1 /** 2 * 分页,SearcherAfter 3 * @param query 4 * @param pageIndex 5 * @param pageSize 6 */ 7 public void searchPageByAfter(String query,int pageIndex,int pageSize){ 8 try { 9 IndexSearcher indexSearcher = getSearcher(); 10 QueryParser parser = new QueryParser("content", new StandardAnalyzer()); 11 Query q = parser.parse(query); 12 //获取上一页的最后一个元素 13 ScoreDoc lastScoreDoc = getLastScoreDoc(pageIndex, pageSize, q, indexSearcher); 14 //通过最后一个元素搜索下页的pageSize个元素 15 TopDocs topDocs = indexSearcher.searchAfter(lastScoreDoc,q,pageSize); 16 System.out.println("共:"+topDocs.totalHits); 17 for (ScoreDoc item : topDocs.scoreDocs) { 18 Document doc = indexSearcher.doc(item.doc); 19 System.out.println("名字:" + doc.get("name") + ",邮箱:" + doc.get("email") + ",id:" + doc.get("id")); 20 } 21 } catch (Exception e) { 22 // TODO: handle exception 23 e.printStackTrace(); 24 }finally{ 25 try { 26 directory.close(); 27 } catch (IOException e) { 28 // TODO Auto-generated catch block 29 e.printStackTrace(); 30 } 31 } 32 }
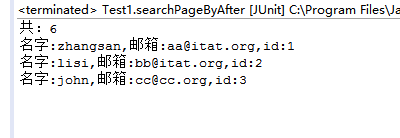
测试:
@Test public void searchPageByAfter(){ SearchUtil util = new SearchUtil(); util.searchPageByAfter("like",1,3); }