T-SQL语言
按用途分四部分
- 数据定义语言(CREATE,DROP,ALTER)
- 数据操作语言(INSERT,DELETE,UPDATE)
- 数据查询语言(SELECT)
- 数据控制语言(GRANT,REVOKE,DENY)
数据类型
- 系统数据类型
- 用户自定义数据类型(建立方式:a.图形化方式 b.命令方式)
1 use TEST 2 EXEC sp_addtype sno,'varchar(10)','nonull' 3 EXEC sp_droptype sno
变量
命名规则:
字母、下划线、@或#开头,但不能全为下划线、@或#
不能为“关键字”,不能嵌入空格及其他特殊字符,如需使用则需要双引号或方括号括起
1.局部变量:
由用户声明,必须以@开头,只在定义该变量的过程中有效,局部变量必须先声明后使用
注意:
- 第一次声明变量时,其值设置为NULL。
- 局部变量不能使用“变量=变量值”的格式进行初始化,必须使用SELECT或SET语句来设置其初始值。
- 如果声明字符型的局部变量,一定要在变量类型中指明其最大长度,否则系统默认其长度为1。
- 若要声明多个局部变量,请在定义的第一个局部变量后使用一个逗号,然后指定下一个局部变量名称和数据类型。
1 USE student 2 DECLARE @var1 char(10),@var2 int 3 SET @var1='number' 4 select @var2=cgrade 5 from sc 6 where sno='201810010' 7 8 print @var1+"s"
2.全局变量:
由系统定义,供SQL server系统内部使用的变量,任何程序任何时间都可以调用。通常以“@@”开头。

T-SQL语句
1.注释语句
(1) --
(2) /*……*/
2.批处理--GO
3.控制流程语句
(1) begin...end语句(相当于C语言中的{} )
(2) if...else语句(可嵌套)
(3)case语句(多条件选择语句)


(4)print语句(屏幕输出语句)
(5)while语句(有条件的循环语句)
(6)goto语句(无条件跳转语句)
(7)break语句
(8)continue语句
4.常用函数(系统函数、用户自定义函数)
一些系统函数:
(1)字符串函数
(2)数学函数

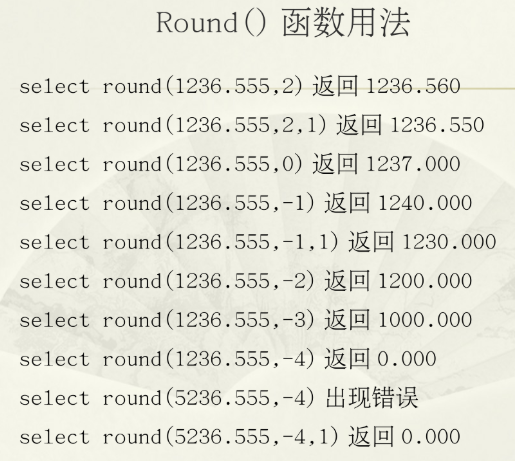
(3)日期和时间函数
(4)聚合函数
注意:


用户自定义函数:
1.分类:
标量值函数:返回单个值
内联表值函数:返回可更新的表
多语句表值函数:返回不可更新的表
2.标量值函数命令方式创建
1 CREATE FUNCTION f2(@a real,@b real) 2 RETURNS real 3 AS 4 BEGIN 5 IF @a>=@b 6 RETURN @a 7 RETURN @b 8 END 9 10 PRINT '最大值为' 11 PRINT dbo.f2(77,56)
1 CREATE FUNCTION f3(@n real) 2 RETURNS real 3 AS 4 BEGIN 5 DECLARE @i real,@sum real 6 SET @i=0 7 SET @sum=0 8 WHILE @i<@n 9 BEGIN 10 SET @i=@i+1 11 SET @sum=@sum+@i 12 END 13 RETURN @sum 14 END 15 16 PRINT dbo.f3(10)
3.自定义函数的调用
(1)标量值函数可以使用select、print、exec调用
(2)表值函数只能用select调用
4.删除方式
drop function 函数名
数据库
数据库概述
1.数据库常用对象:
表、数据类型、视图、索引、存储过程、触发器
系统数据库:
master、model、tempdb、msdb
2.数据库存储结构(数据库文件、数据库文件组):
数据库文件:
存放数据库数据和数据库对象的文件。一个数据库文件只属于一个数据库。
(1)主数据文件
是数据库的起点,指向数据库中文件的其他部分。每个数据库都有一个主数据文件。主数据文件的扩展名是 .mdf
(2)次数据文件
包含除主数据文件外的其他数据文件。有些数据库可能没有次数据文件,而有些数据库则有多个次数据文件。次数据文件的扩展名是 .ndf
(3)日志文件
包含恢复数据库所需的所有日志信息。每个数据库必须至少有一个日志文件,但可以不止一个。日志文件的扩展名是 .ldf
数据库文件组:
文件组允许多个数据库文件组成一个组,并对它们整体进行管理。
文件组是将多个数据文件集合起来形成的一个整体(主文件组+次文件组)
一个数据文件只能存在于一个文件组中,一个文件组也只能被一个数据库使用
日志文件不分组,他不属于任何文件组
创建数据库

1 CREATE DATABASE student 2 ON PRIMARY 3 ( 4 NAME=student_data, 5 FILENAME='d:student_mdf.mdf', 6 SIZE=20, 7 MAXSIZE=unlimited, 8 FILEGROWTH=25% 9 ), 10 ( 11 NAME=student_data1, 12 FILENAME='d:student_ndf.ndf', 13 SIZE=20, 14 MAXSIZE=25, 15 FILEGROWTH=25% 16 ) 17 LOG ON 18 ( 19 NAME=student_log1, 20 FILENAME='d:student_ldf1.ldf', 21 SIZE=3, 22 MAXSIZE=10, 23 FILEGROWTH=1 24 ), 25 ( 26 NAME=student_log2, 27 FILENAME='d:student_ldf2.ldf', 28 SIZE=3, 29 MAXSIZE=10, 30 FILEGROWTH=1 31 )
修改数据库

ALTER DATABASE 语句的选项较多,但一次只能选择其中一项,所以还是比较简单的。





删除数据库
对于不再使用的数据库应该删除它以释放数据库所占用的存储空间。
只有处于正常状态下的数据库,才能使用drop语句删除(当数据库正在使用或正在恢复等不能删除)
DROP DATABASE tsg1,tsg2,tsg3
表
表的概述
数据表也简称为表,它是数据库中唯一用来存储数据的对象,是整个数据库的核心和基础。
1.数据库与数据表的关系
- 数据库包含数据表,一个数据库可以包含多个数据表。数据表是数据库的对象。
- 一个数据库对应一个文件。一个数据库对应一个主题。
- 先创建数据库,再创建数据表。先打开数据库,再打开数据表。
2.数据表的组织
不同的数据模型组织表的方式不同,在基于关系模型创建的数据表中,数据是以行和列的形式进行组织和保存的,我们也称为“二维表”。
3.数据表的组成
数据表一般由以下三部分组成
(1)表名
表名既用于概括表中的信息,也方便引用。可以根据需要对表重新命名,但重新命名前,需要将数据表关闭。
(2)表结构
所谓表结构就是不包括任何记录的数据表,也称为“空表”。空表通常只有字段名及其属性,没有任何数据。
(3)表记录
数据表中除字段名外的每行称为一条“记录”。
每一条记录的内容由其对应的数据项组成,反应某个事物相关信息的原始数据。
只有在建立了表结构后才能向表中输入记录。记录的内容随时可以根据需要更改。
4.数据表的创建与修改
创建表的过程,实际上是定义表的结构,确定表的组织形式的过程。
具体讲就是定义表中属性的个数、属性名、属性的数据类型、属性大小、定义索引、主键以及完整性等。
在创建表之前要设计号表的结构,确定上述内容,并确定无误才开始具体的建表操作。
SQL语句创建表

1 USE stu 2 CREATE TABLE student 3 ( 4 sno varchar(10) not null primary key, 5 sname varchar(20) , 6 sgender char(2) , 7 sage int , 8 sdept varchar(20) 9 ) 10 11 USE stu 12 CREATE TABLE course 13 ( 14 cno varchar(10) not null primary key, 15 cname varchar(20) , 16 ccredit smallint 17 ) 18 19 USE stu 20 CREATE TABLE sc 21 ( 22 sno varchar(10) not null, 23 cno varchar(10) not null, 24 cgrade smallint , 25 primary key(sno,cno), 26 foreign key (sno) references student(sno), 27 foreign key (cno) references course(cno) 28 )
SQL语句修改表结构

SQL语句删除表

SQL语句插入元组


SQL语句修改表

SQL语句删除元组

视图
视图的概念
视图概述
视图(View) 是一种数据库对象,是从若千个表或已经存在的视图中按照某种条件提取的数据组成的“虚表”。
之所以说它是“虚表”,是因为视图本身并不保存任何数据,其数据仍然存储在视图所引用的基本表中。
相对于视图,我们将以前所学过的数据表称为基本表。
视图和表类似,也是包括被定义的数据列和多个数据行,但这些数据列和数据行是建立在对基本表查询的基础上的,就本质而言,这些数据行和列来源于视图所引用的表。被引用的表也称为“数据源”。
在数据库中保存的视图实际上是创建视图时提取数据的规则和方法!
视图可以是一个数据表的一部分,也可以是多个基表的联合。
关于视图
- 视图一经定义便存储在数据库中,其保存的是视图创建的方法和提取数据的规则。
- 只有在运行视图时,才能看到视图中的数据, 这些数据在运行视图时按照某种条件从指定的数据源提取,并按视图定义的布局显示出来。
- 当通过视图对所看到的数据进行修改时,其所引用的数据源中的数据也会发生变化。反之,当数据源中的数据发生变化时,这种变化后的数据将自动反映到视图中。因此视图与其引用的数据源(基本表、 已经存在的视图)是彼此相关联的。
视图的优点
与表相比较,视图具有如下优点:
(1)视图可以屏蔽数据的复杂性,简化用户对数据库的操作。
(2)视图可以让不同的用户以不同的方式看到不同或者相同的数据集。利用视图对数据源的数据直观地进行浏览和编辑。
(3)可以使用视图重新组织数据。根据需要从指定数据源中提取满足条件的数据,从而实现定制数据。
(4)从若干个表或视图中提取更多、更有用的综合信息,从而实现高效率地处理、加工数据。
(5)可以对提取的数据进行浏览、筛选、排序、检索、统计和更新等操作。
(6)视图可以定制不同用户对数据的访问权限。
视图与表的区别
1.视图是已经编译好的SQL语句,而表不是。
2.视图不保存数据记录,而表保存数据记录。
3.视图是查看数据表的一种方式,只是一些SQL语句的集合。
4.表是实表,视图是虚表。
5.视图的创建和删除只影响视图本身,不影响其引用的表。
使用CREATE VIEW 命令创建视图
使用Transact-SQL语句中的CREATE VIEW 命令创建视图,其语法形式如下:
CREATE VIEW <视图名> [(字段名)[,……n]]
[WITH ENCRYPTION] ] --对视图进行加密
AS
SELECT sname, sdept
FROM studentinfo
WHERE sdept = 'cs'
[WITH CHECK OPTION]
说明:
[WITH ENCRYPTION] --对视图进行加密
[WITH CHECK OPTION] --强制针对视图执行的所有数据修改语句必须符合在子查询中设置的条件
例:在产品销售数据库CPXS中创建价格不大于2000的有关产品情况的视图VIEW_CP_PRICE2000,要求加密并保证对该视图的更新都要符合价格不大于2000这个条件
USE CPXS go create view VIEW_CP_PRICE2000 with encryption -- 加密 as select * from 产品 where 价格<=2000 with check option -- 检查
例:基于VIEW_GMQK视图,查询各客户在2006年10月9日购买产品的情况。
USE CPXS select * from VIEW_GMQK where 销售日期='2006-10-09'
例:利用T-SQL语句对于视图VIEW_CP_PRICE2000进行以下数据更新。(1)插入一条产品记录( '0042','数码相机',1500,2)(2)删除产品编号为’ 0042’的产品
USE CPXS insert into VIEW_CP_PRICE2000 values('0042','数码相机',1500,2) USE CPXS delete from VIEW_CP_PRICE2000 where 产品编号='0042'
例:将VIEW_CP_PRICE2000视图不加密。
USE CPXS go alter view VIEW_CP_PRICE2000 as select * from 产品 where 价格<=2000 with check option
例:将VIEW-GMQK视图删除。
USE CPXS go drop view VIEW_GMQK
例:对产品表,在产品名称上定义一个唯一非聚簇的索引ind_cp,降序。
USE CPXS create unique nonclustered index ind_cp on 产品(产品名称 DESC)
例:通过执行系统存储过程,显示产品表的索引文本。
exec sp_helpindex 产品
exec sp_rename 原视图名称, 新视图名称
use 学生课程数据库 go exec sp_rename 'old_name','new_name'
例:删除ind_cp索引。
USE CPXS drop index 产品.ind_cp