一、检索数据
1、不能部分使用DISTINCT,DISTINCT关键字应用于所有列而不仅是前置它的列。
2、检索出来的数据的行号从0开始。带一个值的LIMIT总是从第一行开始,给出的数为返回的行数;带两个值的LIMIT可以指定从行号为第一个值的位置开始,第二个值为返回的行数。
二、排序检索数据
检索出的数据并不是以纯粹的随机顺序显示的。如果不排序,数据一般将以它在底层表中出现的顺序显示。这可以是数据最初添加到表中的顺序。但是,如果数据后来进行过更新或删除,则此顺序将会受到MySQL重用回收存储空间的影响。因此,如果不明确控制的话,不能依赖该排序顺序。为了明确地排序用SELECT语句检索出的数据,可以使用ORDER BY子句。
1、默认地,ORDER BY按ASC排序。
2、ASC/DESC关键字只应用到直接位于其前面的列名。因此,如果想在多个列上进行降序排序,必须对每个列指定DESC关键字。
3、在给出ORDER BY子句时,应该保证它位于FROM子句之后。如果使用LIMIT,它必须位于ORDER BY之后。
三、过滤数据
1、MySQL在执行匹配时默认不区分大小写。
2、BETWEEN匹配范围中所有的值,包括指定的开始值和结束值。
3、NULL表示无值,它与字段包含0、空字符串或仅仅包含空格不同。可以用 IS NULL 子句来检查具有NULL值的列。
4、在通过过滤选择出不具有特定值的行时,你可能希望返回具有NULL值的行。但是,不行。因为NULL具有特殊的含义,数据库不知道它们是否匹配,所以在匹配过滤或不匹配过滤时不返回它们。
5、IN (L,R),IN操作符用来指定条件范围,范围中的每个条件都可以进行匹配,包括L、R。
6、NOT操作符有且只有一个功能,那就是否定它之后所跟的任何条件。MySQL支持使用NOT对IN、BETWEEN和EXISTS子句取反。
四、用通配符进行过滤
通配符:用来匹配值的一部分的特殊字符。
搜索模式:由字面值、通配符或两者组合构成的搜索条件。
为在搜索子句中使用通配符,必须使用LIKE操作符。LIKE指示MySQL,后跟的搜索模式利用通配符匹配而不是直接相等匹配进行比较。
1、%通配符表示任意字符出现任意次数。即使是%也不能匹配NULL。
2、_通配符表示匹配一个字符。
注意:通配符搜索的处理一般要比其他搜索所花时间更长。不要过度使用通配符,如果其他操作符能达到相同的目的,应该使用其他操作符。在确实需要使用通配符时,除非绝对有必要,否则不要把它们用在搜索模式的开始处。置于搜索模式的开始处,搜索起来是最慢的。
五、正则表达式
正则表达式的关键字是REGEXP。
1、在LIKE和REGEXP有一个重要的差别,如下所示。
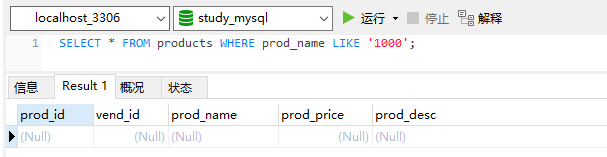
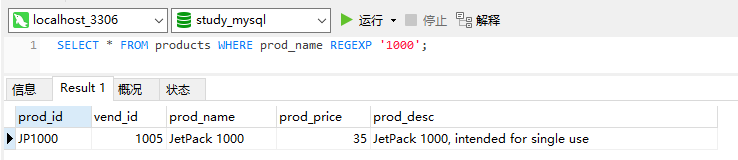
第一条语句不返回数据,第二条才返回数据,为什么?因为,LIKE匹配整个列,如果被匹配的文本在列值中出现,LIKE将不会找到它,想应的行也不会被返回(除非使用通配符)。而REGEXP在列值内进行匹配,如果被匹配的文本在列值中出现,REGEXP将会找到它,相应的行将被返回。
2、.是正则表达式语言中一个特殊的字符,表示匹配任意一个字符。
3、MySQL中的正则表达式匹配不区分大小写。为区分大小写,可在REGEXP后跟上关键字BINARY。
4、|为正则表达式的OR操作符,表示匹配其中之一。除非把|括在一个集合中,否则它将应用于整个串。
5、如果只想匹配特定的字符,可以指定一组用 [ 和 ] 括起来的字符来完成。[]是另一种形式的OR语句。例如:'[123] Ton'是'[1|2|3] Ton'的缩写,[123]定义一组字符,它的意思是匹配1或2或3,因此1 Ton和2 Ton和3 Ton都匹配。
6、字符集合也可以被否定,即,它们将匹配除指定字符外的任何东西。为否定一个字符集,在集合的开始处放置一个^即可。因此,尽管[123]匹配字符1、2、3,但[^123]却匹配除这些字符外的任何东西。
7、可以使用 - 来定义集合的一个范围。[1-5]等价于[12345]。[a-z]匹配任意字母字符。
8、正则表达式语言由具有特定含义的特殊字符构成。为了匹配特殊字符,必须用\为前导。\-表示查找-,\.表示查找.。
9、匹配字符类
[:alnum:] 任意字母和数字(同[a-zA-Z0-9])
[:alpha:] 任意字符(同[a-zA-Z])
[:blank:] 空格和制表(同[ ])
[:cntrl:] ASCII控制字符(ASCII 0到31和127)
[:digit:] 任意数字(同[0-9])
[:graph:] 与[:print:]相同,但不包括空格
[:lower:] 任意小写字母(同[a-z])
[:print:] 任意可打印字符
[:punct:] 既不在[:alnum:]又不在[:cntrl:]中的任意字符
[:space:] 包括空格在内的任意空白字符(同[f v])
[:upper:] 任意大写字母(同[A-Z])
[:xdigit:] 任意十六进制数字(同[a-fA-F0-9])
10、目前为止使用的正则表达式都试图匹配单次出现。如果存在一个匹配,该行被检索出来,如果不存在,检索不出任何行。但有时候需要对匹配的数目进行更强的控制,这时就需要正则表达式重复元字符来完成。
* 0个或多个匹配
? 0个或1个匹配(等于{0,1})
{n} 指定数目的匹配
{n,} 不少于指定数目的匹配
{n,m} 匹配数目的范围(m不超过255)
将重复元字符放在想匹配的字符后面,即可匹配多个。
11、为了匹配特定位置的文本,需要使用定位符。
^ 匹配文本的开始
$ 匹配文本的结尾
[[:<:]] 匹配词的开始
[[:>:]] 匹配词的结尾