声明
1)本文仅供学术交流,非商用。所以每一部分具体的参考资料并没有详细对应。如果某部分不小心侵犯了大家的利益,还望海涵,并联系博主删除。
2)博主才疏学浅,文中如有不当之处,请各位指出,共同进步,谢谢。
3)此属于第一版本,若有错误,还需继续修正与增删。还望大家多多指点。大家都共享一点点,一起为祖国科研的推进添砖加瓦。
文章目录
0、前言
在之前写过一个手撕代码系列 深度学习之手撕神经网络代码(基于numpy),搭建了感知机和一个隐藏层的神经网络,理解了神经网络的基本结构和传播原理,掌握了如何从零开始手写一个神经网络。但是神经网络和深度学习之所以效果奇佳的一个原因就是,隐藏层多,网络结构深,很久之前一个小伙伴想让我写一个基于numpy的DNN,一直没填坑,今天就来写一下。
1、神经网络步骤
不知道你还记不记得搭建一个神经网络结构的步骤(深度学习之手撕神经网络代码(基于numpy)),大概是六点:
- 构建网络
- 初始化参数
- 迭代优化
- 计算损失
- 反向传播
- 更新参数
简洁地说就是三点,即构建网络、赋值参数、循环计算。
- 首先是确定准备搭建的网络结构是怎么样的(大话卷积神经网络CNN(干货满满)),比如经典的AlexNet,VGGNet等等;
- 然后是对权重w和偏置b进行参数初始化(深度学习入门笔记(十二):权重初始化),比如Xavier初始化,He初始化等等;
- 最后是迭代计算,(深度学习之手撕神经网络代码(基于numpy)),比如前向传播,反向传播等等。

2、深度神经网络
之前写过的一些深度神经网络的理论:
需要补得童鞋可以看一下,避免后面不懂。这里就简单说两句,底层神经网络提取特征,然后接着卷积池化,再经过神经元的激活和随机失活,从而实现前行传播,计算损失函数,反向传播回调整参数,优化迭代过程。
以一个简单的手写数字识别为例,图例是整个过程:
- 端到端无中间操作,像素值即特征,转换为向量,经过深度神经网络,输出独热编码概率。

- 网络结构包括输入层,输出层和隐藏层,前向传播即,卷积池化并输出下一层,反向传播也是如此,只不过是反着的。

- 得到一张图片,提取其中的像素输入到,GPU加速训练过的神经网络中,输出结果就是分类结果。

3、初始化参数
深度神经网络的隐藏层数量用 layer_dims 表示,这样一共有多少层就不用全部写出来了,更加方便灵活:
def initialize_parameters_deep(layer_dims):
# 随机种子
np.random.seed(3)
parameters = {}
# 网络层数
L = len(layer_dims)
for l in range(1, L):
parameters['W' + str(l)] = np.random.randn(layer_dims[l], layer_dims[l-1])*0.01
parameters['b' + str(l)] = np.zeros((layer_dims[l], 1))
assert(parameters['W' + str(l)].shape == (layer_dims[l], layer_dims[l-1]))
assert(parameters['b' + str(l)].shape == (layer_dims[l], 1))
return parameters
上述代码使用的是随机数和归零操作来初始化权重 W 和偏置 b,如果想要别的初始化方式,几种常用的初始化方式的numpy写法如下:
- 截断正态分布初始化
def truncated_normal(mean, std, out_shape):
"""
Parameters
----------
mean : float or array_like of floats
The mean/center of the distribution
std : float or array_like of floats
Standard deviation (spread or "width") of the distribution.
out_shape : int or tuple of ints
Output shape. If the given shape is, e.g., ``(m, n, k)``, then
``m * n * k`` samples are drawn.
Returns
-------
samples : :py:class:`ndarray <numpy.ndarray>` of shape `out_shape`
Samples from the truncated normal distribution parameterized by `mean`
and `std`.
"""
samples = np.random.normal(loc=mean, scale=std, size=out_shape)
reject = np.logical_or(samples >= mean + 2 * std, samples <= mean - 2 * std)
while any(reject.flatten()):
resamples = np.random.normal(loc=mean, scale=std, size=reject.sum())
samples[reject] = resamples
reject = np.logical_or(samples >= mean + 2 * std, samples <= mean - 2 * std)
return samples
- He正态分布初始化
def he_normal(weight_shape):
"""
Parameters
----------
weight_shape : tuple
The dimensions of the weight matrix/volume.
Returns
-------
W : :py:class:`ndarray <numpy.ndarray>` of shape `weight_shape`
The initialized weights.
"""
fan_in, fan_out = calc_fan(weight_shape)
std = np.sqrt(2 / fan_in)
return truncated_normal(0, std, weight_shape)
- Glorot正态分布初始化(Xavier)
def glorot_normal(weight_shape, gain=1.0):
"""
Parameters
----------
weight_shape : tuple
The dimensions of the weight matrix/volume.
Returns
-------
W : :py:class:`ndarray <numpy.ndarray>` of shape `weight_shape`
The initialized weights.
"""
fan_in, fan_out = calc_fan(weight_shape)
std = gain * np.sqrt(2 / (fan_in + fan_out))
return truncated_normal(0, std, weight_shape)
这三个初始化方式可自行调用,这里就按照最简单的讲解了。
小应用
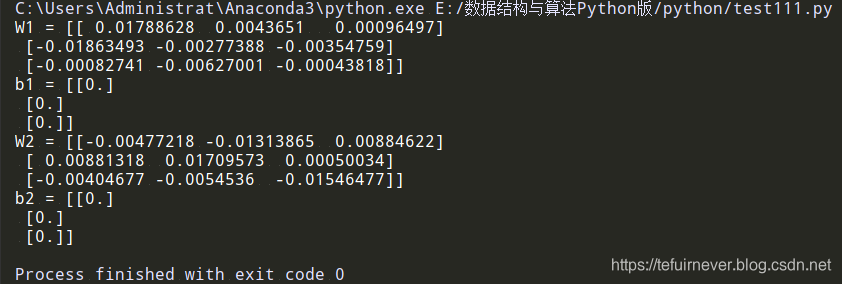
假设一个输入层大小 3 ,隐藏层大小 3,输出层大小 3 的深度神经网络,然后调用参数初始化函数,输入参数 [3,3,3,输出如下:
parameters = initialize_parameters_deep([3,3,3])
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))
4、激活函数
除了经常使用的 sigmoid 激活函数,就是 ReLU 激活函数了,有 Leaky RELU,ELU,SELU,Softplus 等等。
wikipedia列出来的这些函数:

几种常用的激活函数的numpy写法如下:
from abc import ABC, abstractmethod
import numpy as np
class ActivationBase(ABC):
def __init__(self, **kwargs):
super().__init__()
def __call__(self, z):
if z.ndim == 1:
z = z.reshape(1, -1)
return self.fn(z)
@abstractmethod
def fn(self, z):
raise NotImplementedError
@abstractmethod
def grad(self, x, **kwargs):
raise NotImplementedError
class Sigmoid(ActivationBase):
def __init__(self):
"""
A logistic sigmoid activation function.
"""
super().__init__()
def __str__(self):
return "Sigmoid"
def fn(self, z):
"""
Evaluate the logistic sigmoid, :math:`sigma`, on the elements of input `z`.
"""
return 1 / (1 + np.exp(-z))
def grad(self, x):
"""
Evaluate the first derivative of the logistic sigmoid on the elements of `x`.
"""
fn_x = self.fn(x)
return fn_x * (1 - fn_x)
def grad2(self, x):
"""
Evaluate the second derivative of the logistic sigmoid on the elements of `x`.
"""
fn_x = self.fn_x
return fn_x * (1 - fn_x) * (1 - 2 * fn_x)
class ReLU(ActivationBase):
"""
A rectified linear activation function.
"""
def __init__(self):
super().__init__()
def __str__(self):
return "ReLU"
def fn(self, z):
"""
Evaulate the ReLU function on the elements of input `z`.
"""
return np.clip(z, 0, np.inf)
def grad(self, x):
"""
Evaulate the first derivative of the ReLU function on the elements of input `x`.
"""
return (x > 0).astype(int)
def grad2(self, x):
"""
Evaulate the second derivative of the ReLU function on the elements of input `x`.
"""
return np.zeros_like(x)
class LeakyReLU(ActivationBase):
"""
'Leaky' version of a rectified linear unit (ReLU).
"""
def __init__(self, alpha=0.3):
self.alpha = alpha
super().__init__()
def __str__(self):
return "Leaky ReLU(alpha={})".format(self.alpha)
def fn(self, z):
"""
Evaluate the leaky ReLU function on the elements of input `z`.
"""
_z = z.copy()
_z[z < 0] = _z[z < 0] * self.alpha
return _z
def grad(self, x):
"""
Evaluate the first derivative of the leaky ReLU function on the elements
of input `x`.
"""
out = np.ones_like(x)
out[x < 0] *= self.alpha
return out
def grad2(self, x):
"""
Evaluate the second derivative of the leaky ReLU function on the elements of input `x`.
"""
return np.zeros_like(x)
class ELU(ActivationBase):
def __init__(self, alpha=1.0):
"""
An exponential linear unit (ELU).
-----
Parameters
----------
alpha : float
Slope of negative segment. Default is 1.
"""
self.alpha = alpha
super().__init__()
def __str__(self):
return "ELU(alpha={})".format(self.alpha)
def fn(self, z):
"""
Evaluate the ELU activation on the elements of input `z`.
"""
# z if z > 0 else alpha * (e^z - 1)
return np.where(z > 0, z, self.alpha * (np.exp(z) - 1))
def grad(self, x):
"""
Evaluate the first derivative of the ELU activation on the elements
of input `x`.
"""
# 1 if x > 0 else alpha * e^(z)
return np.where(x > 0, np.ones_like(x), self.alpha * np.exp(x))
def grad2(self, x):
"""
Evaluate the second derivative of the ELU activation on the elements
of input `x`.
"""
# 0 if x > 0 else alpha * e^(z)
return np.where(x >= 0, np.zeros_like(x), self.alpha * np.exp(x))
class SELU(ActivationBase):
"""
A scaled exponential linear unit (SELU).
"""
def __init__(self):
self.alpha = 1.6732632423543772848170429916717
self.scale = 1.0507009873554804934193349852946
self.elu = ELU(alpha=self.alpha)
super().__init__()
def __str__(self):
return "SELU"
def fn(self, z):
"""
Evaluate the SELU activation on the elements of input `z`.
"""
return self.scale * self.elu.fn(z)
def grad(self, x):
"""
Evaluate the first derivative of the SELU activation on the elements
of input `x`.
"""
return np.where(
x >= 0, np.ones_like(x) * self.scale, np.exp(x) * self.alpha * self.scale
)
def grad2(self, x):
"""
Evaluate the second derivative of the SELU activation on the elements
of input `x`.
"""
return np.where(x > 0, np.zeros_like(x), np.exp(x) * self.alpha * self.scale)
class SoftPlus(ActivationBase):
def __init__(self):
"""
A softplus activation function.
"""
super().__init__()
def __str__(self):
return "SoftPlus"
def fn(self, z):
"""
Evaluate the softplus activation on the elements of input `z`.
"""
return np.log(np.exp(z) + 1)
def grad(self, x):
"""
Evaluate the first derivative of the softplus activation on the elements
of input `x`.
"""
exp_x = np.exp(x)
return exp_x / (exp_x + 1)
def grad2(self, x):
"""
Evaluate the second derivative of the softplus activation on the elements
of input `x`.
"""
exp_x = np.exp(x)
return exp_x / ((exp_x + 1) ** 2)
5、前向传播
我们这里仅仅使用 sigmoid 和 relu 两种激活函数进行前向传播,代码如下:
def linear_activation_forward(A_prev, W, b, activation):
if activation == "sigmoid":
Z, linear_cache = linear_forward(A_prev, W, b)
A, activation_cache = sigmoid(Z)
elif activation == "relu":
Z, linear_cache = linear_forward(A_prev, W, b)
A, activation_cache = relu(Z)
assert (A.shape == (W.shape[0], A_prev.shape[1]))
cache = (linear_cache, activation_cache)
return A, cache
A_prev 是前一步前向计算的结果,W 和 b 分别对应权重和偏置,中间有一个激活函数判断。如果你想更换激活函数,直接替换即可。
对于某一层的前向传播过程如下:
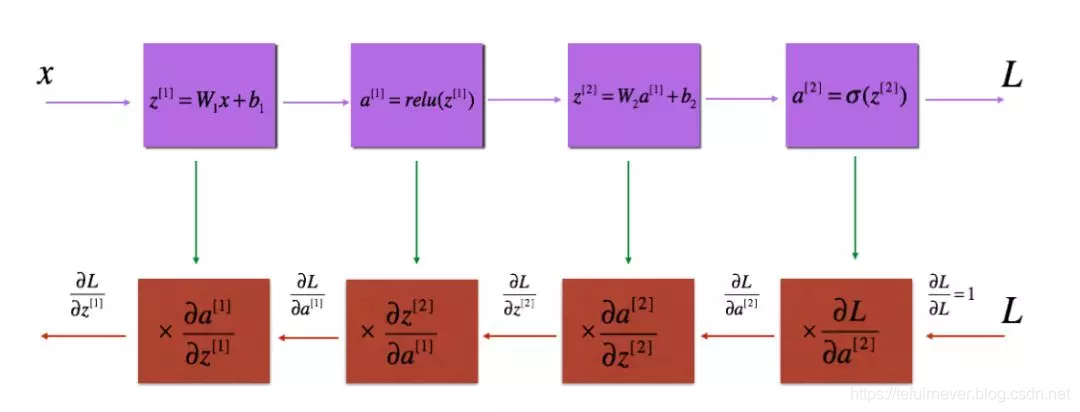
实现过程如下:
def L_model_forward(X, parameters):
caches = []
A = X
网络层数
L = len(parameters) // 2
# 实现[LINEAR -> RELU]*(L-1)
for l in range(1, L):
A_prev = A
A, cache = linear_activation_forward(A_prev, parameters["W"+str(l)], parameters["b"+str(l)], "relu")
caches.append(cache)
# 实现LINEAR -> SIGMOID
AL, cache = linear_activation_forward(A, parameters["W"+str(L)], parameters["b"+str(L)], "sigmoid")
caches.append(cache)
assert(AL.shape == (1,X.shape[1]))
return AL, caches
6、计算损失
通过前向传播得到结果之后,根据结果去计算损失函数大小。
from abc import ABC, abstractmethod
import numpy as np
import numbers
def is_binary(x):
"""Return True if array `x` consists only of binary values"""
msg = "Matrix must be binary"
assert np.array_equal(x, x.astype(bool)), msg
return True
def is_stochastic(X):
"""True if `X` contains probabilities that sum to 1 along the columns"""
msg = "Array should be stochastic along the columns"
assert len(X[X < 0]) == len(X[X > 1]) == 0, msg
assert np.allclose(np.sum(X, axis=1), np.ones(X.shape[0])), msg
return True
class OptimizerInitializer(object):
def __init__(self, param=None):
"""
A class for initializing optimizers. Valid inputs are:
(a) __str__ representations of `OptimizerBase` instances
(b) `OptimizerBase` instances
(c) Parameter dicts (e.g., as produced via the `summary` method in
`LayerBase` instances)
If `param` is `None`, return the SGD optimizer with default parameters.
"""
self.param = param
def __call__(self):
param = self.param
if param is None:
opt = SGD()
elif isinstance(param, OptimizerBase):
opt = param
elif isinstance(param, str):
opt = self.init_from_str()
elif isinstance(param, dict):
opt = self.init_from_dict()
return opt
def init_from_str(self):
r = r"([a-zA-Z]*)=([^,)]*)"
opt_str = self.param.lower()
kwargs = dict([(i, eval(j)) for (i, j) in re.findall(r, opt_str)])
if "sgd" in opt_str:
optimizer = SGD(**kwargs)
elif "adagrad" in opt_str:
optimizer = AdaGrad(**kwargs)
elif "rmsprop" in opt_str:
optimizer = RMSProp(**kwargs)
elif "adam" in opt_str:
optimizer = Adam(**kwargs)
else:
raise NotImplementedError("{}".format(opt_str))
return optimizer
def init_from_dict(self):
O = self.param
cc = O["cache"] if "cache" in O else None
op = O["hyperparameters"] if "hyperparameters" in O else None
if op is None:
raise ValueError("Must have `hyperparemeters` key: {}".format(O))
if op and op["id"] == "SGD":
optimizer = SGD().set_params(op, cc)
elif op and op["id"] == "RMSProp":
optimizer = RMSProp().set_params(op, cc)
elif op and op["id"] == "AdaGrad":
optimizer = AdaGrad().set_params(op, cc)
elif op and op["id"] == "Adam":
optimizer = Adam().set_params(op, cc)
elif op:
raise NotImplementedError("{}".format(op["id"]))
return optimizer
class WeightInitializer(object):
def __init__(self, act_fn_str, mode="glorot_uniform"):
"""
A factory for weight initializers.
-----
Parameters
----------
act_fn_str : str
The string representation for the layer activation function
mode : str (default: 'glorot_uniform')
The weight initialization strategy. Valid entries are {"he_normal",
"he_uniform", "glorot_normal", glorot_uniform", "std_normal",
"trunc_normal"}
"""
if mode not in [
"he_normal",
"he_uniform",
"glorot_normal",
"glorot_uniform",
"std_normal",
"trunc_normal",
]:
raise ValueError("Unrecognize initialization mode: {}".format(mode))
self.mode = mode
self.act_fn = act_fn_str
if mode == "glorot_uniform":
self._fn = glorot_uniform
elif mode == "glorot_normal":
self._fn = glorot_normal
elif mode == "he_uniform":
self._fn = he_uniform
elif mode == "he_normal":
self._fn = he_normal
elif mode == "std_normal":
self._fn = np.random.randn
elif mode == "trunc_normal":
self._fn = partial(truncated_normal, mean=0, std=1)
def __call__(self, weight_shape):
if "glorot" in self.mode:
gain = self._calc_glorot_gain()
W = self._fn(weight_shape, gain)
elif self.mode == "std_normal":
W = self._fn(*weight_shape)
else:
W = self._fn(weight_shape)
return W
def _calc_glorot_gain(self):
"""
Values from:
https://pytorch.org/docs/stable/nn.html?#torch.nn.init.calculate_gain
"""
gain = 1.0
act_str = self.act_fn.lower()
if act_str == "tanh":
gain = 5.0 / 3.0
elif act_str == "relu":
gain = np.sqrt(2)
elif "leaky relu" in act_str:
r = r"leaky relu(alpha=(.*))"
alpha = re.match(r, act_str).groups()[0]
gain = np.sqrt(2 / 1 + float(alpha) ** 2)
return gain
class ObjectiveBase(ABC):
def __init__(self):
super().__init__()
@abstractmethod
def loss(self, y_true, y_pred):
pass
@abstractmethod
def grad(self, y_true, y_pred, **kwargs):
pass
class SquaredError(ObjectiveBase):
def __init__(self):
"""
A squared-error / `L2` loss.
"""
super().__init__()
def __call__(self, y, y_pred):
return self.loss(y, y_pred)
def __str__(self):
return "SquaredError"
@staticmethod
def loss(y, y_pred):
"""
Compute the squared error between `y` and `y_pred`.
-----
Parameters
----------
y : :py:class:`ndarray <numpy.ndarray>` of shape (n, m)
Ground truth values for each of `n` examples
y_pred : :py:class:`ndarray <numpy.ndarray>` of shape (n, m)
Predictions for the `n` examples in the batch.
Returns
-------
loss : float
The sum of the squared error across dimensions and examples.
"""
return 0.5 * np.linalg.norm(y_pred - y) ** 2
@staticmethod
def grad(y, y_pred, z, act_fn):
"""
Gradient of the squared error loss with respect to the pre-nonlinearity
input, `z`.
-----
Parameters
----------
y : :py:class:`ndarray <numpy.ndarray>` of shape (n, m)
Ground truth values for each of `n` examples.
y_pred : :py:class:`ndarray <numpy.ndarray>` of shape (n, m)
Predictions for the `n` examples in the batch.
act_fn : :doc:`Activation <numpy_ml.neural_nets.activations>` object
The activation function for the output layer of the network.
Returns
-------
grad : :py:class:`ndarray <numpy.ndarray>` of shape (n, m)
The gradient of the squared error loss with respect to `z`.
"""
return (y_pred - y) * act_fn.grad(z)
class CrossEntropy(ObjectiveBase):
def __init__(self):
"""
A cross-entropy loss.
"""
super().__init__()
def __call__(self, y, y_pred):
return self.loss(y, y_pred)
def __str__(self):
return "CrossEntropy"
@staticmethod
def loss(y, y_pred):
"""
Compute the cross-entropy (log) loss.
-----
Parameters
----------
y : :py:class:`ndarray <numpy.ndarray>` of shape (n, m)
Class labels (one-hot with `m` possible classes) for each of `n`
examples.
y_pred : :py:class:`ndarray <numpy.ndarray>` of shape (n, m)
Probabilities of each of `m` classes for the `n` examples in the
batch.
Returns
-------
loss : float
The sum of the cross-entropy across classes and examples.
"""
is_binary(y)
is_stochastic(y_pred)
# prevent taking the log of 0
eps = np.finfo(float).eps
# each example is associated with a single class; sum the negative log
# probability of the correct label over all samples in the batch.
# observe that we are taking advantage of the fact that y is one-hot
# encoded
cross_entropy = -np.sum(y * np.log(y_pred + eps))
return cross_entropy
@staticmethod
def grad(y, y_pred):
"""
Compute the gradient of the cross entropy loss with regard to the
softmax input, `z`.
-----
Parameters
----------
y : :py:class:`ndarray <numpy.ndarray>` of shape `(n, m)`
A one-hot encoding of the true class labels. Each row constitues a
training example, and each column is a different class.
y_pred: :py:class:`ndarray <numpy.ndarray>` of shape `(n, m)`
The network predictions for the probability of each of `m` class
labels on each of `n` examples in a batch.
Returns
-------
grad : :py:class:`ndarray <numpy.ndarray>` of shape (n, m)
The gradient of the cross-entropy loss with respect to the *input*
to the softmax function.
"""
is_binary(y)
is_stochastic(y_pred)
# derivative of xe wrt z is y_pred - y_true, hence we can just
# subtract 1 from the probability of the correct class labels
grad = y_pred - y
# [optional] scale the gradients by the number of examples in the batch
# n, m = y.shape
# grad /= n
return
这里用最简单的两个单元计算,函数如下:
def compute_cost(AL, Y):
m = Y.shape[1]
# Compute loss from aL and y.
cost = -np.sum(np.multiply(Y,np.log(AL))+np.multiply(1-Y,np.log(1-AL)))/m
cost = np.squeeze(cost)
assert(cost.shape == ())
return cost
7、反向传播
反向传播的关键在于链式法则求导,好在上次课有认真推倒过交叉熵的导数,同时以前写过一个 深度学习100问之深入理解Back Propagation(反向传播),如果认真看过的话,反向传播应该不会再有手撕代码的问题。


因而现行反向传播函数代码如下:
def linear_backward(dZ, cache):
A_prev, W, b = cache
m = A_prev.shape[1]
dW = np.dot(dZ, A_prev.T)/m
db = np.sum(dZ, axis=1, keepdims=True)/m
dA_prev = np.dot(W.T, dZ)
assert (dA_prev.shape == A_prev.shape)
assert (dW.shape == W.shape)
assert (db.shape == b.shape)
return dA_prev, dW, db
还有线性激活反向传播函数如下:
def linear_activation_backward(dA, cache, activation):
linear_cache, activation_cache = cache
if activation == "relu":
dZ = relu_backward(dA, activation_cache)
dA_prev, dW, db = linear_backward(dZ, linear_cache)
elif activation == "sigmoid":
dZ = sigmoid_backward(dA, activation_cache)
dA_prev, dW, db = linear_backward(dZ, linear_cache)
return dA_prev, dW, db
得到反向传播函数如下:
def L_model_backward(AL, Y, caches):
grads = {}
L = len(caches)
# 层数
m = AL.shape[1]
Y = Y.reshape(AL.shape)
# after this line, Y is the same shape as AL
# 初始化backpropagation
dAL = - (np.divide(Y, AL) - np.divide(1 - Y, 1 - AL))
current_cache = caches[L-1]
grads["dA" + str(L)], grads["dW" + str(L)], grads["db" + str(L)] = linear_activation_backward(dAL, current_cache, "sigmoid")
for l in reversed(range(L - 1)):
current_cache = caches[l]
dA_prev_temp, dW_temp, db_temp = linear_activation_backward(grads["dA" + str(l + 2)], current_cache, "relu")
grads["dA" + str(l + 1)] = dA_prev_temp
grads["dW" + str(l + 1)] = dW_temp
grads["db" + str(l + 1)] = db_temp
return grads
建议认真看一看反向传播,尤其是交叉熵的求导,堪称是复合函数求导的极致,如果能推倒明白了,基本上就没啥大问题了。
8、参数更新
反向传播之后,就是参数更新了,函数如下:
def update_parameters(parameters, grads, learning_rate):
# number of layers in the neural network
L = len(parameters) // 2
# Update rule for each parameter. Use a for loop.
for l in range(L):
parameters["W" + str(l+1)] = parameters["W"+str(l+1)] - learning_rate*grads["dW"+str(l+1)]
parameters["b" + str(l+1)] = parameters["b"+str(l+1)] - learning_rate*grads["db"+str(l+1)]
return parameters
9、封装搭建过程(选看)
到这来,一个DNN就已经全部搭建完成了,和上一节类似,肯定想对这些函数进行一下简单的封装,代码如下:
def L_layer_model(X, Y, layers_dims, learning_rate = 0.0075, num_iterations = 3000, print_cost=False):
np.random.seed(1)
costs = []
# 参数初始化
parameters = initialize_parameters_deep(layers_dims)
# 循环迭代
for i in range(0, num_iterations):
# 前向传播:
# [LINEAR -> RELU]*(L-1) -> LINEAR -> SIGMOID
AL, caches = L_model_forward(X, parameters)
# 计算损失
cost = compute_cost(AL, Y)
# 反向传播
grads = L_model_backward(AL, Y, caches)
# 参数更新
parameters = update_parameters(parameters, grads, learning_rate)
# 每训练100个样本打印一次损失
if print_cost and i % 100 == 0:
print ("Cost after iteration %i: %f" %(i, cost))
costs.append(cost)
# 给损失画图
plt.plot(np.squeeze(costs))
plt.ylabel('cost')
plt.xlabel('iterations (per tens)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
return parameters
到这来一个深度神经网络就已经完整地搭建完毕了,原代码是吴恩达深度学习课程的代码,可以GitHub寻找一下,如果实在找不到也可以留言。
下面是一些其他结构的numpy代码:
Appendix_1、数据读取
minibatch 可以提高算法的运行速度,同时增加训练过程中的随机性。

蓝色是 minibatch,紫色是 fullbatch。
def minibatch(X, batchsize=256, shuffle=True):
"""
Compute the minibatch indices for a training dataset.
Parameters
----------
X : :py:class:`ndarray <numpy.ndarray>` of shape `(N, *)`
The dataset to divide into minibatches. Assumes the first dimension
represents the number of training examples.
batchsize : int
The desired size of each minibatch. Note, however, that if ``X.shape[0] %
batchsize > 0`` then the final batch will contain fewer than batchsize
entries. Default is 256.
shuffle : bool
Whether to shuffle the entries in the dataset before dividing into
minibatches. Default is True.
Returns
-------
mb_generator : generator
A generator which yields the indices into X for each batch
n_batches: int
The number of batches
"""
N = X.shape[0]
ix = np.arange(N)
n_batches = int(np.ceil(N / batchsize))
if shuffle:
np.random.shuffle(ix)
def mb_generator():
for i in range(n_batches):
yield ix[i * batchsize : (i + 1) * batchsize]
return mb_generator(), n_batches
Appendix_2、学习率设置
学习率与迭代下降的速度有关,当学习率设置的过小时,收敛过程将变得十分缓慢;而当学习率设置的过大时,梯度可能会在最小值附近来回震荡,甚至可能无法收敛。

学习率衰减的效果如下:

可以由上图看出,固定学习率时,当收敛时,会在最优值附近一个较大的区域内摆动;而学习率衰减,当收敛时,会在最优值附近一个更小的区域内摆动。
from copy import deepcopy
from abc import ABC, abstractmethod
import numpy as np
from math import erf
def gaussian_cdf(x, mean, var):
"""
Compute the probability that a random draw from a 1D Gaussian with mean
`mean` and variance `var` is less than or equal to `x`.
"""
eps = np.finfo(float).eps
x_scaled = (x - mean) / np.sqrt(var + eps)
return (1 + erf(x_scaled / np.sqrt(2))) / 2
class SchedulerBase(ABC):
def __init__(self):
"""Abstract base class for all Scheduler objects."""
self.hyperparameters = {}
def __call__(self, step=None, cur_loss=None):
return self.learning_rate(step=step, cur_loss=cur_loss)
def copy(self):
"""Return a copy of the current object."""
return deepcopy(self)
def set_params(self, hparam_dict):
"""Set the scheduler hyperparameters from a dictionary."""
if hparam_dict is not None:
for k, v in hparam_dict.items():
if k in self.hyperparameters:
self.hyperparameters[k] = v
@abstractmethod
def learning_rate(self, step=None):
raise NotImplementedError
class ConstantScheduler(SchedulerBase):
def __init__(self, lr=0.01, **kwargs):
"""
Returns a fixed learning rate, regardless of the current step.
Parameters
----------
initial_lr : float
The learning rate. Default is 0.01
"""
super().__init__()
self.lr = lr
self.hyperparameters = {"id": "ConstantScheduler", "lr": self.lr}
def __str__(self):
return "ConstantScheduler(lr={})".format(self.lr)
def learning_rate(self, **kwargs):
"""
Return the current learning rate.
Returns
-------
lr : float
The learning rate
"""
return self.lr
class ExponentialScheduler(SchedulerBase):
def __init__(
self, initial_lr=0.01, stage_length=500, staircase=False, decay=0.1, **kwargs
):
"""
An exponential learning rate scheduler.
---
Parameters
----------
initial_lr : float
The learning rate at the first step. Default is 0.01.
stage_length : int
The length of each stage, in steps. Default is 500.
staircase : bool
If True, only adjusts the learning rate at the stage transitions,
producing a step-like decay schedule. If False, adjusts the
learning rate after each step, creating a smooth decay schedule.
Default is False.
decay : float
The amount to decay the learning rate at each new stage. Default is
0.1.
"""
super().__init__()
self.decay = decay
self.staircase = staircase
self.initial_lr = initial_lr
self.stage_length = stage_length
self.hyperparameters = {
"id": "StepScheduler",
"decay": self.decay,
"staircase": self.staircase,
"initial_lr": self.initial_lr,
"stage_length": self.stage_length,
}
def __str__(self):
return "ExponentialScheduler(initial_lr={}, stage_length={}, staircase={}, decay={})".format(
self.initial_lr, self.stage_length, self.staircase, self.decay
)
def learning_rate(self, step, **kwargs):
"""
Return the current learning rate as a function of `step`.
Parameters
----------
step : int
The current step number.
Returns
-------
lr : float
The learning rate for the current step.
"""
cur_stage = step / self.stage_length
if self.staircase:
cur_stage = np.floor(cur_stage)
return self.initial_lr * self.decay ** cur_stage
如果想要更多的资源,欢迎关注 @我是管小亮,文字强迫症MAX~
回复【福利】即可获取我为你准备的大礼,包括C++,编程四大件,NLP,深度学习等等的资料。
想看更多文(段)章(子),欢迎关注微信公众号「程序员管小亮」~

参考文章
- https://www.coursera.org/learn/machine-learning
- https://www.deeplearning.ai/
- 深度学习之手撕神经网络代码(基于numpy)
- 深度神经网络原理与实践
- 深度学习笔记3:手动搭建深度神经网络(DNN)
- https://github.com/ddbourgin/numpy-ml