WEB框架介绍
框架,即framework,特指为解决一个开放性问题而设计的具有一定约束性的支撑结构,使用框架可以帮你快速开发特定的系统,简单地说,就是你用别人搭建好的舞台来做表演。
对于所有的Web应用,本质上其实就是一个socket服务端,用户的浏览器其实就是一个socket客户端

import socket def handle_request(client): buf = client.recv(1024) client.send("HTTP/1.1 200 OK ".encode("utf8")) client.send("<h1 style='color:red'>Hello, yuan</h1>".encode("utf8")) def main(): sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.bind(('localhost',8001)) sock.listen(5) while True: connection, address = sock.accept() handle_request(connection) connection.close() if __name__ == '__main__': main()
最简单的Web应用就是先把HTML用文件保存好,用一个现成的HTTP服务器软件,接收用户请求,从文件中读取HTML,返回。
如果要动态生成HTML,就需要把上述步骤自己来实现。不过,接受HTTP请求、解析HTTP请求、发送HTTP响应都是苦力活,如果我们自己来写这些底层代码,还没开始写动态HTML呢,就得花个把月去读HTTP规范。
正确的做法是底层代码由专门的服务器软件实现,我们用Python专注于生成HTML文档。因为我们不希望接触到TCP连接、HTTP原始请求和响应格式,所以,需要一个统一的接口,让我们专心用Python编写Web业务。
这个接口就是WSGI:Web Server Gateway Interface。
HTTP协议
:简单理解成 规定消息的格式
所有的Web应用本质上就是一个socket服务端,而用户的浏览器就是一个socket客户端。用户的浏览器一输入网址,会给服务端发送数据,那浏览器会发送什么数据?怎么发?这个谁来定?HTTP协议。HTTP协议就是解决这个问题,它规定了发送消息和接收消息的格式
每个HTTP请求和响应都遵循相同的格式,一个HTTP包含Header和Body两部分,其中Body是可选的。HTTP响应的Header中有一个Content-Type表明响应的内容格式。如text/html表示HTML网页。
(1)HTTP请求
HTTP GET请求的格式:

HTTP POST请求格式:
(2)HTTP响应
HTTP响应的格式:

标准Web框架


#!/usr/bin/env python #coding:utf-8 from wsgiref.simple_server import make_server def RunServer(environ, start_response): start_response('200 OK', [('Content-Type', 'text/html')]) return '<h1>Hello, web!</h1>' if __name__ == '__main__': httpd = make_server('', 8000, RunServer) print "Serving HTTP on port 8000..." httpd.serve_forever()
自定义Web框架
from wsgiref.simple_server import make_server def login(): return 'login' def index(): data = open('index.html','r').read() return data url = ( ('/login/',login), ('/index/',index), ) def RunServer(environ, start_response): start_response('200 OK', [('Content-Type', 'text/html')]) geturl = environ['PATH_INFO'] for item in url: if item[0] == geturl: return item[1]() else: return '404' if __name__ == '__main__': httpd = make_server('', 8000, RunServer) print "Serving HTTP on port 8000..." httpd.serve_forever()
3、自定义WEB框架
WEB应用本质就是一个sockect服务端,只要让我们的Web框架在给客户端回复响应的时候按照HTTP协议的规则加上响应头,这样我们就实现了一个正经的Web框架。如下简单实例:开启服务端后,在浏览器上输入网址:127.0.0.1:8090/index/后就会向浏览器返回:这是主页内容
from socket import socket server=socket() server.bind(("127.0.0.1",8090)) server.listen(5) while True: conn,addr=server.accept() data = conn.recv(1024).decode() #data为请求的HTTP格式 print(data) header=data.split(" ")[0] #获得请求header部分 temp=header.split(" ")[0] #获得header中包含请求路径的第一行 url=temp.split(" ")[1] #获得请求路径 conn.send(b'HTTP/1.1 200 OK Content-Type:text/html; charset=utf-8 ') #返回HTTP响应格式内容 #根据路径不同返回不同的内容 if url=="/index/": response="这是主页" else: response="404" conn.send(bytes(response,encoding="utf-8"))
如下为上述实例接收到HTTP请求的data内容:
GET /index/ HTTP/1.1 #header部分 Host: 127.0.0.1:8090 Connection: keep-alive Cache-Control: max-age=0 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.89 Safari/537.36 Upgrade-Insecure-Requests: 1 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8 Accept-Encoding: gzip, deflate, br Accept-Language: zh-CN,zh;q=0.9 GET /favicon.ico HTTP/1.1 #body部分 Host: 127.0.0.1:8090 Connection: keep-alive Pragma: no-cache Cache-Control: no-cache User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.89 Safari/537.36 Accept: image/webp,image/apng,image/*,*/*;q=0.8 Referer: http://127.0.0.1:8090/index/ Accept-Encoding: gzip, deflate, br Accept-Language: zh-CN,zh;q=0.9
上述实例我们可以从请求头里面拿到请求的URL,然后做一个判断,我们的Web服务根据用户请求的URL不同而返回不同的内容。但是问题又来了,如果有很多很多页面怎么办?难道要挨个判断?当然不用,我们有更聪明的办法
from socket import socket server=socket() server.bind(("127.0.0.1",8090)) server.listen(5) def index(): return "这是主页" def info(): return "这是个人信息页" func_list=[ ("/index/",index), ("/info/",info) ] while True: conn,addr=server.accept() data = conn.recv(1024).decode() header=data.split(" ")[0] temp=header.split(" ")[0] url=temp.split(" ")[1] conn.send(b'HTTP/1.1 200 OK Content-Type:text/html; charset=utf-8 ') func_name=None for i in func_list: if url==i[0]: func_name=i[1] break if func_name: response=func_name() else: response="404" conn.send(bytes(response,encoding="utf-8"))
完美解决了不同URL返回不同内容的问题。但是我不想仅仅返回几个字符串,我想给浏览器返回完整的HTML内容,这又该怎么办呢?没问题,不管是什么内容,最后都是转换成字节数据发送出去的。我可以打开HTML文件,读取出它内部的二进制数据,然后发送给浏览器。
from socket import socket server=socket() server.bind(("127.0.0.1",8090)) server.listen(5) def index(): with open("index.html",encoding="utf-8") as f: data_html=f.read() #读取html程序,本质是字符串 import pymysql conn = pymysql.connect(host='localhost', user='root', password='', database='day65', charset='utf8') cur = conn.cursor(cursor=pymysql.cursors.DictCursor) # 设置查询结果以字典形式显示 sql = "select id,name,balance from user" cur.execute(sql) use_list = cur.fetchall() print(use_list)#[{'id': 1, 'name': 'egon', 'balance': 10000}, {'id': 2, 'name': 'alex', 'balance': 2000}, {'id': 3, 'name': 'wsb', 'balance': 20000}] ret="" for i in use_list: ret+=""" <tr> <td>{0}</td> <td>{1}</td> <td>{2}</td> </tr> """.format(i["id"],i["name"],i["balance"]) cur.close() conn.close() data_new=data_html.replace("@@xx@@",ret) #将html中的占位内容用数据库中查询的结果组成的字符替换 return data_new #返回替换数据的html字符串 index() def info(): return "这是个人信息页" func_list=[ ("/index/",index), ("/info/",info) ] while True: conn,addr=server.accept() data = conn.recv(1024).decode() header=data.split(" ")[0] temp=header.split(" ")[0] url=temp.split(" ")[1] conn.send(b'HTTP/1.1 200 OK Content-Type:text/html; charset=utf-8 ') func_name=None for i in func_list: if url==i[0]: func_name=i[1] break if func_name: response=func_name() else: response="404" conn.send(bytes(response,encoding="utf-8"))
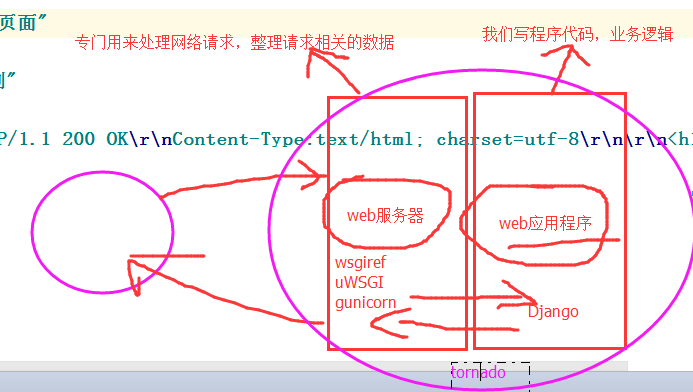
上述代码模拟了一个web服务的本质,而对于真实开发中的Python Web程序来说,一般分为两部分:服务器程序和应用程序。服务器程序负责对Socket服务器进行封装,并在请求到来时,对请求的各种数据进行整理。应用程序则负责具体的逻辑处理。为了方便应用程序的开发,就出现了众多的Web框架。
不同的框架有不同的开发方式,但是无论如何,开发出的应用程序都要和服务器程序配合,才能为用户提供服务。这样,服务器程序就需要为不同的框架提供不同的支持。这样混乱的局面无论对于服务器还是框架,都是不好的。对服务器来说,需要支持各种不同框架,对框架来说,只有支持它的服务器才能被开发出的应用使用。这时候,标准化就变得尤为重要。一旦标准确定,双方根据约定的标准各自进行开发即可。WSGI(Web Server Gateway Interface)就是这样一种规范,它定义了使用Python编写的Web APP与Web Server之间接口格式,实现Web APP与Web Server间的解耦。
模板渲染jinja2
from wsgiref.simple_server import make_server import jinja2 def index(): with open("index.html", encoding="utf8") as f: data = f.read() # 连接数据库 import pymysql # 连接 conn = pymysql.connect(host="localhost", user="root", password="123456", database="day60", charset="utf8") # 没有- # 获取光标 cursor = conn.cursor() # 写sql语句 sql = "select name, pwd from userinfo where id =1;" cursor.execute(sql) ret = cursor.fetchone() print(ret) # 将数据库中的数据填充到HTML页面 new1_data = data.replace("@@2@@", ret[0]) new2_data = new1_data.replace("##3##", ret[1]) return new2_data def home(): return "这是home页面" def userlist(): with open("userlist.html", encoding="utf8") as f: data = f.read() # 生成了一个jinja2的模板对象 template = jinja2.Template(data) # 相当于字符串替换 new_data = template.render({ "user_list": [ {"name": "jianchao", "pwd": "1234"}, {"name": "liyan", "pwd": "5678"} ] }) return new_data def login(): with open("login.html", encoding="utf8") as f: data = f.read() import time time_str = str(time.time()) new_data = data.replace("@@2@@", time_str) return new_data URL_FUNC = [ ("/index/", index), ("/home/", home), ("/login/", login), ("/userlist/", userlist), ] def run_server(environ, start_response): start_response('200 OK', [('Content-Type', 'text/html;charset=utf8')]) # 设置HTTP响应的状态码和头信息 url = environ['PATH_INFO'] # 取到用户输入的url print("--->url:", url) # 根据url的不同,返回不同的内容 func_name = None for i in URL_FUNC: if url == i[0]: # 如果能找到对应关系,就把函数名拿到 func_name = i[1] break # 拿到可以执行的函数,执行函数拿到结果 if func_name: body = func_name() else: body = "404找不到这个页面" return [bytes("<h1>{}</h1>".format(body), encoding="utf8"),] if __name__ == '__main__': httpd = make_server('', 9000, run_server) print("Serving HTTP on port 8000...") httpd.serve_forever()