark-day09\资料\order.csv") val reduced: RDD[((String, String), Double)] = lines.map(line => { val fields: Array[String] = line.split(",") val sid: String = fields(0) val dateStr: String = fields(1) val month: String = dateStr.substring(0, 7) val money: Double = fields(2).toDouble ((sid, month), money) }).reduceByKey(_ + _) // 按照shop id分组 val result: RDD[(String, String, String, Double)] = reduced.groupBy(_._1._1).mapValues(it => { //将迭代器中的数据toList放入到内存 //并且按照月份排序【字典顺序】 val sorted: List[((String, String), Double)] = it.toList.sortBy(_._1._2) var rollup = 0.0 sorted.map(t => { val sid = t._1._1 val month = t._1._2 val month_sales = t._2 rollup += month_sales (sid, month, rollup) }) }).flatMapValues(lst => lst).map(t => (t._1, t._2._1, t._2._2, t._2._3)) result.foreach(println) sc.stop() } }
注意点:可以直接读取csv文件获取DataFram,再获取rdd,如下

2. 分组topN的实现(大数据学习day21中的计算学科最受欢迎老师topN)
- SQL
注意点:此处的文件格式是text的,所以需要用SparkContext的textFile方法来读取数据,然后处理此数据,得到需要的字段(subject,teacher),再利用toDF("subject", "teacher")方法获取对应的DataFrame,从而创建相应的视图
object FavoriteTeacherSQL { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder() .appName(this.getClass.getSimpleName) .master("local[*]") .getOrCreate() import spark.implicits._ val lines: RDD[String] = spark.sparkContext.textFile("E:\javafile\spark\teacher100.txt") // 处理数据,获取DataFrame,用于创建视图 val df: DataFrame = lines.map(line => { val fields = line.split("/") val subject = fields(2).split("\.")(0) val teacher = fields(3) (subject, teacher) }).toDF("subject", "teacher") // 创建视图 df.createTempView("v_teacher") var topN: Int = 2 // SQL实现分组topN spark.sql( s""" |SELECT | subject,teacher,counts | rk |FROM |( | SELECT | subject,teacher,counts, | RANK() OVER(PARTITION BY subject ORDER BY counts DESC) rk | FROM | ( | SELECT | subject,teacher, | count(*) counts | FROM | v_teacher | GROUP BY subject, teacher | ) t1 |) t2 WHERE rk <= $topN |""".stripMargin).show() } }
此处的小知识点:
row_number(), rank(), dense_rank()方法的区别
row_number() over() 打行号,行号从1开始
rank() over() 排序,有并列,如果有两个第1,就没有第2了,然后直接第3,跳号
dense_rank() over() 排序,有并列,不跳号
- DSL
object FavoriteTeacherDSL { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder() .appName(this.getClass.getSimpleName) .master("local[*]") .getOrCreate() import spark.implicits._ val lines: RDD[String] = spark.sparkContext.textFile("E:\javafile\spark\teacher100.txt") // 处理数据,获取DataFrame,用于创建视图 val df: DataFrame = lines.map(line => { val fields = line.split("/") val subject = fields(2).split("\.")(0) val teacher = fields(3) (subject, teacher) }).toDF("subject", "teacher") import org.apache.spark.sql.functions._ df.groupBy("subject","teacher") .agg(count("*") as "counts") .withColumn("rk",dense_rank().over(Window.partitionBy($"subject").orderBy($"counts" desc)) ) .filter('rk <= 2) .show() spark.stop() } }
3. spark自定义函数-UDF
UDF:一进一出(输入一行,返回一行)
UDTF: 一进多出
UDAF: 多进一出
object MyConcatWsUDF { def main(args: Array[String]): Unit = { val spark = SparkSession.builder().appName(this.getClass.getSimpleName) .master("local[*]") .getOrCreate() import spark.implicits._ val tp: Dataset[(String, String)] = spark.createDataset(List(("aaa", "bbb"), ("aaa", "ccc"), ("aaa", "ddd"))) val df: DataFrame = tp.toDF("f1", "f2") //注册自定义函数 //MY_CONCAT_WS函数名称 //后面传入的scala的函数就是具有的实现逻辑 spark.udf.register("MY_CONCAT_WS", (s: String, first: String, second:String) => { first + s + second }) import org.apache.spark.sql.functions._ //df.selectExpr("CONCAT_WS('-', f1, f2) as f3") //df.select(concat_ws("-", $"f1", 'f2) as "f3").show() //df.selectExpr("MY_CONCAT_WS('_', f1, f2) as f3").show() df.createTempView("v_data") spark.sql( """ |SELECT MY_CONCAT_WS('-', f1, f2) f3 FROM v_data """.stripMargin).show() spark.stop() } }