前言,在列表查询中,分页查询是必不可少的,(因为SQLServer版本也是不断更新的,所以有的方式低版本不支持),本文总结下SQLServer分页的几种方式,及拉姆达表达式分页,
ROW_NUMBER() OVER()方式:
示例:
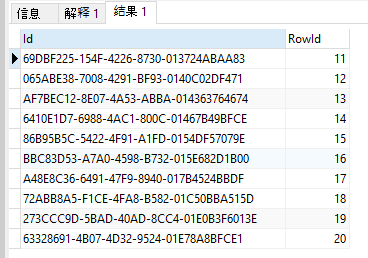
SELECT * FROM ( SELECT Id,ROW_NUMBER ( ) OVER ( ORDER BY StartDate ) AS RowId FROM Task ) AS r WHERE RowId BETWEEN 11 AND 20
备注:用子查询新增了一列RowId,外层结果集用Between关键词(这里表字段只查询了Id列),注意到between是从11~20,因为第二页是从11 开始的
查询结果如下:
总结:
SELECT * FROM ( SELECT *, ROW_NUMBER ( ) OVER ( ORDER BY 排序字段) AS RowId FROM 表名) AS r WHERE RowId BETWEEN (pageIndex-1)*pageSize + 1 AND pageIndex * PageSize
offset fetch next方式(SQL2012以上的版本才支持:推荐使用 )
示例:
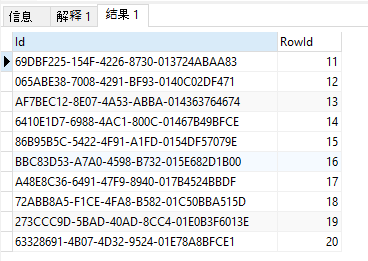
SELECT Id, ROW_NUMBER ( ) OVER ( ORDER BY StartDate ) AS RowId FROM Task ORDER BY StartDate offset 10 ROWS FETCH NEXT 10 ROWS ONLY
备注:offset 是跳过多少行,next是取接下来的多少行(为方便看效果,这里ROW_NUMBER 只负责显示序号,不做分页使用),句式 offset...rows fetch nect ..rows only ,注意rows和末尾的only 不要写漏掉了
查询结果如下:
注:(这种方式必须要接着Order by XX 使用,不然会报错)
SELECT * FROM 表名 ORDER BY 排序字段 offset ( pageIndex - 1 ) * pageSize ROWS FETCH NEXT pageSize ROWS ONLY
top not in方式 (适应于数据库2012以下的版本 不推荐)
示例:
SELECT TOP 10 Id, ROW_NUMBER ( ) OVER ( ORDER BY StartDate ) AS RowId FROM Task WHERE Id NOT IN ( SELECT TOP 10 Id FROM Task )
备注:这里用到了子查询,SQL语句翻译过来就是 查询ID不在前10行的前十条数据,也就是跳过前10行取10行数据
查询结果如下:

注:查询结果RowId是1~10而不是11~20 是因为我们排除了前十行后重新对结果集用的ROW_NUMBER排序,结果可以参照上面两种方式的Id列是一致的
总结:
SELECT TOP pageSize Id, ROW_NUMBER ( ) OVER ( ORDER BY StartDate ) AS RowId FROM Task WHERE Id NOT IN ( SELECT TOP (pageSize-1)*pageIndex Id FROM Task )
用存储过程的方式进行分页 不推荐
示例:
Create procedure GetData @tablename varchar(20), @sortName varchar(20), @descStr varchar(20), @pageIndex int, @pageSize int AS declare @newspage int, @res varchar(200) begin set @newspage=@pageSize*(@pageIndex - 1) set @res='select Id,ROW_NUMBER ( ) OVER ( ORDER BY '+@sortName+' '+@descStr+' ) AS RowId from ' +@tablename+ ' ORDER BY '+@sortName+' '+@descStr+' offset '+CAST(@newspage as varchar(10)) +' rows fetch next '+ CAST(@pageSize as varchar(10)) +' rows only' exec(@res) end
备注:从存储过程可以看出实质是还是采用的offset fetch next 方式,所以存储过程的方式只是提供一种思路,
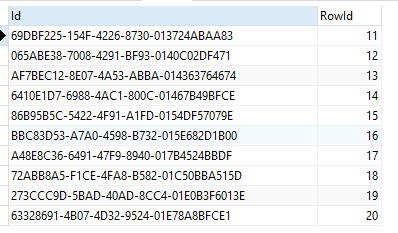
Navicat调用:

结果如下:
查询窗口调用:
EXEC GetData 'Task','StartDate','',2,10
Lambda表达式分页
示例:
List<int> list = new List<int>(); for (int i = 0; i < 100; i++) { list.Add(i); } list = list.Skip(11).Take(10).ToList(); //返回值 11,12,13,14,15,16,17,18,19,20
备注:Skip: 表示从第pageIndex * pageSize + 1条数据开始,也就是说再这之前有pageIndex * pageSize条数据。
Task:表示拿多少条数据
总结:
list = list.Skip(pageIndex * pageSize +1 ).Take(pageSize).ToList();
以上就是数据查询中经常用到的方式,在数据库版本支持的情况下个人推荐程度排序:offset fetch netct > lambda > between > top > procdure
d