语法糖
Java语法糖系列,所以首先讲讲什么是语法糖。语法糖是一种几乎每种语言或多或少都提供过的一些方便程序员开发代码的语法,它只是编译器实现的一些小把戏罢了,编译期间以特定的字节码或者特定的方式对这些语法做一些处理,开发者就可以直接方便地使用了。这些语法糖虽然不会提供实质性的功能改进,但是它们或能提高性能、或能提升语法的严谨性、或能减少编码出错的机会。Java提供给了用户大量的语法糖,比如泛型、自动装箱、自动拆箱、foreach循环、变长参数、内部类、枚举类、断言(assert)等
断言(assert)
开启断言
-
用java 命令在console下直接运行class文件,跟 -ea 启动参数即可

参考文章
-
单独给某个程序制定运行参数

-
给整个java运行环境配置默认参数

一、
语法形式
Java2在1.4中新增了一个关键字:assert。在程序开发过程中使用它创建一个断言(assertion),它的
语法形式有如下所示的两种形式:
1、assert condition;
这里condition是一个必须为真(true)的表达式。如果表达式的结果为true,那么断言为真,并且无任何行动
如果表达式为false,则断言失败,则会抛出一个AssertionError对象。这个AssertionError继承于Error对象,
而Error继承于Throwable,Error是和Exception并列的一个错误对象,通常用于表达系统级运行错误。
2、asser condition:expr;
这里condition是和上面一样的,这个冒号后跟的是一个表达式,通常用于断言失败后的提示信息,说白了,它是一个传到AssertionError构造函数的值,如果断言失败,该值被转化为它对应的字符串,并显示出来。
使用示例:

语法改进
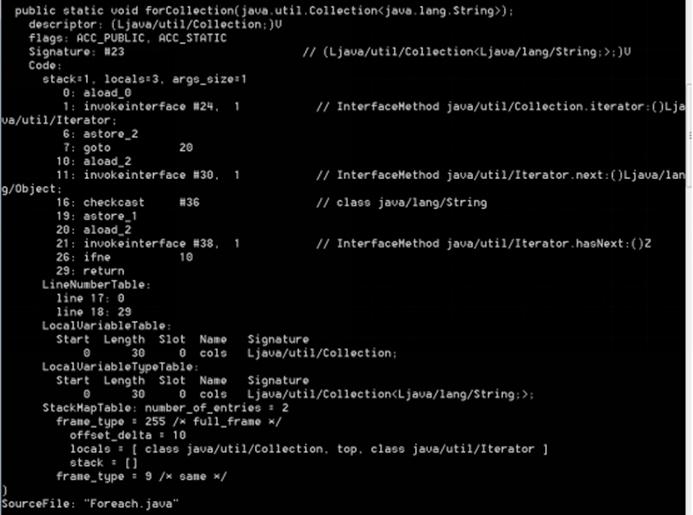
Foreach与变长参数


Foreach和边长参数都是语法糖。
For Array循环是标准的数组下标循环的语法糖。

For Collection 是迭代器的语法糖。



可变长参数,每次都会初始化一个参数长度数组,并申请内存和赋值。在多次调用的情况这个消耗是没有必要且明显的。应当根据提供固定参数个数的方法。
关于返回值的问题。

基本类型拆箱装箱
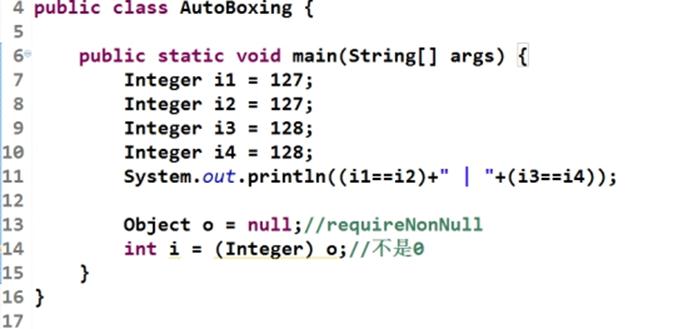

true | false的原因
Integer的享元设计,上限取决于业务数字使用范围。


空指针原因是integer.intValue();这是个对象方法

内部类与资源自动管理


字节码文件中没有其他类信息,只有本类方法和类描述,内部类表

自动关闭资源在字节码文件中还是生成了close方法

泛型(Generic)
支持创建可以按类型进行参数化的类.可以把类型参数看作是使用参数类型时指定的类型占位符,泛型能保证大型应用程序的类型安全和良好的维护性。Java泛型的实现是语法糖,在编译完成后并没有保留参数化类型的信息。因此你可以通过反射获取后添加非泛型数据,当然一般不会这么做。泛型的好处在于:可以定义一类数据集合,进行相同的操作,如果非泛型成员,在编译时候就可以检测;可以在声明时指定具体类型,这样避免写过多的子类。
泛型可以在方法和类(接口、抽象类)上声明。语法为<T> ,T表示泛型,可以是任意字母,一般T便是type类型,E表示元素等。在运行时T已经确定。
数组是协变的,例如:参数类型为Object[],表示可以传任意数组。如果Sub为Super的子类型,那么数组类型Sub[]就是Super[]的子类型。List<Sub>与List<Super>并没有什么关系。
如果进行类型转换,数组在运行时才知道具体的类型,这会导致ArrayStoreException异常,而泛型在编译期间检查错误,确保为某一类型。
泛型的运行时擦除,导致不能定义泛型数组。因为运行时并不保存泛型类型信息。
泛型用法
List<E>、List<?>与原生List。
泛型的上限与下限
枚举
创建枚举类型要使用 enum 关键字,隐含了所创建的类型都是 java.lang.Enum 类的子类(java.lang.Enum 是一个抽象类)。枚举类型符合通用模式 Class Enum<E extends Enum<E>>,而 E 表示枚举类型的名称。枚举类型的每一个值都将映射到 protected Enum(String name, int ordinal) 构造函数中,在这里,每个值的名称都被转换成一个字符串,并且序数设置表示了此设置被创建的顺序。但是并不推荐显示调用序数作为枚举映射列表。
简介
这个例子描述人类的性别,人类的性别记录应该为三种男、女、不确定。枚举的元素是确定的而且在加载类的时候就会初始化为一个对象。枚举对象跟普通的类对象,没有任何区别。你可以增加一个方法,做一些操作。我们一般利用枚举对象是特定做一些除了数据枚举外的高级操作。
枚举中可以只有枚举属性。


每个枚举对象会走对应的构造方法。不能new 枚举对象。通过枚举的官方定义,枚举是按照创建顺序的。

应用
在使用int常量作为枚举是,我们通过大写的名称对应相应的int值,表述此类使用的多个常量。不同类型的int枚举类型可以用命名前缀来区分。这种做法性能好,省力,可读性也很好。但它作为人为的口头约束。如果没有了解约束,放任何int值是可能的,甚至用枚举做运算。外部调用时可能出错。再者,int枚举类型并不能很好的表述含义,它至少一个0,1,2,4等等。你不知道它的名称。
Java的枚举类型,即天然是int值类型,又支持名称的意义。而且枚举作为类,你可以非常方便的拓展需要的成员或者方法。枚举final并不提供实例化的构造器,让它完全避免了反射等可能造成的对象实例受限破坏。枚举的值为顺势的transient,序列化不会造成枚举常量实例多份的危险。设计非常巧妙。
如果需要用枚举做映射,实现高性能的类似位图的枚举映射数据结构可以参考EnumSet<E extends Enum<E>>、EnumMap<K extends Enum<K>,V>。
语法糖的实现
初始化,枚举三原色,成员变量name,index

按需要定义普通方法

枚举中关键的属性

输出结果

利用枚举对象实例的确定性质,枚举元素只有一个就是一个规范的单例,你可以按需定义成员。此种方式可以保证该单例线程安全、防反射攻击、防止序列化生成新的实例。


枚举元素的初始化过程

枚举类编译后的类中没有任何构造方法。自然没办法进行反射new对象。下面是普通对象的构造方法。

枚举禁用clone保证唯一性
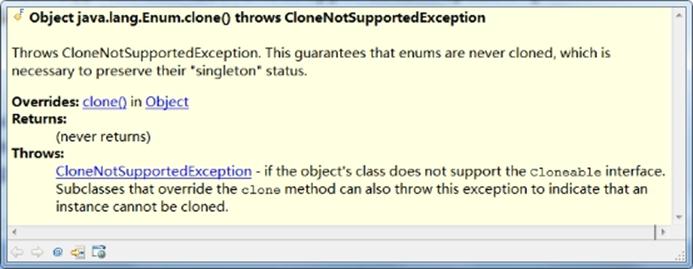
关于序列化的问题
Java枚举序列化不会把枚举对象序列化,只会序列化枚举的名字,反序列化会把常量作为参数。来保证只有枚举对象的唯一性。1.12 Serialization of Enum Constants
枚举的扩展

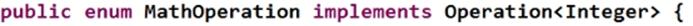




为了方便使用,在接口中添加default方法,需要jdk1.8


这个写法调用两次PLUS,但在编译期间可以检测实例是否是枚举和Operation接口类型。
Lambda
本文介绍了Java SE 8中新引入的lambda语言特性以及这些特性背后的设计思想。这些特性包括:
-
lambda表达式(又被成为"闭包"或"匿名方法")
-
方法引用和构造方法引用
-
扩展的目标类型和类型推导
-
接口中的默认方法和静态方法
1. 背景
Java是一门面向对象编程语言。面向对象编程语言和函数式编程语言中的基本元素(Basic Values)都可以动态封装程序行为:面向对象编程语言使用带有方法的对象封装行为,函数式编程语言使用函数封装行为。但这个相同点并不明显,因为Java的对象往往比较"重量级":实例化一个类型往往会涉及不同的类,并需要初始化类里的字段和方法。不过有些Java对象只是对单个函数的封装。
Lambda表达式是一段可以传递的代码
场景一:线程逻辑



场景二:自定义比较器

 场景三:事件按钮回调
场景三:事件按钮回调

 幻
幻
2. 函数式接口(Functional interfaces)
可以通过@FunctionalInterface注解来显式指定一个接口是函数式接口。 我们选择了"使用已知类型"这条路——因为现有的类库大量使用了函数式接口,通过沿用这种模式,我们使得现有类库能够直接使用lambda表达式。例如下面是Java SE 7中已经存在的函数式接口:
- java.lang.Runnable
- java.util.concurrent.Callable
- java.security.PrivilegedAction
- java.util.Comparator
- java.io.FileFilter
- java.beans.PropertyChangeListener
除此之外,Java SE 8中增加了一个新的包:java.util.function,它里面包含了常用的函数式接口,例如:
- Predicate<T>——接收T对象并返回boolean
- Consumer<T>——接收T对象,不返回值
- Function<T, R>——接收T对象,返回R对象
- Supplier<T>——提供T对象(例如工厂),不接收值
- UnaryOperator<T>——接收T对象,返回T对象
- BinaryOperator<T>——接收两个T对象,返回T对象
- IntSupplier,LongBinaryOperator——原始类型(Primitive type)的特化(Specialization)函数式接口
- BiFunction<T, U, R>——接收T对象和U对象,返回R对象

匿名类型最大的问题就在于其冗余的语法。有人戏称匿名类型导致了"高度问题"(height problem),lambda表达式是匿名方法,它提供了轻量级的语法,从而解决了匿名内部类带来的"高度问题"。
下面是一些lambda表达式:

第一个lambda表达式接收x和y这两个整形参数并返回它们的和;第二个lambda表达式不接收参数,返回整数'42';第三个lambda表达式接收一个字符串并把它打印到控制台,不返回值。
lambda表达式的语法由参数列表、箭头符号->和函数体组成。函数体既可以是一个表达式,也可以是一个语句块:
- 表达式:表达式会被执行然后返回执行结果。
-
语句块:语句块中的语句会被依次执行,就像方法中的语句一样——
- return语句会把控制权交给匿名方法的调用者
- break和continue只能在循环中使用
- 如果函数体有返回值,那么函数体内部的每一条路径都必须返回值
表达式函数体适合小型lambda表达式,它消除了return关键字,使得语法更加简洁。
lambda表达式也会经常出现在嵌套环境中,比如说作为方法的参数。为了使lambda表达式在这些场景下尽可能简洁,我们去除了不必要的分隔符。不过在某些情况下我们也可以把它分为多行,然后用括号包起来,就像其它普通表达式一样。
下面是一些出现在语句中的lambda表达式:

3. 目标类型(Target typing)
对于给定的lambda表达式的类型是由其上下文推导而来,这符合
这就意味着同样的lambda表达式在不同上下文里可以拥有不同的类型:

第一个lambda表达式() -> "done"是Callable的实例,而第二个lambda表达式则是PrivilegedAction的实例。
编译器负责推导lambda表达式的类型。它利用lambda表达式所在上下文所期待的类型进行推导,这个被期待的类型被称为目标类型。lambda表达式只能出现在目标类型为函数式接口的上下文中。
当然,lambda表达式对目标类型也是有要求的。编译器会检查lambda表达式的类型和目标类型的方法签名(method signature)是否一致。当且仅当下面所有条件均满足时,lambda表达式才可以被赋给目标类型T:
- T是一个函数式接口
- lambda表达式的参数和T的方法参数在数量和类型上一一对应
- lambda表达式的返回值和T的方法返回值相兼容(Compatible)
-
lambda表达式内所抛出的异常和T的方法throws类型相兼容
由于目标类型(函数式接口)已经"知道"lambda表达式的形式参数(Formal parameter)类型,所以我们没有必要把已知类型再重复一遍。也就是说,lambda表达式的参数类型可以从目标类型中得出:

在上面的例子里,编译器可以推导出s1和s2的类型是String。此外,当lambda的参数只有一个而且它的类型可以被推导得知时,该参数列表外面的括号可以被省略:

在前三个上下文(变量声明、赋值和返回语句)里,目标类型即是被赋值或被返回的类型:
 数组初始化器和赋值类似,只是这里的"变量"变成了数组元素,而类型是从数组类型中推导得知:
数组初始化器和赋值类似,只是这里的"变量"变成了数组元素,而类型是从数组类型中推导得知: 方法参数的类型推导要相对复杂些:目标类型的确认会涉及到其它两个语言特性:重载解析(Overload resolution)和参数类型推导(Type argument inference)。
方法参数的类型推导要相对复杂些:目标类型的确认会涉及到其它两个语言特性:重载解析(Overload resolution)和参数类型推导(Type argument inference)。重载解析会为一个给定的方法调用(method invocation)寻找最合适的方法声明(method declaration)。由于不同的声明具有不同的签名,当lambda表达式作为方法参数时,重载解析就会影响到lambda表达式的目标类型。编译器会通过它所得之的信息来做出决定。如果lambda表达式具有显式类型(参数类型被显式指定),编译器就可以直接 使用lambda表达式的返回类型;如果lambda表达式具有隐式类型(参数类型被推导而知),重载解析则会忽略lambda表达式函数体而只依赖lambda表达式参数的数量。
如果在解析方法声明时存在二义性(ambiguous),我们就需要利用转型(cast)或显式lambda表达式来提供更多的类型信息。如果lambda表达式的返回类型依赖于其参数的类型,那么lambda表达式函数体有可能可以给编译器提供额外的信息,以便其推导参数类型。

在上面的代码中,ps的类型是List<Person>,所以ps.stream()的返回类型是Stream<Person>。map()方法接收一个类型为Function<T, R>的函数式接口,这里T的类型即是Stream元素的类型,也就是Person,而R的类型未知。由于在重载解析之后lambda表达式的目标类型仍然未知,我们就需要推导R的类型:通过对lambda表达式函数体进行类型检查,我们发现函数体返回String,因此R的类型是String,因而map()返回Stream<String>。绝大多数情况下编译器都能解析出正确的类型,但如果碰到无法解析的情况,我们则需要:
- 使用显式lambda表达式(为参数p提供显式类型)以提供额外的类型信息
- 把lambda表达式转型为Function<Person, String>
- 为泛型参数R提供一个实际类型。(.<String>map(p -> p.getName()))
lambda表达式本身也可以为它自己的函数体提供目标类型,也就是说lambda表达式可以通过外部目标类型推导出其内部的返回类型,这意味着我们可以方便的编写一个返回函数的函数:

类似的,条件表达式可以把目标类型"分发"给其子表达式:
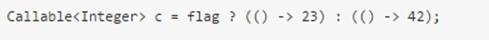
在无法确认目标类型时,转型表达式(Cast expression)可以显式提供lambda表达式的类型:

除此之外,当重载的方法都拥有函数式接口时,转型可以帮助解决重载解析时出现的二义性。
目标类型这个概念不仅仅适用于lambda表达式,泛型方法调用和"菱形"构造方法调用也可以从目标类型中受益,下面的代码在Java SE 7是非法的,但在Java SE 8中是合法的:

局部变量
基于词法作用域的理念,lambda表达式所在上下文中的局部变量不可以重复定义。
在Java SE 7中,编译器对内部类中引用的外部变量(即捕获的变量)要求被声明为final。对于lambda表达式和内部类,我们允许在其中捕获那些符合有效只读(Effectively final)的局部变量。
如果一个局部变量在初始化后从未被修改过,那么它就符合有效只读的要求,换句话说,加上final后也不会导致编译错误的局部变量就是有效只读变量。
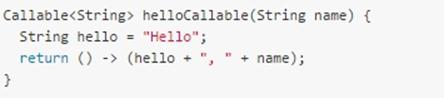
为什么要禁止这种行为呢?因为这样的lambda表达式很容易引起race condition。lambda expressions close over values, not variables:
 lambda表达式不支持修改捕获变量的另一个原因是我们可以使用更好的方式来实现同样的效果:使用规约(reduction)。java.util.stream包提供了各种通用的和专用的规约操作(例如sum、min和max),就上面的例子而言,我们可以使用规约操作(在串行和并行下都是安全的)来代替forEach:
lambda表达式不支持修改捕获变量的另一个原因是我们可以使用更好的方式来实现同样的效果:使用规约(reduction)。java.util.stream包提供了各种通用的和专用的规约操作(例如sum、min和max),就上面的例子而言,我们可以使用规约操作(在串行和并行下都是安全的)来代替forEach:

sum()等价于下面的规约操作:

规约需要一个初始值(以防输入为空)和一个操作符(在这里是加号),然后用下面的表达式计算结果:

规约也可以完成其它操作,比如求最小值、最大值和乘积等等。如果操作符具有可结合性(associative),那么规约操作就可以容易的被并行化。所以,与其支持一个本质上是并行而且容易导致race condition的操作,我们选择在库中提供一个更加并行友好且不容易出错的方式来进行累积(accumulation)。
4. 方法引用(Method references)
方法引用有很多种,它们的语法如下:
- 静态方法引用:ClassName::methodName
- 实例上的实例方法引用:instanceReference::methodName
- 超类上的实例方法引用:super::methodName
- 类型上的实例方法引用:ClassName::methodName
- 构造方法引用:Class::new
- 数组构造方法引用:TypeName[]::new
构造方法也可以通过new关键字被直接引用:

数组的构造方法引用的语法则比较特殊,为了便于理解,你可以假想存在一个接收int参数的数组构造方法。参考下面的代码:

5. 默认方法和静态接口方法(Default and static interface methods)
向函数式接口里增加默认方法,所有实现接口的类都自动继承这个默认方法并调用。
下面的例子展示了如何向Iterator接口增加默认方法skip:

除了默认方法,Java SE 8还在允许在接口中定义静态方法。这使得我们可以从接口直接调用和它相关的辅助方法(Helper method),而不是从其它的类中调用(之前这样的类往往以对应接口的复数命名,例如Collections)。比如,我们一般需要使用静态辅助方法生成实现Comparator的比较器,在Java SE 8中我们可以直接把该静态方法定义在Comparator接口中:
 比如说下面的代码:
比如说下面的代码:

冗余代码实在太多了!
有了lambda表达式,我们可以去掉冗余的匿名类:
 尽管代码简洁了很多,但它的抽象程度依然很差:开发者仍然需要进行实际的比较操作(而且如果比较的值是原始类型那么情况会更糟),所以我们要借助Comparator里的comparing方法实现比较操作:
尽管代码简洁了很多,但它的抽象程度依然很差:开发者仍然需要进行实际的比较操作(而且如果比较的值是原始类型那么情况会更糟),所以我们要借助Comparator里的comparing方法实现比较操作:
 在类型推导和静态导入的帮助下,我们可以进一步简化上面的代码:
在类型推导和静态导入的帮助下,我们可以进一步简化上面的代码:

我们注意到这里的lambda表达式实际上是getLastName的代理(forwarder),于是我们可以用方法引用代替它:

最后,使用Collections.sort这样的辅助方法并不是一个好主意:它不但使代码变的冗余,也无法为实现List接口的数据结构提供特定(specialized)的高效实现,而且由于Collections.sort方法不属于List接口,用户在阅读List接口的文档时不会察觉在另外的Collections类中还有一个针对List接口的排序(sort())方法。
默认方法可以有效的解决这个问题,我们为List增加默认方法sort(),然后就可以这样调用:

此外,如果我们为Comparator接口增加一个默认方法reversed()(产生一个逆序比较器),我们就可以非常容易的在前面代码的基础上实现降序排序。

Lambda(类库篇——Streams API,Collector和并行)
对于 anyMatch(Predicate) 和 findFirst() 这些急性求值操作,我们可以使用短路(short-circuiting)来终止不必要的运算。以下面的流水线为例:

尽管并行是显式的,但它并不需要成为侵入式的。利用 parallelStream() ,我们可以轻松的把之前重量求和的代码并行化:

下面的代码源自JDK中的 Class 类型( getEnclosingMethod 方法),这段代码会遍历所有声明的方法,然后根据方法名称、返回类型以及参数的数量和类型进行匹配:

通过使用流,我们不但可以消除上面代码里面所有的临时变量,还可以把控制逻辑交给类库处理。通过反射得到方法列表之后,我们利用 Arrays.stream 将它转化为 Stream ,然后利用一系列过滤器去除类型不符、参数不符以及返回值不符的方法,然后通过调用 findFirst 得到 Optional<Method> ,最后利用 orElseThrow 返回目标值或者抛出异常。

相对于未使用流的代码,这段代码更加紧凑,可读性更好,也不容易出错。
流操作特别适合对集合进行查询操作。假设有一个"音乐库"应用,这个应用里每个库都有一个专辑列表,每张专辑都有其名称和音轨列表,每首音轨表都有名称、艺术家和评分。
假设我们需要得到一个按名字排序的专辑列表,专辑列表里面的每张专辑都至少包含一首四星及四星以上的音轨,为了构建这个专辑列表,我们可以这么写:

我们可以用流操作来完成上面代码中的三个主要步骤——识别一张专辑是否包含一首评分大于等于四星的音轨(使用 anyMatch );按名字排序;以及把满足条件的专辑放在一个 List 中:

可变的集合操作(Mutative collection operation)
集合上的流操作一般会生成一个新的值或集合。不过有时我们希望就地修改集合,所以我们为集合(例如 Collection , List 和 Map )提供了一些新的方法,比如 Iterable.forEach(Consumer) , Collection.removeAll(Predicate) , List.replaceAll(UnaryOperator) , List.sort(Comparator) 和 Map.computeIfAbsent()。除此之外, ConcurrentMap 中的一些非原子方法(例如 replace 和 putIfAbsent)被提升到 Map 之中。
函数式编程简介
如果你不知道什么是函数式编程,或者不了解map,filter,reduce这些常用的高阶函数。下文是简单介绍。或者找专业资料查阅。
高阶函数:一个函数就接收另一个函数作为参数,这种函数就称之为高阶函数
1.高阶函数之map:
此时我们有一个数组和一个接受一个参数并返回一个数的函数。我们需要把这个数组的每一个值在这个函数上走一遍,从而得到一个新数组。此时就需要map了

2.高阶函数之reduce:
此时我们有一个数组和一个接受两个参数并返回一个数的函数。我们需要把这个数组的每两个值在这个函数上走一遍变成一个值,然后再让这个值继续和下一个值走这个函数,最后从而得到一个值。

3.高阶函数之filter:
此时我们有一个数组,这个数组里面有我们想要的也有我们不想要的,怎么办,我们可以下一个函数,让这些值在这个函数里面走一遍,想要的留下,不想要的去掉,返回一个只有理想数值的数组。此时需要filter

4.高阶函数之sort:
这个就是之前数组里面提到的排序函数,这个也是一个高级函数,默认是从低到高。 通常规定,对于两个元素x和y,如果认为x < y,则返回-1,如果认为x == y,则返回0,如果认为x > y,则返回1,这样,排序算法就不用关心具体的比较过程,而是根据比较结果直接排序。我们可以传入一个函数,让sort从高到低排序
