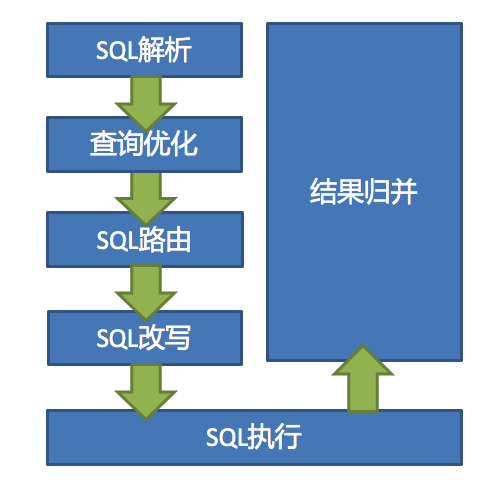
内部执行-官网流程图:SQL 解析 => 执行器优化 => SQL 路由 => SQL 改写 => SQL 执行 => 结果归并
对应5.0代码包shardingsphere-infra-***
SQL解析:
分为词法解析和语法解析。 先通过词法解析器将 SQL 拆分为一个个不可再分的单词。再使用语法解析器对 SQL 进行理解,并最终提炼出解析上下文。 解析上下文包括表、选择项、排序项、分组项、聚合函数、分页信息、查询条件以及可能需要修改的占位符的标记。
shardingsphere-sql-parser-*
shardingsphere-sql-parser-engine
依赖外部的部分,一个是shardingsphere-infra-optimize依赖于calciteSQL解析优化,另一个是ANTLR支持更丰富语法模板
SQL路由
分片路由:直接路由(hint)、标准路由(一般带key的或绑定的join)、笛卡尔路由(非绑定关系join)
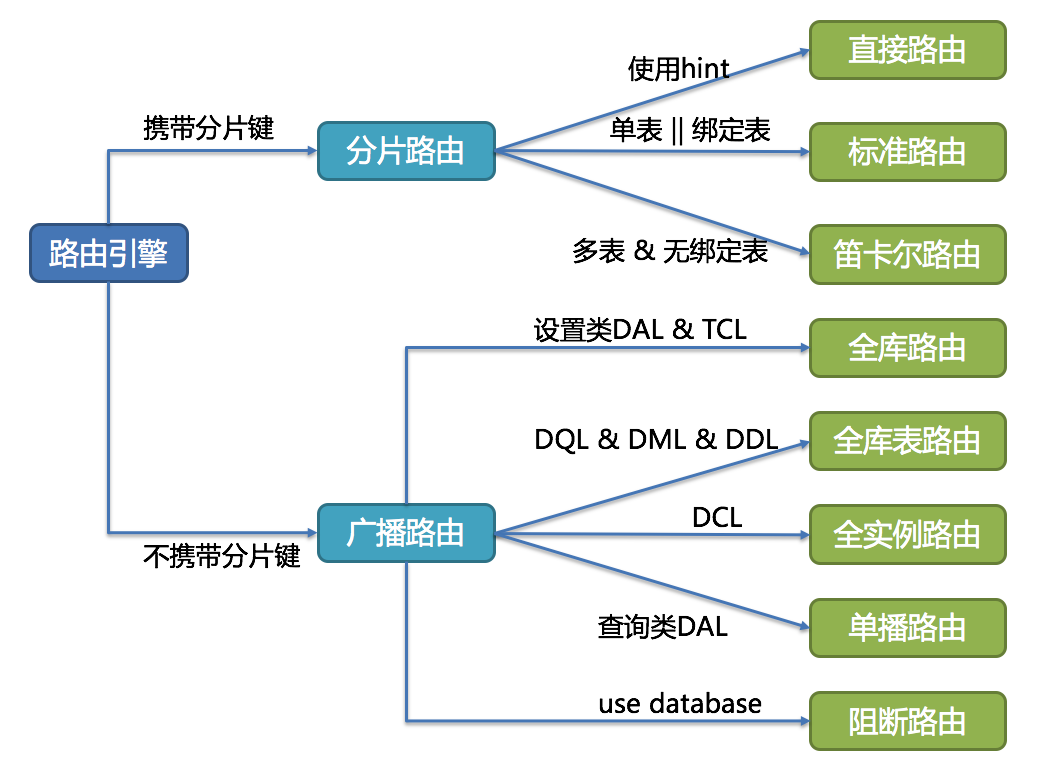
SQL路由处理实现如下

调用关系如下
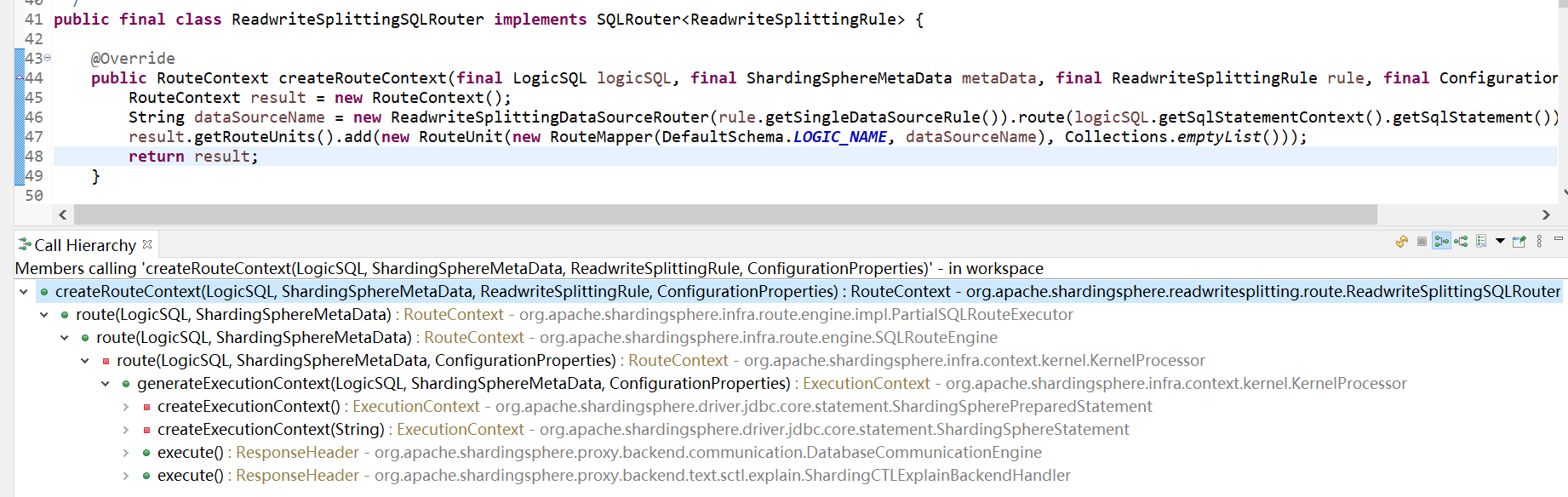
读写分离路由具体实现
public final class ReadwriteSplittingDataSourceRouter { private final ReadwriteSplittingDataSourceRule rule; public String route(final SQLStatement sqlStatement) { if (isPrimaryRoute(sqlStatement)) { PrimaryVisitedManager.setPrimaryVisited(); String autoAwareDataSourceName = rule.getAutoAwareDataSourceName(); if (Strings.isNullOrEmpty(autoAwareDataSourceName)) { return rule.getWriteDataSourceName(); } Optional<DataSourceNameAware> dataSourceNameAware = DataSourceNameAwareFactory.getInstance().getDataSourceNameAware(); if (dataSourceNameAware.isPresent()) { return dataSourceNameAware.get().getPrimaryDataSourceName(autoAwareDataSourceName); } } String autoAwareDataSourceName = rule.getAutoAwareDataSourceName(); if (Strings.isNullOrEmpty(autoAwareDataSourceName)) { return rule.getLoadBalancer().getDataSource(rule.getName(), rule.getWriteDataSourceName(), rule.getReadDataSourceNames()); } Optional<DataSourceNameAware> dataSourceNameAware = DataSourceNameAwareFactory.getInstance().getDataSourceNameAware(); if (dataSourceNameAware.isPresent()) { Collection<String> replicaDataSourceNames = dataSourceNameAware.get().getReplicaDataSourceNames(autoAwareDataSourceName); return rule.getLoadBalancer().getDataSource(rule.getName(), rule.getWriteDataSourceName(), new ArrayList<>(replicaDataSourceNames)); } return rule.getLoadBalancer().getDataSource(rule.getName(), rule.getWriteDataSourceName(), rule.getReadDataSourceNames()); } private boolean isPrimaryRoute(final SQLStatement sqlStatement) { return containsLockSegment(sqlStatement) || !(sqlStatement instanceof SelectStatement) || PrimaryVisitedManager.getPrimaryVisited() || HintManager.isWriteRouteOnly() || TransactionHolder.isTransaction(); } private boolean containsLockSegment(final SQLStatement sqlStatement) { return sqlStatement instanceof SelectStatement && SelectStatementHandler.getLockSegment((SelectStatement) sqlStatement).isPresent(); } }
负载均衡策略

SQL改写

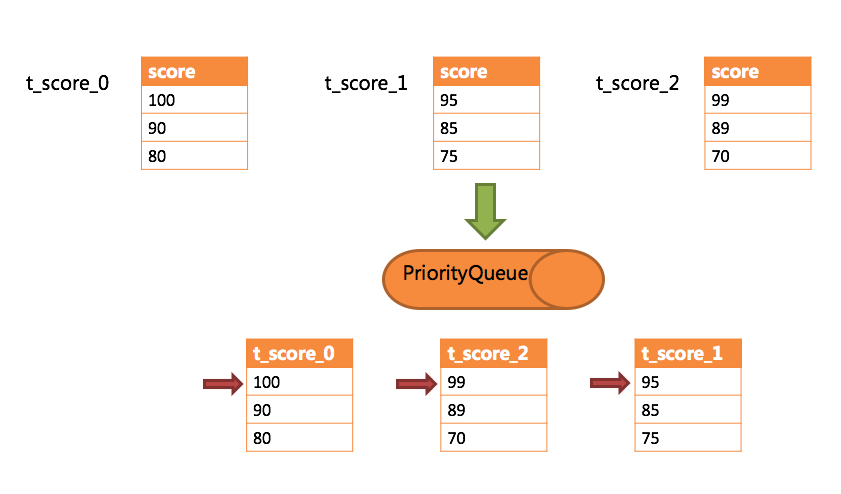
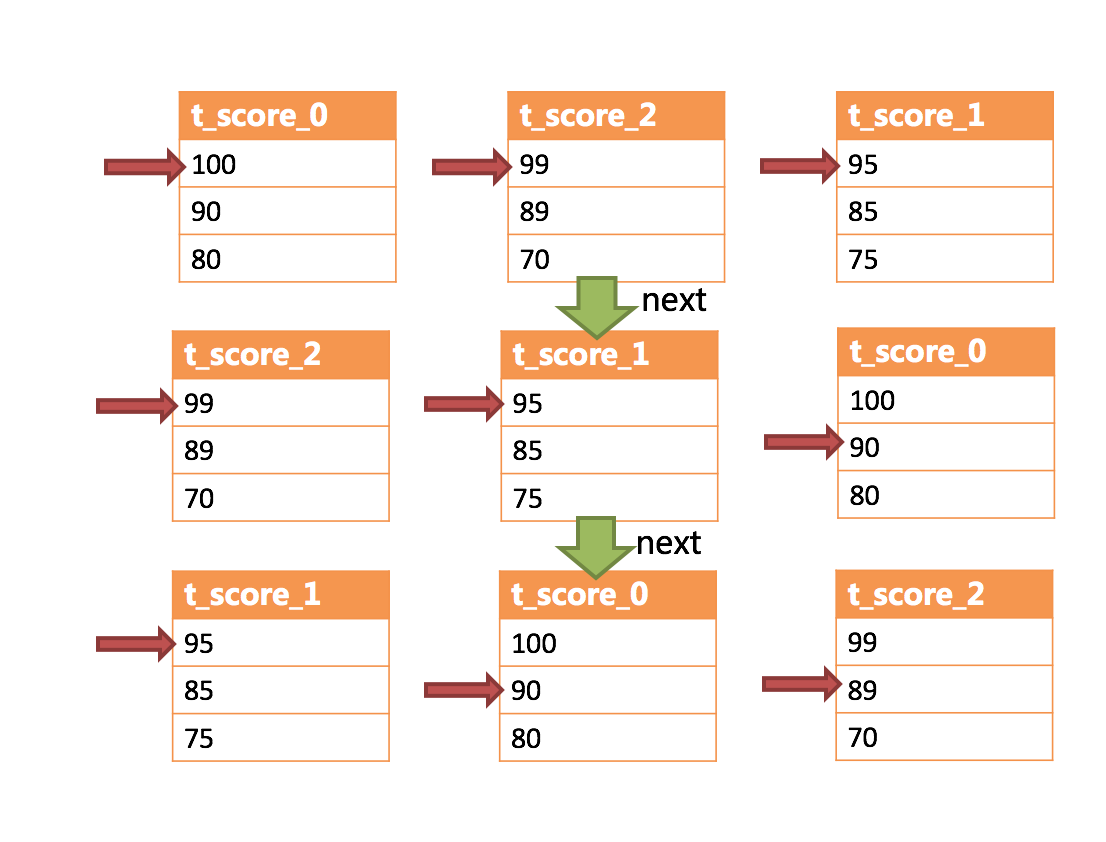
处理结果集
ShardingResultMergerEngine
@Override public ResultMerger newInstance(final DatabaseType databaseType, final ShardingRule shardingRule, final ConfigurationProperties props, final SQLStatementContext sqlStatementContext) { if (sqlStatementContext instanceof SelectStatementContext) { return new ShardingDQLResultMerger(databaseType); } if (sqlStatementContext.getSqlStatement() instanceof DALStatement) { return new ShardingDALResultMerger(shardingRule); } return new TransparentResultMerger(); }
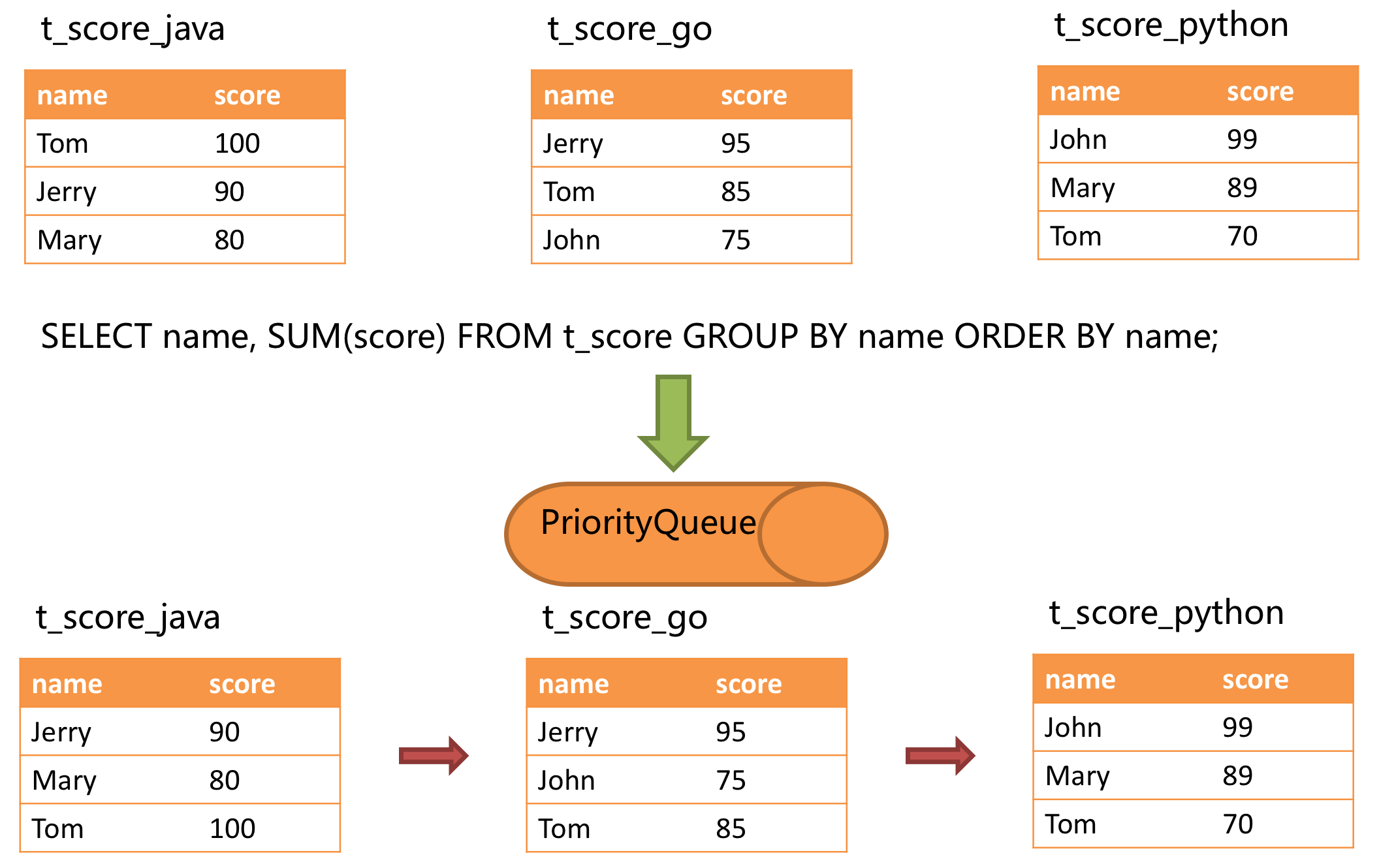
合并部分例
@Override public MergedResult merge(final List<QueryResult> queryResults, final SQLStatementContext<?> sqlStatementContext, final ShardingSphereSchema schema) throws SQLException { if (1 == queryResults.size()) { return new IteratorStreamMergedResult(queryResults); } Map<String, Integer> columnLabelIndexMap = getColumnLabelIndexMap(queryResults.get(0)); SelectStatementContext selectStatementContext = (SelectStatementContext) sqlStatementContext; selectStatementContext.setIndexes(columnLabelIndexMap); MergedResult mergedResult = build(queryResults, selectStatementContext, columnLabelIndexMap, schema); return decorate(queryResults, selectStatementContext, mergedResult); }
调用关系
private MergedResult build(final List<QueryResult> queryResults, final SelectStatementContext selectStatementContext, final Map<String, Integer> columnLabelIndexMap, final ShardingSphereSchema schema) throws SQLException { if (isNeedProcessGroupBy(selectStatementContext)) { return getGroupByMergedResult(queryResults, selectStatementContext, columnLabelIndexMap, schema); } if (isNeedProcessDistinctRow(selectStatementContext)) { setGroupByForDistinctRow(selectStatementContext); return getGroupByMergedResult(queryResults, selectStatementContext, columnLabelIndexMap, schema); } if (isNeedProcessOrderBy(selectStatementContext)) { return new OrderByStreamMergedResult(queryResults, selectStatementContext, schema); } return new IteratorStreamMergedResult(queryResults); }
流式合并和内存合并
private MergedResult getGroupByMergedResult(final List<QueryResult> queryResults, final SelectStatementContext selectStatementContext, final Map<String, Integer> columnLabelIndexMap, final ShardingSphereSchema schema) throws SQLException { return selectStatementContext.isSameGroupByAndOrderByItems() ? new GroupByStreamMergedResult(columnLabelIndexMap, queryResults, selectStatementContext, schema) : new GroupByMemoryMergedResult(queryResults, selectStatementContext, schema); }
关于合并,官网内容非常详细