欢迎关注WX公众号:【程序员管小亮】
专栏——深度学习入门笔记
声明
1)该文章整理自网上的大牛和机器学习专家无私奉献的资料,具体引用的资料请看参考文献。
2)本文仅供学术交流,非商用。所以每一部分具体的参考资料并没有详细对应。如果某部分不小心侵犯了大家的利益,还望海涵,并联系博主删除。
3)博主才疏学浅,文中如有不当之处,请各位指出,共同进步,谢谢。
4)此属于第一版本,若有错误,还需继续修正与增删。还望大家多多指点。大家都共享一点点,一起为祖国科研的推进添砖加瓦。
文章目录
深度学习入门笔记(十三):批归一化(Batch Normalization)
Batch Normalization简称BN。
1、归一化(BN)网络的激活函数
在深度学习兴起后,最重要的一个思想是它的一种算法,叫做 批归一化(BN),由 Sergey loffe 和 Christian Szegedy 两位研究者创造。
Batch 归一化会使参数搜索问题变得很容易,使神经网络对超参数的选择更加稳定,使超参数的范围更加庞大,使工作效果很好,也会使训练更加容易,即使是深层网络。
那么它是如何工作的呢?
让我们来看看 批归一化(BN) 是怎么起作用的吧。
举个例子,当训练一个模型,比如 logistic 回归时,你也许会记得,归一化输入特征可以加快学习过程:
- 计算了平均值,从训练集中减去平均值;
- 计算了方差,从上面的结果中除以方差;
- 接着完成对数据集进行归一化。
这其实就是一个问题——把学习问题的轮廓,从很长的东西,变成更圆的东西,变得更易于算法优化。

所以这是有效的,对 logistic 回归和神经网络的归一化输入特征值而言。

那么更深的模型呢?
它们不仅输入了特征值 ,而且这层有激活值 ,这层还有激活值 等等。如果想训练这些参数,比如 ,,那归一化 的平均值和方差岂不是很好?以便使 , 的训练更有效率。
在上面所说的 logistic 回归的例子中,你可以看到了如何归一化 ,,,会帮助我们更有效的训练参数 和 。
所以问题来了,对任何一个隐藏层而言,能否归一化 值,在此例中,比如说 的值,但可以是任何隐藏层的,以更快的速度训练 ,,因为 是下一层的输入值,所以就会影响 , 的训练。
简单来说,这就是 批归一化(BN) 的作用,尽管严格意义上来说,真正归一化的不是 ,而是 ,这在很多深度学习文献中有一些争论——关于在激活函数之前是否应该将值 归一化,或是否应该在应用激活函数 后再归一化。

这个问题何凯明在两代 ResNet 中做了详细的说明,我这里就不多赘述了,虽然我尝试的结果并不明显。。。甚至没效果=-=。实践中,最经常做的还是归一化 ,本人的经验告诉我,这是个默认的选择。
那么归一化的推导过程是怎么样的呢?
在神经网络中,已知一些中间值,假设有一些隐藏单元值,从 到 ,这些都来源于隐藏层,所以这样写会更准确,即 为隐藏层, 从1到m。
但这里省略 及方括号,以便简化这一行的符号,强调一下,所有这些都是针对 层,然后用常用公式计算方差,接着取每个 值,使其归一化,方法如下,减去均值再除以标准偏差,为了使数值稳定,通常将 作为分母,以防出现 的情况。
数学公式如下:
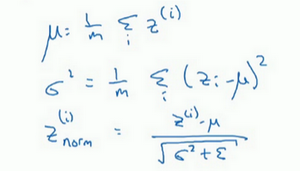
所以现在 值已经被标准化了(平均值0和标准单位方差),但我们不想让隐藏单元总是如此,也许隐藏单元有了不同的分布会有意义,所以一个很牛的计算是:
其中 和 是模型需要学习的参数,请注意 和 的作用,是无论如何随意设置 的平均值,事实上,如果 ,如果 等于这个分母项( 中的分母), 等于 ,这里的 中的 ,那么 的作用在于,它会精确转化这个方程,如果这些成立(),那么 。
归一化输入特征 是有助于神经网络中的学习的,批归一化(BN) 的作用是一个适用的归一化过程,不只是输入层,甚至同样适用于神经网络中的深度隐藏层。
有了 和 两个参数后,就可以确保所有的 值都是想赋予的值,或者是保证隐藏的单元已使均值和方差标准化,即 无论数据归一化计算时出现多大问题,通过参数都可以调整回来。
2、将BN拟合进神经网络
上面讲的推导过程是可以在单一隐藏层进行 BN,接下来看看在深度网络训练中如何拟合?

假设有一个上图所示的神经网络,可以认为每个单元负责计算两件事。第一,计算z,然后应用其到激活函数中再计算a,所以每个圆圈代表着两步的计算过程,即左半边是求z,右半边是求a。同样的,对于下一层而言,那就是 和 等。
所以如果没有 BN,输入 会拟合到第一隐藏层,然后计算 ,这是由 和 两个参数控制的。接着,通常会把 拟合到激活函数以计算 。
但 BN 的做法是将 值进行归一化,此过程将由上面提到过的 和 两参数控制,这一操作会得到一个新的归一化 值(),然后将其输入激活函数中得到 ,即 。
第二层计算也是如此,所以需要强调的是 BN 是发生在计算 和 之间的!!!
到这里,简单的 BN 操作就已经清晰明了了——计算均值和方差,减去均值,再除以方差,如果你使用的是深度学习编程框架,通常不必自己实现 BN 层,但是需要知道它是如何作用的,因为这可以帮助你更好地理解代码的作用。
在实践中,绝大多数深度学习框架都可写成一行代码,比如在 TensorFlow 框架中,可以用这个函数(tf.nn.batch_normalization)来实现 BN,详见 tf.nn.batch_normalization()函数解析(最清晰的解释) 和 TensorFlow学习笔记之批归一化:tf.layers.batch_normalization()函数。
很多情况下,BN 和训练集的 mini-batch 一起使用,具体如下:
-
用第一个 mini-batch(),然后计算 ,应用参数 和 ,使用这个 mini-batch()。
-
接着,继续第二个 mini-batch(),BN 会减去均值,除以标准差,由 和 重新缩放,这样就得到了 ,而这些都是在第一个 mini-batch 的基础上,再应用激活函数得到 。然后用 和 计算 ,等等。这一切都是为了在第一个 mini-batch()上进行一步梯度下降法。

-
类似的工作,在第二个 mini-batch()上、在第三个 mini-batch()上同样这样做,继续训练。
现在让我们总结一下关于如何用 BN 应用梯度下降法:
- 假设使用 mini-batch 梯度下降法,运行 到 batch 数量的 for 循环;
- 在 mini-batch 上应用正向 prop,每个隐藏层都应用正向 prop,用 BN 代替 为 ;
- 接下来,确保在这个 mini-batch 中, 值有归一化的均值和方差,归一化均值和方差后是 ;
- 然后,你用反向 prop 计算 和 ,及所有 层所有的参数,和;
- 最后,更新这些参数:;
- 和以前一样,;
- 对 也是如此,。
如果已将梯度计算如下,就可以使用梯度下降法了,但也同样适用于有 Momentum、RMSprop、Adam 的梯度下降法。除此之外也可以应用其它的一些优化算法来更新由 BN 添加到算法中的 和 参数。
希望,我们能学会如何从头开始应用 BN,而不仅仅是只会使用深度学习编程框架,虽然这会使 BN 的使用变得很容易,但是出来混迟早会换的!!!
3、BN为什么奏效?
现在,以防 BN 归一化仍然看起来很神秘,尤其是还不清楚为什么其能如此显著的加速训练的时候,为什么 BN 会起作用呢? 它到底在做什么?
- BN 有效的一个原因是,归一化的输入特征值 ,均值为0,方差为1,现在有一些从0到1而不是从1到1000的特征值,通过归一化所有的输入特征值 ,可以获得类似范围的值,可以加速学习。所以 BN 起作用的原因,直观的一点就是,它在做类似的工作,但不仅仅对于这里的输入值,还有隐藏单元的值,这只是 BN 作用的冰山一角,还有些深层的原理。
- BN 有效的第二个原因是,它可以使权重比网络更滞后或更深层,比如,第10层的权重更能经受得住变化,相比于神经网络中前层的权重,比如第1层。
为了解释第二个原因,让我们来看看这个最生动形象的例子(吴恩达老师讲的)。

如上图,这是一个网络的训练过程,也许是个浅层网络,比如 logistic 回归或是一个其他的什么神经网络,或者是一个深层网络,比如著名的猫脸识别检测,但现在我们假设已经在所有黑猫图像上训练了数据集,如果现在要把此网络应用于有色猫,这种情况下,正面的例子不只是左边的黑猫,还有右边其它颜色的猫,那么你的 cosfa 可能适用的不会很好。

如果训练集是上图左侧这个样子的,正面例子在这儿,反面例子在那儿,但你试图把它们都统一归于一个数据集中,如上图右侧。在这种情况下,你就不能期待在左边训练得很好的模块,同样在右边也运行得很好,即使可能是存在运行都很好的同一个函数。使数据改变分布的这个想法,有个有点怪的名字 Covariate shift,这个想法是这样的:
如果模型已经学习了 到 的映射,但是此时 的分布改变了,那么可能就需要重新训练这个学习算法了,为什么这么说呢,往下看就知道了。
现在再想一个问题,Covariate shift 的问题怎么应用于神经网络呢?
还是试想一个深度网络,从第三层看学习过程。此网络已经学习了参数 和 ,从第三隐藏层的角度来看,它从前层中取得一些值,接着它需要做些什么才能使输出值 接近真实值 ?
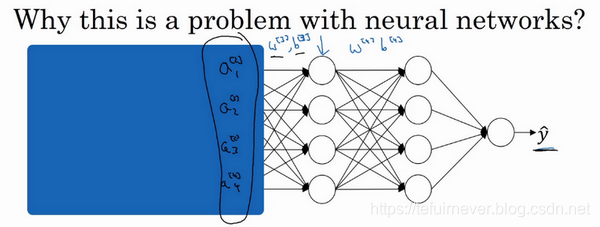
这样看,先遮住网络左边的部分,从第三隐藏层的角度来看,它得到的这些值,称为 ,, 和 ,但这些值也可以是特征值 ,, 和 ,我们此时的工作是找到一种方式使这些值映射到 ,也许是学习这些参数, 和 或 和 或 和 。

现在把刚才盖住的网络左边揭开,这个网络还有参数 , 和 ,,如果这些参数改变,这些 的值也会改变。
所以综上,从第三层隐藏层的角度来看,这些隐藏单元的值在不断地改变,就有了 Covariate shift 的问题。
BN 做的是减少了这些隐藏值分布变化的数量。 和 的值可以改变,因此神经网络在之前层中可以更新参数,但是 BN 可以确保无论其怎样变化, 和 的均值和方差保持不变,所以即使值改变,至少均值和方差也会是均值0,方差1,或不一定必须是均值0,方差1,而是由 和 决定的值。这使得值变得更稳定,神经网络的之后层就会有更坚实的基础。即使输入分布改变了一些,但是它会改变得更少。BN 做的是当前层保持学习,当改变时,迫使后层适应的程度减小。
用人话翻译一下就是:减弱了前层参数的作用与后层参数的作用之间的联系,网络每层都可以自己学习,稍稍独立于其它层,这有助于加速整个网络的学习。
所以,希望 BN 的学习能带给更好的直觉(作为一个“玄学专业”)。
BN 还有一个作用,它有轻微的正则化效果。在 mini-batch 中,由于只是一小部分数据估计得出的均值和方差,而不是在整个数据集上,均值和方差有一些小的噪声,所以和 dropout 相似,往每个隐藏层的激活值上增加了噪音。
这里简单说两句,dropout 有增加噪音的方式,它使一个隐藏的单元,以一定的概率乘以0,以一定的概率乘以1,所以 dropout 含几重噪音,因为它乘以0或1。
对比而言,BN 含几重噪音,因为标准偏差的缩放和减去均值带来的额外噪音,所以类似于 dropout,噪音迫使后部单元不过分依赖任何一个隐藏单元,但是因为添加的噪音很微小,所以并不是巨大的正则化效果。如果将 BN 和 dropout 一起使用应该会得到更强大的正则化效果。
也许另一个轻微非直观的效果是,如果应用了较大的 mini-batch,比如说,用了512而不是64,就会减少了噪音,因此也就减少了正则化效果,这是 dropout 的一个奇怪的性质,就是应用较大的 mini-batch 会减少正则化效果。
说到这儿,BN 好像一种正则化,有时它会对算法有额外的期望效应或非期望效应,但是不要把 BN 当作正则化,把它当作归一化隐藏单元激活值并加速学习的方式更好,正则化可以认为是一个意想不到的副作用,也就是惊喜。
4、测试时的 Batch Norm
BN 将数据以 mini-batch 的形式逐一处理,但在测试时,可能需要对每个样本逐一处理。
那么怎样调整网络来做到这一点呢?

回想一下,在训练时,上面这些公式都是用来执行 BN。在一个 mini-batch 中,
- 先对 值求和,计算均值,所以这里只把一个 mini-batch 中的样本都加起来,假设用m来表示这个 mini-batch 中的样本数量,而不是整个训练集。
- 然后计算方差,再算 ,即用均值和标准差来调整,加上 是为了数值稳定性。 是用 和 再次调整 得到的。
请注意,用于调节计算的 和 是在整个 mini-batch 上进行计算的,但是在测试时,可能不能将一个 mini-batch 中的很多个样本同时处理,因此,需要用其它方式来得到 和 ,而且如果只有一个样本的话,一个样本的均值和方差是没有意义的。
所以实际上,为了将神经网络运用于测试,就需要单独估算 和 ,在典型的 BN 运用中,需要用一个指数加权平均来估算。
总结来说就是,在训练时, 和 是在整个 mini-batch 上计算出来的包含了一定数量的样本,但在测试时,可能需要逐一处理样本,方法是根据训练集估算 和 。
估算的方式有很多种,
- 理论上可以在最终的网络中运行整个训练集来得到 和 ,但在实际操作中,通常运用指数加权平均来追踪在训练过程中的 和 的值。
- 还可以用指数加权平均,有时也叫做流动平均,来粗略估算 和 ,然后在测试中使用 和 的值来进行所需的隐藏单元 值的调整。
在实践中,不管用什么方式估算 和 ,这套过程都是比较稳健的,而且如果使用的是某种深度学习框架,通常会有默认的估算 和 的方式,应该会起到比较好的效果。
BN 就讲到这里了,使用 BN 能够训练更深的网络,让学习算法运行速度更快,其他的理论理解也可以看一下这个博客 深度学习100问之深入理解Batch Normalization(批归一化)。
推荐阅读
- 深度学习入门笔记(一):深度学习引言
- 深度学习入门笔记(二):神经网络基础
- 深度学习入门笔记(三):求导和计算图
- 深度学习入门笔记(四):向量化
- 深度学习入门笔记(五):神经网络的编程基础
- 深度学习入门笔记(六):浅层神经网络
- 深度学习入门笔记(七):深层神经网络
- 深度学习入门笔记(八):深层网络的原理
- 深度学习入门笔记(九):深度学习数据处理
- 深度学习入门笔记(十):正则化
- 深度学习入门笔记(十一):权重初始化
- 深度学习入门笔记(十二):深度学习数据读取
- 深度学习入门笔记(十三):批归一化(Batch Normalization)
- 深度学习入门笔记(十四):Softmax
- 深度学习入门笔记(十五):深度学习框架(TensorFlow和Pytorch之争)
- 深度学习入门笔记(十六):计算机视觉之边缘检测
- 深度学习入门笔记(十七):深度学习的极限在哪?
- 深度学习入门笔记(十八):卷积神经网络(一)
- 深度学习入门笔记(十九):卷积神经网络(二)
- 深度学习入门笔记(二十):经典神经网络(LeNet-5、AlexNet和VGGNet)
参考文章
- 吴恩达——《神经网络和深度学习》视频课程