集成学习分成Bagging和Boosting两大类,这里也分成两篇来总结,两个类别的区别如下:
主要根据集成的基学习期生成方式来分的,一个是强依赖关系,串行而成,代表是Boosting。另一种是不存在强依赖关系同时生成,代表是Bagging和随机森林(Random Forest)

一、Bagging
1、步骤
1、在样本中使用重采样选出N个样本(跟原来的样本数量一致,这就导致会重复,没关系)
2、对选出来的这N个样本建立模型,可以是ID3,C4.5,CART,logistic回归,SVM都可以
3、重复第一步,第二步,抽取了M次这么多样本,同时建立了M个模型,根据这M个模型来投票最终的分类结果
2、注意:
这里由于使用重复抽样,所以导致样本会重复
由于有一部分样本没有被抽中,我们把这部分样本叫做袋外数据,可以用来来检测模型的好坏。
从方差—偏差角度上来看,Bagging主要关注降低方差,因此他在不剪枝的决策树和神经网络等若分类器上效果更好
二、随机森林
随机森林是在Bagging基础上做了一部分改进,Bagging只是对于样本使用了重复抽样,随机森林在此基础上,对于特征的选择也做了抽样
1、步骤
1、在样本中使用重采样选出N个样本(跟原来的样本数量一致,这就导致会重复,没关系)
2、对选出来的这N个样本建立模型,可以是ID3,C4.5,CART,logistic回归,SVM都可以,这时候能使用的划分特征数并不是全部,只是其中抽取了一部分,这里的抽取数量一般使用 k = log2(d) 其中d为特征数
这里到底是先选择完属性在建立决策树还是,决策树每个节点都要做一次抽样啊???如果是每个节点都做随机选择,那只能是决策树为基学习器了吧,如果是选做了属性选择在做树建立,那就能用logistic回归或者svm
3、重复第一步,第二步,抽取了M次这么多样本,同时建立了M个模型,根据这M个模型来投票最终的分类结果
三、结合策略
1、平均法
对于数值型输出,常常使用平均法:
简单平均法: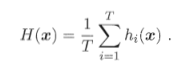 加权平均法:
加权平均法: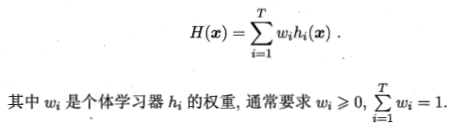
2、投票法


相对多数投票法:其实就是少数服从多数
绝对多数投票法:在相对多数投票法的基础上,我们还要求这个标记的投票数过半,不然就拒绝
加权投票法:各个学习期有一个权重,先加权在求和,选取最大的那个类别
还有一种自己造公式:
3、学习法
学习法的代表是stacking,我们不是对弱学习器的结果做简单的逻辑处理,而是再加上一层学习器,也就是说,我们将训练集弱学习器的学习结果作为输入,将训练集的输出作为输出,重新训练一个学习器来得到最终结果。
也就是说,我们将训练集弱学习器的学习结果作为输入,将训练集的输出作为输出,重新训练一个学习器来得到最终结果。