2017-08-06 19:52:21
目标:获取上交所和深交所所有股票的名称和交易信息
输出:保存到文件中
技术路线:scrapy
获取股票列表:
东方财富网:http://quote.eastmoney.com/stocklist.html
获取个股信息:
百度股票:https://gupiao.baidu.com/stock/
单个股票:https://gupiao.baidu.com/stock/sz002439.html
程序框架
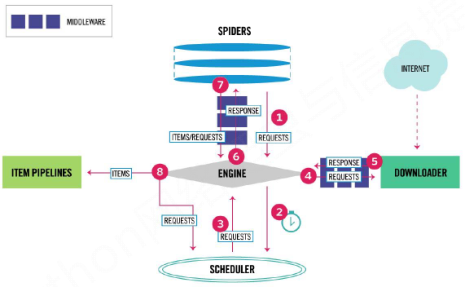
编写spider处理链接爬取和页面解析,编写pipelines处理信息存储。
一、具体流程
步骤1:建立工程和Spider模板
步骤2:编写Spider
步骤3:编写ITEM Pipelines
- 建立工程和Spider模板
>scrapy startproject BaiduStocks
>cd BaiduStocks
>scrapy genspider stocks baidu.com
进一步修改spiders/stocks.py文件
- 编写Spider
- 配置stocks.py文件
- 修改对返回页面的处理
- 修改对新增URL爬取请求的处理
stocks.py修改前

stock.py修改后
# -*- coding: utf-8 -*- import scrapy import re import random class StocksSpider(scrapy.Spider): name = "stocks" start_urls = ['http://quote.eastmoney.com/stocklist.html'] user_agent_list = [ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1" "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3"] def parse(self, response): ua = random.choice(self.user_agent_list) headers = { 'Accept-Encoding':'gzip, deflate, sdch, br', 'Accept-Language':'zh-CN,zh;q=0.8', 'Connection':'keep-alive', 'Referer':'https://gupiao.baidu.com/', 'User-Agent':ua }#构造请求头 for href in response.css('a::attr(href)').extract(): try: stock = re.findall(r"[s][hz]d{6}",href)[0] url = "https://gupiao.baidu.com/stock/"+stock+".html" yield scrapy.Request(url,callback=self.parse_stock,headers = headers) except: continue def parse_stock(self,response): #itempipline模块接受的是字典类型的数据 infodict = {} name = response.css('.bets-name').extract()[0] keylist = response.css('dt').extract() vallist = response.css('dd').extract() for i in range(len(keylist)): key = re.findall(r".*>(.*)</dt>",keylist[i])[0] try: val = re.findall(r">[-]?d+.?.*</dd>",vallist[i])[0][1:-5] except: val = "--" infodict[key] = val infodict.update({"股票名称":re.findall(r"s+.*(",name)[0].split()[0]+re.findall(r"d+</s",name)[0][0:-3]}) yield infodict
Scrapy中提供了css选择器,可以使用css选择器进行html页面的提取。
主要的使用方法有:
<HTML>.css('a::attr(href)').extract() : 这样会提取到a标签下的href属性的值,并提取为字符串,返回一个列表
<HTML>.css('a').extract() :这样会提取所有a标签以及全部内容,转成字符串,返回一个列表
<HTML>.css('.calc').extract():这样会提取所有类型为calc的标签及其全部内容,转成字符串,返回一个列表
<HTML>.css('.calc'):不提取的话,会返回一个选择器类型,可以继续对类型为calc的便签内容进行继续提取
- 编写Pipelines
配置pipelines.py文件
定义对爬取项(Scraped Item)的处理类,每一个类处理一个items
配置ITEM_PIPELINES选项
pipelines.py修改前:

pipelines.py修改后
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html #每一个类都是对一个itme进行处理的类 class BaidustocksPipeline(object): def process_item(self, item, spider): return item class Baidustocksinfopipeline(object): def open_spider(self,spider): self.f = open("Baidustockinfo.txt",'w') def close_spider(self,spider): self.f.close() def process_item(self,item,spider): try: line = str(dict(item))+" " self.f.write(line) except: pass return item
- 配置settings.py文件

- 最后使用 Scrapy crawl stocks 执行爬虫
注意事项:
在实际编写过程中遇到不少的问题,这里提一下其中的需要注意的部分。
(1)爬取的结果为403,爬取失败。这一般是反爬虫程序在作怪,使用自行配置的headers即可解决。
(2)正则表达式的匹配问题,主要是最短匹配的问题里有个更高优先级的是,最先开始匹配的拥有最高优先级。
(3)extract()提取出来的是列表,在使用的时候需要加上 [ i ],同理,re.findall()返回的也是列表,即使仅包含一个元素也需要使用[0]来进行成员的访问。