1 概述
Java 8由Oracle公司于2014年3月18日发布,至今已过去数年之久。然而,直到今日仍有许多软件开发者对其相关特性不了解,这可能主要是Java基础教材更新缓慢的原因。为了使大家对与Java8的特性有全面系统的了解,本公众号将连续几篇文章介绍Java8中的各个特性。
Java8中新增的特性主要有:
- Lambda 表达式 − Lambda允许把函数作为一个方法的参数(函数作为参数传递进方法中。
- 方法引用 − 方法引用提供了非常有用的语法,可以直接引用已有Java类或对象(实例)的方法或构造器。与lambda联合使用,方法引用可以使语言的构造更紧凑简洁,减少冗余代码。
- 默认方法 − 默认方法就是一个在接口里面有了一个实现的方法。
- 新工具 − 新的编译工具,如:Nashorn引擎 jjs、 类依赖分析器jdeps。
- Stream API −新添加的Stream API(java.util.stream) 把真正的函数式编程风格引入到Java中。
- Date Time API − 加强对日期与时间的处理。
- Optional 类 − Optional 类已经成为 Java 8 类库的一部分,用来解决空指针异常。
- Nashorn, JavaScript 引擎 − Java 8提供了一个新的Nashorn javascript引擎,它允许我们在JVM上运行特定的javascript应用。
本文介绍其中的Steam操作。其它特性会在后续文章中陆续介绍。
2 Steam
2.1 概述
Java 8 中的 Stream 是对集合(Collection)对象功能的增强,它专注于对集合对象进行各种非常便利、高效的聚合操作(aggregate operation),或者大批量数据操作 。Stream API 借助于同样新出现的 Lambda 表达式,极大的提高编程效率和程序可读性。
同时它提供串行和并行两种模式进行汇聚操作,并发模式能够充分利用多核处理器的优势,内部使用 fork/join 并行方式来拆分任务和加速处理过程。通常编写并行代码很难而且容易出错, 但使用 Stream API 无需编写一行多线程的代码,就可以很方便地写出高性能的并发程序。
在 Java 7 中,如果要发现 type 为 grocery 的所有交易,然后返回以交易值降序排序好的交易 ID 集合,我们需要这样写:
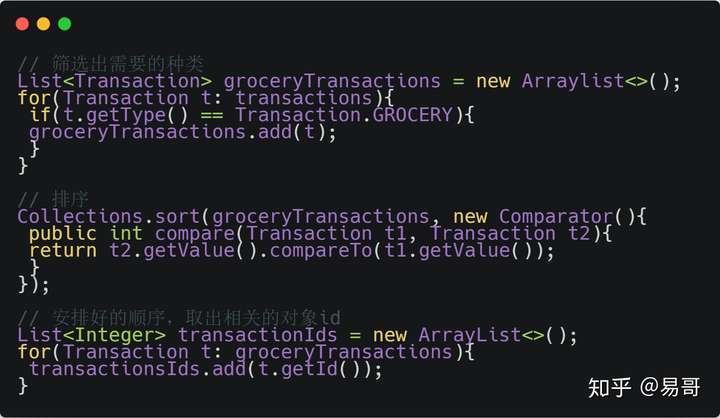
而在 Java 8 使用 Stream,代码更加简洁易读;而且使用并发模式,程序执行速度更快。
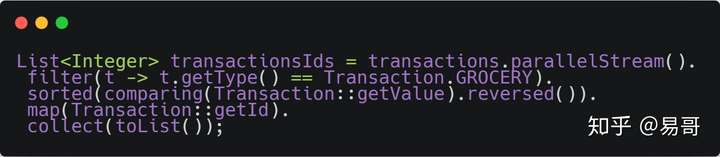
是不是和之前Python做大数据处理时的代码一样!这就是Steam。要注意的是,整个操作不改变transactions本身(好理解,最后的输出都不一定是transactions对象了),最后输出了结果。即整个操作不对数据流产生影响。
Stream 不是集合元素,它不是数据结构并不保存数据,它是有关算法和计算的,它更像一个高级版本的 Iterator。原始版本的Iterator,用户只能显式地一个一个遍历元素并对其执行某些操作;高级版本的Stream,用户只要给出需要对其包含的元素执行什么操作,比如 “过滤掉长度大于 10 的字符串”、“获取每个字符串的首字母”等,Stream 会隐式地在内部进行遍历,做出相应的数据转换。
Stream 就如同一个迭代器(Iterator),单向,不可往复,数据只能遍历一次,遍历过一次后即用尽了,就好比流水从面前流过,一去不复返。而和迭代器又不同的是,Stream 可以并行化操作,迭代器只能命令式地、串行化操作。顾名思义,当使用串行方式去遍历时,每个 item 读完后再读下一个 item。而使用并行去遍历时,数据会被分成多个段,其中每一个都在不同的线程中处理,然后将结果一起输出。Stream 的并行操作依赖于 Java7 中引入的 Fork/Join 框架(JSR166y)来拆分任务和加速处理过程。
Java 的并行 API 演变历程基本如下:
- 1.0-1.4 中的 java.lang.Thread
- 5.0 中的 java.util.concurrent
- 6.0 中的 Phasers 等
- 7.0 中的 Fork/Join 框架
- 8.0 中的 Lambda
2.2 流的组成
当我们使用一个流的时候,通常包括三个基本步骤: 获取一个数据流(source)→ 数据转换→执行操作获取想要的结果。

因此,其实就是一个map reduce过程。具体就是获取数据流、各种map、最后reduce。
2.2.1 数据流的获取
最常用的创建Stream有两种途径:
- 1:通过Stream接口的静态工厂方法(注意:Java8里接口可以带静态方法),有三种:
- 1-1:of方法:有两个overload方法,一个接受变长参数,一个接口单一值:

- 1-2:generator方法:生成一个无限长度的Stream,其元素的生成是通过给定的Supplier(这个接口可以看成一个对象的工厂,每次调用返回一个给定类型的对象)。
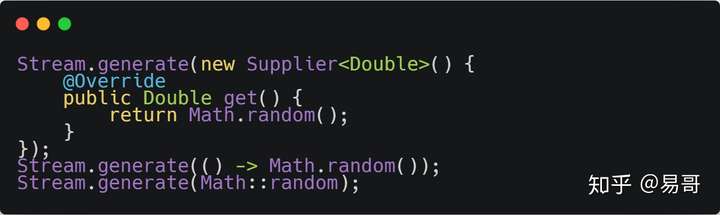
三条语句的作用都是一样的,只是使用了lambda表达式和方法引用的语法来简化代码。每条语句其实都是生成一个无限长度的Stream,其中值是随机的。这个无限长度Stream是懒加载,一般这种无限长度的Stream都会配合Stream的limit()方法来用。
- 1-3:iterate方法:也是生成无限长度的Stream,和generator不同的是,其元素的生成是重复对给定的种子值(seed)调用用户指定函数来生成的。其中包含的元素可以认为是:seed,f(seed),f(f(seed))无限循环

这段代码就是先获取一个无限长度的正整数集合的Stream,然后取出前10个打印。千万记住使用limit方法,不然会无限打印下去。
- 2:通过Collection接口的默认方法stream(),把一个Collection对象转换成Stream。查看Java doc就可以发现Collection接口有一个stream方法,所以其所有子类都都可以获取对应的Stream对象。
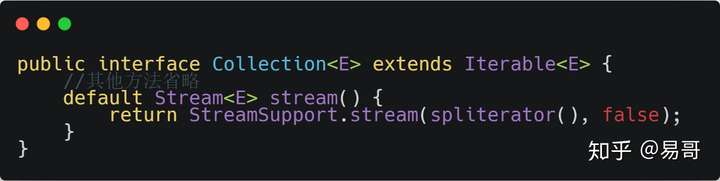
对于基本数值型,目前有三种对应的包装类型 Stream:IntStream、LongStream、DoubleStream。当然我们也可以用 Stream、Stream >、Stream,但是 boxing 和 unboxing 会很耗时,所以特别为这三种基本数值型提供了对应的 Stream。
一个Stream只可以使用一次,否则会报错。
2.2.2 数据转换
数据转换就是指Intermediate操作。一个流可以后面跟随零个或多个 intermediate 操作。其目的主要是打开流,做出某种程度的数据映射/过滤,然后返回一个新的流,交给下一个操作使用。相当于处理管道中的一个环节。
这类操作都是惰性化的(lazy),就是说,仅仅调用到这类方法,并没有真正开始流的遍历,只是定义了管道。
具体的操作指令有: map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel、 sequential、 unordered
2.2.3 执行操作获取想要的结果
执行操作获取想要的结果是terminal操作。一个流只能有一个 terminal 操作,当这个操作执行后,流就被使用“光”了,无法再被操作,所以这必定是流的最后一个操作。
Terminal 操作的执行,才会真正开始流的遍历,并且会生成一个结果。这和Python中的处理是一样的。
具体的操作指令有: forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 iterator
注意:
有一些操作比较特殊,被称为Short-circuiting操作,其特点是:对于一个 intermediate 操作,如果它接受的是一个无限大(infinite/unbounded)的 Stream,但返回一个有限的新 Stream;对于一个 terminal 操作,如果它接受的是一个无限大的 Stream,但能在有限的时间计算出结果。
这些指令已经在上面用下划线标出,具体有: anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 limit
有相同爱好的可以进来一起讨论哦:企鹅群号:1046795523
学习视频资料:http://www.makeru.com.cn/live/1392_1164.html?s=143793