韩玉琪 + 原创作品转载请注明出处 + 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
一、进程的描述
为了管理进程,内核必须对每个进程进行清晰的描述,进程描述符提供了内核所需了解的进程信息。
1. 进程控制块PCB——task_struct
-
操作系统的三大管理功能
- 进程管理 - 内存管理 - 文件系统 -
PCB task_struct中包含
- 进程状态 - 进程打开的文件 - 进程优先级信息 -
struct task_struct数据结构很庞大
2. Linux进程的状态
-
不同于操作系统(就绪、运行、阻塞)
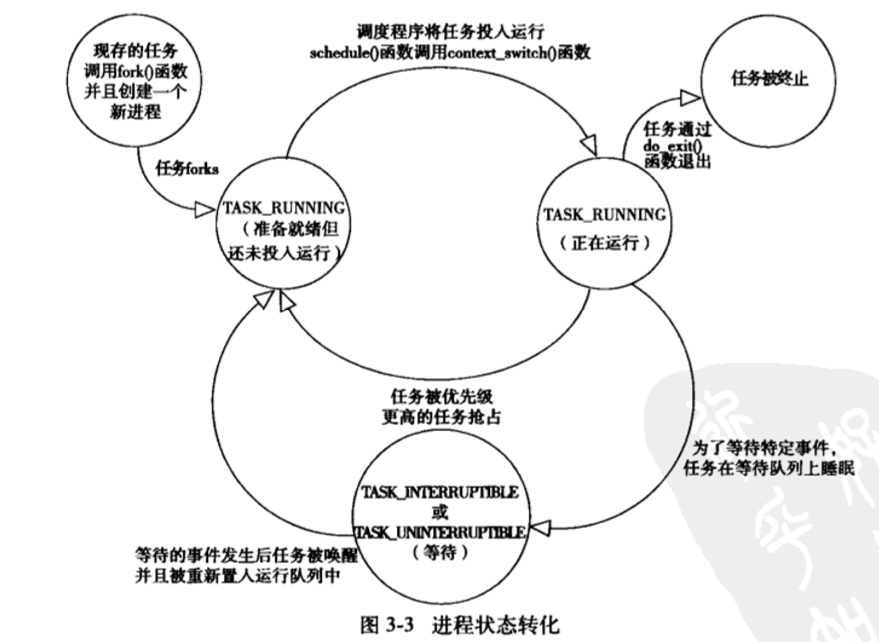
图片来源:《Linux内核设计与实现》
-
定义的进程状态

3. 我们关心的字段




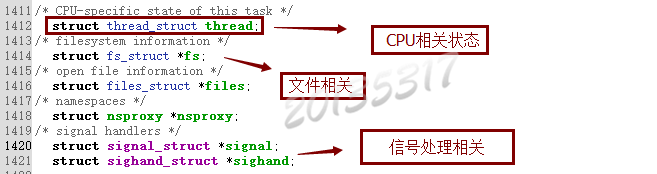
4. 分析内核处理过程
(1)do_fork
- 调用
copy_process,将当前进程复制一份出来给子进程,并且为子进程设置相应地上下文信息。 - 调用
wake_up_new_task,将子进程放入调度器的队列中,此时的子进程就可以被调度进程选中运行。
(2)copy_process
- 创建进程描述符以及子进程所需要的其他所有数据结构,为子进程准备运行环境
- 调用
dup_task_struct复制一份task_struct结构体,作为子进程的进程描述符。 - 复制所有的进程信息
- 调用
copy_thread,设置子进程的堆栈信息,为子进程分配一个pid。
(3)dup_ task_ struct
-
先调用
alloc_task_struct_node分配一个task_struct结构体。 -
调用
alloc_thread_info_node,分配了一个union。这里分配了一个thread_info结构体,还分配了一个stack数组。返回值为ti,实际上就是栈底。 -
tsk->stack = ti将栈底的地址赋给task的stack变量。 -
最后为子进程分配了内核栈空间。
-
执行完
dup_task_struct之后,子进程和父进程的task结构体,除了stack指针之外,完全相同。
(4)copy_thread
- 获取子进程寄存器信息的存放位置
- 对子进程的thread.sp赋值,将来子进程运行,这就是子进程的esp寄存器的值。
- 如果是创建内核线程,那么它的运行位置是
ret_from_kernel_thread,将这段代码的地址赋给thread.ip,之后准备其他寄存器信息,退出 - 将父进程的寄存器信息复制给子进程。
- 将子进程的eax寄存器值设置为0,所以fork调用在子进程中的返回值为0.
- 子进程从
ret_from_fork开始执行,所以它的地址赋给thread.ip,也就是将来的eip寄存器。
(5)运行新进程
从ret_from_fork处开始执行
dup_task_struct中为其分配了新的堆栈copy_process中调用了sched_fork,将其置为TASK_RUNNINGcopy_thread中将父进程的寄存器上下文复制给子进程,这是非常关键的一步,这里保证了父子进程的堆栈信息是一致的。- 将
ret_from_fork的地址设置为eip寄存器的值,这是子进程的第一条指令。
二、进程的创建
1. fork
- fork系统调用在父进程和子进程各返回一次
- 子进程中返回的是0,父进程中返回值是子进程的pid。
2. 创建一个新进程在内核中的执行过程
fork、vfork和clone三个系统调用都可以创建一个新进程,而且都是通过调用do_fork来实现进程的创建。
- 创建新进程是通过复制当前进程实现的。
do_fork主要是复制了父进程的task_struct,然后修改必要的信息,从而得到子进程的task_struct。
-
复制一个PCB——task_struct
err = arch_dup_task_struct(tsk, orig); -
要给新进程分配一个新的内核堆栈
ti = alloc_thread_info_node(tsk, node); tsk->stack = ti; setup_thread_stack(tsk, orig); //这里只是复制thread_info,而非复制内核堆栈 -
要修改复制过来的进程数据,比如pid、进程链表等。
3. 子进程系统调用处理过程
*childregs = *current_pt_regs(); //复制内核堆栈
childregs->ax = 0; //子进程的fork返回0的原因
p->thread.sp = (unsigned long) childregs; //调度到子进程时的内核栈顶
p->thread.ip = (unsigned long) ret_from_fork; //调度到子进程时的第一条指令地址
- 刚fork出来的子进程是从
ret_from_fork开始执行的,然后跳转到syscall_exit,从系统调用中返回。
三、实践:分析Linux内核创建一个新进程的过程
1. 启动MenuOS
cd LinuxKernel
rm menu -rf
git clone https://github.com/mengning/menu.git
cd menu
mv test_fork.c test.c
make rootfs

2. gdb调试fork命令
qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.img -s -S
-
在新窗口中启动调试:
$ gdb $ file linux-3.18.6/vmlinux $ target remote:1234 -
设置断点:

- b sys_clone - b do_fork - b dup_task_struct - b copy_process - b copy_thread - b ret_from_fork -
在Menu系统中输入fork指令,可以看到只输出了fork功能的描述,在断点处sys_clone处停止了。

-
继续调试,停在do_ fork 和copy_ process

-
程序停在dup_task_struct函数处

-
在copy_thread函数中,继续单步执行,可以看到,内核空间压栈地址被初始化了。
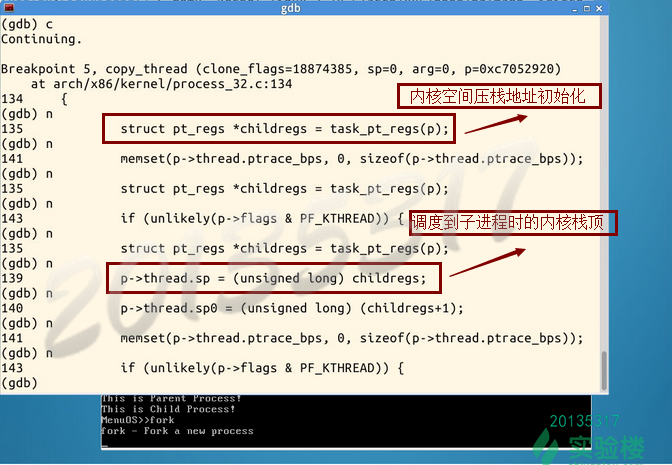

-
程序停止在了ret_ from_ fork处,当前系统执行的是汇编代码。(同时打印出进程信息)

四、总结
Linux通过复制父进程来创建一个新进程,通过调用do_ fork来实现并为每个新创建的进程动态地分配一个task_ struct结构。
1. 新进程的开始
-
copy_thread()中:
p->thread.ip = (unsigned long) ret _from _fork; -
将子进程的ip设置为ret_ form _ fork的首地址,因此子进程是从ret_ from_ fork开始执行的。
2. 执行起点与内核堆栈保证一致
-
在设置子进程的ip之前:
*childregs = *current_ pt_ regs(); -
将父进程的regs参数赋值到子进程的内核堆栈,*childregs的类型为pt_regs,其中存放了SAVE ALL中压入栈的参数。