1.pom.xml
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-hadoop</artifactId>
<version>2.5.0.RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.3.2</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>org.mortbay.jetty</groupId>
<artifactId>servlet-api-2.5</artifactId>
</exclusion>
<exclusion>
<groupId>org.mortbay.jetty</groupId>
<artifactId>servlet-api-2.5-6.1.14</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.3</version>
<exclusions>
<exclusion>
<artifactId>servlet-api</artifactId>
<groupId>javax.servlet</groupId>
</exclusion>
</exclusions>
</dependency>
2.wordcount例子
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
public class JavaSparkWordCount {
public static void main(String[] args) {
//配置执行
SparkConf conf = new SparkConf().setAppName("Java_WordCount");
// 创建SparkContext对象: JavaSparkContext
JavaSparkContext context = new JavaSparkContext(conf);
//读入数据
JavaRDD<String> lines = context.textFile(args[0]);
//分词
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
// @Override
public Iterator<String> call(String line) throws Exception {
return Arrays.asList(line.split(" ")).iterator();
}
});
//每个单词记一次数
JavaPairRDD<String, Integer> wordOne = words.mapToPair(new PairFunction<String, String, Integer>() {
// @Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String,Integer>(word,1);
}
});
//执行reduceByKey的操作
JavaPairRDD<String, Integer> count = wordOne.reduceByKey(new Function2<Integer, Integer, Integer>() {
// @Override
public Integer call(Integer i1, Integer i2) throws Exception {
return i1 + i2;
}
});
//执行计算,执行action操作: 把结果打印在屏幕上
List<Tuple2<String, Integer>> result = count.collect();
//输出
for(Tuple2<String, Integer> tuple: result){
System.out.println(tuple._1+"\t"+tuple._2);
}
//停止SparkContext对象
context.stop();
}
}
3.打包运行
如果按springboot的maven打包方式打包,提交时报ClassNotFoundException
bin/spark-submit --master spark://hadoop1:7077 --class com.JavaSparkWordCount /xxx/sparktest.jar /xxx/data.txt
WARN SparkSubmit$$anon$2:87 - Failed to load com.JavaSparkWordCount.
java.lang.ClassNotFoundException: com.JavaSparkWordCount
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
解压打出的jar包,发现main所在类文件不在根目录,而是:在BOOT-INF\classes目录。
正确的打包方式:
按F4,或者点击idea的
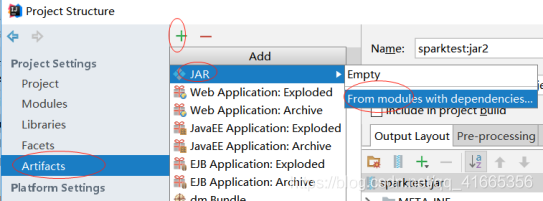
配置完后,点build,build artifacts...打包
打完包可以在jar包的com目录找到class文件。
再提交运行ok。
更多spark知识点,参见spark相关章节(spark知识点好像还没写博客,后续补上)
————————————————
版权声明:本文为CSDN博主「qq_41665356」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_41665356/article/details/89283645