本文环境:lucene5.2 JDK1.7 IKAnalyzer
引入lucene相关包
<!-- lucene核心包 --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>5.2.0</version> </dependency> <!-- 查询解析器 --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-queryparser</artifactId> <version>5.2.0</version> </dependency> <!-- 分词器 --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-common</artifactId> <version>5.2.0</version> </dependency>
开发中依赖的包
<!-- https://mvnrepository.com/artifact/commons-io/commons-io --> <dependency> <groupId>commons-io</groupId> <artifactId>commons-io</artifactId> <version>2.4</version> </dependency> <!-- https://mvnrepository.com/artifact/junit/junit --> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.10</version> </dependency>
一、创建索引
1、确定索引库的位置
a、将索引库存入本地磁盘
FSDirectory dir=FSDirectory.open(path);
b、将索引存入内存
Directory directory = new RAMDirectory();
2、创建分词器
//创建分词器 Analyzer al=new StandardAnalyzer();
lucene内置有四个分析器:WhitespaceAnalyzer、SimpleAnalyzer、StopAnalyser、StandardAnalyzer
- WhitespaceAnalyzer:分析器是通过空格来分割文本信息
- SimpleAnalyzer:分析器会首先通过非字母字符来拆分文本信息,并统一转为小写格式,会去掉数字类型的字符
- StopAnalyser:和SimpleAnalyzer分析器类似,但StopAnalyser会去掉一些常用单词(the、a、an..)
- StandardAnalyzer:是lucene最复杂的核心分析器,可以识别某些种类的语汇单元,如公司名称、Email、主机名称等,它会将语汇单元转为小写格式,并去除掉停用词和标点符号
3、创建IndexWriter,进行索引文件的写入。
//创建索引的写入配置对象 IndexWriterConfig iwc= new IndexWriterConfig(al); //创建索引的Writer IndexWriter iw=new IndexWriter(dir, iwc);
4、创建文档 创建域将内容提取并进行索引的存储
//创建文档 Document doc=new Document(); //创建域 (域是键值对的数据结构)Store.YES:将该值存储到索引库 Field fieldName=new TextField("fieldName","xs.txt",Store.YES); Field fieldContent=new TextField("fieldContent","san guo yan yi",Store.YES); Field fieldsize=new LongField("fieldSize",10324,Store.YES); Field fieldPath=new TextField("fieldPath","F:/xs/sg/xs.txt",Store.YES); //将域加入文档中 doc.add(fieldName); doc.add(fieldContent); doc.add(fieldsize); doc.add(fieldPath); //把文档写入索引库 iw.addDocument(doc);
Field域的3各重要属性:
a、是否分析
将field值按照指定的分词器进行分析出相应的语汇单元,将词进行索引。例如:博文标题、博文作者、博文描述、博文内容 ,这些都应该建立索引
b、是否索引
对field分析后的词或整个field值进行索引,只有建立索引的field才能被搜索
c、是否存储(Store.YES:表示存储 Store.NO:表示不存储)
将field值存储在文档中,只有存储在文档中的field才可以从Document中取出。(一般对于内容较大的field不建立存储)
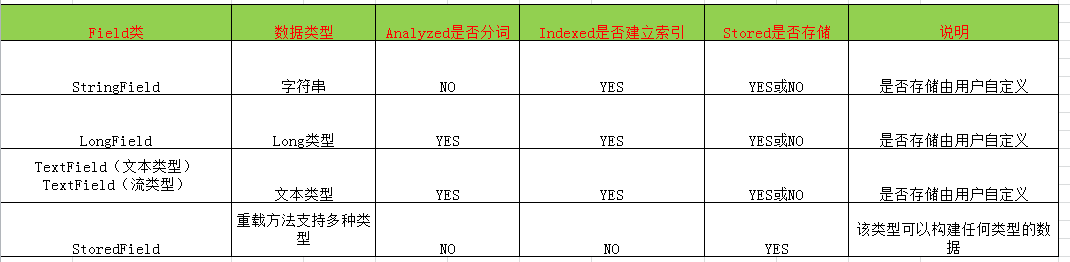
常用Field域的类型:
5、提交,并关闭资源
//提交 iw.commit(); iw.close();
完整代码:


1 @Test 2 public void ImportIndex() throws IOException { 3 //获得索引库路径 4 Path path=Paths.get("E:\test\luceneWI"); 5 //打开索引库 6 FSDirectory dir=FSDirectory.open(path); 7 //创建分词器 8 Analyzer al=new StandardAnalyzer(); 9 //创建索引的写入配置对象 10 IndexWriterConfig iwc= new IndexWriterConfig(al); 11 //创建索引的Writer 12 IndexWriter iw=new IndexWriter(dir, iwc); 13 //采集原始文档 14 File sourceFile=new File("E:\test\lucene"); 15 //获取该文件下所有的文件 16 File [] files=sourceFile.listFiles(); 17 //遍历每一个文件 18 for(File file:files){ 19 //获取文件属性 20 String fileName=file.getName(); 21 String content=FileUtils.readFileToString(file); 22 long size=FileUtils.sizeOf(file); 23 String sourcePath=file.getPath(); 24 //创建文档 25 Document doc=new Document(); 26 //创建域 (域是键值对的数据结构)Store.YES:将该值存储到索引库 27 Field fieldName=new TextField("fieldName",fileName,Store.YES); 28 Field fieldContent=new TextField("fieldContent",content,Store.YES); 29 Field fieldsize=new LongField("fieldSize",size,Store.YES); 30 Field fieldPath=new TextField("fieldPath",sourcePath,Store.NO); 31 //将域加入文档中 32 doc.add(fieldName); 33 doc.add(fieldContent); 34 doc.add(fieldsize); 35 doc.add(fieldPath); 36 //把文档写入索引库 37 iw.addDocument(doc); 38 } 39 //提交 40 iw.commit(); 41 iw.close(); 42 }
执行结果查看索引库
我们使用 luke可以查看索引库的具体信息luke-5.3.0-luke-release
二、添加索引
添加前我们的索引库中有7各文档

现在我们要新加一条文档
@Test public void addIndex() throws IOException { //获得索引库路径 Path path=Paths.get("E:\test\luceneWI"); //打开索引库 FSDirectory dir=FSDirectory.open(path); //创建分词器 Analyzer al=new IKAnalyzer(); //创建索引的写入配置对象 IndexWriterConfig iwc= new IndexWriterConfig(al); //创建索引的Writer IndexWriter iw=new IndexWriter(dir, iwc); //新建一个文件 china.txt File file=new File("E:\test\lucene\china.txt"); String fileName=file.getName(); String content=FileUtils.readFileToString(file); long size=FileUtils.sizeOf(file); String sourcePath=file.getPath(); //创建域 (域时键值对的数据结构)Store.YES:在索引库中是否以存储的形式存在 Field fieldName=new TextField("fieldName",fileName,Store.YES); Field fieldContent=new TextField("fieldContent",content,Store.YES); Field fieldsize=new LongField("fieldSize",size,Store.YES); Field fieldPath=new TextField("fieldPath",sourcePath,Store.YES); //创建文档 Document doc=new Document(); //将域加入文档中 doc.add(fieldName); doc.add(fieldContent); doc.add(fieldPath); doc.add(fieldsize); //把文档写入索引库 iw.addDocument(doc); iw.commit(); iw.close(); }
执行后

三、删除索引
1、删除所有
@Test public void deleteIndexAll() throws IOException { //获得索引库路径 Path path=Paths.get("E:\test\luceneWI"); //打开索引库 FSDirectory dir=FSDirectory.open(path); //创建分词器 Analyzer al=new IKAnalyzer(); //创建索引的写入配置对象 IndexWriterConfig iwc= new IndexWriterConfig(al); //创建索引的Writer IndexWriter iw=new IndexWriter(dir, iwc); iw.deleteAll();//删除所有 iw.commit();//提交 iw.close();//关闭资源 }
2、按照条件删除
@Test public void deleteIndexAllQuery() throws IOException { //获得索引库路径 Path path=Paths.get("E:\test\luceneWI"); //打开索引库 FSDirectory dir=FSDirectory.open(path); //创建分词器 Analyzer al=new IKAnalyzer(); //创建索引的写入配置对象 IndexWriterConfig iwc= new IndexWriterConfig(al); //创建索引的Writer IndexWriter iw=new IndexWriter(dir, iwc); //创建语汇单元 Term term=new Term("fieldName","china");// 要删除的document中包含的语汇单元 //创建根据语汇单元的查询对象 Query query=new TermQuery(term); iw.deleteDocuments(query); iw.commit();//提交 iw.close();//关闭资源 }
四、查询
1、分词语汇单元查询
@Test public void QueryIndexAll() throws IOException { //获得索引库路径 Path path=Paths.get("E:\test\luceneWI"); //打开索引库 FSDirectory dir=FSDirectory.open(path); //创建索引库的读取对象 DirectoryReader reader=DirectoryReader.open(dir); //创建索引库的搜索对象 IndexSearcher is=new IndexSearcher(reader); //创建语汇单元 Term term=new Term("fieldName","license");// 要删除的document中包含的语汇单元 //创建根据语汇单元的查询对象 TermQuery tq=new TermQuery(term); TopDocs result=is.search(tq, 10);//查询前10条 int totalHits=result.totalHits;//获取总记录数 System.out.println("totalHits:"+totalHits); //获取文档列表 ScoreDoc[] sd=result.scoreDocs; for(ScoreDoc sc:sd){ int id=sc.doc;//获取文档ID Document doc=is.doc(id);//获取文档 String fieldName=doc.get("fieldName"); String fieldContent=doc.get("fieldContent"); String fieldSize=doc.get("fieldSize"); String fieldPath=doc.get("fieldPath"); System.out.println("fieldName:"+fieldName); System.out.println("fieldContent:"+fieldContent); System.out.println("fieldSize:"+fieldSize); System.out.println("fieldPath:"+fieldPath); } }
2、数值范围查询
@Test public void queryIndexNumberAll() throws IOException { //获得索引库路径 Path path=Paths.get("E:\test\luceneWI"); //打开索引库 FSDirectory dir=FSDirectory.open(path); //创建索引库的读取对象 DirectoryReader reader=DirectoryReader.open(dir); //创建索引库的搜索对象 IndexSearcher is=new IndexSearcher(reader); //创建数值查询对象 Query tq=NumericRangeQuery.newLongRange("fieldSize", 0L, 100L, true, true); System.out.println("打印查询对象:"+tq);//打印查询对象:fieldSize:[0 TO 100] TopDocs result=is.search(tq, 10);//查询前10条 int totalHits=result.totalHits;//获取总记录数 System.out.println("totalHits:"+totalHits); //获取文档列表 ScoreDoc[] sd=result.scoreDocs; for(ScoreDoc sc:sd){ int id=sc.doc;//获取文档ID Document doc=is.doc(id);//获取文档 String fieldName=doc.get("fieldName"); String fieldContent=doc.get("fieldContent"); String fieldSize=doc.get("fieldSize"); String fieldPath=doc.get("fieldPath"); System.out.println("fieldName:"+fieldName); System.out.println("fieldContent:"+fieldContent); System.out.println("fieldSize:"+fieldSize); System.out.println("fieldPath:"+fieldPath); } }
3、多查询对象联合查询
@Test public void bqqueryIndexNumberAll() throws IOException { //获得索引库路径 Path path=Paths.get("E:\test\luceneWI"); //打开索引库 FSDirectory dir=FSDirectory.open(path); //创建索引库的读取对象 DirectoryReader reader=DirectoryReader.open(dir); //创建索引库的搜索对象 IndexSearcher is=new IndexSearcher(reader); //创建多条件查询对象,通过控制& 或者| 或者 ! 来组合查询条件 BooleanQuery tq=new BooleanQuery(); //创建分词语汇查询对象 Query query1=new TermQuery(new Term("fieldName","china")); Query query2=new TermQuery(new Term("fieldContent","china")); Query query3=NumericRangeQuery.newLongRange("fieldSize", 0L, 100L, true, true); //通过BooleanQuery 控制 两个查询条件的关系 tq.add(query1,Occur.MUST); tq.add(query2,Occur.MUST); //Occur.MUST 同时满足 Occur.SHOULD: 可以满足可以不满足 Occur.MUST_NOT:不能满足 tq.add(query3,Occur.MUST); System.out.println("bq:"+tq);//bq:+fieldName:china +fieldContent:china ( 表示 必须同时满足两个条件) TopDocs result=is.search(tq, 10);//查询前10条 int totalHits=result.totalHits;//获取总记录数 System.out.println("totalHits:"+totalHits); //获取文档列表 ScoreDoc[] sd=result.scoreDocs; for(ScoreDoc sc:sd){ int id=sc.doc;//获取文档ID Document doc=is.doc(id);//获取文档 String fieldName=doc.get("fieldName"); String fieldContent=doc.get("fieldContent"); String fieldSize=doc.get("fieldSize"); String fieldPath=doc.get("fieldPath"); System.out.println("fieldName:"+fieldName); System.out.println("fieldContent:"+fieldContent); System.out.println("fieldSize:"+fieldSize); System.out.println("fieldPath:"+fieldPath); } }
4、解析查询
QueryParser 对查询条件进行分词查询
@Test public void queryParserIndexAll() throws Exception { //获得索引库路径 Path path=Paths.get("E:\test\luceneWI"); //打开索引库 FSDirectory dir=FSDirectory.open(path); //创建索引库的读取对象 DirectoryReader reader=DirectoryReader.open(dir); //创建索引库的搜索对象 IndexSearcher is=new IndexSearcher(reader); //创建查询解析对象 QueryParser qp=new QueryParser("fieldName", new IKAnalyzer());//分词器要与创建索引的一样 //通过QueryParser解析查询对象 Query tq=qp.parse("爱我china");//单个查询条件 // Query tq=qp.parse("fieldName:爱我 OR fieldContent:china");//多个查询条件 OR /AND System.out.println("tq:"+tq);//tq:fieldName:爱我 fieldName:我 fieldName:china (进行分词了) TopDocs result=is.search(tq, 10);//查询前10条 int totalHits=result.totalHits;//获取总记录数 System.out.println("totalHits:"+totalHits); //获取文档列表 ScoreDoc[] sd=result.scoreDocs; for(ScoreDoc sc:sd){ int id=sc.doc;//获取文档ID Document doc=is.doc(id);//获取文档 String fieldName=doc.get("fieldName"); String fieldContent=doc.get("fieldContent"); String fieldSize=doc.get("fieldSize"); String fieldPath=doc.get("fieldPath"); System.out.println("fieldName:"+fieldName); System.out.println("fieldContent:"+fieldContent); System.out.println("fieldSize:"+fieldSize); System.out.println("fieldPath:"+fieldPath); } }
5、多域解析查询
@Test public void queryManyParserIndexAll() throws Exception { //获得索引库路径 Path path=Paths.get("E:\test\luceneWI"); //打开索引库 FSDirectory dir=FSDirectory.open(path); //创建索引库的读取对象 DirectoryReader reader=DirectoryReader.open(dir); //创建索引库的搜索对象 IndexSearcher is=new IndexSearcher(reader); //定义多个域 String [] fields={"fieldName","fieldContent"}; //创建查询解析对象 查询的语汇单词之间的关系是或,只要满足其中一个语汇单元,就可以查询出来 MultiFieldQueryParser mp=new MultiFieldQueryParser(fields, new IKAnalyzer()); Query tq=mp.parse("爱我china"); System.out.println("tq:"+tq);//tq:(fieldName:爱我 fieldName:我 fieldName:china) (fieldContent:爱我 fieldContent:我 fieldContent:china) TopDocs result=is.search(tq, 10);//查询前10条 int totalHits=result.totalHits;//获取总记录数 System.out.println("totalHits:"+totalHits); //获取文档列表 ScoreDoc[] sd=result.scoreDocs; for(ScoreDoc sc:sd){ int id=sc.doc;//获取文档ID Document doc=is.doc(id);//获取文档 String fieldName=doc.get("fieldName"); String fieldContent=doc.get("fieldContent"); String fieldSize=doc.get("fieldSize"); String fieldPath=doc.get("fieldPath"); System.out.println("fieldName:"+fieldName); System.out.println("fieldContent:"+fieldContent); System.out.println("fieldSize:"+fieldSize); System.out.println("fieldPath:"+fieldPath); } }