发表时间:2020(ICML 2020)
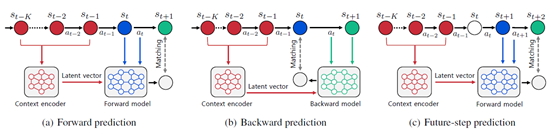
文章要点:这篇文章想说model based方法在data efficiency和planning方面都具有天然优势,但是model的泛化性通常是个问题。这篇文章提出学一个context相关的latent vector,然后用model去predict的时候会基于这个latent vector去做,这在一定程度上捕捉了环境变化的特征,使得model会根据latent vector的变换而调整。此外作者设计了一个loss function,使得model不仅去前向预测,还有一个model去做后向预测(predicting both forward and backward dynamics),作者说这样做有助于增强泛化性。
具体地,latent vector通过一个encoder实现
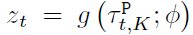
这里,(g)是encoder网络,(phi)是网络参数,( au)是过去K条轨迹
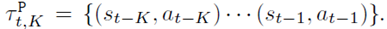
相当于说,给定过去K条轨迹,就输出一个当前dynamics的latent vector。另外,作者说并不是直接输入state,而是输入state的差,即
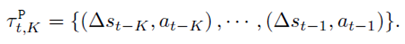
然后基于这个latent vector去训一个前向预测模型f(forward dynamics model)和一个后向预测模型b(backward dynamics model)
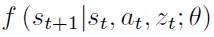
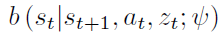
整个loss为
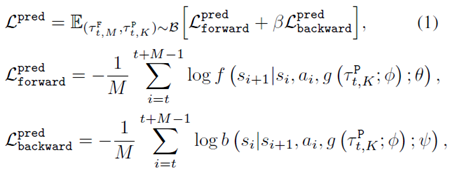
其中( au_M)是前向轨迹,( au_K)是后向轨迹。训好了之后就拿这个model去做planning就好了。此外,作者还直接把训好的latent vector用在model free算法上作为输入,作者说这也能提高model free算法的泛化性。整个算法流程如下

总结:idea感觉很自然也很简单,就相当于说给一个dynamics的先验。主要还是在做实验,关于那些loss啥的,应该是做实验发现效果好吧。
疑问:这个loss function感觉没写完吧,只写了预测,没有写反传的label啊。而且这个f和b不是预测状态吗,为什么要取个log,难道输出的是个概率?如果是概率的话,那这个f和b是输出预测状态的分布,那就是有限个状态的概率分布?
还有算法伪代码里面,最后encoder和dynamics model的更新是分开写的,那这个更新就不是同时更新的,而是一个一个轮流更新的?