Shuffle过程:数据从map端传输到reduce端的过程~
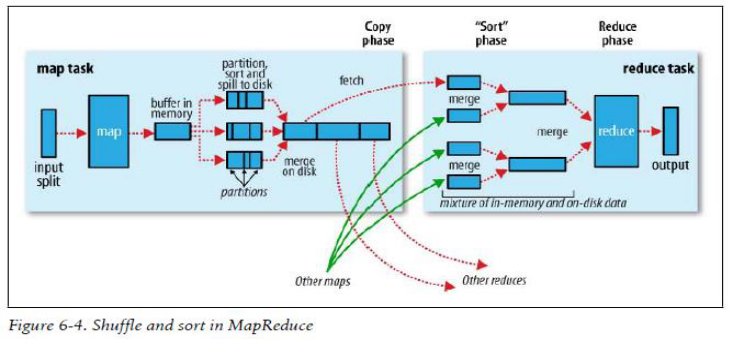
Map端
- 每个map有一个环形内存缓冲区,用于存储任务的输出。默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spill.percent),一个后台线程把内容写到(spill)磁盘的指定目录(mapred.local.dir)下的新建的一个溢出写文件。
- 写磁盘前,要partition,sort。如果有combiner,combine排序后数据。
- 等最后记录写完,合并全部溢出写文件为一个分区且排序的文件。
hadoop1中的是resourcemanager,在hadoop2中applicationmaster会通过reduce task从map task拷贝文件
Reduce端
- Reducer通过Http方式得到输出文件的分区。 ( 上图为3个reduce任务,每一个分区产生一个reduce任务,分区后的数据通过shuffle,由reduce主动fetch数据,通过网络copy到reduce端)
- TaskTracker为分区文件运行Reduce任务。复制阶段把Map输出复制到Reducer的内存或磁盘。一个Map任务完成,Reduce就开始复制输出。
- 排序阶段合并map输出。然后走Reduce阶段。
优化点:
- 内存缓冲器越小的时,往磁盘写的几率会增加。磁盘上会产生更多小文件的合并。数据的排序发生在内存中,如果缓冲区越大,也就是往磁盘写入的更少。
- Spill到指定目录,如果把指定目录建立在固定硬盘上速度会加快。
- 数据传输的时候网络也是可优化的,可增加网络带宽。
源码导读:

注释:
/**
* Reduces a set of intermediate values which share a key to a smaller set of Reduce减少汇总了一些中间值的集合,共享一个key给一些较小值得集合
* values.
*
<p><code>Reducer</code> has 3 primary phases:</p>
* <ol>
* <li>
*
* <h4 id="Shuffle">Shuffle</h4>
*
* <p>The <code>Reducer</code> copies the sorted output from each //复制每个的排序输出,核心是拷贝
* {@link Mapper} using HTTP across the network.</p> //在整个网络上使用HTTP,网络传输的过程就是shuffle的过程
* </li>
*
* <li>
* <h4 id="Sort">Sort</h4>
*
* <p>The framework merge sorts <code>Reducer</code> inputs by
* <code>key</code>s
* (since different <code>Mapper</code>s may have output the same key).</p>
*
* <p>The shuffle and sort phases occur simultaneously i.e. while outputs are
* being fetched they are merged.</p>
*
* <h5 id="SecondarySort">SecondarySort</h5>
*
* <p>To achieve a secondary sort on the values returned by the value
* iterator, the application should extend the key with the secondary
* key and define a grouping comparator. The keys will be sorted using the
* entire key, but will be grouped using the grouping comparator to decide
* which keys and values are sent in the same call to reduce.The grouping
* comparator is specified via
* {@link Job#setGroupingComparatorClass(Class)}. The sort order is
* controlled by
* {@link Job#setSortComparatorClass(Class)}.</p>
* For example, say that you want to find duplicate web pages and tag them
* all with the url of the "best" known example. You would set up the job
* like:
* <ul>
* <li>Map Input Key: url</li>
* <li>Map Input Value: document</li>
* <li>Map Output Key: document checksum, url pagerank</li>
* <li>Map Output Value: url</li>
* <li>Partitioner: by checksum</li>
* <li>OutputKeyComparator: by checksum and then decreasing pagerank</li>
* <li>OutputValueGroupingComparator: by checksum</li>
* </ul>
* </li>
*
* <li>
* <h4 id="Reduce">Reduce</h4>
*
* <p>In this phase the
* {@link #reduce(Object, Iterable, Context)}
* method is called for each <code><key, (collection of values)></code> in
* the sorted inputs.</p>
* <p>The output of the reduce task is typically written to a
* {@link RecordWriter} via
* {@link Context#write(Object, Object)}.</p>
* </li>
* </ol>
*
* <p>The output of the <code>Reducer</code> is <b>not re-sorted</b>.</p>
*
* <p>Example:</p>
* <p><blockquote><pre>
* public class IntSumReducer<Key> extends Reducer<Key,IntWritable,
* Key,IntWritable> {
* private IntWritable result = new IntWritable();
*
* public void reduce(Key key, Iterable<IntWritable> values,
* Context context) throws IOException, InterruptedException {
* int sum = 0;
* for (IntWritable val : values) {
* sum += val.get();
* }
* result.set(sum);
* context.write(key, result);
* }
* }
* </pre></blockquote></p>
*
* @see Mapper
* @see Partitioner
*/
End!