一、MySQL 导入数据库
-
创建数据库 -
mysql> CREATE DATABASE IF NOT EXISTS jialedb DEFAULT CHARSET utf8 COLLATE utf8_general_ci; mysql> use jialedb;
- 导入数据库
-
导入数据库
测试导入结果
-
 测试
测试
mysql> select city,phone,country from `offices`; +---------------+------------------+-----------+ | city | phone | country | +---------------+------------------+-----------+ | San Francisco | +1 650 219 4782 | USA | | Boston | +1 215 837 0825 | USA | | NYC | +1 212 555 3000 | USA | | Paris | +33 14 723 4404 | France | | Beijing | +86 33 224 5000 | China | | Sydney | +61 2 9264 2451 | Australia | | London | +44 20 7877 2041 | UK | +---------------+------------------+-----------+
二、查询数据
- select 语句简介
- 使用
SELECT语句从表或视图获取数据。表由行和列组成,如电子表格。 通常,我们只希望看到子集行,列的子集或两者的组合。SELECT语句的结果称为结果集,它是行列表,每行由相同数量的列组成。 - 我们来看一下
select语句的语法: -
SELECT column_1, column_2, ... FROM table_1 [INNER | LEFT |RIGHT] JOIN table_2 ON conditions WHERE conditions GROUP BY column_1 HAVING group_conditions ORDER BY column_1 LIMIT offset, length;
SELECT语句由以下列表中所述的几个子句组成:- select之后是逗号分隔列或星号(
*)的列表,表示要返回所有列。 from指定要查询数据的表或视图。join根据某些连接条件从其他表中获取数据。where过滤结果集中的行。group by将一组行组合成小分组,并对每个小分组应用聚合函数。having过滤器基于GROUP BY子句定义的小分组。order by指定用于排序的列的列表。limit限制返回行的数量。
- select之后是逗号分隔列或星号(

select 语句示例:
SELECT lastname, firstname, jobtitle FROM employees;
- MySQL distinct 子句简介
- 从表中查询数据时,可能会收到重复的行记录。为了删除这些重复行,可以在
SELECT语句中使用DISTINCT子句。 - distinct 子句语法如下:
-
select distinct columns from table_name where where_conditions;
示例:
-
select distinct state,city from customers where state is not null order by state,city;
以上示例,表示从customers 表中获取城市(city)和州(state)的唯一组合;
- distinct 和聚合函数示例:
SELECT COUNT(DISTINCT state) FROM customers WHERE country = 'USA';
- distinct 与 limit 子句示例:
- 以下查询
customers表中的前3个非空(NOT NULL)唯一state列的值
SELECT DISTINCT state FROM customers WHERE state IS NOT NULL LIMIT 3;
- 过滤数据
- where 语句
- 示例:
- 假设只想从
employees表中获取销售代表员工,可使用以下查询: -
SELECT lastname, firstname, jobtitle FROM employees WHERE jobtitle = 'Sales Rep';
要在办公室代码(
officeCode)等于1中查找所有销售代表,请使用以下查询: -
SELECT lastname, firstname, jobtitle FROM employees WHERE jobtitle = 'Sales Rep' AND officeCode = 1;
下表列出了可用于在
WHERE子句中形成过滤表达式的比较运算符。操作符 描述 =等于,几乎任何数据类型都可以使用它。 <>或!=不等于 <小于,通常使用数字和日期/时间数据类型。 >大于, <=小于或等于 >=大于或等于 - 以下查询使用不等于(!=)运算符来获取不是销售代表的其它所有员工:
-
SELECT lastname, firstname, jobtitle FROM employees WHERE jobtitle <> 'Sales Rep';
and 运算符 例如,以下查询返回位于美国加州的客户,并且信用额度大于
100K。 -
SELECT customername, country, state, creditlimit FROM customers WHERE country = 'USA' AND state = 'CA' AND creditlimit > 100000;
OR运算符 - 以下声明返回位于美国(
USA)或者法国(France),并且信用额度大于10000的客户。 -
SELECT customername, country, creditLimit FROM customers WHERE (country = 'USA' OR country = 'France') AND creditlimit > 100000;
IN运算符 -
SELECT column1,column2,... FROM table_name WHERE (expr|column_1) IN ('value1','value2',...);
in 示例:
- 如果您想查找位于美国和法国的办事处,可以使用
IN运算符作为以下查询: -
SELECT officeCode, city, phone, country FROM offices WHERE country IN ('USA' , 'France');
- 要获得不在美国和法国的办事处,请在
WHERE子句中使用NOT IN如下: -
SELECT officeCode, city, phone FROM offices WHERE country NOT IN( 'USA', 'France');
-
in 子查询
IN运算符通常用于子查询。子查询不提供常量值列表,而是提供值列表。我们来看看两张表:
orders和orderDetails表的结构以及它们之间的关系: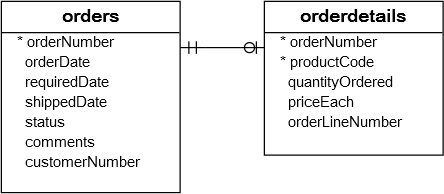
例如,如果要查找总金额大于
60000的订单,则使用IN运算符查询如下所示: -
SELECT orderNumber, customerNumber, status, shippedDate FROM orders WHERE orderNumber IN (SELECT orderNumber FROM orderDetails GROUP BY orderNumber HAVING SUM(quantityOrdered * priceEach) > 60000);
between 运算符
BETWEEN运算符允许指定要测试的值范围。 我们经常在SELECT,INSERT,UPDATE和DELETE语句的WHERE子句中使用BETWEEN运算符。- 示例:
- 假设您想要查找价格在
90和100(含90和100)元范围内的商品,可以使用BETWEEN运算符作为以下查询: -
SELECT productCode, productName, buyPrice FROM products WHERE buyPrice BETWEEN 90 AND 100;
要查找购买价格不在
20到100(含20到100)之间的产品,可将BETWEEN运算符与NOT运算符组合使用,如下: -
SELECT productCode, productName, buyPrice FROM products WHERE buyPrice NOT BETWEEN 20 AND 100;
between 与 日期类型数据示例:
- 例如,要查询获取所需日期(
requiredDate)从2013-01-01到2013-01-31的所有订单,请使用以下查询: -
SELECT orderNumber, requiredDate, status FROM orders WHERE requireddate BETWEEN CAST('2013-01-01' AS DATE) AND CAST('2013-01-31' AS DATE);
like 运算符
-
MySQL提供两个通配符,用于与
LIKE运算符一起使用,它们分别是:百分比符号 -%和下划线 -_。- 百分比(
%)通配符允许匹配任何字符串的零个或多个字符。 - 下划线(
_)通配符允许匹配任何单个字符。
- 百分比(
- 示例:
-
SELECT employeeNumber, lastName, firstName FROM employees WHERE lastname like "%on%";
查找名字以
T开头的员工,以m结尾,并且包含例如Tom,Tim之间的任何单个字符,可以使用下划线通配符来构建模式,如下所示: -
SELECT employeeNumber, lastName, firstName FROM employees WHERE firstname like "T_m";
如下语句,将查询
productCode字段中包含_20字符串的值。 -
SELECT productCode, productName FROM products WHERE productCode like "%\_20%" ;
有时想要匹配的模式包含通配符,例如
10%,_20等这样的字符串时。在这种情况下,您可以使用ESCAPE子句指定转义字符,以便MySQL将通配符解释为文字字符。如果未明确指定转义字符,则反斜杠字符是默认转义字符。 - limit 子句
- 在
SELECT语句中使用LIMIT子句来约束结果集中的行数。LIMIT子句接受一个或两个参数。两个参数的值必须为零或正整数 -
SELECT column1,column2,... FROM table LIMIT offset , count;
我们来查看
LIMIT子句参数:offset参数指定要返回的第一行的偏移量。第一行的偏移量为0,而不是1。count指定要返回的最大行数。- 示例:
- 我们的任务找出结果集中价格第二高的产品。可以使用
LIMIT子句来选择第二行,如以下查询(注意:偏移量从0开始,所以要指定从1开始,然后取一行记录): -
select productCode, productName, buyprice FROM products ORDER BY buyprice DESC LIMIT 1, 1;
四、排序数据
当使用SELECT语句查询表中的数据时,结果集不按任何顺序进行排序。要对结果集进行排序,请使用ORDER BY子句。 ORDER BY子句允许:
- 对单个列或多个列排序结果集。
- 按升序或降序对不同列的结果集进行排序。
下面说明了ORDER BY子句的语法:
SELECT column1, column2,...
FROM tbl
ORDER BY column1 [ASC|DESC], column2 [ASC|DESC],...