一,为什么要使用log日志
1.主要是项目运行阶段, 程序员不在现场 不能够看到当时出现的bug 所以把bug先以文档的形式存储在log文件中 . 方便排除错误,日志是我们排查问题, 了解系统状况的重要线索.
2.在日常开发调试过程中,日志也能方便我们快速定位问题
不管是使用何种编程语言,日志输出几乎无处不再。总结起来,日志大致有以下几种用途:
l 问题追踪:通过日志不仅仅包括我们程序的一些bug,也可以在安装配置时,通过日志可以发现问题。
l 状态监控:通过实时分析日志,可以监控系统的运行状态,做到早发现问题、早处理问题。
l 安全审计:审计主要体现在安全上,通过对日志进行分析,可以发现是否存在非授权的操作。
二:log日志的使用
1.当把log日志的架包引入到项目中后,就可以在类中直接创建log对象,并使用它,这根XML配置没有关系
2.只有当需要配置log对象的属性时才需要在XML文件里面进行配置,这样打印出来的log日志就是我们想要的格式和内容


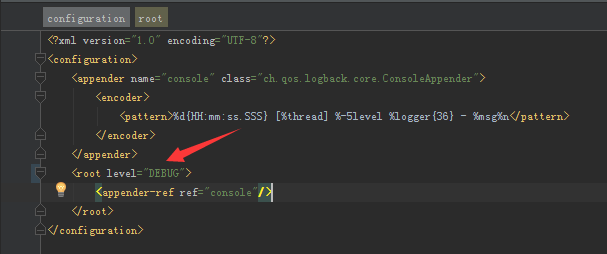
3.箭头所示出表示控制台打印出最小级别log日志,如果这里设置成warn级别,那么debug和INFO级别将被过滤,不会被打印
4.理解
appender:控制日志输出文件的格式,名称,位置等等
logger:控制日志输入内容筛选,哪些日志对象不输出,或输出高级别的日志
root:控制日志数据方式,日志文件,或控制台显示,也可以控制级别(筛选输出内容)
优先级:根据优先级我们可以做组合筛选
多个地方同时配置,日志筛选配置,有冲突和优先级,例如,在application.yml里配置了日志筛选,再在logback-spring.xml里配置,
logback-spring.xml和application.yml 有冲突的配置,以application.yml为准
logger 和 root 配置有冲突时 以logger 配置为准
2 记录Log的基本原则
2.1 日志的级别划分
Java日志通常可以分为:error、warn、info、debug、trace五个级别。在J2SE中预定义的级别更多,分别为:SEVERE、WARNING、INFO、CONFIG、FINE、FINER、FINEST。两者的对应大致如下:
|
Log4j、slf4j |
J2se |
使用场景 |
|
error |
SEVERE |
问题已经影响到软件的正常运行,并且软件不能自行恢复到正常的运行状态,此时需要输出该级别的错误日志。 |
|
warn |
WARNING |
与业务处理相关的失败,此次失败不影响下次业务的执行,通常的结果为外部的输入不能获得期望的结果。 |
|
info |
INFO |
系统运行期间的系统运行状态变化,或关键业务处理记录等用户或管理员在系统运行期间关注的一些信息。 |
|
CONFIG |
系统配置、系统运行环境信息,有助于安装实施人员检查配置是否正确。 |
|
|
debug |
FINE |
软件调试信息,开发人员使用该级别的日志发现程序运行中的一些问题,排除故障。 |
|
FINER |
基本同上,但显示的信息更详尽。 |
|
|
trace |
FINEST |
基本同上,但显示的信息更详尽。 |
2.2 日志对性能影响
不管是多么优秀的日志工具,在日志输出时总会对性能产生或多或少的影响,为了将影响降低到最低,有以下几个准则需要遵守:
l 如何创建Logger实例:创建Logger实例有是否static的区别,在log4j的早期版本,一般要求使用static,而在高版本以及后来的slf4j中,该问题已经得到优化,获取(创建)logger实例的成本已经很低。所以我们要求:对于可以预见的多数情况下单例运行的class,可以不添加static前缀;对于可能是多例居多,尤其是需要频繁创建的class,我们要求要添加static前缀。
l 判断日志级别:
n对于可以预见的会频繁产生的日志输出,比如for、while循环,定期执行的job等,建议先使用if对日志级别进行判断后再输出。
n对于日志输出内容需要复杂的序列化,或输出的某些信息获取成本较高时,需要对日志级别进行判断。比如日志中需要输出用户名,而用户名需要在日志输出时从数据库获取,此时就需要先判断一下日志级别,看看是否有必要获取这些信息。
l 优先使用参数,减少字符串拼接:使用参数的方式输出日志信息,有助于在性能和代码简洁之间取得平衡。当日志级别限制输出该日志时,参数内容将不会融合到最终输出中,减少了字符串的拼接,从而提升执行效率。
2.3 什么时候输出日志
日志并不是越多越详细就越好。在分析运行日志,查找问题时,我们经常遇到该出现的日志没有,无用的日志一大堆,或者有效的日志被大量无意义的日志信息淹没,查找起来非常困难。那么什么时候输出日志呢?以下列出了一些常见的需要输出日志的情况,而且日志的级别基本都是>=INFO,至于Debug级别日志的使用场景,本节没有专门列出,需要具体情况具体分析,但也是要追求“恰如其分”,不是越多越好。
2.3.1 系统启动参数、环境变量
系统启动的参数、配置、环境变量、System.Properties等信息对于软件的正常运行至关重要,这些信息的输出有助于安装配置人员通过日志快速定位问题,所以程序有必要在启动过程中把使用到的关键参数、变量在日志中输出出来。在输出时需要注意,不是一股脑的全部输出,而是将软件运行涉及到的配置信息输出出来。比如,如果软件对jvm的内存参数比较敏感,对最低配置有要求,那么就需要在日志中将-Xms -Xmx -XX:PermSize这几个参数的值输出出来。
2.3.2 异常捕获处
在捕获异常处输出日志,大家在基本都能做到,唯一需要注意的是怎么输出一个简单明了的日志信息。这在后面的问题问题中有进一步说明。
2.3.3 函数获得期望之外的结果时
一个函数,尤其是供外部系统或远程调用的函数,通常都会有一个期望的结果,但如果内部系统或输出参数发生错误时,函数将无法返回期望的正确结果,此时就需要记录日志,日志的基本通常是warn。需要特别说明的是,这里的期望之外的结果不是说没有返回就不需要记录日志了,也不是说返回false就需要记录日志。比如函数:isXXXXX(),无论返回true、false记录日志都不是必须的,但是如果系统内部无法判断应该返回true还是false时,就需要记录日志,并且日志的级别应该至少是warn。
2.3.4 关键操作
关键操作的日志一般是INFO级别,如果数量、频度很高,可以考虑使用DEBUG级别。以下是一些关键操作的举例,实际的关键操作肯定不止这么多。
n 删除:删除一个文件、删除一组重要数据库记录……
n 添加:和外系统交互时,收到了一个文件、收到了一个任务……
n 处理:开始、结束一条任务……
n ……
2.4 日志输出的内容
l ERROR:错误的简短描述,和该错误相关的关键参数,如果有异常,要有该异常的StackTrace。
l WARN:告警的简短描述,和该错误相关的关键参数,如果有异常,要有该异常的StackTrace。
l INFO:言简意赅地信息描述,如果有相关动态关键数据,要一并输出,比如相关ID、名称等。
l DEBUG:简单描述,相关数据,如果有异常,要有该异常的StackTrace。
在日志相关数据输出的时要特别注意对敏感信息的保护,比如修改密码时,不能将密码输出到日志中。
2.5 什么时候使用J2SE自带的日志
我们通常使用slf4j或log4j这两个工具记录日志,那么还需要使用J2SE的日志框架吗?当然需要,在我们编写一些通用的工具类时,为了减少对第三方的jar包的依赖,首先要考虑使用java.util.logging。
考虑到slf4j等日志框架提供了日志bridge工具,为java.util.logging提供了Handler,所以普通应用的开发过程中也可以考虑使用J2SE自有日志,这样不但可以减少项目的编译依赖,同时在应用实施时可以更灵活的选择日志的输出工具包。
3 典型问题分析
3.1 该用日志的地方不用
上图对异常的处理直接使用e.printStackTrace()显然是有问题的,正确的做法是:要么通过日志方式输出错误信息,要么直接抛出异常,要么创建新的自定义异常抛出。
另:对于静态工具类函数中的异常处理,最简单的方式就是不捕获、不记录日志,直接向上抛出,如果认为异常类型太多,或者意义不明确,可以抛出自定义异常类的实例。
3.2 啰嗦重复、没有重点
首先上面不应该有error级别的日志。
其次在日志中直接输出e.toString(),为定位问题提供的信息太少。
另外需要明确一点:日志系统是一个多线程公用的系统,在两行日志输出之间有可能会被插入其他线程的日志记录,不会按照我们的意愿顺序输出,后面有更典型的例子。
最后,上面的日志可以简化为:
logger.debug(“从properties中...{}...{}...”,name, value, e);
logger.warn(“从properties中获取{}发生错误:{}”,name, e.toString());
或者直接一句:
logger.warn(“从properties中...{}...{}...”,name, value, e);
或者更完美的:
if(logger.isDebugEnabled()){
logger.warn(“从properties中...{}...”, name, e);
}else{
logger.warn(“从properties中获取{}发生错误:{}”, name, e.toString());
}
3.3 日志和异常处理的关系
首先上面的日志信息不够充分,级别定义不够恰当。
另外,既然将异常捕获并记录的日志,就不应该重新将一个一模一样的异常再次抛出去了。如果将异常再次抛出,那在上层肯定还需要对该异常进行处理,并记录日志,这样就重复了。如果没有特别原因,此处不应该捕获异常。
3.4 System.out方式的日志
上面的日志形式十分随意,只适合临时的代码调试,不允许提交到正式的代码库中。
对于临时调试日志,建议在日志的输出信息中添加一些特殊的连续字符,也可以用自己的名称、代号,这样可以在调试完毕后,提交代码之前,方便地找到所有临时代码,一并删除。
3.5 日志信息不明确
上面的“添加任务出错。。。”既没有记录任务id,也没有任务名称,软件部署后发现错误后,根据该日志记录不能确认哪一条任务错误,给进一步的分析原因带来困难。
另外第二个红圈中的问题有:要使用参数;一行日志就可以了。
还有一些其他共性的错误,就不多说了。
3.6 忘记日志输出是多线程公用的
如果有另外一个线程正在输出日志,上面的记录就会被打断,最终显示输出和预想的就会不一致。正确的做法应是将这些信息放到一行,如果需要换行可以考虑使用“
”,如果内容较多,考虑增加if (logger.isDebugEnabled())进行判断。而第二个例子中的输出有System.out的习惯,相关内容应该一行完成。
3.7 多个参数的处理
对于多参的日志输出,可以考虑:
public void debug(String format, Object... arguments);
但是在使用多参时,会创建一个对象数组,也会有一定的消耗,为此,在对性能敏感的场景,可以增加对日志级别的判断。
(一)log4j的用途:可以用来做日志文件,即可以往.log文件中输入我们在程序中运行的一些数据,比如说:你往数据库里面保存了一条信息,同样,你也可以用log4j的日志文件来记录你所保存的信息,并且更完整,可以包含1、保存的时间 2、调用的函数 3、自己想记录、保存什么信息 等等 这些都是可以的。
Log4j由三个重要的组成构成:日志记录器(Loggers),输出端(Appenders)和日志格式化器(Layout)。
A).Logger对象的获得或创建:
Logger被指定为实体,由一个String类的名字识别。Logger的名字是大小写敏感的,且名字之间具有继承关系,子名用父名作为前缀,用点“.”分隔,例如x.y是x.y.z的父亲。
root Logger(根Logger)是所有Logger的祖先,它有如下属性:
1.它总是存在的。
2.它不可以通过名字获得。
B)日志级别
每个Logger都被了一个日志级别(log level),用来控制日志信息的输出。日志级别从高到低分为:
A:off 最高等级,用于关闭所有日志记录。
B:fatal 指出每个严重的错误事件将会导致应用程序的退出。
C:error 指出虽然发生错误事件,但仍然不影响系统的继续运行。
D:warm 表明会出现潜在的错误情形。
E:info 一般和在粗粒度级别上,强调应用程序的运行全程。
F:debug 一般用于细粒度级别上,对调试应用程序非常有帮助。
G:all 最低等级,用于打开所有日志记录。
C)输出端Appender
Appender用来指定日志信息输出到哪个地方,可以同时指定多个输出目的地。Log4j允许将信息输出到许多不同的输出设备中,一个log信息输出目的地就叫做一个Appender。
每个Logger都可以拥有一个或多个Appender,每个Appender表示一个日志的输出目的地。可以使用Logger.addAppender(Appender app)为Logger增加一个Appender,也可以使用Logger.removeAppender(Appender app)为Logger删除一个Appender。
以下为Log4j几种常用的输出目的地。
a:org.apache.log4j.ConsoleAppender:将日志信息输出到控制台。
b:org.apache.log4j.FileAppender:将日志信息输出到一个文件。
c:org.apache.log4j.DailyRollingFileAppender:将日志信息输出到一个日志文件,并且每天输出到一个新的日志文件。
d:org.apache.log4j.RollingFileAppender:将日志信息输出到一个日志文件,并且指定文件的尺寸,当文件大小达到指定尺寸时,会自动把文件改名,同时产生一个新的文件。
e:org.apache.log4j.WriteAppender:将日志信息以流格式发送到任意指定地方。
f::org.apache.log4j.jdbc.JDBCAppender:通过JDBC把日志信息输出到数据库中。