把Lucene的查询当成sql的查询,也许会笼统的明白些query的真相了。
查询分为大致两类,1:精准查询。2,模糊查询。
创建测试数据。
private Directory directory; private IndexReader reader; private String[] ids = {"1","2","3","4","5","6"}; private String[] emails = {"aa@itat.org","bb@itat.org","cc@cc.org","dd@sina.org","ee@zttc.edu","ff@itat.org"}; private String[] contents = { "welcome to visited the space,I like book", "hello boy, I like pingpeng ball", "my name is cc I like game", "I like football", "I like football and I like basketball too", "I like movie and swim" }; private int[] attachs = {2,3,1,4,5,5}; private String[] names = {"zhangsan","lisi","john","jetty","lisi","jake"};
先建立索引。
1 private Map<String,Float> scores = new HashMap<String,Float>(); 2 3 public SearchUtil(){ 4 try { 5 directory = FSDirectory.open(Paths.get("D://lucene//index")); 6 scores.put("itat.org", 1.5f); 7 scores.put("cc.org", 2.0f); 8 } catch (IOException e) { 9 // TODO Auto-generated catch block 10 e.printStackTrace(); 11 } 12 } 13 /** 14 * 创建索引 15 */ 16 @SuppressWarnings("deprecation") 17 public void index(){ 18 IndexWriter writer = null; 19 try { 20 directory = FSDirectory.open(Paths.get("D://lucene//index")); 21 writer = getWriter(); 22 Document doc = null; 23 for(int i=0;i<ids.length;i++){ 24 doc = new Document(); 25 doc.add(new Field("id", ids[i], Field.Store.YES,Field.Index.NOT_ANALYZED_NO_NORMS)); 26 doc.add(new Field("name", names[i], Field.Store.YES,Field.Index.NOT_ANALYZED_NO_NORMS)); 27 doc.add(new Field("content", contents[i], Field.Store.NO,Field.Index.ANALYZED)); 28 //存储数字 29 doc.add(new IntField("attach", attachs[i], Field.Store.YES)); 30 31 // 加权操作 32 TextField field = new TextField("email", emails[i], Field.Store.YES); 33 String et = emails[i].substring(emails[i].lastIndexOf("@")+1); 34 if (scores.containsKey(et)) { 35 field.setBoost(scores.get(et)); 36 } 37 doc.add(field); 38 // 添加文档 39 writer.addDocument(doc); 40 } 41 } catch (Exception e) { 42 // TODO: handle exception 43 e.printStackTrace(); 44 }finally{ 45 try { 46 writer.close(); 47 } catch (IOException e) { 48 // TODO Auto-generated catch block 49 e.printStackTrace(); 50 } 51 } 52 }
索引建立完毕。

构造方法。
/** * getSearcher * @return */ public IndexSearcher getSearcher(){ try { directory = FSDirectory.open(Paths.get("D://lucene//index")); if(reader==null){ reader = DirectoryReader.open(directory); }else{ reader.close(); } return new IndexSearcher(reader); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } return null; }
一、精准匹配。
1,精准查询
就是查什么给什么。
1 /** 2 * 精准匹配 3 */ 4 public void search(String searchField,String field){ 5 // 得到读取索引文件的路径 6 IndexReader reader = null; 7 try { 8 directory = FSDirectory.open(Paths.get("D://lucene//index")); 9 reader = DirectoryReader.open(directory); 10 IndexSearcher searcher = new IndexSearcher(reader); 11 // 运用term来查找 12 Term t = new Term(searchField, field); 13 Query q = new TermQuery(t); 14 // 获得查询的hits 15 TopDocs hits = searcher.search(q, 10); 16 // 显示结果 17 System.out.println("匹配 '" + q + "',总共查询到" + hits.totalHits + "个文档"); 18 for (ScoreDoc scoreDoc : hits.scoreDocs){ 19 Document doc = searcher.doc(scoreDoc.doc); 20 System.out.println("id:"+doc.get("id")+":"+doc.get("name")+",email:"+doc.get("email")); 21 } 22 23 } catch (IOException e) { 24 // TODO Auto-generated catch block 25 e.printStackTrace(); 26 }finally{ 27 try { 28 reader.close(); 29 } catch (IOException e) { 30 // TODO Auto-generated catch block 31 e.printStackTrace(); 32 } 33 } 34 }
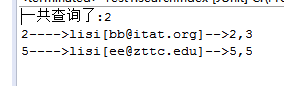
2,区间查询。
/** * between * @param field * @param start * @param end * @param num */ public void searchByTermRange(String field,String start,String end,int num) { try { IndexSearcher searcher = getSearcher(); BytesRef lowerTerm = new BytesRef(start.getBytes()) ; BytesRef upperTerm = new BytesRef(end.getBytes()) ; Query query = new TermRangeQuery(field, lowerTerm , upperTerm, true, true); TopDocs tds = searcher.search(query, num); System.out.println("一共查询了:"+tds.totalHits); for(ScoreDoc sd:tds.scoreDocs) { Document doc = searcher.doc(sd.doc); System.out.println(doc.get("id")+"---->"+ doc.get("name")+"["+doc.get("email")+"]-->"+doc.get("id")+","+ doc.get("attach")); } } catch (CorruptIndexException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } }
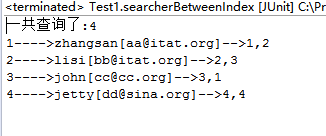
3、匹配其索引开始以指定的字符串的文档
1 /** 2 * 匹配其索引开始以指定的字符串的文档 3 * @param field 4 * @param value 5 * @param num 6 */ 7 public void searchByPrefix(String field,String value,int num) { 8 try { 9 IndexSearcher searcher = getSearcher(); 10 Query query = new PrefixQuery(new Term(field,value)); 11 TopDocs tds = searcher.search(query, num); 12 System.out.println("一共查到:"+tds.totalHits); 13 for(ScoreDoc scoreDoc:tds.scoreDocs){ 14 Document doc = searcher.doc(scoreDoc.doc); 15 System.out.println(doc.get("id")+"---->"+ 16 doc.get("name")+"["+doc.get("email")+"]-->"+doc.get("id")+","+ 17 doc.get("attach")); 18 } 19 } catch (Exception e) { 20 e.printStackTrace(); 21 } 22 }

4、数字搜索
/** * 数字搜索 * @param field * @param start * @param end * @param num */ public void searchByNums(String field,int start,int end,int num){ try { IndexSearcher searcher = getSearcher(); Query query = NumericRangeQuery.newIntRange(field, start, end, true, true); TopDocs tds = searcher.search(query, num); System.out.println("一共查到:"+tds.totalHits); for(ScoreDoc scoreDoc:tds.scoreDocs){ Document doc = searcher.doc(scoreDoc.doc); System.out.println(doc.get("id")+"---->"+ doc.get("name")+"["+doc.get("email")+"]-->"+doc.get("id")+","+ doc.get("attach")); } } catch (Exception e) { e.printStackTrace(); } }
二、模糊匹配
/** * 通配符 * @param field * @param value * @param num */ public void searchByWildcard(String field,String value,int num){ try { IndexSearcher searcher = getSearcher(); WildcardQuery query = new WildcardQuery(new Term(field,value)); TopDocs tds = searcher.search(query, num); System.out.println("一共查到:"+tds.totalHits); for(ScoreDoc scoreDoc:tds.scoreDocs){ Document doc = searcher.doc(scoreDoc.doc); System.out.println(doc.get("id")+"---->"+ doc.get("name")+"["+doc.get("email")+"]-->"+doc.get("id")+","+ doc.get("attach")); } } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } } /** * BooleanQuery可以连接多个子查询 * Occur.MUST表示必须出现 * Occur.SHOULD表示可以出现 * Occur.MUSE_NOT表示不能出现 * @param field * @param value * @param num */ @SuppressWarnings("deprecation") public void searchByBoolean(String[] field,String[] value,int num){ try { if(field.length!=value.length){ System.out.println("field的长度需要与value的长度相等!"); System.exit(0); } IndexSearcher searcher = getSearcher(); BooleanQuery query = null; TopDocs tds = null; for(int i = 0;i<field.length;i++){ query = new BooleanQuery(); query.add(new TermQuery(new Term(field[i],value[i])),Occur.SHOULD); tds = searcher.search(query, num); } System.out.println("一共查询:"+tds.totalHits); for(ScoreDoc doc:tds.scoreDocs){ Document document = searcher.doc(doc.doc); System.out.println(document.get("id")+"---->"+ document.get("name")+"["+document.get("email")+"]-->"+document.get("id")+","+ document.get("attach")); } } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } } public void searchByPhrase(int num){ try { IndexSearcher searcher = getSearcher(); PhraseQuery query = new PhraseQuery(); query.setSlop(3); query.add(new Term("content","like")); // //第一个Term query.add(new Term("content","football")); TopDocs tds = searcher.search(query, num); System.out.println("一共查询了:"+tds.totalHits); for(ScoreDoc sd:tds.scoreDocs) { Document doc = searcher.doc(sd.doc); System.out.println(doc.get("id")+"---->"+ doc.get("name")+"["+doc.get("email")+"]-->"+doc.get("id")+","+ doc.get("attach")); } } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } } /** * 相似度匹配查询 * @param num */ public void searchByFuzzy(int num) { try { IndexSearcher searcher = getSearcher(); FuzzyQuery query = new FuzzyQuery(new Term("name","jake")); TopDocs tds = searcher.search(query, num); System.out.println("一共查询了:"+tds.totalHits); for(ScoreDoc sd:tds.scoreDocs) { Document doc = searcher.doc(sd.doc); System.out.println(doc.get("id")+"---->"+ doc.get("name")+"["+doc.get("email")+"]-->"+doc.get("id")+","+ doc.get("attach")+","+doc.get("date")); } } catch (CorruptIndexException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } public void searchByQueryParse(Query query,int num) { try { IndexSearcher searcher = getSearcher(); TopDocs tds = searcher.search(query, num); System.out.println("一共查询了:"+tds.totalHits); for(ScoreDoc sd:tds.scoreDocs) { Document doc = searcher.doc(sd.doc); System.out.println(doc.get("id")+"---->"+ doc.get("name")+"["+doc.get("email")+"]-->"+doc.get("id")+","+ doc.get("attach")+","+doc.get("date")+"=="+sd.score); } } catch (CorruptIndexException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } }