在一些场景下,有些数据被访问的次数非常少,甚至只会被访问一次。当这些数据服务完访问请求后,如果还继续留存在缓存中的话,就只会白白占用缓存空间。这种情况,就是缓存污染。
如何解决缓存污染问题?
要解决缓存污染,我们也能很容易想到解决方案,那就是得把不会再被访问的数据筛选出来并淘汰掉。这样就不用等到缓存被写满以后,再逐一淘汰旧数据之后,才能写入新数据了。
volatile-random 和 allkeys-random 这两种策略:
-
它们都是采用随机挑选数据的方式,来筛选即将被淘汰的数据。
volatile-ttl 策略:
-
也可能出现数据被淘汰后,被再次访问导致的缓存缺失问题。
除了在明确知道数据被再次访问的情况下, volatile-ttl 可以有效避免缓存污染。在其他情况下,volatile-random、allkeys-random、volatile-ttl 这三种策略并不能应对缓存污染问题。
LRU 缓存策略
Redis 中的 LRU 策略,会在每个数据对应的 RedisObject 结构体中设置一个 lru 字段,用来记录数据的访问时间戳。在进行数据淘汰时,LRU 策略会在候选数据集中淘汰掉 lru 字段值最小的数据(也就是访问时间最久的数据)。
-
也正是因为只看数据的访问时间,使用 LRU 策略在处理扫描式单次查询操作时,无法解决缓存污染。
所谓的扫描式单次查询操作,就是指应用对大量的数据进行一次全体读取,每个数据都会被读取,而且只会被读取一次。此时,因为这些被查询的数据刚刚被访问过,所以 lru 字段值都很大。

lru 在遇到扫描式单次查询操作时, 会把热点数据挤出去.
LFU 缓存策略的优化
LFU 缓存策略是在 LRU 策略基础上,为每个数据增加了一个计数器,来统计这个数据的访问次数。当使用 LFU 策略筛选淘汰数据时,首先会根据数据的访问次数进行筛选,把访问次数最低的数据淘汰出缓存。如果两个数据的访问次数相同,LFU 策略再比较这两个数据的访问时效性,把距离上一次访问时间更久的数据淘汰出缓存。
和那些被频繁访问的数据相比,扫描式单次查询的数据因为不会被再次访问,所以它们的访问次数不会再增加。因此,LFU 策略会优先把这些访问次数低的数据淘汰出缓存。这样一来,LFU 策略就可以避免这些数据对缓存造成污染了。
Redis 在实现 LFU 策略的时候,只是把原来 24bit 大小的 lru 字段,又进一步拆分成了两部分。
-
ldt 值:lru 字段的前 16bit,表示数据的访问时间戳;
-
counter 值:lru 字段的后 8bit,表示数据的访问次数。
Redis 只使用了 8bit 记录数据的访问次数,而 8bit 记录的最大值是 255,这样可以吗?
在实现 LFU 策略时,Redis 并没有采用数据每被访问一次,就给对应的 counter 值加 1 的计数规则,而是采用了一个更优化的计数规则。
-
LFU 策略实现的计数规则是:每当数据被访问一次时,首先,用计数器当前的值乘以配置项 lfu_log_factor 再加 1,再取其倒数,得到一个 p 值;然后,把这个 p 值和一个取值范围在(0,1)间的随机数 r 值比大小,只有 p 值大于 r 值时,计数器才加 1。
下面这段 Redis 的部分源码,显示了 LFU 策略增加计数器值的计算逻辑。其中,baseval 是计数器当前的值。计数器的初始值默认是 5(由代码中的 LFU_INIT_VAL 常量设置),而不是 0,这样可以避免数据刚被写入缓存,就因为访问次数少而被立即淘汰。
double r = (double)rand()/RAND_MAX;...double p = 1.0/(baseval*server.lfu_log_factor+1);if (r < p) counter++;
为了更进一步说明 LFU 策略计数器递增的效果,你可以看下下面这张表。这是 Redis官网上提供的一张表,它记录了当 lfu_log_factor 取不同值时,在不同的实际访问次数情况下,计数器的值是如何变化
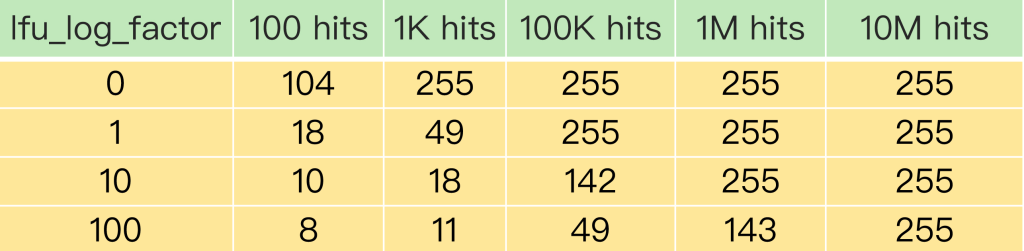
推荐设置 lfu_log_factor 为10.
在一些场景下,有些数据在短时间内被大量访问后就不会再被访问了。那么再按照访问次数来筛选的话,这些数据会被留存在缓存中,但不会提升缓存命中率。为此,Redis 在实现 LFU 策略时,还设计了一个 counter 值的衰减机制。
LFU 策略使用衰减因子配置项 lfu_decay_time 来控制访问次数的衰减。LFU 策略会计算当前时间和数据最近一次访问时间的差值,并把这个差值换算成以分钟为单位。然后,LFU 策略再把这个差值除以 lfu_decay_time 值,所得的结果就是数据 counter 要衰减的值。
小结
缓存污染问题指的是留存在缓存中的数据,实际不会被再次访问了,但是又占据了缓存空间。如果这样的数据体量很大,甚至占满了缓存,每次有新数据写入缓存时,还需要把这些数据逐步淘汰出缓存,就会增加缓存操作的时间开销。
-
要解决缓存污染问题,最关键的技术点就是能识别出这些只访问一次或是访问次数很少的数据,在淘汰数据时,优先把它们筛选出来并淘汰掉。
往期推荐
- Redis哨兵集群中哨兵挂了,主从库还能切换吗?
- 这样学Redis,才能技高一筹!
- 解读Redis缓存穿透,击穿以雪崩问题,附带解决方式
- 除了手动清理,Redi还有哪些回收策略?
- 两分钟解读Redis单机,主从,哨兵,集群架构
