发表时间:2021(ICLR 2021)
文章要点:这篇文章想说,在state里面其实有很多任务无关的东西,如果用Reconstruction之类的方式去做就还是会考虑这些东西,作者提出用Bisimulation metric去做representation,让latent space里面状态的距离等于Bisimulation metric。具体来说,Bisimulation metric的思路就是两个state的距离应该是reward的差和状态转移的差,所以就不考虑其他东西,就自然不会包含任务无关的表征。具体的,Bisimulation metric定义为
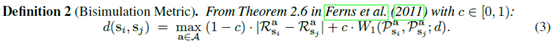
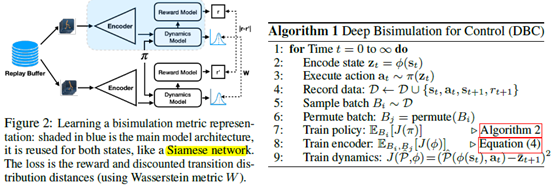
具体到算法,就是先有一个encoder把state弄到latent space,然后基于这个latent space的状态来训强化,比如SAC。这个Bisimulation metric就用来训encoder,具体到算法loss变成
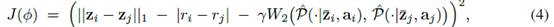
这里z就是经过encoder后在latent space里的状态,r就是reward,P就是状态转移,如果是随机转移,就考虑高斯分布。这里的意思就是说我从buffer里找两个状态,然后使这两个状态的距离就和r,P的差距一样。
其实这里面的dynamic P也是要训的,其实就相当于是个model based方法,这样J里面的P才能算得出来。
总结:总的来说就是提出了一个表征的方式,不考虑任务无关的东西,提高稳定性和泛化性。想法make sense,不过要连训三个东西,估计不太好训啊。另外里面写了好几个theorem,感觉和实验关系不大。
疑问:如果我用目标检测,语义分割,实例分割之类的技术来直接排除无关的object,会不会更直接?还是说有的东西不好判断是不是无关,所以不好做?
如果在train一个encoder的时候,某个物体被认为是无关的,然后在test environment上,这个物体其实是相关的,这样的话这个encoder的泛化性是不是直接无了?